新一代海量数据搜索引擎 TurboSearch 来了!
本文作者:sololzluo,腾讯 AI Lab 开发工程师
一. TurboSearch 简介
AI Lab 多年一直在搜索领域进行深耕和积累,继搜搜网页搜索之后,陆续服务于微信搜一搜(公众号文章、朋友圈、视频)、应用宝搜索、地图搜索、音乐搜索、视频搜索、手 Q、QQ 群等精品垂直搜索业务,以及云搜中小数据搜索业务。
从网页搜索继承下来的搜索系统,经过多年的需求迭代,越来越难以支撑结构级新特性更新。因此我们投入精力对整体系统重构和优化,重新构建了大规模、轻量级、松耦合、可裁剪、低运营成本 具有完整解决方案 的新一代搜索系统 TurboSearch 。主要有以下特性:
-
完整的 分布式、海量 搜索系统及运营解决方案
-
支持便捷 私有化部署
-
高性能索引及 并行检索
-
支持 多粒度索引 及检索
-
支持普通检索、分类检索、WAND 及精细化的检索层过滤逻辑
-
核心组件 解耦,支持横向扩展,能力可裁剪
-
无缝对接 AI Lab 各项 NLP 能力,涵盖 Query 分析及排序等多个领域
-
支持场景丰富,除传统的网页和各类非结构化垂类场景外,同时 可扩展 到多模态向量搜索场景
与业界部分开源引擎框架 ElasticSearch,Solr 等不同的是,TurboSearch 更倾向于面向在线 高并发、大规模、低时延 的检索需求,同时能够平行扩展到多模态场景,并提供完整的搜索运营能力。TurboSearch 在将会分层次和分阶段逐步在公司内部开源。
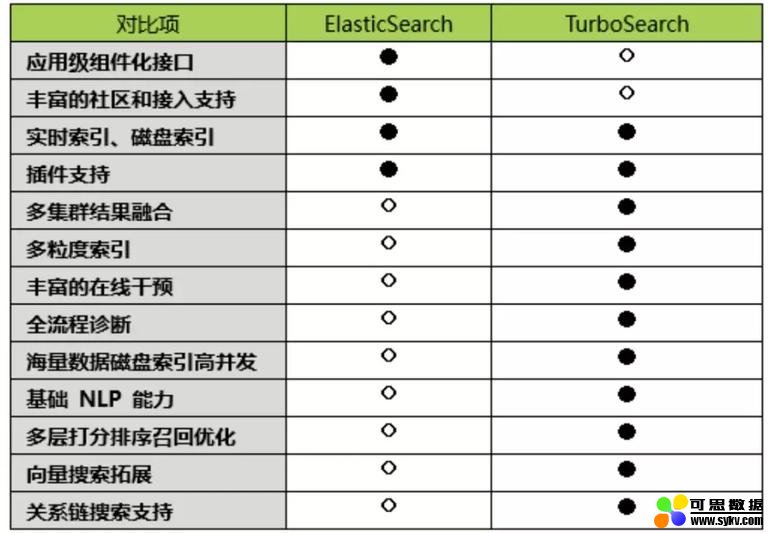
在 多模态 / 向量检索 领域,AI Lab 已经推出 GNES 检索系统,聚焦于内容对象的 Encoding,以及多种算法模型的平台化整合。同样在向量检索领域,TurboSearch 会逐步从索引层面,探索针对大规模向量数据集的高性能检索。并从向量索引、及系统化运营层面为 GNES 提供支持。
二. 引擎框架介绍
TurboSearch 引擎主要有六大核心能力:
-
搜索核心组件:基础核心能力抽象和组件化,便于扩展,如索引计算、检索核心等。同时为了降低多进程资源开销,构建了多线程 C++ 检索通信框架 smqRPC。
-
搜索基础服务:基于搜索核心组件分层包装的检索服务,主要包括离线索引、在线检索及检索接入三大层次。支持包括内存、磁盘索引在内的分布式索引及检索环境。
-
搜索 OSS 体系:包括离线索引生成、在线索引滚动更新、检索干预、ABTest 等多项能力。后续将进一步完善包括好例、离线效果评估等其它精细化运营系统。
-
效果扩展组件:搜索效果随业务场景而变化,我们将打分排序解耦剥离,内置部分基础相关性排序功能,也可自定义排序。
-
API 组件:提供包括 SDK、smq 协议访问及 HTTP RESTful 接口等多种访问方式。
-
Query 分析能力:除了基础的分词之外,也具备同义词、纠错、时新性计算、意图识别、成分分析、非比留、新词发现等全面能力。
TurboSearch 基础框架:

三. 引擎特性
1. Query 检索召回
检索多次下发
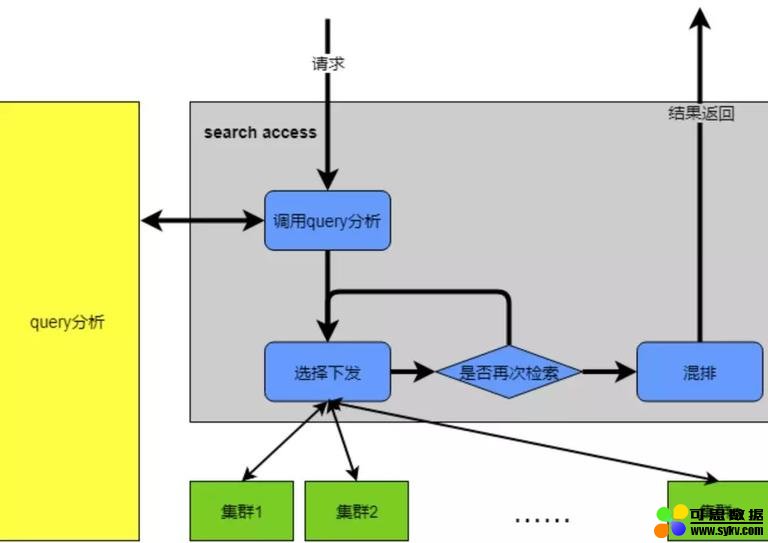
一个 Query 的搜索过程可以分为以下几个主要部分:
-
Query 分析(适用于网页和垂搜),包括切词、纠错、拓展、改写等。
-
检索召回,包括倒排求交、截断合并等。
-
打分排序,在 TurboSearch 中包含多层 rank 提高召回率。
然而,单次 Query 召回往往并不能达到搜索预期。比如,搜索 “吃鸡”,只召回吃饭相关的文章可能难以命中用户意图。将其拓展为 “和平精英”,或其他热点事件 Query,并将多次拓展结果融合,更容易命中用户意图。因此 TurboSearch 应对这样的 NLP 拓展能力,原生支持多次下发结果融合。
2. QRW & 分层打分排序
QRW 是 AI Lab 多年积累的 Query 分析 NLP 服务,除了覆盖垂搜所需的 纠错 同义词 / 非比留 / 基础相关性等基础能力之外,也涵盖了全网搜索所需具备的全部能力,如 Query 改写 / 时新性 / 意图识别 / 成分分析 / 文本分档 等等。
在排序和召回层面,TurboSearch 设计了 5 层 Rank 来最大化提高召回率 **,从 L0 - L4 覆盖离线、倒排求交、精计算、全局精排等多个层面,为每个可能漏招环节做保障。**
3. 高性能检索
并行检索
文本检索召回的基础即倒排求交:
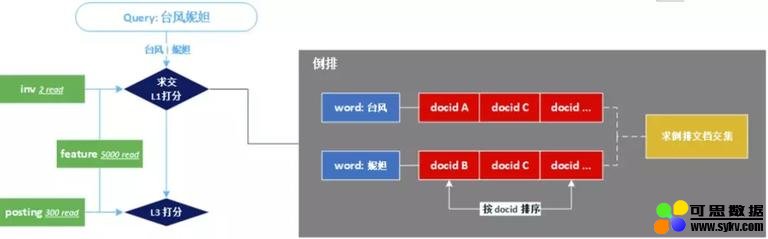
最耗时部分集中在 求交 +L1 打分 和 L3 打分。在传统的程序设计中,这两部分均在单线程中串行执行。使得在高频词检索求交时,单次请求耗时难以控制。
TurboSearch 针对两个高耗时流程,采用 多线程并行处理。将倒排索引切分,来并行化检索求交 +L1:
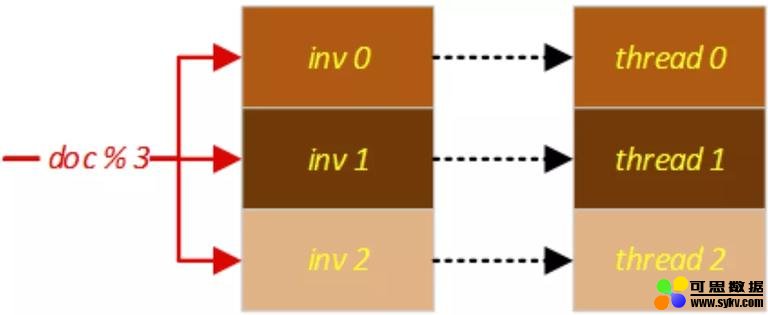
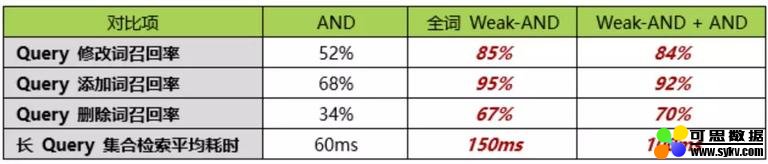
我们做了一些 特殊的无锁多线程结果合并设计,避免合并结果等待导致闲置 CPU 的问题。负载未达 100% 时,平均检索耗时可大幅降低(数据集为长文本新闻数据 250w):

Weak-AND
Weak-AND 在广告或推荐等小数据集召回场景下,已经有较多的应用。在海量数据检索中,TurboSearch 正探索其在 长 Query 召回场景 下的应用。通过结合 Weak-AND 与 AND,平衡召回率和检索性能。
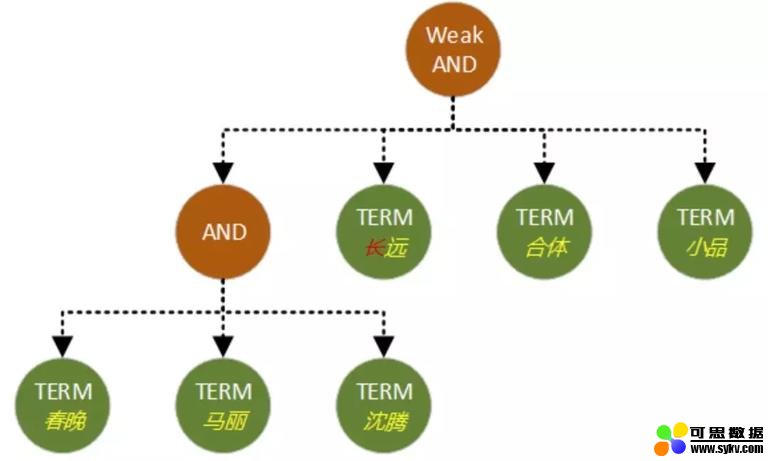
Weak-AND 的性能优化和场景探索将持续进行。
倒排性能优化
** 求交召回过程中,倒排的索引结构设计,对求交耗时影响较大。** 内存实时索引倒排在设计上具有以下特性:
-
倒排索引需要支持 高性能同时读写,写入新文档和读取倒排求交的能力。
-
需要写入 共享内存 避免进程停止导致索引需要重新加载。
- 本文地址:http://www.6aiq.com/article/1578466356903
- 本文版权归作者和AIQ共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出
- 知乎专栏 点击关注
-
倒排链中,存储块越多,性能越差,尽量避免倒排块数量过多。
TurboSearch 对内存倒排索引做以下设计:
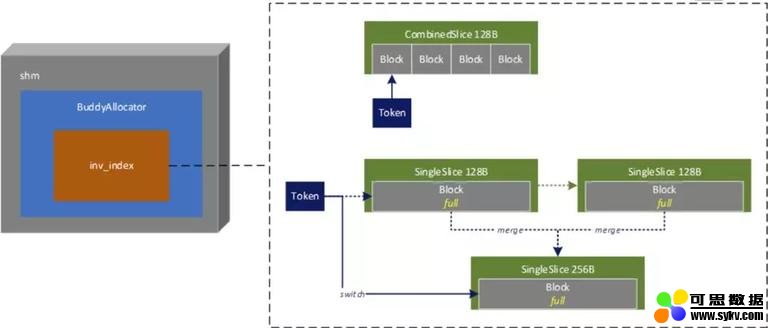
其中:
-
BuddyAllocator 单线程运行, 分配释放处理能力达 1000w/s。
-
分超小块 CombinedChunk 和普通 SingleSlice,解决超短倒排存储率问题。
-
小块 SingleSlice 合并为大 SingleSlice,解决超长倒排中倒排块过多问题。
对比老架构固定块倒排索引:

4. 多粒度索引
不同于 N-gram 这种暴力索引方式,多粒度索引专注于文档与 Query 中的隐性词组发现,对正常分词补充。检索时先进行粗粒度词召回,如果粗粒度无结果或结果偏少,将再次进行细粒度词召回。通过这个方式来解决松散召回导致的紧邻结果截断问题。
如 “海底捞万象城店” 对应的粗粒度索引为 “P: 海底捞 万象城 店”,保证结果能紧邻命中召回,如果在粗粒度检索无结果时,将再次使用 “海底捞”、“万象城”、“店” 进行检索召回。既保证了准确性,也能兼顾召回率。
5. 海量数据索引支持
对于海量数据搜索业务场景,脱胎于网页搜索的 TurboSearch 继承三种类型的索引集群结构:
-
FOB,全内存索引,支持实时增删。
-
GOB/NOB,内存倒排 + 正排,磁盘摘要,不支持实时增删。
-
WOB,磁盘索引,不支持实时增删。
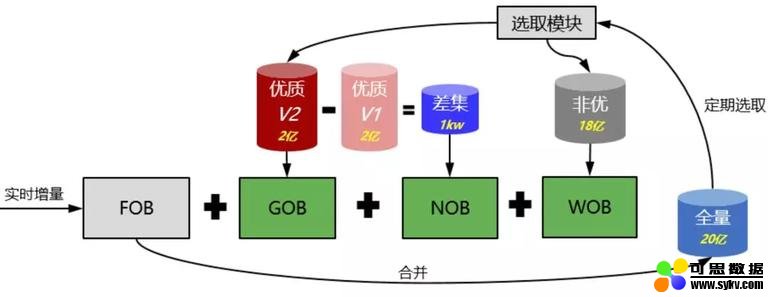
根据不用搜索业务数据场景需求,可将各类索引集群组合达到设计目标。
6. 核心逻辑功能插件拓展
TurboSearch 引擎考虑到自定义功能开发拓展,目前对以下核心功能做了插件支持:
-
过滤库 filter
-
打分库 score
-
求交 intersect
-
语法树 syntax
-
分词库 segment
7. 私有化部署
TurboSearch 整体设计上支持私有化部署。 在公司内网环境运营时,可使用已有的服务组件,如 CL5(名字服务)、Sumeru(资源管理) 等。然而在私有化部署场景下,这些公共服务难以一同打包部署。 因此 TurboSearch 对这些功能 均有 内建相应能力,可选择使用, 并基于以下设计支持私有化实现:
-
开发和部署上,较少的内部环境和外部项目依赖。
-
从运营系统、DB 环境、服务模块均可支持 Docker 部署。
-
完善独立设计的路由管理和资源管理。
四. 系统运营
1. 离线、在线运营架构
以较小数据量的 FOB(实时内存索引系统)集群为例 ,离线、在线运营系统通过以下设计保证稳定持续服务:
-
全量数据平滑无缝版本更新,确保线上服务 不受数据滚动影响。
-
实时数据与全量滚动无缝衔接,确保滚动 不会导致实时数据缺失。

2. 干预系统
在现网运营中,检索召回排序无法保证所有 Query 达到最佳。对于一些突发高曝光 Badcase,需要有 临时干预能力。TurboSearch 在接入层设计了干预系统,并沉淀积累了大量干预策略,可覆盖现网运营大部分干预需求。** 主要支持两大类干预类型:
-
通用干预规则,系统预先定义和实现了具体的干预处理逻辑。
-
自定义干预规则,提供干预规则的读写接口,满足不同业务的特定干预需求。

3. 全流程检索、数据诊断
在持续优化的海量数据搜索业务运营过程中,会有持续或突发的 Badcase 需要定位。** 而一个海量数据搜索业务中,一般都是 多集群、多机服务、多层逻辑 的复杂系统。在整体系统中定位和诊断 Badcase 是一个复杂而困难的工作。** 比如一篇文档未被召回有以下多种可能:
-
文档数据入库问题,某些原因数据被删除或未入库。
-
求交篇数阶段问题,由于在线检索考虑耗时和性能问题,无法做到全求交召回,召回太多被截断。
-
求交超时截断问题,出于耗时限制,超高频词之间的求交过程常常会出现超时截断。
-
L1 打分低未进入 L3,L1 取 Top300 进入 L3,因此 L1 打分过低可能导致无法召回。
-
L3 打分低被合并截断,每一层检索转发 access 服务均会对召回结果按照打分取 TopN 截断返回。
-
L4 打分低或被过滤,多集群召回融合打分会丢弃掉一些文档。
-
语法树本身无法召回目标文档,下发的语法树全求交也不可能召回目标文档。
-
…
一篇文章有如此繁多的漏召回可能性。TurboSearch 从在线服务模块和离线数据流程两个方面入手,设计全流程的诊断,来协助快速定位召回和数据问题。
五. 应用场景和展望
** 目前 TurboSearch 已可应用在 传统文本搜索、关系链搜索、LBS 位置相关搜索、中心聚类向量搜索 等场景。** 在持续改进引擎现有功能之外,我们还会做更多的探索:
-
持续优化 WAND 检索性能,以及分析拓展其使用的 Query 场景。
-
探索基于倒排索引,引入 知识实体的链接类搜索,比如搜索 “腾讯总办”,可从索引层面召回相应结果。
-
在 多模态 / 向量检索 领域,探索新结构索引,比如图式、树式索引来优化向量检索性能和效果。
-
逐步开源开放整个引擎,并构建协同开发生态。

时间:2020-01-18 23:59 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]删数据,还要删AI模型:美国科技公司遭遇最严厉
- [机器学习]入学试可用手机找数据 日本大学考核学生思维
- [机器学习]英伟达的DPU,是想在数据中心奇袭英特尔?
- [机器学习]阿里开源3D-FUTURE数据集 建模时间可从3小时降至10秒
- [机器学习]MIT研究人员发现 ImageNet 数据集存在系统性缺陷
- [机器学习]NVIDIA针对数据不充分数据集进行生成改进,大幅
- [机器学习]数据集永久下架,微软不是第一个,MIT 也不是最
- [机器学习]Gartner发布2020年数据与分析领域的十大技术趋势
- [机器学习]NVIDIA针对数据不充分数据集进行生成改进,大幅
- [机器学习]数据科学vs.机器学习:有什么区别?
相关推荐:
网友评论:















