NLP 技术在微博 feed 流中的应用
导读: 新浪微博截止 2019.9 统计的数据,月活跃用户数为 4.97 亿,日活跃用户数为 2.16 亿,其中约 94% 为移动端用户,今天会和大家分享新浪微博在 feed 流中遇到的 NLP 问题和解决思路。主要包括:
❶ 难点与现存问题
❷ 标签系统
❸ 物料库
❹ 多任务、多模态探索
❺ 大规模预训练模型技术
——难点与现存问题——
❶ 博文内容大多比较短
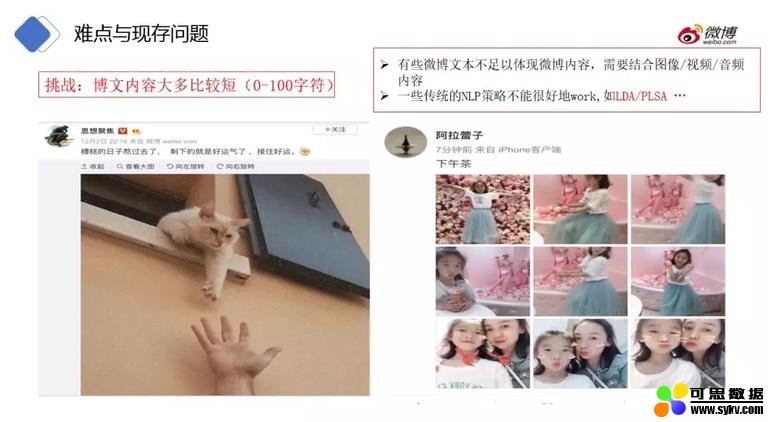
第一个问题,微博的内容都是比较短的 (一般都是 100 字符以内),比如右图中提到文本 “下午茶”,但是图片内容并不是美食 “下午茶”,考虑整个微博文本和图片内容应该分类到美女频道而不是美食频道更合适。另外对于短文本使用 LDA/PLSA 等 topic model 效果都不太好。
❷ 语言表达随意化
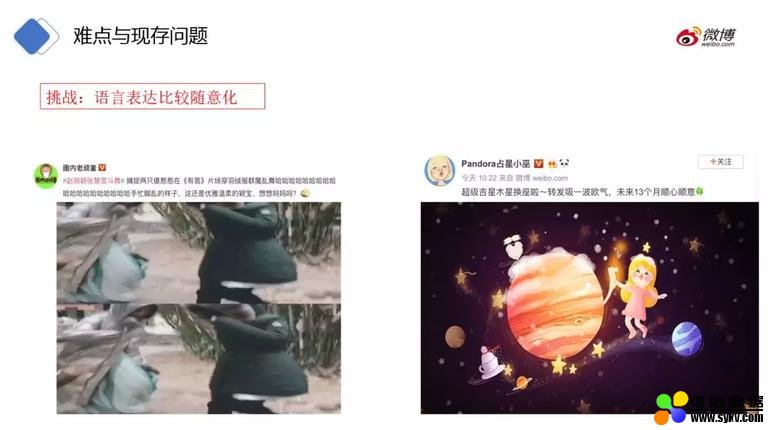
第二个问题,文本的随意化和口语化,语法结构不严谨,对于内容分析带来较大挑战。
❸ 用户搜索行为序列不能准确获取
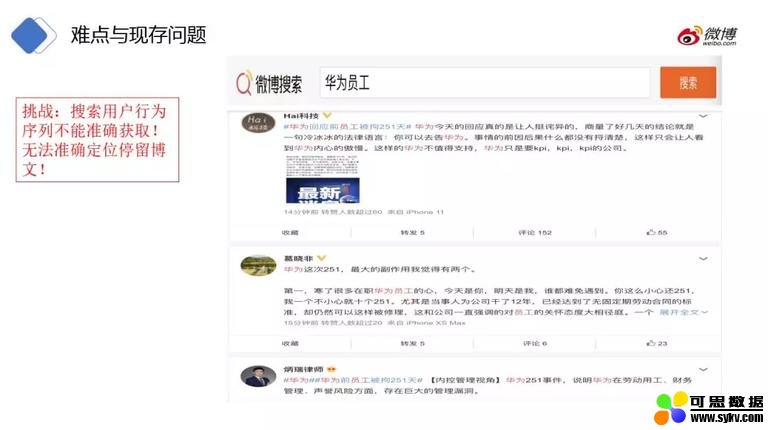
第三个问题,比如:在微博搜索结果页中,由于文本简短,大部分的结果在页面中能看到全文,没必要点击进入看内容 (除了第二条,需要点击展开全文),而从停留行为来看,由于一页展示多条博文,也不能准确定位用户感兴趣的是哪条微博。
❹ 用户 feed 行为序列不能准确获取
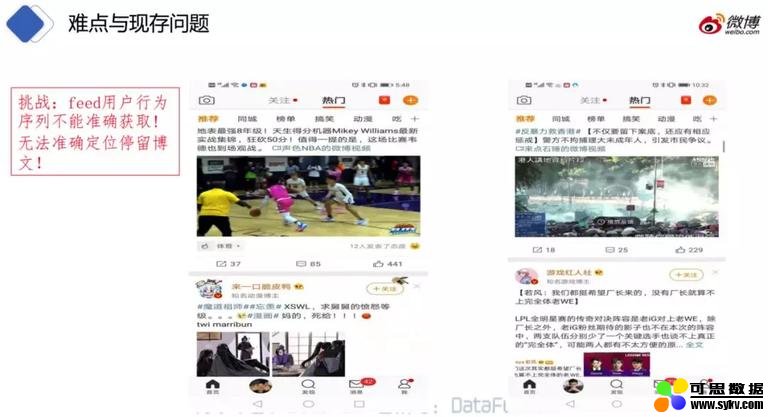
这个问题与搜索结果页相似,用户停留在 feed 流的页面中,不能准确区分哪条微博为用户感兴趣的。我们对点击较高的博文分析发现,点击较高的博文很多包含多张图片。由于一条微博可以包含多张图片,部分高点击的博文是由于用户想查看图片的内容才点击进入微博的正文页,但是这样的点击不能代表用户对该博文感兴趣。
综上所述,目前的微博场景很难获取十分准确的用户行为序列 (用户行为序列包括展示页,点击,停留,转发,评论,赞,收藏等),导致使用 LDA/PLSA 主题的方式和用户行为序列方式建模效果都不太好。接下来,将为大家分享下我们的解决办法和思路。
——标签系统——
标签系统主要包括:博文标签、用户兴趣 ( 画像 ) 标签、博主标签。今天主要介绍博文标签和用户兴趣 ( 画像 ) 标签。
❶ 博文标签
博文标签,主要分为:一二级标签、实体标签、关键词标签。
① 一二级标签

一级标签: 对应频道,例如财经,法律,IT 产业,军事,历史,美食等标签。
二级标签: 一级标签 “财经”,包含的二级标签:投资,众筹,货币,股票,保险,债券,基金,贷款,美股等。
一二级标签运用: 一级标签与少量的二级标签和垂直频道对应,打上这部分标签的博文会分发到对应的频道下,对应的博文会在该频道进行展示。其次一级和二级标签也可用于画像的构建以及推荐中的召回和排序,但是作为标签,粒度太粗,不能很好的刻画用户兴趣。比如,有的用户只对英语感兴趣,如果把大量的教育相关的博文推荐给他,用户体验会比较差。
一二级标签分类系统:
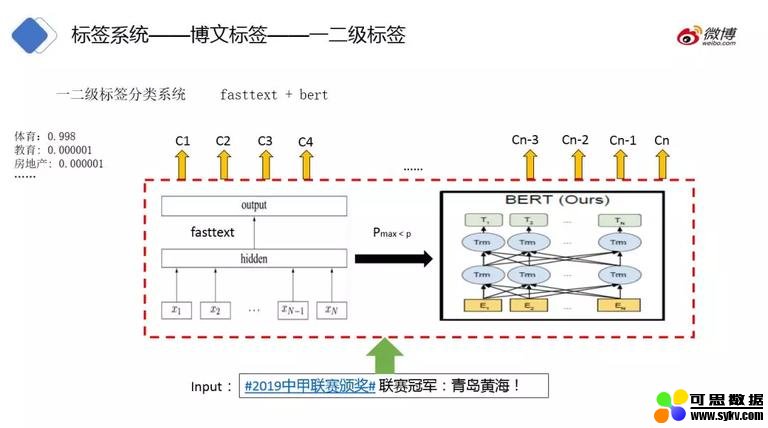
目前分类系统使用 fasttext+bert 结合的方案,是由于 bert 效果好,而 fasttext 性能好。我们有如下的方案:针对关注度高 (明星) 和高质量的博文使用 bert,其他的博文先过一遍 fasttext,若标签得分高于阀值 (95 分),则不再使用 bert 进行处理;若最高得分只有 70 分,那么使用 bert 再预测一次。Bert 是一种多层的编码器,最近的研究表明,bert 不同层的 embedding 捕获到了不同的句子知识。比如底层 embedding 捕获到词法方面特征,中间层 embedding 捕获到句法特征,高层 embedding 捕获到语义特征。因此,我们对 bert 的结构做了优化,使用对各层 embedding 加权后获得的 embedding 作为整个博文的表征,后续的博文质量模型也是这种做法。
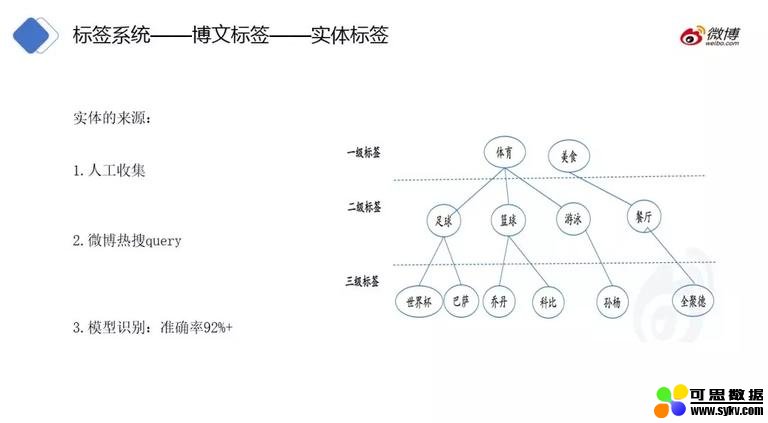
② 实体标签
实体标签在我们的场景中也叫三级标签,实体标签的来源:人工收集、微博热搜 query 和模型识别。如下图可看到一二级标签和实体标签之间的关系。
实体识别模型:
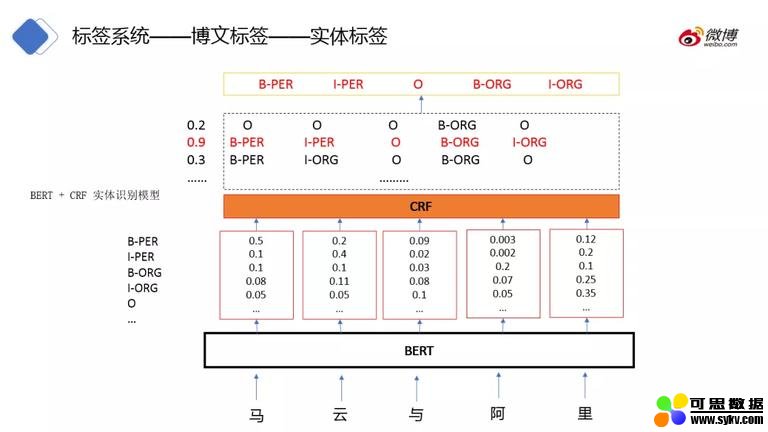
模型如图结构所示,首先经过 bert 层输出每个词对应每个序列标注的概率分布,再经过 crf 层输出最终的标注结果。而这些序列标注的训练数据是由人工标注的。
③ 关键词标签
关键词来源为两块:名词短语和用户 query。这是由于博文的文本较短所决定的 (90% 以上都是 100 个字符以内),使用传统的主题模型方式并不奏效。
a. 名词短语抽取
首先我们先从名词短语抽取关键词说起,我们可从某个句子中获取依存句法相关信息。
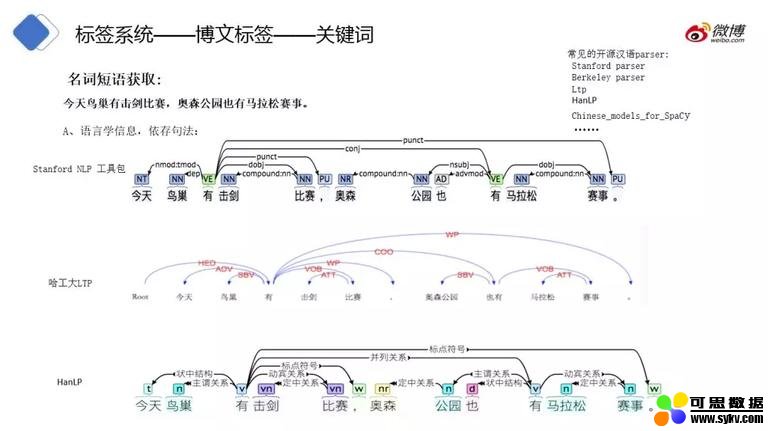
如上图所示,有 Stanford NLP、哈工大 LTP 和 HanLP 等工具包可以获取句子的依存句法,可以根据多个 parser 解析出来的依存句法对名词短语进行提取,例如,击剑、比赛两个词。首先在 stanford NLP 中击剑、比赛为一个名词短语且在一个语块 (chunker) 下,同样其他依存句法工具也是击剑、比赛都为名词短语并且都为同一个语块 (chunker)。这样多个句法分析工具输出结果都是一致的,我们就认为击剑比赛可以作为标签使用。

其次也可以从不同的分词结果对名词短语进行提取和校验。通过下列方式可以获取多个不同的分词结果:
❶ 同一个分词器不同的分词粒度。
❷ 同一个分词器 nbest (其它可能) 的结果
❸ 不同的分词器
使用不同的分词结果可以用于做名词短语提取正确性的校验。下文我们会详细阐述提取规则。
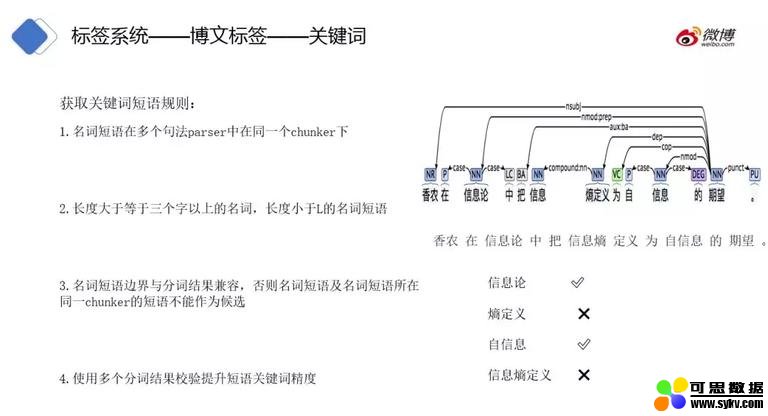
我们提取关键词短语有如下规则:
❶ 名词短语在多个句法 parser 中,在同一个 chunker 下,例如 “击剑比赛” 三个工具输出都是同一个 chunker。
❷ 长度大于等于三个字以上的名词,长度小于 L 的名词短语,不宜太长 (实际操作中长度不超过 6)。
❸ 名词短语边界与分词结果兼容,否则名词短语及名词短语所在同一 chunker 的短语不能作为候选 。例如我们使用 Stanford NLP 依存句法结果与一个分词结果做兼容,依存句法结果:香农 / 在 / 信息论 / 中 / 把 / 信息 / 熵定义 / 为 / 自 / 信息 / 的 / 期望 ,分词器的结果:香农 / 在 / 信息论 / 中 / 把 / 信息熵 / 定义 / 为 / 自信息 / 的 / 期望。
可得到如下结论:
-
“信息论” 依存句法和分词都是同一个词说明兼容;
-
“信息熵定义” 依存句法分割为 “信息” 和 “熵定义”,而分词结果为 “信息熵” 和 “定义”,这两个切分的边界不一致。即依存句法边界在信息、熵的中间,而分词边界在熵、定义中间说明与分词不兼容。若依存句法为信息 / 熵 / 定义,那么熵、定义是拆开的,边界算是与分词保持一致,那么 “信息熵” 则与分词结果兼容;
-
“自信息” 依存句法为 / 自 / 信息 /,分词结果为 / 自信息 /,这里虽然依存句法自、信息被拆开了,但是与分词结果 “自信息” 是兼容的。
-
“信息熵定义”,依存句法结果为 / 信息 / 熵定义 /,分词结果为 / 信息熵 / 定义 /,因为分词结果 / 信息熵 / 定义 / 是拆开的,并且依存句法拆分不一致所以与分词结果不兼容,除非依存句法与分词结果拆分一致都为 / 信息熵 / 定义 /,那么才说明与分词兼容。
❹ 使用多个分词结果校验提升关键词精度

最后,我们可根据以上所说的实体识别和名词短语规则将博文中词语提取出来做为关键词的候选。
**b. **用户 query 提取
用户 query 作为关键词的条件:
❶ Query 必须为高频
❷ 需要限制长度,不易太长
❸ 另外,query 会存在边界错误的情况。可使用新词发现的方式,通过左右信息熵和紧密度进行噪音过滤。
c. 匹配算法:

首先,我们可以使用高效匹配算法,Trie 树 /Hash table、Double array trie (dat)、AC 自动机 (三者中 AC 匹配效率最高 ), 500w+ 的词典通过这些匹配算法,在博文上进行匹配。接着我们使用分词工具对文章进行分词,来校验分词的结果边界是否与匹配算法的结果兼容,输出最终兼容的结果。
- 本文地址:http://www.6aiq.com/article/1577441806595
- 本文版权归作者和AIQ共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出
- 知乎专栏 点击关注

其实该方法与上文说的提取名词短语思路相似,例如:关键词为 “史记”,而文中为 “历史记录”。在使用匹配算法时会将 “历史记录” 中的 “史记” 匹配上,但是经过分词工具时,分出来历史 / 记录,而史记被分开,“史” 与 “历” 链接,没有单独成块,同时 “记” 也与 “录” 链接,那么可以判定与其不能兼容。
有的同学会问,如果把关键词 / 实体词典加入分词用户词典,是不是同时解决了匹配问题和消歧问题?其实这是很难做到的,因为一般的分词词典词汇量约 30-50 万,分词的过程本身就是对句子消歧的过程,在分词的过程中往往借助词频、词性等其它信息,关键词 / 实体词 500W+,远超分词词典中词数量,如果放入分词用户词典,这些词会在匹配之后,在分词结果中保证不会被切开 (不同策略有所区别),将对分词的效果产生很大的负面影响。
d. 相关性

使用匹配算法和分词验证兼容性得到以上关键词,其中天龙八部、新笑傲江湖等是和电影相关的词,但是与博文中的主题相关性不一致 (主题是旅游),由于关键词需要映射到用户画像上来统计用户兴趣,这些词不能代表用户的偏好。
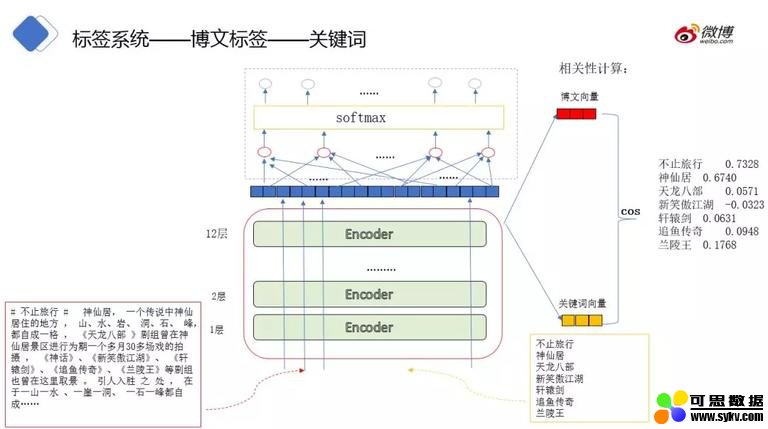
标签与博文的相关性计算流程为:获取文本向量 -> 向量相似度计算 -> 设置阈值过滤标签。其中,我们使用 bert 获取文本向量,博文和标签 (关键词) 分别以字的形式输入至 bert 模型中,对模型最后一层的每个字相加求均值,效果最好 (不同文本相似度计算任务向量取法有所区别,有的任务取最后一层 cls 的向量效果较好)。我们用于计算相似度的 bert 模型是基于博文的分类 fine-tuning 结果的模型。
除了标签还进行了同义词、近义词和上下文词的挖掘,这里不展开做过多阐述。
④ 博文 embedding 标签
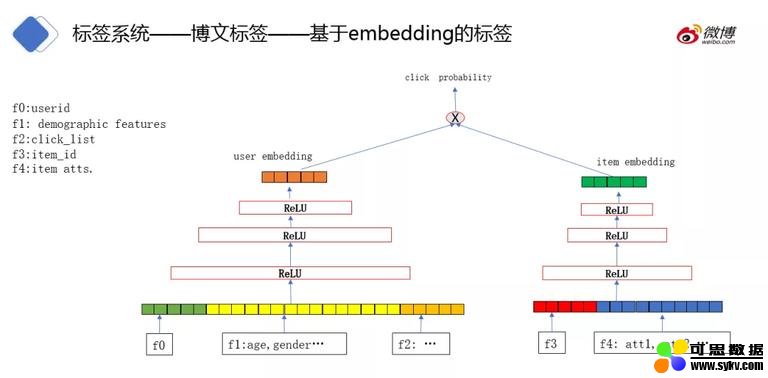
Embedding 标签通过用户的点击序列建模获取。模型如图所示,特征为 f0: 用户 id,f1: 用户的自身属性,f2: 用户点击列表,f3: 博文的 id,f4:博文自身属性,label 为是否点击博文。如前文所述,用户的行为序列不能十分精准的获取,所以 embedding 的效果并不好。
以上就是基于博文的一些打标签的方式,下面我们再来讨论一下基于用户方面的标签。
❷ 用户兴趣标签

**① **首先是基于模型 embedding 的用户兴趣标签: 上文中有介绍,此方法效果不太好。
② 基于统计的标签:
❶ 标签可以分成三种类型,分别为长期、短期和即时。分别进行统计,就有了不同类型的标签,可用于做召回或者排序模型的特征。
❷ 关键词用户兴趣标签的特征有以下两个方面:一是,关键词在特定的用户行为中的曝光率、互动率、转评赞率和平均停留时长;二是,关键词在全量用户行为中的曝光率、互动率、转评赞率和平均停留时长,用来表示在大众整体的偏好,可用于排序的输入特征。
❸ 将用户生成博文 embedding 映射到用户兴趣标签中。
❹ 在以上计算用户兴趣的标签时,会用到一些平滑的策略。
——物料库——
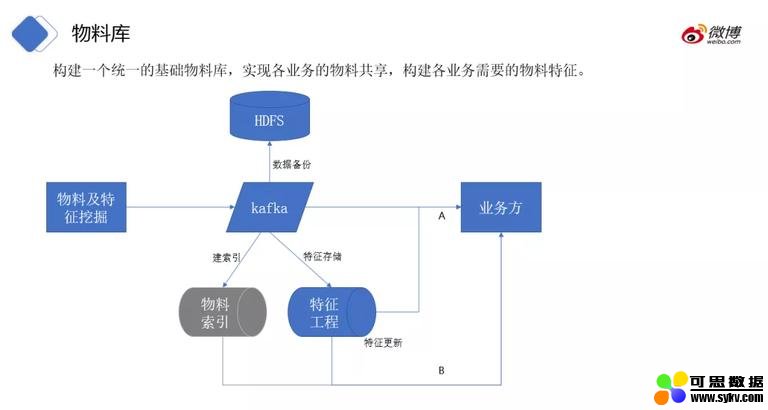
对用户发博的博文做预处理,最终构建一个统一的基础物料库,实现各业务的物料共享,构建各业务需要的物料特征。
❶ 段子识别模型
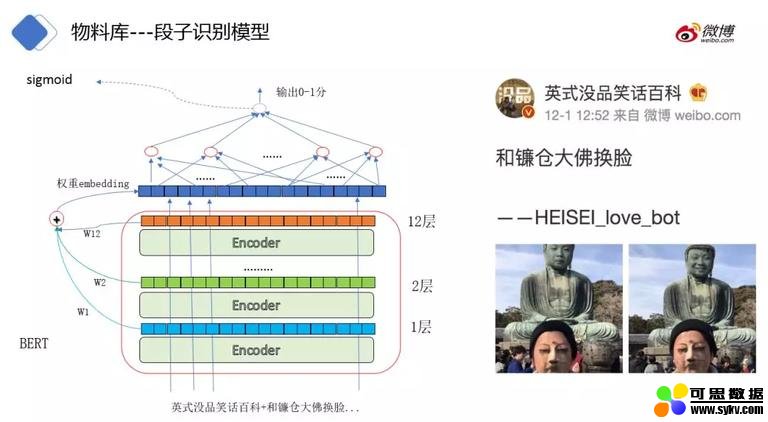
各层的权重在训练过程中优化获得。在权重 embedding 的基础上进行 reduce_mean 操作获取到最终的 embedding 表示,进行 sigmoid 操作获取到相应的概率分数。我们基于人工标注的数据进行 bert 的 fine-turning。
❷ 物料评级模型
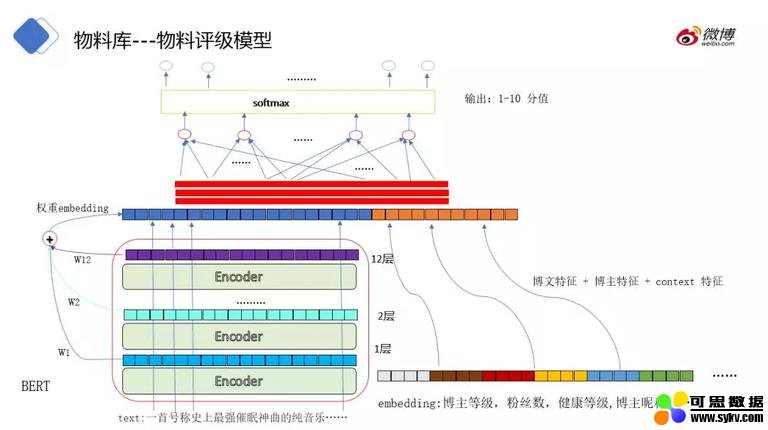
物料评级模型分成两块:一块是博文的内容,使用 bert 进行文本向量的抽取;另一块为博主的特征和上下文特征 (博主发博的上下文),比如博主等级,粉丝数,健康等级,博主昵称等,把相关特征拼接在一起,进行多分类。
——多模态——
上文也介绍过,对于文本较短的博文,我们没法获取太多的信息,这样需要借助多模态信息。
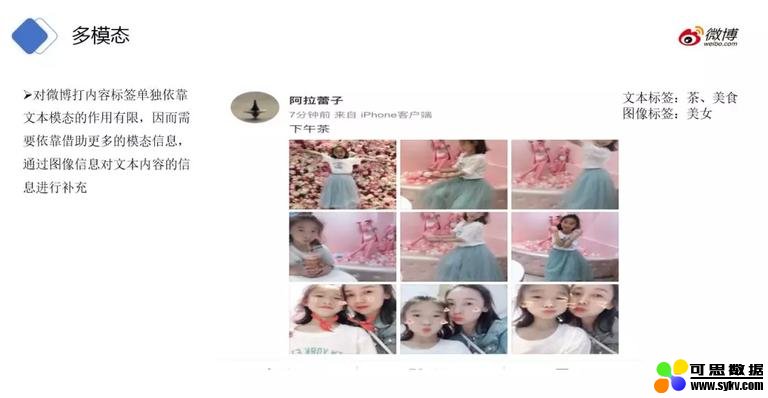
比如通过图像信息对文本内容的信息进行补充。那么通过该图像模态,我们可以打上美女这样的标签。
博文中出现了苹果,可能指代吃的苹果或者苹果公司。若借助图像可一目了然去除歧义。
❶ 多模态对偶模型
上图是在 BERT 发布之前的做法:多模态对偶模型,其中文本编码使用 lstm 模块,图像编码则使用 Inception-Resnet-V2 模块。两者编码对齐到同一个长度进行 attention-both 计算,之后两个模块分别与文本编码和图像编码进行加权计算,然后向量 add 输出多模态向量,最后解码进行标签分类。Attention-both 可以这样理解:由于 image、文本都编码为语义向量,单独的使用文本进行解码时,可以利用图片的 attention 信息,而单独使用图片解码时,可以利用到文本的 attention 信息,Attention-both 就是这两者的结合。模型效果相对于文本模型有一定的提升,但是性能会比较慢。
❷ BERT 多模态模型
① 预训练模型
BERT 出来之后,微软发表了图像结合 BERT 的多模态预训练文章。
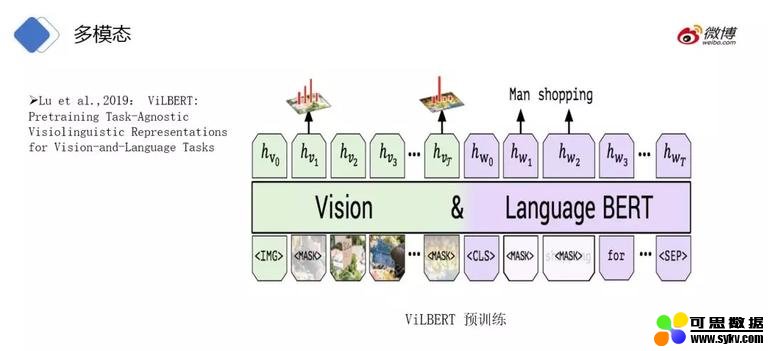
其预训练除了文本还加入了图像的部分。首先把完整的图像做切分 (Fast RCNN),每个为一个个小块图片,并且做 mask 输入到模型中进行预测还原。
文本和图片的向量融合再进行预训练,输出文本和图片的联合向量 。联合向量可用于相似博文的召回和根据博文内容来检索相似图片 (自动配图)。
② 多模态打标签
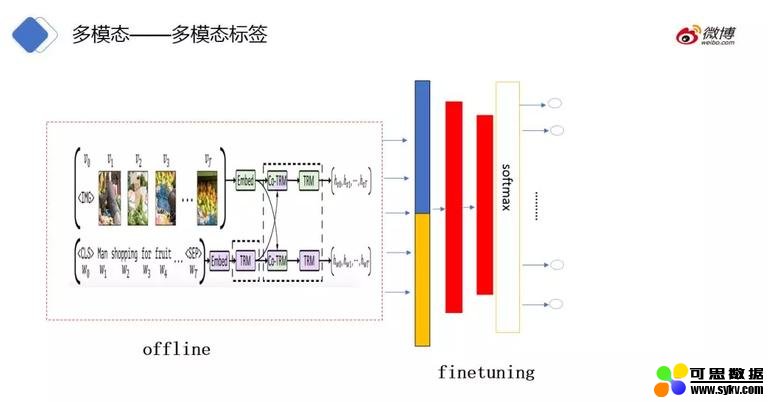
我们也尝试在多模态预训练之后做打标签的任务,预训练的向量之后进行多分类的 finetuning。
——多任务——
对比之前版本的质量模型,多任务新增了 ctr 和停留时长的任务。整体效果会有些提升。
——大规模预训练模型技术——
有以下两种模型:BERT 和 GPT2,而这两种模型是有区别的。BERT 主要做编码,对文本进行理解。GPT2 则为做生成任务,可辅助写作。杜则尧同学开源了基于中文的 GPT2 模型:
https://github.com/Morizeyao/GPT2-Chinese
感兴趣可以具体了解。
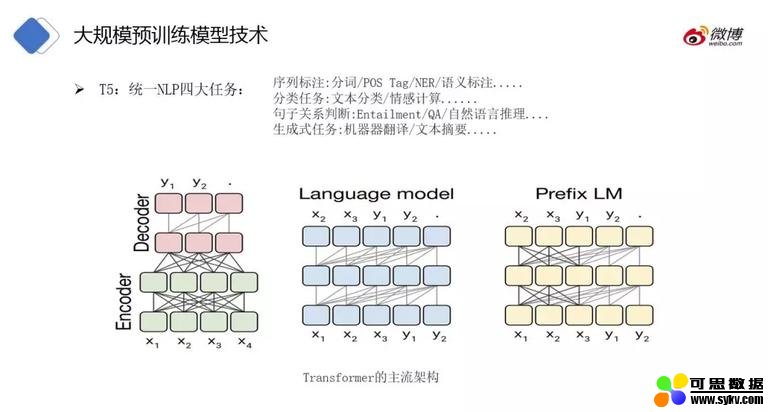
除了 BERT 和 GPT2,还有 T5。T5 整合了 NLP 的四大任务:序列标注 ,分类任务 ,句子关系判断 ,生成式任务。
我们目前在大规模预训练模型技术,做了以下几块工作:
❶ 实现了 GPT2 模型的训练和推理
❷ 同时也实现了 T5 模型训练和推理
❸ 由于模型参数太多,性能太慢,我们尝试了模型的蒸馏、量化和 Tensor RT 以便提升性能
❹ 由于 T5 训练时是大杂烩,把所有任务和内容放在一块训练,我们认为把更相似的、可以相互影响的任务一起训练效果很更好
除此之外还孵化了以下几个项目:
❶ 机器翻译
❷ 复述系统
❸ 人工辅助写作系统
❹ 拼写纠错、语法检查和用词润色
——总结——
今天主要讲了新浪微博在 feed 流中遇到的 NLP 问题和解决思路。我们内部正与产品、架构团队积极沟通,以获取高精度的用户行为序列用于用户行为的分析和建模。由于博文较短,我们没有采用主流 LDA/PLSA 技术解决相关问题,而采用了更为传统的 NLP 技术和一些 trick 完成了实体 / 关键词的挖掘和相关性计算。
从技术来讲,随着预训练模型的出现,NLP 最近这几年取得了实质性的进展,但不可忽略的是:传统的 NLP 技术在某些场景下依然发挥着重要的作用。另外,一个技术趋势是在解决相关问题时逐渐从单一的技术走向多任务、多模态、多语言的融合。

时间:2020-01-01 01:01 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















