深度 |58 商业流量排序策略优化实践
背景
58 作为国内最大的生活信息服务平台,涵盖了本地服务,招聘,房产,二手车,二手物品多条业务线。商业部门作为中台部门,职能是为各个业务线提供商业变现解决方案,提升业务线流量变现效率,同时满足各业务线个性化,多元化的流量变现需求。
在不同的商业产品类型以及不同的场景下,业务线对于变现效率和用户体验存在不同的诉求。目前在 listing 模式下,当帖子候选数量较大时,排序对变现效率和用户体验的影响很大,满足业务线多元化、差异化商业产品需求和变现效率提升诉求的同时,兼顾用户体验,成为排序需要去解决的非常关键的问题。
本文主要介绍商业策略技术团队在 58 商业流量上的排序策略优化实践,主要包括数据流升级,特征升级,模型升级,排序机制升级四个部分,并阐述在升级过程中,对新技术落地的实践效果和心得体会。
优化前排序策略介绍
在介绍上述 4 个部分升级前,先简要介绍一下优化前的基础模型情况。
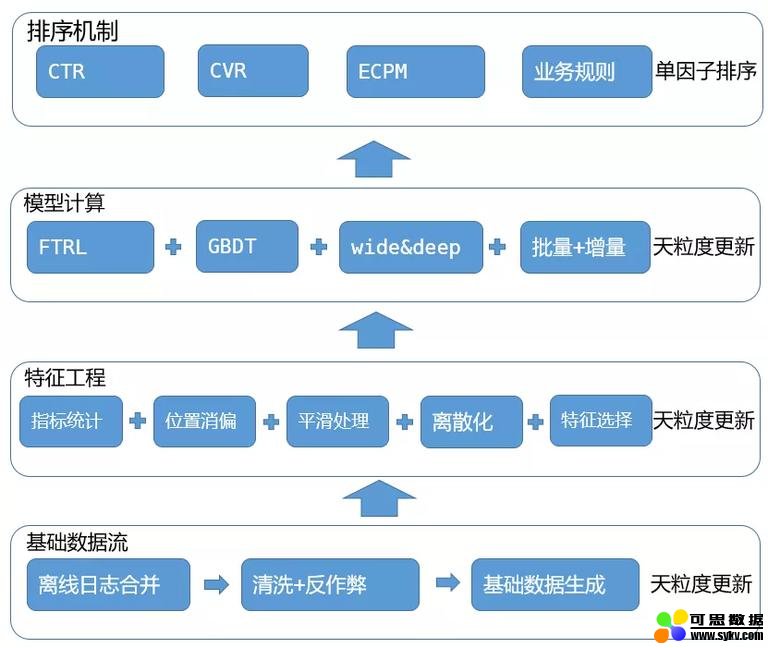
图 1 优化前排序策略情况
如图 1 所示,也从 4 个部分来阐述基础模型:
(1)基础数据流:基础数据流主要产出供后续样本生成和特征指标计算的基础数据。在这个部分,需要完成离线日志合并,数据清洗以及一些基础的数据加工操作。我们能获取的业务日志,一般有列表页广告展现日志,点击日志以及转化日志,日志合并操作会按指定的 key(一般会打平到单次展现下广告粒度,方便后续进行聚合分析等操作)进行合并。由于作弊,爬虫等原因,我们合并好的基础数据中包含了大量噪声,直接用来进行指标计算或者样本生成会对模型效果产生较大的影响,所以需要对合并完成后的数据进行清洗和反作弊,对于商业流量,因为有线上反作弊系统,所以拿到的原始日志中是会带有反作弊标识的,直接根据该标识对日志进行过滤即可(一次展现下如果有一个点击被识别为作弊点击,则去除所有改成展现下的日志数据)。对于清洗,主要是通过 ip 黑名单和用户黑名单(通过算法挖掘生成)以及筛选真曝光的方式来进行日志过滤。完成上述操作后,我们会获得带有上百个基础字段的可用样本,这些样本数据会在下一个环节被用来生成最终样本和进行指标计算;
(2)特征工程:人工特征工程一般包括特征设计,特征加工,特征选择三个步骤,首先在特征设计环节需要结合当前的业务场景,进行详细的数据分析,判断哪些类型的特征会对业务指标带来增长。举一个例子,比如黄页的用户,返回率较低,大多数用户,当天找到服务后,很长一段时间都不会重复寻找相同服务,例如找开锁换锁,那么在黄页场景下,用户特征的效果就会大打折扣。但是用户在找黄页服务的时候,对距离因素特别在意,那么在排序中增加 lbs 相关特征,效果就会比较明显;不同业务线差异较大,二手车上就需要高度的用户个性化,所以特征设计环节,就是需要结合对业务的理解和数据分析,来判断该往哪个方向去设计特征。这里以比较常见的,也比较通用的帖子维度历史点击率为例简要介绍一下几种常见的统计类特征加工操作:1. 位置消偏,listing 模式下,位置对点击率的影响非常之大,通过统计数据也可以发现,很多业务线上,首屏占了大部分的点击,而这种位置带来的点击率会影响特征统计,所以需要对位置进行消偏,一般会采用 COEC 来进行位置的消偏;2. 平滑处理,这里主要是针对一些曝光量还不够的帖子,在曝光量不到达具备统计意义的情况前,通过这些数据计算出的点击率是极度不靠谱的,需要进行平滑处理,一般会采用贝叶斯平滑;3. 离散化:对连续性的指标,会进行离散化或者归一化的处理,一个目的是增加其泛化能力,另外一个目的是可以加快模型的训练速度,减小模型复杂度。特征选择一般会基于信息增益和单特征 AUC 来进行挑选;
(3)模型计算:基础模型中支持 FTRL(带正则的进阶版 LR),GBDT 以及 wide&deep,支持这些模型的批量和增量的天粒度更新,其中 wide&deep 基于 tensorflow server api 实现线上批量预估;
(4)排序机制:支持单一因子的排序,例如纯 ctr,cvr 或者按 ecpm 排序;
上述基础模型在线上运行后,陆续发现了一些类似特征 diff,特征实时性不够,排序因子较少等问题,针对发现的这些问题,我们进行针对性的优化升级,取得了不错的效果。
排序策略优化路径
1. 数据流升级
基础版的数据流中,有几个比较明显的缺陷,会制约模型对业务的增长:
(1)特征 diff:通过特征监控发现,在原有的数据流中,存在较多的特征 diff(特征线上线下取值不一致)情况,分析后发现,这种情况出现在线上特征库更新的时候,比如当天 10 点,线上特征库中的统计类特征进行了更新,在 10 点前,线上服务获取的统计类特征依旧是未更新的,离线的样本拼接的都是更新后的数据,这样离线样本中 10 点前的特征就跟线上产生了 diff。由于集群计算资源不稳定,线上特征库的更新时间也不稳定,所以通过离线还原样本的方式,很难完全消除特征 diff;
(2)特征时效性:在用户操作密集型的业务线,例如二手车,特征的时效性尤为重要,例如用户在前几分钟点击了宝马,那当前的排序中,就要能根据用户的实时行为做出反馈,基础模型中,基于天粒度的特征更新,是无法达到这个目标的;
针对上述两个需要优化的地方,我们升级了数据流,搭建了两条实时数据流,其中一条基于 spark streaming,用于进行实时展现点击日志拼接,实时样本生成,另外一条基于 flink,用于进行实时指标计算;
(1)实时样本流:
实时样本流采用实时拼接展现点击数据的方式,从 kafka 中读取展现点击数据,采用 spark streaming,对日志进行实时清洗 / 反作弊处理,提取关键字段,实时拼接在线特征库中的特征,在集群稳定的情况下,相比线上的真实请求,实时流生成样本的延时约在 1 分钟左右,在如此短暂的时延下,样本中获取的特征数据跟线上请求中获取的特征数据,产生 diff 的情况会极大减少。实时样本流上线后,特征 diff 率从 5% 下降到 1% 以内。同时,实时样本流也为支持实时模型训练打下基础。实时样本流请见图 2:
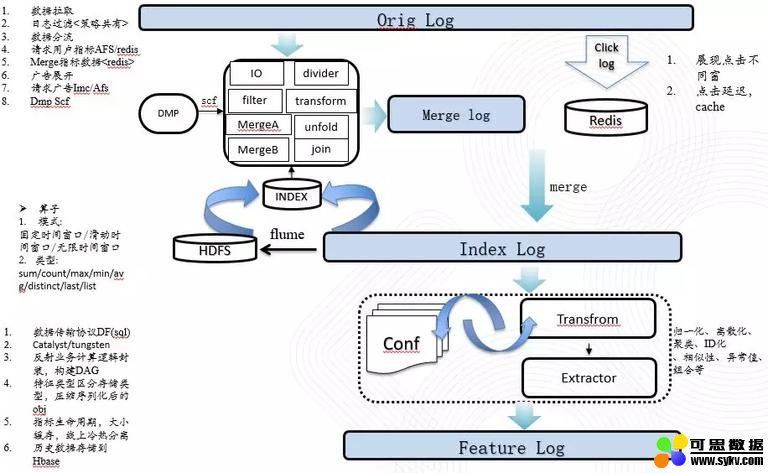
图 2 实时样本数据流
这里需要注意的一个点是展现日志和点击日志的实时拼接上,在常见的业务场景中,展现日志会远多于点击日志,使用 streaming 去处理同一个时间窗口的展现日志和点击日志时,点击日志的处理往往会快很多,一旦出现集群资源紧张,展现日志的处理压力就会变大,处理速度变慢,出现展现日志积压,这样就会产生很多点击日志因为拼接不上展现数据而丢弃的情况,在这里,我们进行了一个优化处理,就是将所有处理后的点击日志,存放在 redis 中,定期(72 小时)清理,然后用展现日志去 redis 中进行点击日志查找,这样就算是展现日志出现延迟的情况,对拼接率的影响也不大。
2. 特征升级
基础版模型中,有一类特征是比较难有效处理的,就是 id 类特征,例如二手车业务线中的车型,车系,品牌等,这类非连续类型的特征,无偏序关系,在基础版模型中,将其取值直接进行 md5 值编码后放入模型中,由线性模型的记忆功能去使得这些特征发挥作用,但这种处理方式的泛化能力较弱,制约模型效果。
在深度学习出现以后,其强大的表征能力,能对人工特征工程进行有效补充,对于一些之前较难处理的特征,例如上述离散类型特征,能进行较好的表征,我们采用其 embedding 的能力,再结合 attention 机制,对部分离散类似特征进行了升级,取得了较好的效果,以二手车业务线两类特征为例:
(1)用户兴趣类特征处理
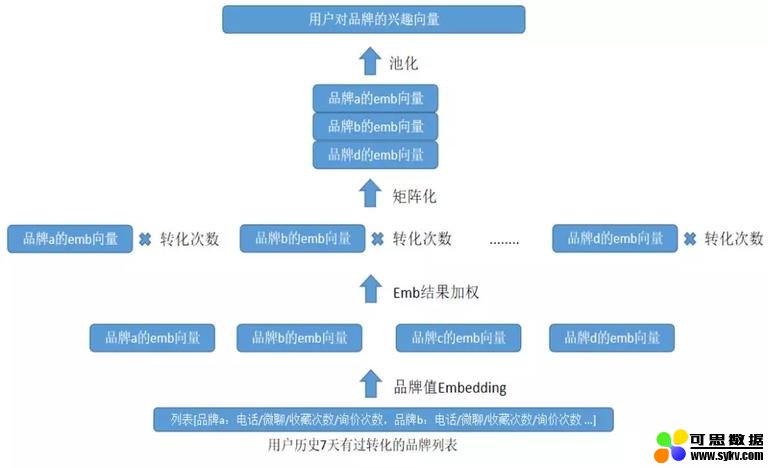 图 3 用户兴趣类特征处理
图 3 用户兴趣类特征处理
用户兴趣类特征向量的生成流程相对其他特征要复杂一些,如图 3 所示输入的信息是用户对某些属性的累积操作数量,先对属性的离散值进行 embedding(这里使用的 TensorFlow 自带的 api:tf.nn.embedding_lookup,其原理本身是可以训练的全连接层),然后使用累积操作的数量,对 embedding 结果进行加权(标量乘以向量,attention),形成兴趣矩阵,最后进行 pooling 操作,使其变成固定长度的兴趣向量。
(2)用户跟当前帖子属性的交叉特征处理
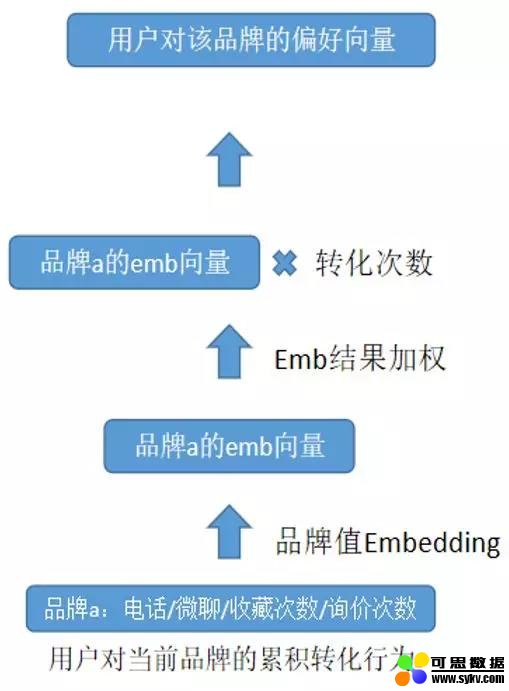
图 4 交叉类特征处理
以用户对当前品牌的累积转化行为特征为例如图 4 所示,属于用户跟当前帖子属性的交叉特征,跟用户兴趣特征向量的区别在于,直接输出 embedding 后的加权向量即可。
将这些特征表征好后,其表征方式将跟随模型一起进行学习,最后生成的表征向量,是满足模型优化目标的最优化表征方式。
3. 特征升级
对模型的升级动作主要有三种,实时模型,多任务模型,相关性模型,下面将分别进行介绍。
a) 实时模型(Online training)
业界对于模型时效性提升有过一些探索和尝试,比较主流的三种方式分别是 1. 动态特征(实时特征)+ 静态模型;2. 静态特征 + 动态模型(实时训练);3. 动态特征 + 动态模型。这里我们的对模型的升级,指的是模型的实时训练(Online training)。
在有了之前的实时样本流(见 3.1 数据流升级)以后,模型的实时训练就能较方便实现了,实时训练中,模型我们采用的是 FTRL,该模型的稀疏性较好;开启实时训练后,每 10 分钟,会 dump 一份模型,推送到线上服务器,线上预估服务支持模型热加载,达到 Onlinetraining 的效果。
b) 多任务模型
基础版中,针对单一因子进行单独建模和预估,例如点击率(展现到点击)预估模型,转化率(点击到转化)预估模型,会有三个问题(前两个问题参考阿里 ESMM 模型论文 [1]):
(1)样本选择偏差
传统 CVR 模型预估使用的是点击到转化的样本,而预估的时候,是在整个样本空间(展现 -> 点击 -> 转化)进行预估,由于点击事件只是展现事件的一个子集,仅从点击事件中获取的特征,相比全局是有偏的,并且从一定程度上违背了机器学习中训练样本和测试样本必须独立同分布的准则。样本选择的偏差,会影响到模型的泛化效果。
(2)训练数据稀疏问题
- 本文地址:http://www.6aiq.com/article/1575265821104
- 本文版权归作者和AIQ共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出
- 知乎专栏 点击关注
相比展现和点击,转化要低出好几个量级,高度稀疏的训练数据,会给模型
训练增加很多困扰,在二手车上,这个问题尤为明显,每天广告的展现是千万量级,点击是百万量级,转化是万量级,很稀疏,严重影响模型训练效果。
(3)模型维护成本
每条业务线都有对点击率和转化率预估的需求,如果拆分建模,意味着需要
维护的模型数量最少是业务线叉乘模型数量,会带来双倍的维护成本,并且大多数时候,点击率预估模型和转化率预估模型的特征都高度重合,重复建模的意义较低。
对于上述这些问题,我们参考阿里的 ESMM 模型 [1],对现有点击率转化率预估模型进行升级。
ESMM(全样本空间多任务学习模型)借鉴了多任务学习的思路,分别拟合 pctr 和 pctcvr(展现到转化的转化率),有效缓解了上述两个问题,相比传统 CVR 预估模型,其有两个特点:
(1)全样本空间建模
pcvr(点击到转化的转化率)可以通过 pctcvr 除以 pctr 推导出来,在 ESMM 模型中,pcvr 只是一个中间变量,没有直接去预估,模型预估的是 pctr 和 pctcvr,这两个模型都是在全样本空间(所有展现)进行建模,所以推导而出的 pcvr 也是基于全样本空间得到的,不像传统 cvr 预估只在点击样本空间建模,解决了样本选择偏差的问题。
(2)共享特征表达
一般神经网络的输入层,会对特征进行 embedding,其作用是把一些高维度的 id 特征,映射成低维向量,是特征更好的表达方式,能有效提升模型效果,但是进行 embedding 层的参数训练,需要大量的训练样本,ESMM 里面对于 cvr 的子任务,其跟 ctr 子任务共享 embedding 表达,这种共享机制,能使得 cvr 子任务能够从只有展现没有点击的海量样本中,对 embedding 进行充分的学习,极大缓解训练数据稀疏问题。
我们在二手车上使用的升级后的模型如下图,底图来自 ESMM 原论文 [1]:
图 5 二手车业务使用的多任务模型
在二手车上实际落地 ESMM 的过程中,我们还是遇到了 ctr 子任务正常收敛,cvr 任务基本不收敛的情况,后面整体分析,还是由于转化的正样本过于少导致,这里我们目前采用对转化进行重采样来进行解决,重采样后,cvr 子任务能正常收敛,但该处理方式会导致 cvr 预估值和真实值有偏,但不影响序,在部分只依赖 cvr 序的场景下可以正常使用,在部分需要跟其他影响因子融合的场景下需要对 cvr 预估值进行校准后使用,后续这部分会考虑更优雅的解决方案。
c) 相关性模型
相关性模型的构建主要是为了支持粗排和精排环节,这里重点讲一下在粗排的应用,因为粗排的帖子量过大,在粗排阶段,无法进行复杂的精排模型计算,于是考虑将用户和帖子转变为向量,在线上进行向量的余弦相似度计算,通过帖子向量跟用户兴趣向量的内积得分来进行粗排,同时对于一些重要因子进行显式强化,当前线上相关性模型打分公式如下:
相关性打分 = ʎ* 强意图 + (1-ʎ)* 弱意图
其中强意图指的用户搜索 / 筛选行为,因为这些行为能定位到具体帖子属性上,可以明确知道用户的关注点;弱意图指的是用户的点击 / 电话 / 微聊行为,因为这些行为只能定位到帖子上,无法明确知道用户是对该帖子中哪些属性比较关注。
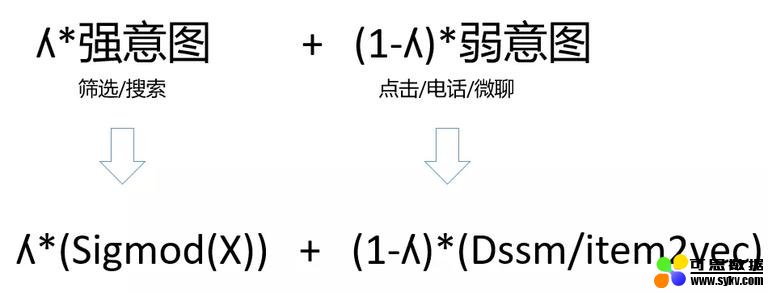
图 6 二手车业务使用的多任务模型
这里强意图部分我们采用了一个线性加权的方式,其中 X:θ1w1 + θ2w2 +…+ θi*wi(当前帖子的属性在用户历史筛选 / 搜索行为中的加权和,其中θi:1/sqrt(1+dayi)(当前属性的时间衰减因子),wi:1 (当前属性的权重,第一版中都暂定为 1)),将输出结果使用 sigmod 函数进行归一化;弱意图部分采用用户向量和帖子向量的余弦距离,这里计算用户向量和帖子向量,使用的模型有 dssm[2](深度语义匹配模型)和 item2vec[3] 模型。用户向量和帖子向量简要数据处理流程请见下图:
图 7 用户向量和帖子向量简要生成流程
4. 排序机制升级
基础版的排序中,只支持单因子(CTR/CVR/ 相关性等)排序,在部分业务线的某些商业产品中,需要同时考虑到 CTR,CVR,相关性以及一些业务规则,例如房产上的视频 / 安选房源加权,二手车上的真车加权等等,支持多个因子的融合需要在排序机制层面进行升级。
升级后的排序机制请见下图:
图 8 多因子排序框架
升级后的多因子排序框架,支持分层排序(按某个因子进行强分层,层内按其他因子进行排序),支持加权融合,支持自定义融合(乘法融合等),支持层内嵌套分层,能够灵活支持业务线各个商业产品多元化的排序需求。
总结、展望或规划
完成上述四部分升级后,我们目前的排序模型能力如下图:
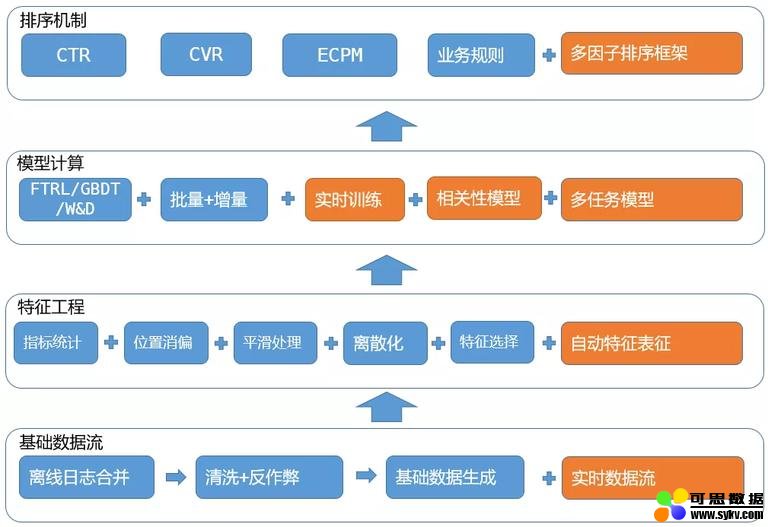
图 9 当前排序策略能力
目前该升级后的排序能力已经陆续应用于多个业务线,对变现效率和连接效率,带来了显著提升。
后续将在以下几个方面继续进行深入的探索和优化:
(1)数据流:引入数据清洗模型算法,进一步去除噪声,同时支持按指定维度进行自动采样;
(2)特征工程:结合具体业务,引入更多数据,进一步提高特征工程的自动化程度;
(3)模型计算:紧跟业界前沿,探索多模型融合,大模型嵌套子模型,模型压缩等方向;
(4)排序机制:构建多目标离线评测环境,支持融合因子的自动探索,提高迭代速度。
参考文献
1.MaX, Zhao L, Huang G,et al. Entire space multi-task model: An effective approachfor estimating post-click conversion rate[C]//The 41st International ACM SIGIRConference on Research & Development in Information Retrieval. ACM, 2018:1137-1140.
2. HuangP S, He X, Gao J, et al. Learning deep structured semantic models for websearch using clickthrough data[C]//Proceedings of the 22nd ACM internationalconference on Information & Knowledge Management. ACM, 2013: 2333-2338.
3.BarkanO,Koenigstein N.Item2vec:,neural item embedding for collaborativefiltering[C]//2016 IEEE 26th International Workshop on Machine Learning forSignal Processing (MLSP). IEEE, 2016: 1-6.
——作者简介——
刘笠熙,商业产品技术部 - 策略技术团队算法资深开发工程师,负责 58 同城多条业务线(二手车、租房、招聘、黄页)的商业流量变现效率和连接效率的优化提升,目前主要专注于预估排序策略的优化迭代。

时间:2019-12-02 23:50 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















