知识图谱的自动构建
本文根据吴信东 (IEEE & AAAS Fellow,明略科技 首席科学家) 教授在2019 知识图谱前沿技术论坛的分享内容,编辑整理而成,发布于 DataFunTalk,编辑整理:王吉东。
注:欢迎转载,转载请在留言区内留言。
导读: 知识图谱的构建包括逻辑建模、隐含空间分析、人机交互和本体模型支撑等多种方法。我们将分析各种构建方法的问题和挑战,指出自动构建的要素和应用场景。
背景
知识图谱是明略科技的核心技术。知识图谱的自动构建和数据挖掘有一定的关联,自动构建知识图谱和手动构建不是一个概念。明略科技的新产品正在做到:专家在台上讲话,后台图谱系统可自动同步构建知识图谱。
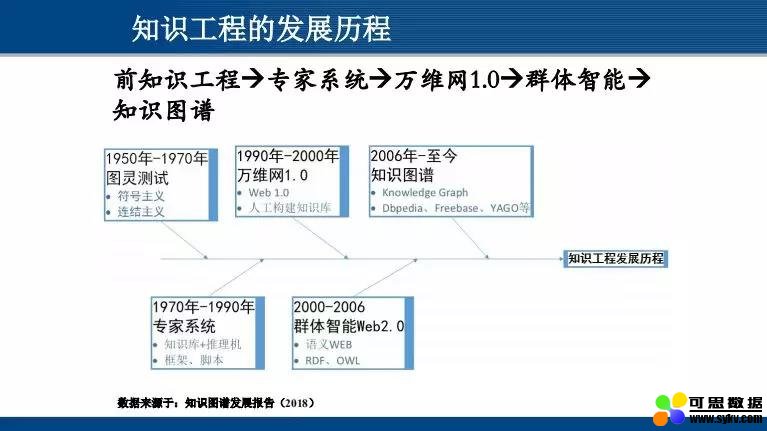
提到知识工程的发展,首先是 80 年代蓬勃发展的专家系统,随后逐步发展至 90 年代的万维网知识库。90 年代的万维网 1.0,以信息收集为主;后面加入人工因素,即人和信息一起,此时进入万维网 2.0 阶段。
“知识图谱” 这一概念是 2006 年由谷歌提出,谷歌出于搜索引擎需要而提出这样的名词,其技术核心类似于 60 年代提出的语义网络。
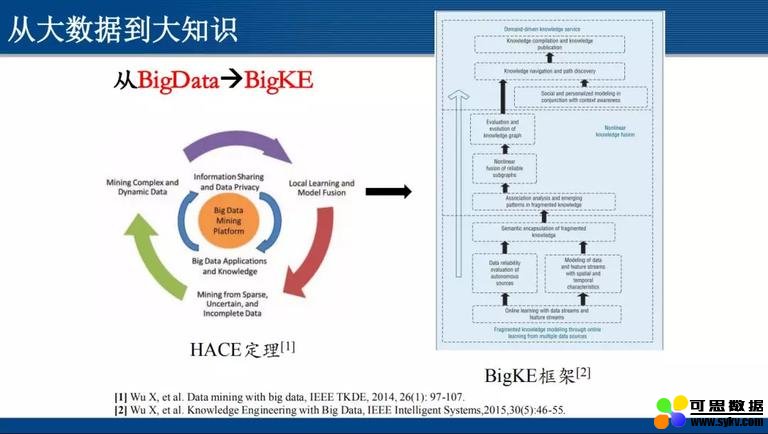
吴信东教授于 2014 提出 “HACE 定理”,指出大数据始于异构 (Heterogeneous)、自治 (Autonomous) 的多源海量数据,旨在寻求探索复杂 (Complex)、演化 (Evolving) 的数据关联和方法,这是对大数据本质特征的提炼。
大数据在实现的过程中分为 3 层结构:最底层是数据平台 (Big Data Mining Platform),做数据的收集、整合、加工等;中间的一层是应用领域,涉及到语义、专业领域知识等方面;最外层是大数据分析实现的算法,涉及到机器学习、数据挖掘等。
从大数据 ( BigData) 到大知识 (BigKE),体现的是基于数据的知识提炼过程。“大” 知识的特点除了量大,更主要的是 “质量没有保证”;我们的目标是,在浩瀚无边的知识海洋中,如何针对当前问题找到相关的知识进行问题求解,实现 “量 -> 质 -> 序” 的过渡。
基于大数据的特点,实现大数据到大知识的跳跃,这一过程中经历了信息检索的不断完善和分析;从知识图谱构建的角度来看,这一过程经历了人工构建 - 群体构建 - 自动构建这样的技术路线。详见下图。
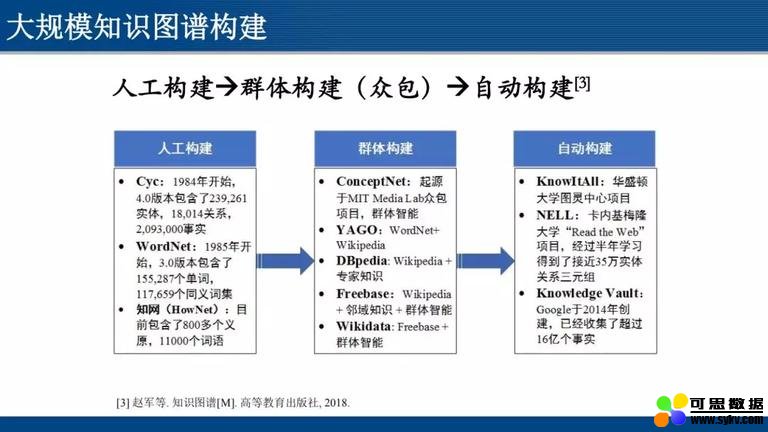
本文将着重讲解 “自动构建”。自动构建的过程中,如果数据是结构化的 (例如图表数据),已知属性名称、属性间的层次结构等,构建知识图谱相对较为容易;如果缺乏以上信息,则只能通过文本信息等非结构化数据中提炼知识构建知识图谱,技术上将面临很多挑战。

结构化数据通常具有良好的布局结构,因此识别和抽取比较容易,可针对特定格式编写模板进行抽取,抽取准确率也比较高。早在知识图谱技术大受追捧之前的上个世纪 90 年代,国内便开始了 “从关系型描述数据库生成语义网络的方法” 研究工作。
非结构化数据上的知识图谱研究,主要集中非结构化文本数据处理上。由于自然语言表达的多样性、灵活性,实体和关系在文本中一般找不到明确的标识,这使得从中抽取实体和识别语义关系非常困难。
下面以一个实例来描述非结构化数据知识图谱的构建过程。文本数据来源于百度百科,介绍秦始皇的生平事迹。原文如下:

基于以上文本,初步构建知识图谱如下:
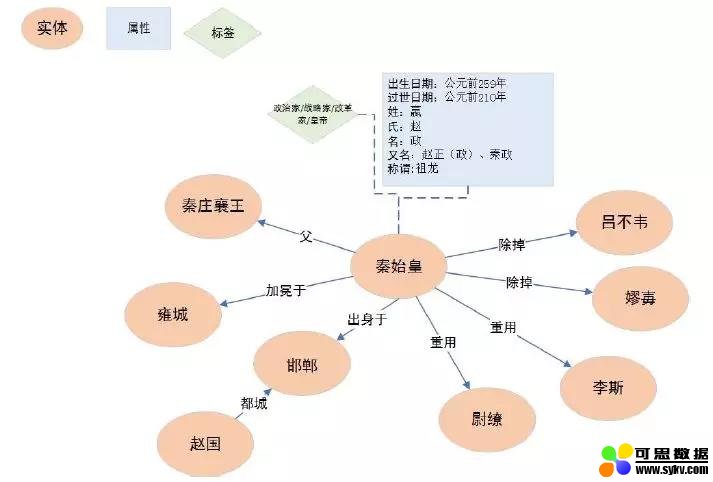
上述图谱抽取的信息不是十分完全,但是大体上能够涵盖和秦始皇相关的各种各样的人物以及各种各样的关系。
构建方法
这一部分会主要介绍现有的常见的知识图谱的构建方法。
知识图谱的构建方法,主要包含 4 大类:逻辑建模,隐含空间分析,人机交互,本体模型。
1. 逻辑建模
上一部分提到的 “秦始皇” 的实例,就是根据逻辑建模提炼生成的。
将名词和关系进行抽取,如果涉及到事件,将会涉及到条件概率、先验概率等。
在逻辑建模中,逻辑 + 概率作为可能世界的概率度量;对逻辑进行概率化,并利用知识库中的每一条关系三元组对可能世界概率进行约束。
逻辑建模中会涉及到逻辑变量和规则推理等方面的模型,其代表模型是马尔可夫逻辑网模型。将马尔可夫逻辑网看作一个构造马尔可夫网的模板,它维护一个基于一阶逻辑的规则库,并对每一个逻辑规则附上了权重,以此对可能的世界进行软约束。其概率模型为:
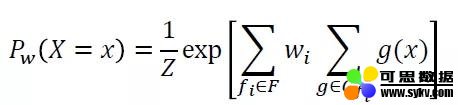
其中,g(x)=1 表示该实例化的规则为真,反之为假;F 为 Markov 网中所有谓词规则的集合,Gfi 是利用所有原子事实去实例化规则 fi 后的集合。
然而逻辑建模的缺陷也很明显:随着知识图谱的规模爆发性地增长,即使利用马尔可夫毯 ( Markov Blanket) 等局部依赖假设,对知识图谱中所有知识实例进行建模也是不可行的。
2. 隐含空间分析
第二种知识图谱构建方法是隐含空间分析。有时候一句简单的语句的背后会包含一些隐含的逻辑关系,例如:吴信东 (首席科学家) 给吴明辉 (董事长) 打电话。这一句简单的语句,背后会隐含各种各样的关系,例如:首席科学家应该做哪些事;和董事长应该讨论的内容等。目前隐含空间分析主要尚处于研究阶段,应用还不是很广泛。
- 距离模型
隐含空间分析的基本模型是距离模型,代表方法是结构表示 ( StructuredEmbedding,SE):对于一个三元组 (h, r, t),SE 将头实体向量和尾实体向量通过关系的两个矩阵投影到关系的对应空间中,然后在该空间中计算两投影向量的距离。SE 模型的损失函数使用的是 L1 范数:

由于 SE 模型对头、尾实体使用两个不同的矩阵进行投影,协同性较差,因此往往无法精确刻画两实体与关系之间的语义联系。由此提出了隐变量模型:
- 隐变量模型 (LatentFactorModel,简称 LFM)
LFM 模型提出基于关系的双线性变换,刻画实体和关系的二阶联系,其评分函数为:
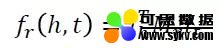
其中,Mr∈Rdxd 为关系 r 对应的双线性变换矩阵。
LFM 模型通过简单有效的方法刻画了实体和关系的语义联系,协同性较好,计算复杂度低。如何具体描述和刻画这个隐含的空间,会涉及到系数问题,于是引出张量神经模型:
- ** 张量神经模型 (neuraltensornetwork,简称 NTN) **
基本思想:用双线性张量取代传统神经网络中的线性变换层,在不同维度下将头、尾实体向量联系起来。
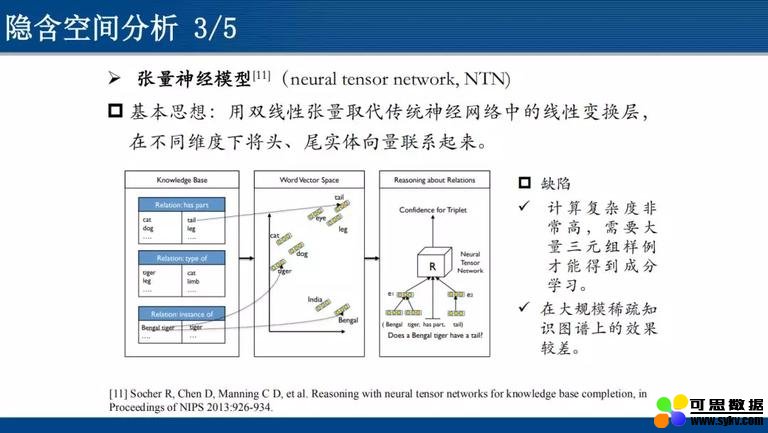
然而,NTN 模型计算复杂度非常高,需要大量三元组样例才能得到成分学习,因而在大规模稀疏知识图谱上的效果较差。由此引出矩阵分解模型:
- 矩阵分解模型
矩阵分解模型的代表方法是 RASACL 模型。
知识库三元组构成一个大的张量 X,如果三元组 (h, r, t) 存在,则 Xhrt=1,否则为 0。张量分解 (矩阵分解) 旨在将每个三元组 (h, r, t) 对应的张量值 Xhrt 分解为实体和关系表示,使得 Xhrt 尽量地接近于 lhMrlt 。这种模型的缺陷是:时间复杂度和空间复杂度较高,且在大规模数据集上效率低、可扩展性差。
- 翻译模型
翻译模型的代表方法是 TransE 模型。对于每个三元组 (h, r, t),将关系 r 的向量 lr 看作头实体向量 lh 和尾实体向量 lt 的平移。
TransE 模型的参数较少,计算复杂度低,能直接建立实体和关系之间的复杂语义联系,但是在处理复杂关系时性能显著降低。
3. 人机交互
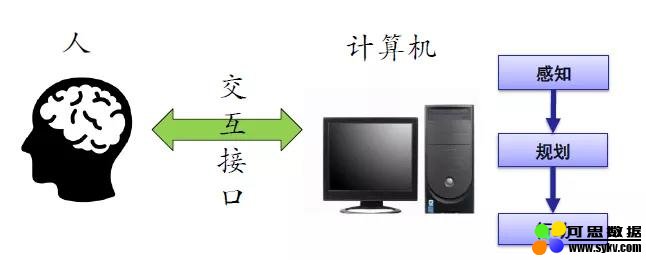
人机交互 ( Human-Computer Interaction, HCI):是指人与计算机之间使用某种对话语言,以一定的交互方式,为完成确定任务的人与计算机之间的信息交换过程。常见的方式就是:存在一个系统,什么都不懂,不断地向用户问问题;随着用户对问题的回答,系统逐步将图谱建立起来。
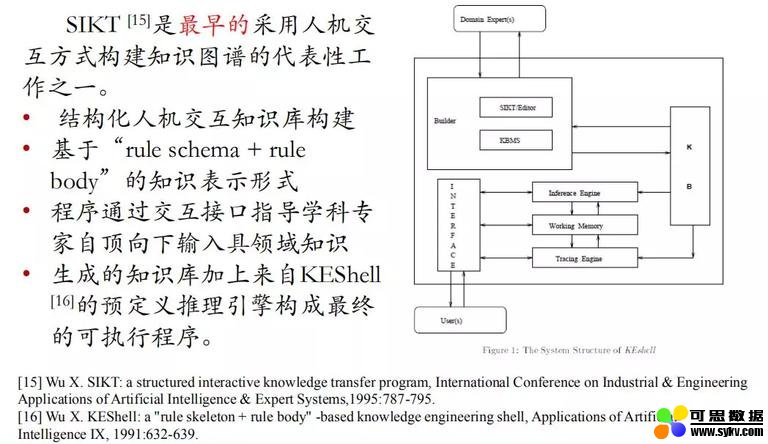
SIKT (structured interactive knowledge transfer program) 是吴教授最早采用人机交互方式构建知识图谱的代表性工作之一,早期称之为 “推理网络”,主要包括以下特色:
-
结构化人机交互知识库构建。
-
基于 “rule schema + rule body” 的知识表示形式。
-
程序通过交互接口指导学科专家自顶向下输入领域知识。
-
生成的知识库加上来自 KEShell 的预定义推理引擎构成最终的可执行程序。
人机交互的另一种方法,也是吴教授的项目课题,是 IAKO (Interactive Acquisition of Knowledge Objects),即半结构化的知识图谱构建。
-
利用面向对象编程的优势,IAKO 基于知识对象 (Knowledge Object) 的表示方法,提出了一个面向对象的交互知识构建系统。
-
IAKO 能够从 0 开始,通过领域专家交互方式生成一套完整的知识库,且进行知识和规则校验,以保障知识库的可执行性。
-
基于知识对象的知识表示方式可以将规则融入对象中,达到 SIKT 中一组 “rule schema + rule body” 的知识表示能力。
-
IAKO 能够使得领域专家构建便携的和可重用的知识库。
人机交互的一种最新方法,是吴教授任职明略科技后同明略科技董事长吴明辉一起提出的一种模型,叫做 “HAO 模型”,该模型有效地融合了 Human Intelligence (HI)、Artificial Intelligence (AI)、Organizational Intelligence 这三种 “智慧”,在以人为本、人机协同的基础上,加入了面向行业应用、具体细分领域的 Organizational Intelligence。下图就是面向行业构建的知识图谱框架。
数据感知 -> 人机交互 -> 行动
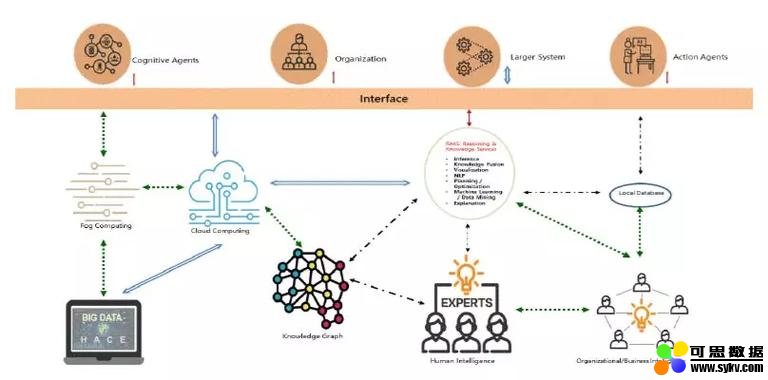
在明略科技所涉及的公安领域,知识图谱是巨大的:在一个具体的公安数据分析系统里,有 16 亿个节点,40 亿条边,140 亿个事件,这样一个 7 度搜索可能需要 40 亿 7 次方的计算量,巨大到不可承受,因此可以看出这类知识图谱的构建中人工干预的必要性。
4. 本体模型支撑
本体模型,主要指:后台有一定的知识储备作为支撑。
系统后台存在一个知识库作为本体的支撑,根据输入语言的特征、关键词等去匹配后台的知识库。这里会涉及到较多的机器学习模型。
- 人工构建
人工构建本体模型支撑,由大量的领域专家相互协作构建本体,用以支撑前台做文本分析;代表方法包括循环获取法、七步法等。
Cyc 循环获取法
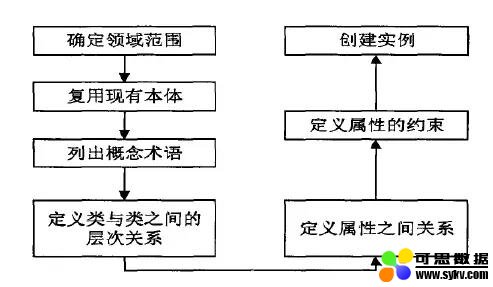
Ontology Development 101 (七步法)
七步法的缺点是:主观性太强,且比较随意,缺少科学管理和评价机制。
- 本文地址:http://www.6aiq.com/article/1575910434302
- 本文版权归作者和AIQ共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出
- 知乎专栏 点击关注
- 半自动构建
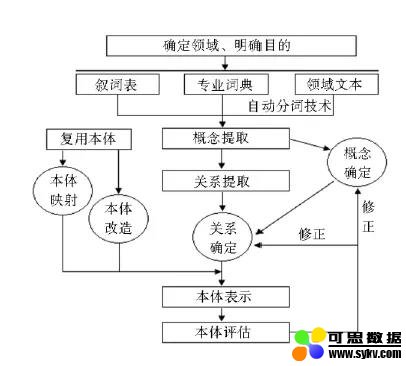
半自动构建本体,利用相关领域内的专业词典、叙词表等专家知识,从中抽取感兴趣的概念和关系,构建需要的本体。
缺点:复用本体中的概念和关系,带来了不同本体匹配的问题。
- 自动构建
自动构建本体,指的是利用知识获取技术、机器学习技术以及统计技术等从数据资源中自动获取本体知识。
主要涉及到两种方法:一种是基于语言规则的方法,另一种是基于统计分析的机器学习方法。
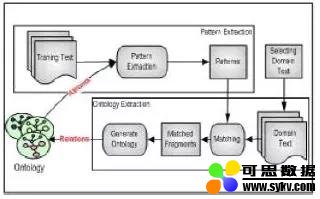
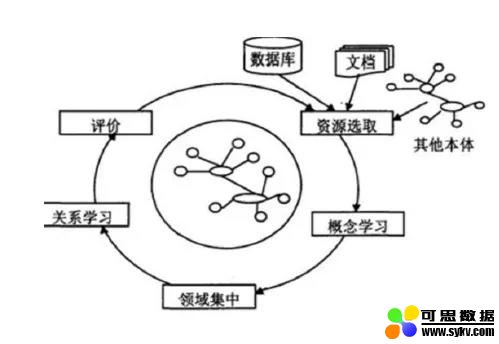
基于语言规则的方法,主要指基于语义模式,从自然域文本构建本体,通过对自然域文本的分析,提取候选关系并将其映射到语义表示中,实现本体的构建。
如上图所示,其基本框架为:
-
使用模式编辑器构造语义模式
-
选择自然域文本
-
从自然域文本中提取领域本体
其优点是:以非分类学关系丰富了浅层本体,一个动词可以表示两个或多个概念之间的关系。然而,这种方法不会发现新的关系,只是发现已知关系实例;而且本体构建的效果依赖于语义模式,因而需事先构建较完备的语义模式。
基于统计分析的机器学习方法,主要是基于数据聚类和模式树挖掘,进行结构化的本体构建。
-
对用于构建每个组的本体书类似文档进行分组
-
使用模式树挖掘从部分本体树构建集成本体
这种方法主要有两个主要模块:
-
文档聚类:使用检索关键字的关系矩阵通过潜在语义分析 (LSA) 和 K-means 方法来聚类文档。
-
本体构建:通过形式概念分析和本体集成构建每组文档的本体。
统计机器学习方法可适用于范围更广的领域,可构建的本体倾向于更好地描述概念间的关系,结构也更加复杂;然而这种方法缺乏必要的语义逻辑基础,抽取概念关系松散且可信度无法得到很好的保证。
图谱自动构建要素
1. 总体设计框架

总体架构的两个核心要素,一个要素是后台的领域知识库,另一个要素是强化学习配合人机交互。
** 步骤一:**数据自动获取
通过使用较为流行的网络数据获取工具,如:Scrapy,Jspider,Larbin 等获取多源异构数据。
步骤二:三元组自动抽取
结合自然语言处理工具和领域知识库,初步识别和抽取文本中的三元组信息。
- 构建要素一:领域知识库
在图谱自动构建过程中,由领域专家 ( HI) 和专业组织 (OI) 提供的领域知识库能够有效提高实体、关系的识别和抽取精度。
** 步骤三:**自动纠错和自主学习
结合 HAO 智能模型和强化学习方法,通过人机交互接口对代表性错误三元组进行人工纠正,并以此对强化学习模型进行训练和提高,实现自动纠错和自主学习。
- 构建要素二:强化学习 + 人机交互
为保证图谱构建质量,需要通过人机交互接口对错误信息进行人工纠正,并以此作为种子案例,通过强化学习加强模型的识别精度和鲁棒性。
应用场景
应用场景一:网络行为动态分析
通过网络爬虫获取最新的网络信息数据,运用知识图谱自动构建技术,动态更新和扩充现有知识库,为网络行为分析提供知识支撑。包括:
-
舆情监测
-
热点跟踪
-
用户情感倾向分析
-
用户设计网络影响力分析
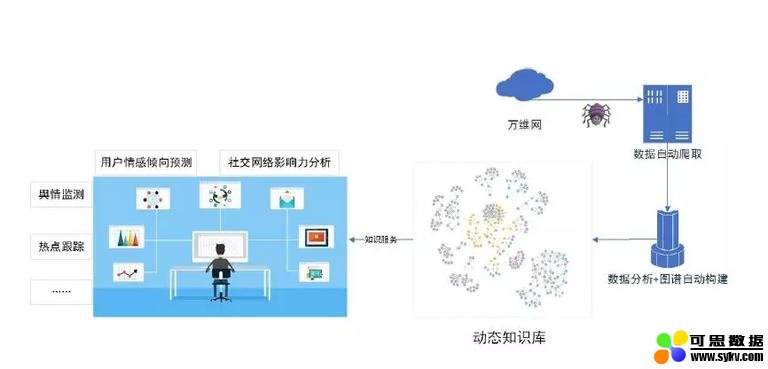
这一部分也是明略科技涉及业务比较多的方面,涉及品牌分析,为大客户做广告设计,推荐广告布局,并做广告监测,以及品牌效应分析;这一部分的后台就是基于知识图谱的基础上做舆情分析、热点跟踪等。
应用场景二:智能 Q&A
通过人机交互 + 知识图谱自动构建,设计更智能的知识问答系统。
-
人机交互:人与机器进行工作互补,共同完成问答场景。
-
知识图谱自动构建:动态更新和扩充问答知识库,响应最新的网络知识。
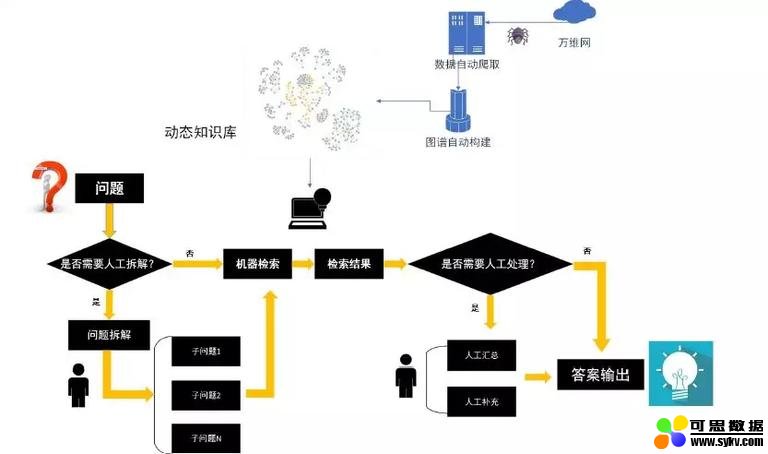
明略科技今年的战略发展之一就是智能 Q&A 产品,类似于科大讯飞的相关产品,前台问答的同时,后台同步构建知识图谱。
应用场景三:智能推荐
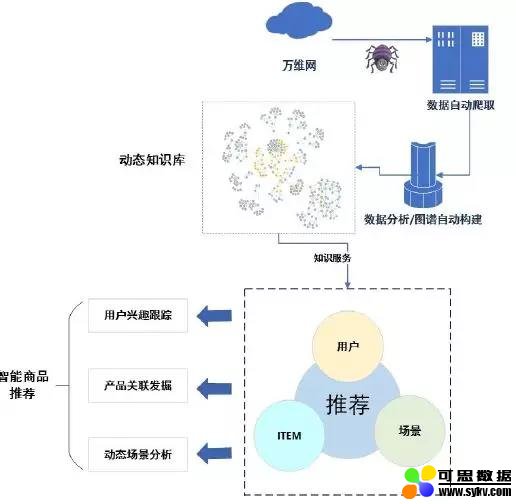
对于推荐系统中的核心元素:用户、场景和 ITEM,利用知识图谱自动构建技术,实时获取互联网海量信息并更新推荐知识库,通过用户兴趣跟踪、产品关联发掘、动态场景分析等方法提供更智能的推荐服务,涉及到用户跟踪,涉及产品动态变化等。
今天的分享就到这里,谢谢大家。
参考资料
[1] WuX, et al. Data mining with big data, IEEE TKDE, 2014, 26(1): 97-107.
[2] WuX, et al. Knowledge Engineering with Big Data, IEEE IntelligentSystems,2015,30(5):46-55.
[3] 赵军等. 知识图谱 [M]. 高等教育出版社, 2018.
[4] 吴信东, 张奠成. 从关系型描述数据库生成语义网络的方法, 科学通报,1990:1674-1676.
[5] FahiemBacchus. Representing and reasoning with probabilistic knowledge, The MITPress, 1990.
[6] Nils J Nilsson. Probabilistic logic, Artificial Intelligence, 1986, 28(1): 71-87.
[7] Matthew Richardson, Pedro Domingos.Markov logic networks, Machine Learning, 2006, 62(1-2): 107-136.
[8] BordesA, Weston J, CollobertR, et al. Learning structured embeddings of knowledge bases, in Proceedings ofAAAI 2011, 2011:301-306.
[9] SutskeverI, Tenenbaum J B, SalakhutdinovR, et al. Modelling Relational Data using Bayesian Clustered TensorFactorization[C], in Proceedings of NIPS 2009:1821-1828.
[10] JenattonR, Roux N L, BordesA, et al. A latent factor model for highly multi-relational data[C], inProceedings of NIPS 2012:3167-3175.
[11] SocherR, Chen D, Manning C D, et al. Reasoning with neural tensor networks forknowledge base completion, in Proceedings of NIPS 2013:926-934.
[12] Nickel M, TrespV, KriegelH. A three-way model for collective learning on multi-relational data, inProceedings of ICML 2011:809–816.
[13] CaiH Y, Zheng V W, Chang K. A Comprehensive Survey of Graph Embedding: Problems,Techniques and Applications. IEEE Transactions on Knowledge and DataEngineering, 2018. 3(9): 1616-1637.
[14] BordesA, UsunierN, Garcia-Duran A, et al. Translating Embeddings for Modeling Multi-relationalData, in Proceedings of NIPS 2013:2787-2795.
[15] Wu X. SIKT: a structured interactive knowledge transfer program, InternationalConference on Industrial & Engineering Applications of ArtificialIntelligence & Expert Systems,1995:787-795.
[16] Wu X. KEShell:a “rule skeleton + rule body” -based knowledge engineering shell,Applications of Artificial Intelligence IX, 1991:632-639.
[17] Xu L , Wu X . Interactive Acquisition of Knowledge Objects, In Proceedings ofIEEE Knowledgeand Data Engineering Exchange Workshop, 1997:97-105.
[18] MinghuiWu and XindongWu, On Big Wisdom, Knowledgeand Information Systems, 2019, 58(1): 1-8.
[19] SwartoutB, Patil R, Knight K, et al.Toward distributed use of large-scale ontologies. In: Proc. of the 10thWorkshop on Knowledge Acquisition for Knowledge-Based Systems, 1996:138-148.
[20] NoyNF, McGuinness DL. Ontology development 101: A guide to creating your firstontology. 2001.
https://doi.org/10.1016/j.artmed.2004.01.014
[21] SuryantoH, Compton P. Discovery of ontologies from knowledge bases, ACM InternationalConference on Knowledge Capture, 2001.
[22] Dahab M Y , Hassan H A , Rafea A . TextOntoEx: Automatic ontology constructionfrom natural English text[J]. Expert Systems With Applications, 2008,34(2):1474-1480.
[23] Yu Y T , Hsu C C . A structured ontology construction by using data clustering andpattern tree mining, International Conference on Machine Learning andCybernetics, ICMLC 2011.

时间:2019-12-14 23:16 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]2021年进入AI和ML领域之前需要了解的10件事
- [机器学习]来自Facebook AI的多任务多模态的统一Transformer:向
- [机器学习]一文详解深度学习最常用的 10 个激活函数
- [机器学习]更深、更轻量级的Transformer!Facebook提出:DeLigh
- [机器学习]AAAI21最佳论文Informer:效果远超Transformer的长序列
- [机器学习]深度学习中的3个秘密:集成、知识蒸馏和蒸馏
- [机器学习]让研究人员绞尽脑汁的Transformer位置编码
- [机器学习]【模型压缩】深度卷积网络的剪枝和加速
- [机器学习]堪比当年的LSTM,Transformer引燃机器学习圈:它是
- [机器学习]深度学习三大谜团:集成、知识蒸馏和自蒸馏
相关推荐:
网友评论:















