LR+FTRL 算法原理以及工程化实现
前言
在实际项目或者刷竞赛的时候,经常会遇到训练数据非常大导致一些算法实际上不能操作的问题。比如在广告行业中,因为 DSP 的请求数据量特别大,一个星期的数据往往有上百 G,这种级别的数据在训练的时候,直接套用一些算法框架是没办法训练的,基本上在特征工程的阶段就一筹莫展。通常采用采样、截断的方式获取更小的数据集,或者使用大数据集群的方式进行训练,但是这两种方式在作者看来目前存在两个问题:
- 采样数据或者截断数据的方式,非常的依赖前期的数据分析以及经验。
- 大数据集群的方式,目前 spark 原生支持的机器学习模型比较少;使用第三方的算法模型的话,需要 spark 集群的 2.3 以上;而且 spark 训练出来的模型往往比较复杂,实际线上运行的时候,对内存以及 QPS 的压力比较大。
我自己以前在刷竞赛的时候,看到别人使用过 FM+FTRL 的模型实现了一个 CTR 算法,印象很深。自己使用的是 DNN+Embedding 的方式做的一个算法模型,从理论上看 embedding 肯定比 one-hot encoder 的方式更加先进且能真实反馈特征数据的相关性,但是实际效果看对方的 FM_FRTL 得到的 AUC 比我高近一个百分点,而且可以在 10G 的数据上一个多小时跑完,而我的 DNN+Embedding 算法,因为没有 GPU 主机,跑一次需要十二个小时,严重影响了调参的积极性,这也是我非常想掌握 FTRL 的出发点。
更重要的是,考虑到刷竞赛与实际算法是否可工程化的的角度,FTRL 结合 LR 或者 FM 是一个非常好的方向,比 Top1 开源的代码使用了 PCA、NLP 处理特征以及多个模型 stacking 的技巧,更具有学习或者借鉴的价值。
本文主要根据谷歌给出的 FTRL 理论论文,以及 FTRL+LR 的工程化实现论文,从理论到工程化实现 LR+FTRL 的开发,任一后端开发人员都能根据文末给出的 python 代码,简单的开发就能实现一个简单、高性能、高可靠的 CTR 预测模型。
LR
关键概念点:
1.logistic distribution
2.几率
3.对数几率
4.损失函数
5.参数估计
6.误差计算
7.随机梯度下降
LR 数学原理
LR(logistic regression model) 是一种分类模型,我们通常都知道:

但是对其实际的数学原理却不是很了解。logistics regression 中的 logistic 指的是统计学中的 logistic distribution:
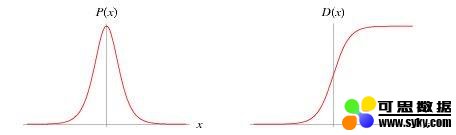
标准 logistic 分布密度函数与分布函数
可以说 LR 是线性回归模型通过 logistic 的分布函数,将预测结果映射到概率空间,进而预测不同分类的概率,其概率由条件概率 P(Y|X) 表示。
LR 模型既可以做二分类也可以做多分类,因为从事的是广告、营销行业的模型预估,本文只针对二分类的 LR 模型(binary logistic regression model) 做原理讲解以及模型工程化实现。
二分类的 LR 模型是如下条件概率的分布:


几率:如果一个事件发生的概率是 p,那么该事件发生的几率是发生的概率 / 不发生的概率:

对数几率:对几率取对数。

代入公式 (2) 和公式 (3) 得到:

可以看出 LR 也可以认为是用线性回归模型的预测结果来预测事件发生的对数几率。
LR 有很多优点,比如:
- 作为统计模型与机器学习的结合点,具有较好的预测结果以及可解释性。
- 直接对分类的可能性建模,无需事先假设数据的分布,这就避免了假设分布不准确带来的影响。
- 不仅预测得到分类,还有分类对应的概率,这对很多需要使用概率辅助决策的任务很有用。
- sigmod 函数是高阶可导的凸函数,具有很好的数学性质,很多数值优化的算法都可以直接用于求解最优解。
参数估计
损失函数
逻辑回归模型学习时,对于给定的训练集,可以使用极大似然估计法估计模型参数(将权重向量 w 和输入向量 x 扩充一位),设:


似然函数是:

对数似然函数:

这样逻辑回归的参数优化问题就变成了以对数似然函数为目标的最优化问题,也就是对公式 10 求最大值时的参数 w;
_ 实际应用中,通常是使用最小化损失函数的概念来寻找最佳参数空间,_ 所以对公式 10 取负号以及平均后得到逻辑回归模型的损失函数:

也就是我们常说的交叉熵损失函数,是一个高阶可导连续凸函数。根据凸函数优化理论,可以使用梯度下降法、牛顿法、trust-region 等方法进行优化。
以梯度下降法为例,计算 l(w) 的梯度为:

所以样本第 j 个参数的优化方式为:

所有样本的第 j 个参数更新方式为:

当样本数据里 N 很大的时候,通常采用的是随机梯度下降法,算法如下所示:
while {
for i in range(0,m):
w_j = w_j + a * g_j
}
随机梯度下降的好处是可以实现分布式并行化,具体计算流程是:
- 在每次迭代的时候,随机抽样一定比例的样本作为当前迭代的计算样本。
- 对计算样本中的每一个样本,分别计算不同特征的计算梯度。
- 通过聚合函数,对所有计算样本的特征的梯度进行累加,得到每一个特征的累积梯度以及损失。
- 最后根据最新的梯度以及之前的参数,对参数进行更新。
- 根据更新的参数计算损失函数误差值,如果损失函数误差值达到允许的范围,那么停止迭代,否则重复步骤 1。
工程化实现思路
主要是需要实现参数更新计算以及损失函数计算。
FTRL
相关背景
广告、营销、推荐行业传统的机器学习开发流程基本是以下步骤:
- 数据融合,获取训练以及评估数据集。
- 特征工程。
- 构建模型,比如 LR,FM 等。
- 训练模型,获得最优解。
- 评估模型效果。
- 保存模型,并在线上使用训练的有效模型进行训练。
这种方式主要存在两个瓶颈:
- 模型更新周期慢,不能有效反映线上的变化,最快小时级别,一般是天级别甚至周级别。
- 模型参数少,预测的效果差;模型参数多线上 predict 的时候需要内存大,QPS 无法保证。
针对这两个问题,一般而言有两种解决方式:
- 本文地址:http://www.6aiq.com/article/1577331013709
- 本文版权归作者和AIQ共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出
- 知乎专栏 点击关注
- 对 1 采用 On-line-learning 的算法。
- 对 2 采用一些优化的方法,在保证精度的前提下,尽量获取稀疏解,从而降低模型参数的数量。
传统的 LR 或者 FM 离线训练方法中,通常使用 L1 正则化的方法获取稀疏解;但是在线学习的时候,针对每一个样本的梯度下降方向并不是全局的,而是一个随机梯度下降的方式,简单的使用 L1 正则化并不能获得正确的稀疏解。
比较出名的在线最优化的方法有:
- TG(Truncated Gradient)
- FOBOS(Forward-Backward Splitting)
- RDA(Regularized Dual Averaging)
- FTRL(Follow the Regularized Leader)
其中 TG 截断比较武断;FOBOS 能获得较好的精度,但是稀疏性较差;RDA 算法会在牺牲一定的精度条件下,获得较好的稀疏性;而 FTRL 算法技能提高 OGD(online-gradient-descent)的精确度,又能获得更好的稀疏性。
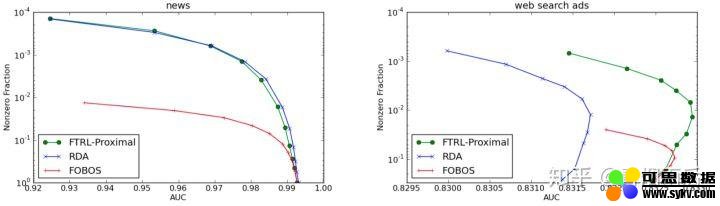
FTRL 与 RDA、FOBOS 对比
算法原理
参数权重更新
FTRL 算法权重更新公式为: 
由于  相对于 W 来说是一个常数,并且令 :
相对于 W 来说是一个常数,并且令 :

公式 15 等价于:

针对特征权重的各个维度将其拆解成 N 个单独的标量最小化问题:

公式 17 是一个无约束的非平滑参数优化问题,其中第二项  在
在  处不可导。假设
处不可导。假设  是其最优解,并且定义
是其最优解,并且定义  是
是  在
在  的次导数 _,那么有:_
的次导数 _,那么有:_

对公式 17 进行求导,并等于 0,有:

由于  大于 0,针对公式 19 分三种情况:
大于 0,针对公式 19 分三种情况:
-
当
 的时候:
的时候: -
如果
 ,由公式 19 可以得到
,由公式 19 可以得到  ,符合公式 18 的条件 1.
,符合公式 18 的条件 1. -
如果
 ,有公式 18 得到
,有公式 18 得到  ,那么
,那么  ,不满足公式 19.
,不满足公式 19. -
如果
 ,有公式 18 得到
,有公式 18 得到  ,那么
,那么  ,不满足公式 19.
,不满足公式 19. -
所以当
 的时候,
的时候,  。
。 -
当
 的时候:
的时候: -
如果
 ,由公式 19 可以得到
,由公式 19 可以得到  ,不符合符合公式 18。
,不符合符合公式 18。 -
如果
 ,有公式 18 得到 $\xi=1
,有公式 18 得到 $\xi=1  ,那么
,那么  ,不满足公式 19.
,不满足公式 19. -
如果
 ,有公式 18 得到
,有公式 18 得到 ,那么
,那么 ,所以有:
,所以有:
-
当
 的时候:
的时候: -
如果
 ,由公式 19 可以得到
,由公式 19 可以得到  ,不符合符合公式 18。
,不符合符合公式 18。 -
如果
 ,有公式 18 得到
,有公式 18 得到 ,那么
,那么 ,所以有:
,所以有:
-
如果
 ,有公式 18 得到 $\xi=-1$
,有公式 18 得到 $\xi=-1$  ,那么
,那么  ,不满足公式 19.
,不满足公式 19.
综合上面的分析,可以得到 FTRL 特征权重各个维度更新的公式为:

per-coordinate learning rates
在 FTRL 中,每个维度的学习率都是单独考虑的。标准的 OGD 理论对每一个样本都是使用的相同的学习率:  。
。
一个简单的思维推理就能证明这种情况并不一定是最理想的:假如我们每一轮扔十个硬币,然后使用 LR 去预估 i 个硬币正面朝上的概率:  。假设使用相同的学习率
。假设使用相同的学习率  ,其中
,其中  是
是  正面朝上的次数。如果
正面朝上的次数。如果 比
比  正面的次数更多,那么
正面的次数更多,那么  的学习率应该比
的学习率应该比  下降的更快,表现为
下降的更快,表现为 具有更多的数据。
具有更多的数据。 的学习率保持的比较高,意味着对
的学习率保持的比较高,意味着对  的新数据更敏感。
的新数据更敏感。
从另一个方面说,如果  从没有投出正面,但是我们依旧在调低
从没有投出正面,但是我们依旧在调低  的学习率,这明显是不合理的。
的学习率,这明显是不合理的。
因此,至少对于某些问题而言,使用 per-coordinate learning rates 是有好处的。谷歌使用以下的公式计算 per-coordinate learning rates:

其中  是第 s 个样本计算的梯度向量
是第 s 个样本计算的梯度向量  中
中  coordinate gradient。
coordinate gradient。
谷歌经验表面,  通常是要调节的,
通常是要调节的,  取 1 就好,且在使用了 per-coordinate learning rates 之后,AUCLoss 下降了 11.2%,对于谷歌的广告系统而言,1% 的 AUCLoss 降低就被认为是很好的优化了。
取 1 就好,且在使用了 per-coordinate learning rates 之后,AUCLoss 下降了 11.2%,对于谷歌的广告系统而言,1% 的 AUCLoss 降低就被认为是很好的优化了。
工程实现思路
工程化实现伪代码
谷歌给出了 FTRL 的工程化算法伪码,其中 

其它谷歌实现的 FTRL 工程化技巧
-
Per-coordinate learning rate
-
原理如前面所述,从统计学上讲就是有效数据越多,数据可信度越高,学习率就越低,优化效果明显。
-
probabilistic feature inclusion
-
每一个特征根据泊松分布,以一定的概率 p 被保存,。
- 使用布隆过滤器,当特征数出现次数大于一个阈值的时候保存。
-
Encoding Values with Fewer Bits:减少存储 weight 参数占用的内存。
- 训练数据子采样
-
正样本正常采样。
- 负样本按照 r 比例采样,在训练的时候对每一个样本乘以 $\frac{1}{r}$ 的权重弥补负样本的损失。
LR+FTRL 工程化实现
根据前面的学习,可以使用 LR 作为基本学习器,使用 FTRL 作为在线最优化的方法来获取 LR 的权重系数,从而达到在不损失精度的前提下获得稀疏解的目标。
工程化实现的几个核心点是:
- 梯度计算代码
- 损失函数计算代码
- 权重更新计算代码
算法代码实现如下所示,这里只给出了核心部分代码,主要做了以下优化:
- 修复原代码更新梯度时候的逻辑错误。
- 支持 pypy3 加速,5.6G 的训练数据,使用 Mac 单机可以 9 分钟跑完一个模型,一个 epoch 之后的 logloss 结果为 0.3916;这对于刷竞赛或者实际工程中模型训练已经是比较理想的性能了。
- 使用 16 位浮点数保存权重数据,降低模型文件大小。
- 使用 json 保存模型非 0 参数 w,z,n,进一步压缩线上使用的时候占据的内存空间,可以进一步考虑压缩模型文件大小,比如使用 bson 编码 +gzip 压缩后保存等。
from datetime import datetime
from csv import DictReader
from math import exp, log, sqrt
import gzip
import random
import json
import argparse
class FTRLProximal(object):
"""
FTRL Proximal engineer project with logistic regression
Reference:
https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/41159.pdf
"""
def __init__(self, alpha, beta, L1, L2, D,
interaction=False, dropout=1.0,
dayfeature=True,
device_counters=False):
# parameters
self.alpha = alpha
self.beta = beta
self.L1 = L1
self.L2 = L2
self.dayfeature = dayfeature
self.device_counters = device_counters
# feature related parameters
self.D = D
self.interaction = interaction
self.dropout = dropout
# model
self.n = [0.] * D
self.z = [0.] * D
self.w = [0.] * D
def _indices(self, x):
'''
A helper generator that yields the indices in x
The purpose of this generator is to make the following
code a bit cleaner when doing feature interaction.
'''
for i in x:
yield i
if self.interaction:
D = self.D
L = len(x)
for i in range(1, L): # skip bias term, so we start at 1
for j in range(i + 1, L):
# one-hot encode interactions with hash trick
yield abs(hash(str(x[i]) + '_' + str(x[j]))) % D
def predict(self, x, dropped=None):
"""
use x and computed weight to get predict
:param x:
:param dropped:
:return:
"""
# wTx is the inner product of w and x
wTx = 0.
for j, i in enumerate(self._indices(x)):
if dropped is not None and dropped[j]:
continue
wTx += self.w[i]
if dropped is not None:
wTx /= self.dropout
# bounded sigmoid function, this is the probability estimation
return 1. / (1. + exp(-max(min(wTx, 35.), -35.)))
def update(self, x, y):
"""
update weight and coordinate learning rate based on x and y
:param x:
:param y:
:return:
"""
ind = [i for i in self._indices(x)]
if self.dropout == 1:
dropped = None
else:
dropped = [random.random() > self.dropout for i in range(0, len(ind))]
p = self.predict(x, dropped)
# gradient under logloss
g = p - y
# update z and n
for j, i in enumerate(ind):
# implement dropout as overfitting prevention
if dropped is not None and dropped[j]:
continue
g_i = g * i
sigma = (sqrt(self.n[i] + g_i * g_i) - sqrt(self.n[i])) / self.alpha
self.z[i] += g_i - sigma * self.w[i]
self.n[i] += g_i * g_i
sign = -1. if self.z[i] < 0 else 1. # get sign of z[i]
# build w on the fly using z and n, hence the name - lazy weights -
if sign * self.z[i] <= self.L1:
# w[i] vanishes due to L1 regularization
self.w[i] = 0.
else:
# apply prediction time L1, L2 regularization to z and get
self.w[i] = (sign * self.L1 - self.z[i]) \
/ ((self.beta + sqrt(self.n[i])) / self.alpha + self.L2)
def save_model(self, save_file):
"""
保存weight数据到本地
:param save_file:
:return:
"""
with open(save_file, "w") as f:
w = {k: v for k, v in enumerate(self.w) if v != 0}
z = {k: v for k, v in enumerate(self.z) if v != 0}
n = {k: v for k, v in enumerate(self.n) if v != 0}
data = {
'w': w,
'z': z,
'n': n
}
json.dump(data, f)
def load_weight(self, model_file, D):
"""
loada weight data
:param model_file:
:return:
"""
with open(model_file, "r") as f:
data = json.load(f)
self.w = data.get('w', [0.] * D)
self.z = data.get('z', [0.] * D)
self.n = data.get('n', [0.] * D)
@staticmethod
def loss(y, y_pred):
"""
log loss for LR model
:param y:
:param y_pred:
:return:
"""
p = max(min(y_pred, 1. - 10e-15), 10e-15)
return -log(p) if y == 1. else -log(1. - p)
def data(f_train, D, dayfilter=None, dayfeature=True, counters=False):
''' GENERATOR: Apply hash-trick to the original csv row
and for simplicity, we one-hot-encode everything
INPUT:
path: path to training or testing file
D: the max index that we can hash to
YIELDS:
ID: id of the instance, mainly useless
x: a list of hashed and one-hot-encoded 'indices'
we only need the index since all values are either 0 or 1
y: y = 1 if we have a click, else we have y = 0
'''
device_ip_counter = {}
device_id_counter = {}
for t, row in enumerate(DictReader(f_train)):
# process id
ID = row['id']
del row['id']
# process clicks
y = 0.
if 'click' in row:
if row['click'] == '1':
y = 1.
del row['click']
# turn hour really into hour, it was originally YYMMDDHH
date = row['hour'][0:6]
row['hour'] = row['hour'][6:]
if dayfilter != None and not date in dayfilter:
continue
if dayfeature:
# extract date
row['wd'] = str(int(date) % 7)
row['wd_hour'] = "%s_%s" % (row['wd'], row['hour'])
if counters:
d_ip = row['device_ip']
d_id = row["device_id"]
try:
device_ip_counter[d_ip] += 1
device_id_counter[d_id] += 1
except KeyError:
device_ip_counter[d_ip] = 1
device_id_counter[d_id] = 1
row["ipc"] = str(min(device_ip_counter[d_ip], 8))
row["idc"] = str(min(device_id_counter[d_id], 8))
# build x
x = [0] # 0 is the index of the bias term
for key in row:
value = row[key]
# one-hot encode everything with hash trick
index = abs(hash(key + '_' + value)) % D
x.append(index)
yield t, ID, x, y
参考文献
- Follow-the-Regularized-Leader and Mirror Descent:Equivalence Theorems and L1 Regularization(Google, FTRL 原理论文)
- Ad Click Prediction: a View from the Trenches(Google,FTRL 工程化文档)
- 在线最优化求解 (冯杨,讲在线最优化算法非常好的一篇文档)
- 统计学习方法 (李航)
- spark MLlib 机器学习 (黄美玲)
- 机器学习 (周航)

时间:2020-01-01 00:58 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]机器学习基础图表:概念、原理、历史、趋势和算法
- [机器学习]浅谈多核心CPU和SoC芯片及其工作原理
- [机器学习]一文详解神经网络与激活函数的基本原理
- [机器学习]ResNet、Faster RCNN、Mask RCNN是专利算法吗?盘点何恺
- [机器学习]DeepMind新突破!首次用深度学习从第一性原理计算
- [机器学习]YOLO算法最全综述:从YOLOv1到YOLOv5
- [机器学习]推荐系统架构与算法流程详解
- [机器学习]YOLO算法最全综述:从YOLOv1到YOLOv5
- [机器学习]深度神经网络模型训练中的 tricks(原理与代码汇
- [机器学习]贝尔实验室和周公“掰手腕”:AI算法解梦成为现
相关推荐:
网友评论:















