跨境电商 Etsy 如何使用交互行为类型进行可解释
“ 本文介绍了跨境电商 Etsy 如何利用用户历史交互行为的类型 (如浏览,喜欢,收藏,加购,购买等) 来完善物品的 embedding 表示,并进行可解释推荐。在离线和在线实验中均验证了引入交互类型信息后对于建模用户行为的准确性有提升。”
背景和介绍
工业级的推荐系统已成为影响电子商务网站用户体验的基石。对于拥有超过 5000 万个手工艺品和古董的在线交易网站 Etsy 来说,用户越来越依赖个性化推荐系统从海量的物品中寻找相关物品。
和众多电商网站类似,在 Etsy 中用户可以产生丰富的交互行为,包括浏览,喜欢,收藏,加购以及购买等。
如果场景中不包含多种行为类型,或者某种行为类型过于稀疏的话,可能也不太适合这种方法
通常我们认为用户产生的不同行为表达了对物品的不同意图,因此除了使用用户历史上交互过的物品信息外,历史行为的类型也是需要考虑的因素。

相似推荐和相关推荐
如图所示,对于同样的目标物品,一盆绿植,对于看过该物品的用户,我们倾向于为他推荐相似的物品,可以作为替代的物品。对于购买了它的用户,我们倾向推荐一些小摆件,或者花盆等相关的物品。
这也是我们通常说相似推荐和相关推荐,仔细想想两者的区别~
本文提出了一种学习基于交互类型的物品表达的方法,除了得到包含物品的共现模式信息外还包含交互类型的共现信息。因此相比于传统的仅仅考虑物品信息的方法,本文的方法更加灵活和具有普适性,并且能够提供诸如“由于你收藏了 A, 所以猜测你想要购买 B”这样的推荐理由。
得到的 embedding 提供了一种很方便的方式来使用内积近似(物品 - 交互)pair 共同发生的概率,这种方式可以用于推荐系统中召回环节。
最后在 Etsy 数据集和在线实验中均验证了考虑行为交互类型后对于建模用户行为的准确性确实有提升。
方法介绍
本文的方法可以看作是在传统的 item2vec 基础上引入用户交互行为的类型,从物品维度的向量表达扩充为【物品 - 交互类型】pair 维度的向量表达,并根据交互类型的偏序关系使用合适的负采样技巧。
简单来说,就是把 item2vec 换成了 (item-interaction_type)2vec,并对负采样做了相应调整。
基于交互类型的 Embedding 学习
设代表物品集合,代表交互类型。对于每个在 Etsy 上访问的用户,都会产生如下的【物品 - 交互类型】pair 例如: 浏览喜欢购买 以上交互序列表明用户先浏览了物品,然后喜欢了物品,最后购买了物品.
给定一个物品 - 交互二元组, 则出现的概率为
这里和分别是 pair 对的输入和输出表示向量,m 是上下文窗口数量。
负采样优化
由于全体物品集合数量很大,使用负采样技巧来加速模型的训练。与传统 item2vec 依据物品热度采样不同的是,本文使用了一种考虑交互类型偏序关系的负采样方法。
定义一个偏序。对于每个 Session 中出现的物品 - 交互二元组,我们添加这样的负样本,其中且。
举例来说,如果一个物品被浏览且加入购物车,那么针对该样本我们会构造一个类型为购买的负样本。
这种方法存在的一个缺点是构造出来的负样本都是不包含浏览类型的。为了解决这个问题,对于每个只有浏览行为的物品,我们额外构造两个负样本和。其中和是从与相同的类目中均匀采样得到的,这样可以捕捉到相同类目下的用户偏好的物品。
embedding 空间下的近邻检索
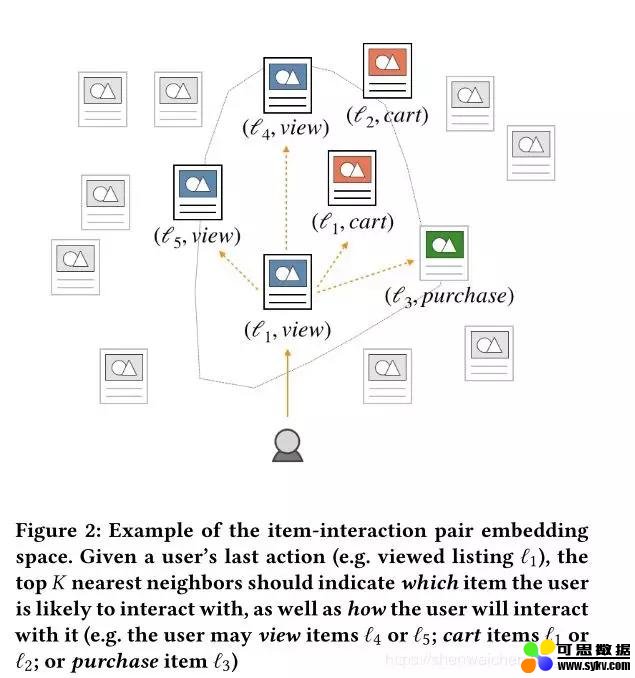
【物品 - 交互】pair 的 embedding 空间示意图
给定一个用户的最后一个动作,图中是,其在 embedding 空间的 topk 个近邻表示用户可能会产生交互的物品和相应的交互类型。(根据图示,用户可能浏览物品或,加购或购买)
- 本文地址:http://www.6aiq.com/article/1578220891041
- 本文版权归作者和AIQ共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出
- 知乎专栏 点击关注
实验和结果
实现细节
数据使用了 2017 年 11 月到 2018 年网站用户访问日志。筛选了包含 pair 对数量大于 3 用户 Session 来避免噪音数据的干扰。
文章使用了 facebook 开源的 fastText 库来训练得到 embedding。
上下文窗口 5,维度 100,除了上述负采样方法,每个序列中额外随机添加 5 个负样本。
离线评估
以下两种方法是本实验选取的 baseline
-
基于共同购买行为的 item cf,目前是 esty 中的主要召回来源
-
不考虑行为类型的 item2vec 召回
hit rate 和召回数量关系图

hit rate 和召回数量关系图
横坐标是召回的结果数量,纵坐标是购买行为的平均 hit rate。
可以观察到,基于浏览交互行为产生的候选集的 hit rate 高于其他几种方法,包括超越了基于共同购买的 itemcf(当召回候选集数量足够多时)。尽管基于浏览交互的模型在候选集数量较少时弱于共同购买 itemcf,但是得益于其探索性,能够在扩充候选集时提升平均 hit rate。这也是 itemcf 的一个弊端,召回的头部物品表现良好,尾部物品表现较差。
另外普通的 item2vec 在几种方法里具有最低的 hit rate,这也说明了学习【物品 - 交互】pair 的 embedding 相比于单纯学习物品的 embedding 能够在召回结果中包含更多的最终被购买的物品。
不同任务目标下的 hit rate 相对变化 (相比于传统 item2vec 提升百分比)
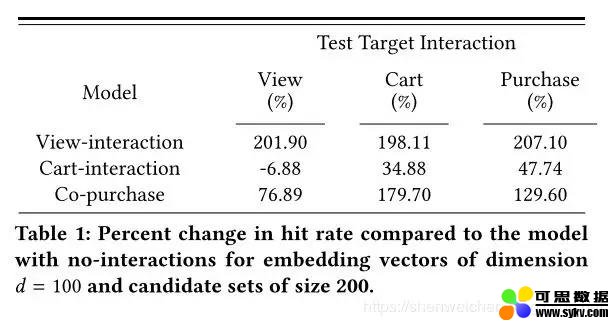
不同任务目标下的 hit rate 相对变化
我们观察到,在所有我们考虑的任务目标上(浏览,加够,购买),浏览交互模型胜过无交互模型 (传统 item2vec) 以及所有其他模型。仅当测试目标互动是加够或购买时,加够互动模型才表现出优于无互动模型。但是,并没有超越基于共同购买的 itemcf。作者认为是由于训练数据中加够互动的稀疏性,导致学习得到 embedding 效果不理想。
物品覆盖率和流量覆盖率
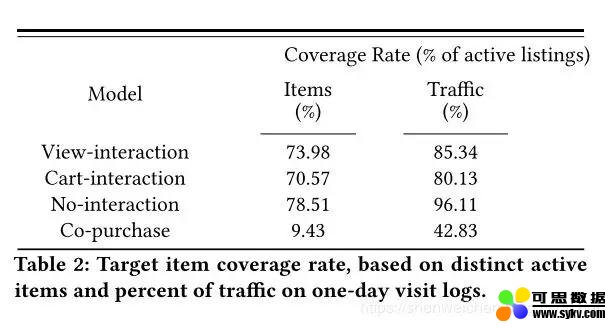
物品覆盖率和流量覆盖率
基于共同购买的 itemcf 由于数据稀疏性存在的一个缺点是其召回结果的覆盖率相对较低。从上表中看到其覆盖率为 9.43%。基于物品 - 交互和无交互的方法至少能够覆盖 70% 的物品,同时也服务于超过 80% 的流量。
itemcf 依赖历史共现数据,item2vec 等方法具有一定泛化性,因此能够召回一些 itemcf 无法召回的结果。
在线实验
在线实验使用了 50% 的流量进行了 7 天的 ab test。对照组使用了不考虑交互类型的用户最近的 100 个交互物品进行召回,实验组使用了两个模块,【View-Interaction】模块使用用户最近浏览过的 4 个物品进行召回,【Cart-Interaction】模块使用用户最近加购过的 4 个物品进行召回。
这里我有个疑问是对照组使用最近 100 个行为,实验组使用最近 4 个,这样的话最近 100 个行为会不会由于包含了时间久远的行为而引入一些噪声呢?

对照组
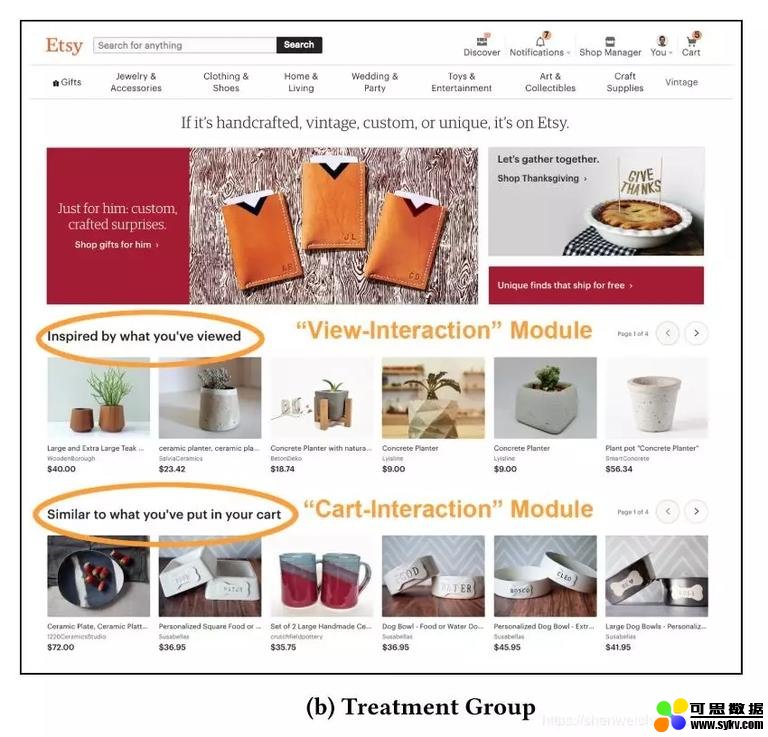
实验组
相比于对照组,实验组的【View-Interaction】模块带来 4.1% 的点击率提升。整体带来了 0.20% 的下单率和 0.31% 的结账率提升。
总体来说,本文提出的方法并不复杂,主要解决的是改进了利用传统的 itemcf 或 item2vec 进行召回时候不便同时利用多种不同类型的交互样本的问题,并在此基础上根据交互类型为推荐结果提供一定的解释性,同时也缓解了某一特定类型交互行为过于稀疏的问题。
参考文献
- Learning Item-Interaction Embeddings for User Recommendations(https://arxiv.org/abs/1812.04407)

时间:2020-01-18 23:58 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















