推荐系统论文回顾:神经协同过滤理解与实现
作者:Kung-Hsiang, Huang (Steeve)
编译:ronghuaiyang
今天给大家回顾一篇论文,神经协同过滤,看名字就知道,神经网络版本的协同过滤,推荐算法的经典的方法之一。

神经协同过滤 (NCF) 是新加坡国立大学、哥伦比亚大学、山东大学、德州农工大学于 2017 年共同发表的一篇论文。利用神经网络的灵活性、复杂性和非线性,建立了一个推荐系统。证明了传统的推荐系统矩阵分解是神经协同过滤的一个特例。此外,它还表明 NCF 在两个公共数据集中的表现优于最先进的模型。本文将解释 NCF 的概念,并演示如何在 Pytorch 中实现它。
必备知识点
在深入研究论文之前,你应该知道什么是推荐系统,以及一些基本的推荐系统。
矩阵分解
我们从矩阵分解开始。它将效用矩阵分解为两个子矩阵。在预测过程中,我们将两个子矩阵相乘来重建预测的效用矩阵。对效用矩阵进行因式分解,使两者相乘的损失与真实效用矩阵的损失最小化。一个常用的损失函数是均方误差。
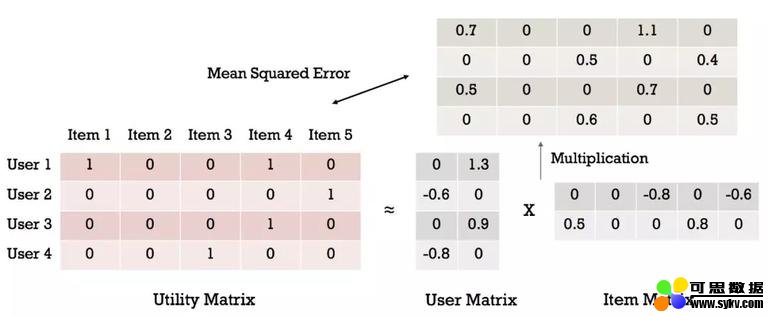
本质上,每个用户和物品都被投射到潜空间中,由潜向量表示。两个潜向量越相似,对应的用户偏好越相关。由于我们将效用矩阵分解成相同的潜在空间,所以我们可以用余弦相似度或点积来度量任意两个潜向量的相似度。实际上,每个用户 / 物品的预测是通过对应的潜向量的点积计算出来的。
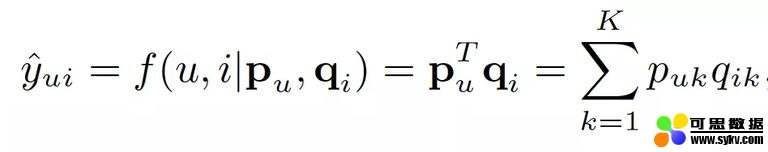
预测等于潜向量的内积
然而,本文认为点积限制了用户和物品潜向量的表达。让我们考虑下面的情况。我们首先关注效用矩阵的前三行。
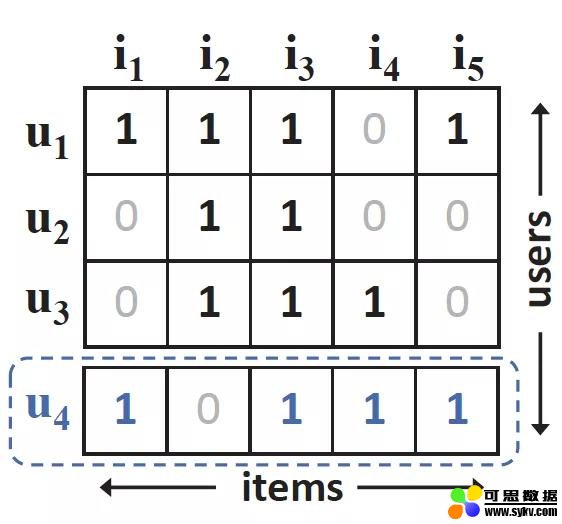
设 S{x,y} 表示用户 x 与用户 y 之间的相似度,通过计算用户 1、2、3 之间的余弦相似度,可知 S{2, 3} > S{1, 2} > S{1, 3}。在不失一般性的情况下,我们将用户映射到一个二维的潜空间,如下所示。
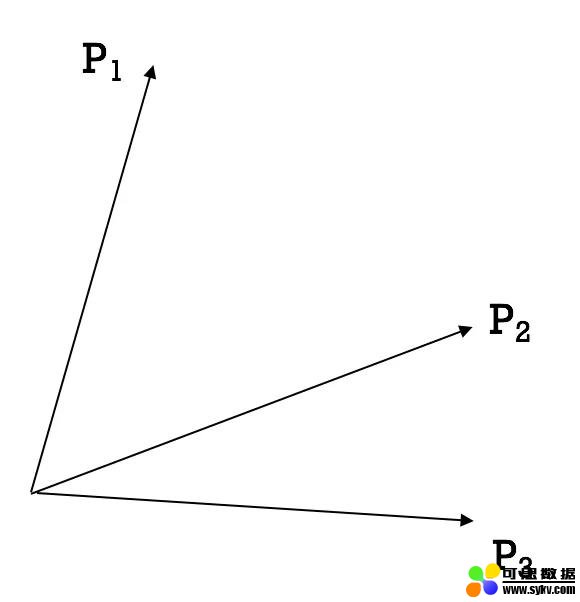
现在,我们考虑用户 4。通过与其他算法的相似性比较,我们得到了 S{1,4} > S{3,4} > S{2,4}。但是,无论我们把潜向量 P4 放在 P1 的左右,它都必然会比 P3 更接近 P2。
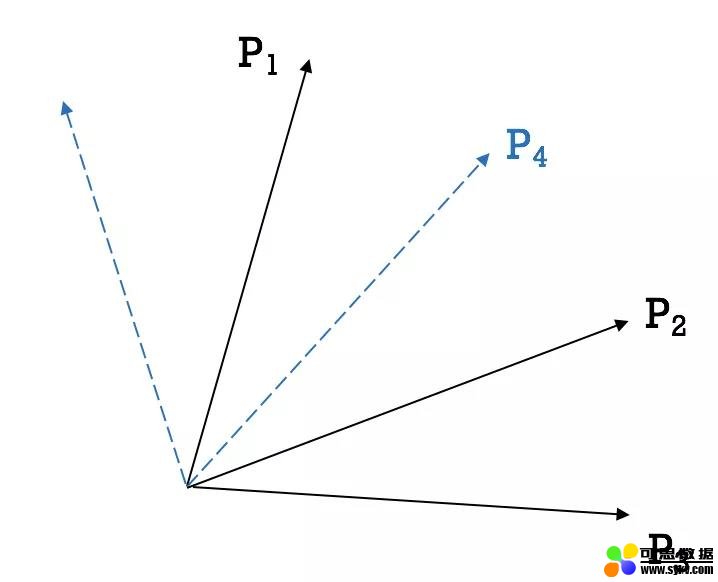
因此,这个例子显示了内积在充分模拟用户和项目在潜在空间中的交互方面的局限性。
神经协同过滤
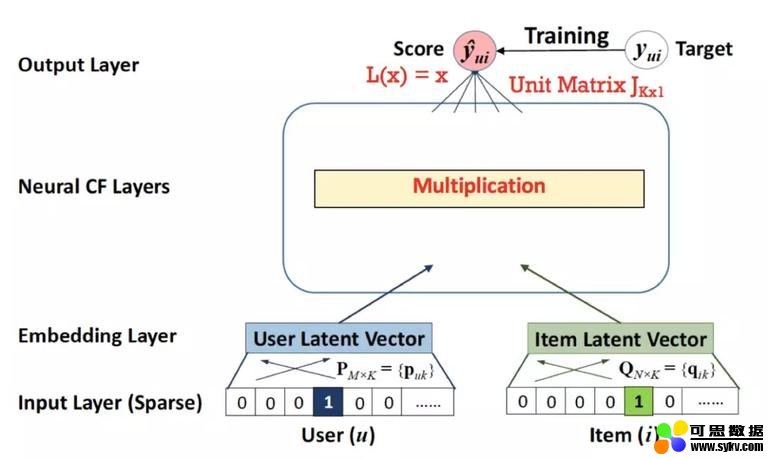
本文提出了如下图所示的神经协同滤波方法。在输入层,用户和物品是独热编码的。然后,通过相应的嵌入层映射到隐藏空间。神经网络 FC 层可以是任何类型的神经元连接。例如,多层感知器可以放在这里。该模型具有神经 CF 层的复杂连接和非线性,能够较好地估计潜空间中用户与物品之间的复杂交互作用。

- 本文地址:http://www.6aiq.com/article/1578837141466
- 本文版权归作者和AIQ共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出
- 知乎专栏 点击关注
NCF 结构
那么,NCF 是如何成为泛化版本的矩阵分解的呢?让我在下图中给你展示。我们首先用乘法层替换神经 CF 层,乘法层对两个输入执行元素级的乘法。然后利用线性激活函数,将乘法层到输出层的权值设为 K×1 维的固定单位矩阵 (全一矩阵)。
然后,我们有以下方程。
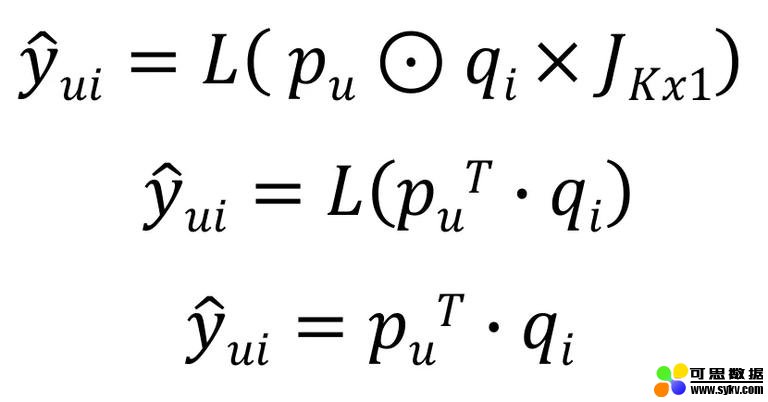
未被发现的交互 ŷ_ui 表示预测值 (u, i) 进入了重建的效用矩阵。L 为线性激活函数,⊙ 为元素乘操作。p_u 和 q_i 分别是用户和项目的潜在向量,J 是维数 (K,1) 的单位矩阵。因为 J 是一个单位矩阵,所以在这个线性函数里面变成了潜向量 p_u 和 q_i 的内积。此外,由于线性函数的输入和输出是相同的,所以可以归结为最后一行。预测标签是对应用户和物品的潜向量的内积。这个方程与矩阵分解部分所示的方程相同。从而证明了矩阵分解是 NCF 的一个特例。
NeuMF
为了引入额外的非线性能力,提出的最终模型 NeuMF 除了广义矩阵分解 (GMP) 层外,还包括一个多层感知器 (MLP) 模块。
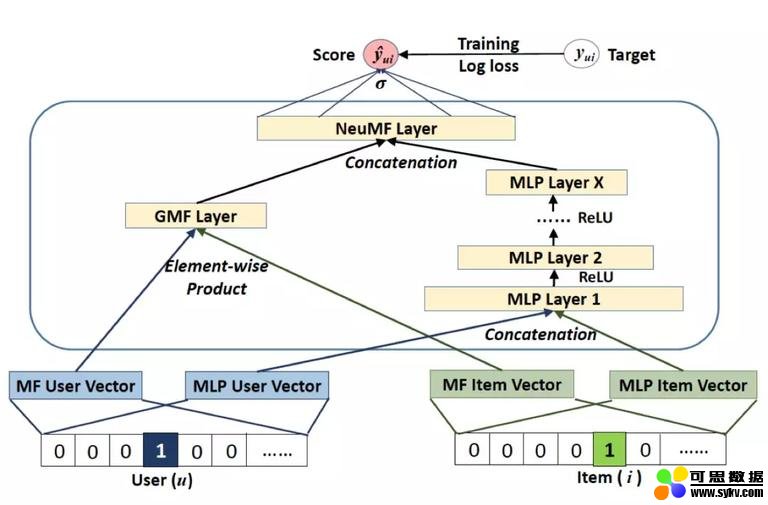
GMF 和 MLP 模块的输出连接到 sigmoid 激活输出层。
性能
本文对 NCF 模型和其他模型进行了评价。也就是说,每个用户的最后一次交互被保留下来进行评估。考虑两个评估指标,命中率 @10 和 NDCG@10。命中率 @K 表示每个用户获得 10 个推荐的预测命中率。假设我们为每个用户推荐 10 个项目,10 个用户中的 4 个与我们推荐的项目进行交互,然后点击 Ratio@10=0.4。另一方面,NDCG 可以被看作是命中率的扩展,它还考虑了命中的顺序。这意味着如果你的命中发生在较高的推荐上,NDCG 将更高。
性能比较如下图所示。在所有情况下,NeuMF 的表现都优于其他模型。
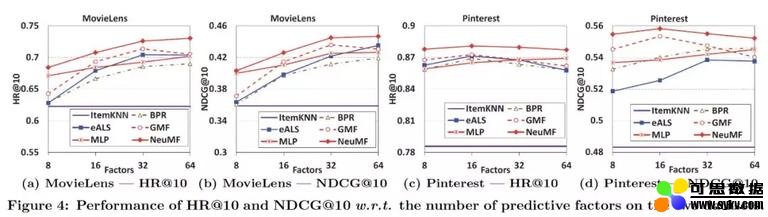
此外,本文还证明了对 NeuMF 各个模块进行预训练的有效性。分别训练 GMF 和 MLP 后,将训练后的 GMF 和 MLP 的权重设置为 NeuMF 的初始化。

实现
在本节中,我将向你展示如何在 Pytorch 中轻松实现 NeuMF。你只需为每个模型实现两个函数,__init__函数指定模型结构,而forward()函数定义如何将输入张量进行前向传播。
def __init__(self, config):
super(NeuMF, self).__init__()
#mf part
self.embedding_user_mf = torch.nn.Embedding(num_embeddings=self.num_users, embedding_dim=self.latent_dim_mf)
self.embedding_item_mf = torch.nn.Embedding(num_embeddings=self.num_items, embedding_dim=self.latent_dim_mf)
#mlp part
self.embedding_user_mlp = torch.nn.Embedding(num_embeddings=self.num_users, embedding_dim=self.latent_dim_mlp)
self.embedding_item_mlp = torch.nn.Embedding(num_embeddings=self.num_items, embedding_dim=self.latent_dim_mlp)
self.fc_layers = torch.nn.ModuleList()
for idx, (in_size, out_size) in enumerate(zip(config['layers'][:-1], config['layers'][1:])):
self.fc_layers.append(torch.nn.Linear(in_size, out_size))
self.logits = torch.nn.Linear(in_features=config['layers'][-1] + config['latent_dim_mf'] , out_features=1)
self.sigmoid = torch.nn.Sigmoid()
研究结果表明,采用单独的嵌入层,MLP 和 GMF 的嵌入效果更好。因此,我们为这两个模块定义了指定的嵌入层。此外,ModuleList 还用于构建多层感知器。
def forward(self, user_indices, item_indices, titles):
user_embedding_mlp = self.embedding_user_mlp(user_indices)
item_embedding_mlp = self.embedding_item_mlp(item_indices)
user_embedding_mf = self.embedding_user_mf(user_indices)
item_embedding_mf = self.embedding_item_mf(item_indices)
#### mf part
mf_vector =torch.mul(user_embedding_mf, item_embedding_mf)
mf_vector = torch.nn.Dropout(self.config.dropout_rate_mf)(mf_vector)
#### mlp part
mlp_vector = torch.cat([user_embedding_mlp, item_embedding_mlp], dim=-1) # the concat latent vector
for idx, _ in enumerate(range(len(self.fc_layers))):
mlp_vector = self.fc_layers[idx](mlp_vector "idx")
mlp_vector = torch.nn.ReLU()(mlp_vector)
mlp_vector = torch.nn.Dropout(self.config.dropout_rate_mlp)(mlp_vector)
vector = torch.cat([mlp_vector, mf_vector], dim=-1)
logits = self.logits(vector)
output = self.sigmoid(logits)
return output
forward()函数相当简单。我们只是让用户和物品索引在定义的网络中流动。特别要注意的是,我在 GMP 和 MLP 模块的末尾添加了 Dropout 层,因为我发现这有助于网络的正则化和性能的提高。

—END—
英文原文:https://towardsdatascience.com/paper-review-neural-collaborative-filtering-explanation-implementation-ea3e031b7f96

时间:2020-01-18 23:59 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]AAAI21最佳论文Informer:效果远超Transformer的长序列
- [机器学习]当推荐遇到冷启动
- [机器学习]Attention!当推荐系统遇见注意力机制
- [机器学习]AAAI21最佳论文Informer:效果远超Transformer的长序列
- [机器学习]万物皆可Graph | 当推荐系统遇上图神经网络
- [机器学习]牛津CS博士小姐姐134页毕业论文探索神经网络内部
- [机器学习]推荐系统架构与算法流程详解
- [机器学习]MIT研究人员发现 ImageNet 数据集存在系统性缺陷
- [机器学习]揭秘Facebook搜索中的语义检索技术
- [机器学习]深度学习推荐系统中各类流行的Embedding方法(下
相关推荐:
网友评论:















