360 展示广告召回系统的演进

文章作者:王华呈 360 资深算法工程师
编辑整理:杨辉之
内容来源:爱奇艺技术沙龙
出品社区:DataFun
导读: 随着展示广告业务数据量的日益增长,360 展示广告召回系统也随之也进行不断升级改进。本次介绍主要从召回系统演进的角度详细阐述工程实践中的算法应用、技术难点以及解决方案。主要分成三块:第一个是 360 展示广告的大致介绍,第二个是整体架构介绍,第三个就是今天的主题召回模块的演进脉络。
▌1. 展示广告介绍
1.1 展示广告业务介绍

展示广告主要是在 RTB 程序化购买框架下运行的,首先有媒体方,比如新浪、搜狐等市面上的各大媒体,我们都已经接入。媒体在一次曝光产生之前会把这次曝光发送给 Ad Exchange(ADX)模块进行拍卖,360 的 ADX 平台叫 360 Max。ADX 平台将该曝光发送给多个竞价平台 DSP,DSP 来决定是否对该次曝光进行竞价,360 的 DSP 平台叫 360 点睛 DSP。广告主们会针对自己的需求设置广告投放策略,DSP 平台会从广告主设置的广告投放库中根据该次曝光的特征匹配出合适的创意(广告)候选集返回给 ADX。一般要求 DSP 的响应时间为 100ms 左右,除去网络传输耗时,留给 DSP 模型的时间只有几十毫秒,其中间各个模块的时间就更少。ADX 从接收到的所有候选集中选择出价最高的广告进行曝光。
1.2 常见展示广告
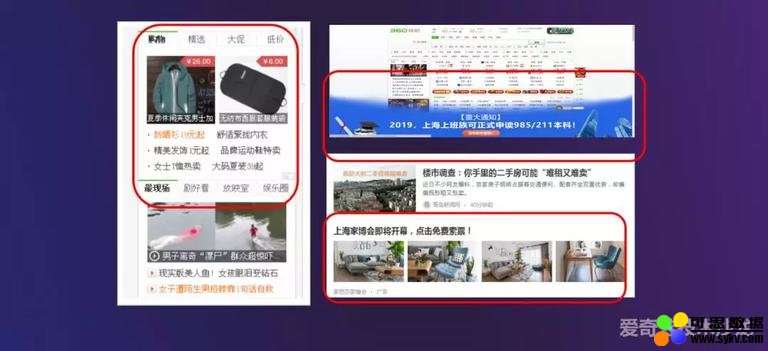
目前在 360 场景下主要有这几种广告类型,第一种类型是广告侧边栏,包含具体投放广告的详情页。第二种类型是整体的开屏广告,主要是品牌广告。第三种类型是在信息流场景下,将广告嵌入新闻上下文中且与文章内容形式保持一致。
▌2. 展示广告整体架构介绍
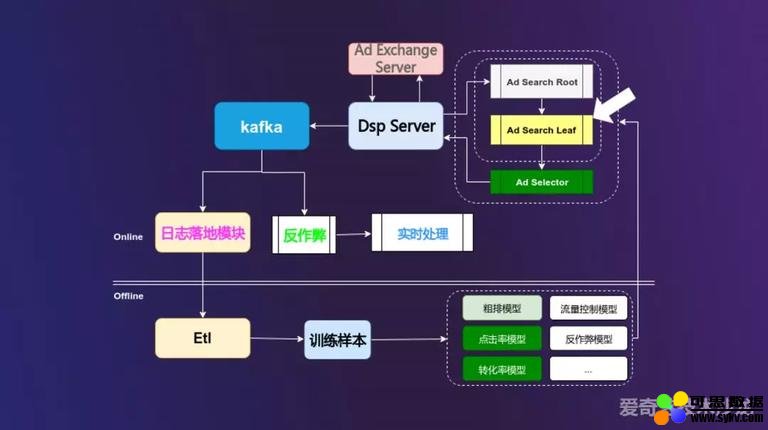
整体架构流程:
流量从 ADX 发送给 DSP 端,DSP 拿到流量之后交给检索召回模块,我们叫 Ad Search 模块,Ad Search 模块分为两个部分,一个是 Ad Search Root 模块,对流量进行识别,判断其为哪种类型的流量,比如 keyword 流量、信息流流量、banner 流量,然后交给不同级别的 Ad Search Leaf 模块对广告进行召回,选出相匹配的广告初步候选集,该模块就是我们今天的主题。然后将选出的广告初步候选集交给 Ad Selector 模块进行精排,即对广告的 CTR 或者 CVR 预估,进行打分,选出 top K 个广告返回给 DSP Server。同时 DSP Server 会将点击、曝光、后续的日志写入 kafka,并进行日志落地,日志落地后会进入后续的 ETL 离线流程,用于后续粗排、点击率等模型生成训练样本使用,另一部实时数据日志数据流会经过反作弊模块后过一遍 ctr 预估的 online learning 和实时曝光反馈的 online feedback。
▌3. 召回模块的演进脉络
3.1 检索召回模块
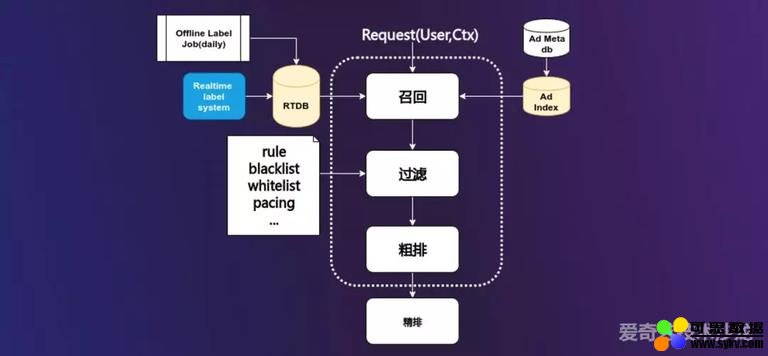
Ad Search Leaf 召回模块展开来主要分三个阶段,召回、过滤和粗排。召回模块接收到 DSP 给流量请求中包含了用户信息和上下文信息。广告主设置的广告投放存在 Ad Meta db 中,然后建成相关的广告索引(Ad index),投放更新后才会实时更新这个索引。RTDB 主要存储用户标签数据,标签数据一部分是通过请求中带的用户信息和上下文信息进行用户标签的实时更新,另一部分是通过线下离线全量更新。召回模块就是结合这两端选出初步的广告候选集,然后进入过滤模块(正排模块),过滤方法主要包括基于规则、黑白名单、广告主预算 pacing 过滤。最后进入粗排模块,对初选的广告候选集按评价函数模型进行打分,但没有精排模块那么复杂,相对比较简单,比如最开始基于核心特征的 LR 模型,后续升级过基于特征交叉的 FFM 模型。
3.2 召回通路
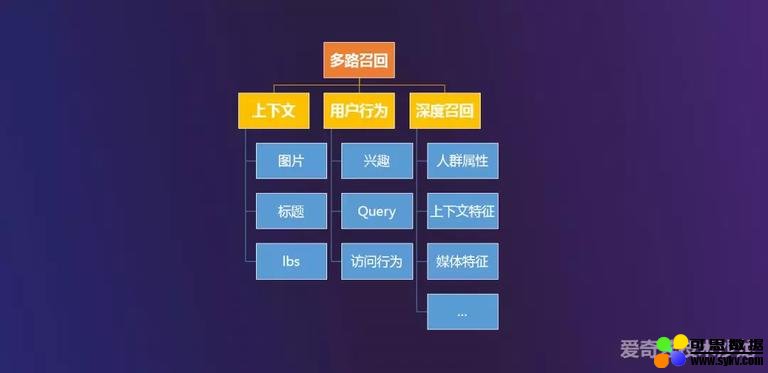
接下来讲一下在我们检索召回中一些通路,我们是进行多路召回的,其中有三种类型,第一种是上下文、第二种是用户行为、第三种是当前正在做的深度召回。
上下文召回有这几种类型,第一种是基于图片的,在内容页场景下,一个明星穿了哪件衣服,根据这件衣服投放哪件商品,做法是将图片向量化,计算广告商品与图片向量的相似度进行召回。第二种是基于标题的,主要是基于文本 NLP 相关模型进行召回。第三种是基于 lbs 的,广告主自身设定某个标签区域进行投放,在该区域内进行标签匹配召回,属于布尔召回。
用户行为召回有这几种类型,第一种是基于兴趣的,基于用户历史行为建立用户画像,打上兴趣标签,进行布尔召回。第二种是基于 Query 的,利用用户的 query 历史行为,进行 NLP 相关模型进行召回,与基于标题的方式类似。第三种是基于访问行为,利用广告主回传的用户商品行为,采用 Item CF、ALS、Neural MF 等模型进行召回。
最后一种召回通路是深度召回,主要是把 user profile、媒体特性、上下文特性等特征结合起来进入深度模型中进行召回,接下来会具体介绍下这个是如何做的。
3.3 基于文本的召回

上面讲的标题和 query 召回主要是文本召回,包括几种,第一种是精准匹配,有完全匹配和基于 ngram 的 TF-IDF 提取核心词匹配,属于比较简单的方式。第二种是模糊匹配,有 word2vec 和 DSSM 语义化模型,将文本语义向量化,然后按向量化检索召回。第三种是广泛匹配,是把语义化向量聚类成多个标签,然后按标签召回。
3.4 召回模块演进

我们的召回模块演进主要是分成三个阶段,第一种是布尔召回,刚才介绍的信息标签类型和 lbs 都是基于这种。第二种是向量检索召回,利用深度学习模型将广告、用户等信息都映射为向量,然后进行向量检索召回。第三种是我们现在在做的基于深度树的匹配。三个阶段是由浅入深的过程,接下来我们依次介绍这三个阶段。
3.5 布尔召回

布尔召回在早期检索中都会用到的,我们的方式是基于树 + 维度 bitMap 分组 + 哈希表。广告主设置定向组合,比如访问某些网站的人群、有特定兴趣的人群等其他各种定向组合。而请求中会带有用户标签,问题就变成了怎么找到与用户标签匹配的定向组合广告?布尔召回本质就是基于倒排索引的布尔运算,所以关键在于倒排索引怎么构建?构建的方式有两个层级,第一层索引是将广告主的投放配置进行分解分组,每一个组为一个 conjunction,一个广告投放会对应多个 conjunction,这样就可以建立 conjunction 到广告投放的倒排索引。第二层索引在于根据用户标签找到对应的 conjunction,我们的标签是一个 int64 类型的整数,高八位的某些 bit 位会做一些标识,来区分这个标签属于哪种类型,拿到用户的标签做位运算,找到 bitMap 分组的 conjunction list。然后到基于每个 conjunction 到第一层取出对应的广告主集合,最后计算每个集合的交并,得到最终召回的广告候选集。
在实际使用中布尔召回有一些问题,比如倒排表有部分 conjunction 对应的广告集合很长(>1w),检索性能很差,我们的实际解决方案是在布尔表达式中做一个转换,比如将先并后交的布尔运算改为先交后并的布尔运算,能极大优化检索的性能。
- 本文地址:http://www.6aiq.com/article/1571971895488
- 本文版权归作者和AIQ共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出
- 知乎专栏 点击关注
3.6 向量化召回
我们在实际向量化召回中有两种类型,第一种是类似于早期 YouTube DNN,把用户变成一个向量,把 item 也变成一个向量,最后做一个向量相似度检索。第二种是用户相关历史内容变成一个向量,再进行向量相似度检索。两种类型都是基于两个向量的相似度进行检索,得到 item 候选集。

实际中我们选择的是微软提出的基于深度语义检索模型(DSSM),该模型的输入是一组相关的 Query 和 Document,以及两个与 Query 不相关的 Documents,然后分别 dense 为 embedding 向量,再经过 NN 网络,再做 softmax 打分,得到三个分数,训练目标就是是相关的 Document 分数尽可能高,不相关的 Documents 尽可能低。中间的 NN 层可以有多个选择,可以为多层 FC,也可以类似 textcnn 那样为 CNN+FC,或者为 RNN。

在通过模型向量化之后就涉及到向量索引该怎么选择?下面介绍下常见的几种。第一种为 LSH(局部敏感哈希)索引,方法就是基于多个哈希函数进行分桶,比较耗内存。第二种为 faiss 提出的 IVF Flat,方法是构建由聚类中心向量构成的倒排表,针对输入向量,先找到聚类中心向量,再基于 KNN 方式进行检索,这种类型是保留精度的,效果跟直接暴力检索非常接近,但性能有很大的提升。第三种为 IVF PQ,也是基于倒排,与 IVF Flat 区别在于在向量上做了有损压缩或 PC 降维,好处在于省内存,但是带来了实际检索精度的丢失。这三种可以根据实际业务场景进行选择。

3.7 深度树召回

上面讲的布尔召回和向量化召回都有一定的缺点,比如布尔召回的有些 conjunction 的候选列表非常长,容易遇到性能瓶颈。向量检索会局限于模型的向量表达是否准确,而且向量空间有限。这里参考了阿里妈妈提出的深度树匹配(TDM)模型,深度树匹配能解决全量检索的性能问题和模型精度问题。如何构建一个深度检索树呢?在广告场景下选取的是基于 ecpm(千次曝光预期收益)最大堆方式,最大堆树下当前层最优 Top K 孩子节点的父亲必然属于上层父节点的最优 Top K,这样就可以从根节点逐层递归向下挑选 Top K 直至叶子层,同时极大提高检索速度。为了简便起见,我们构建树的形式是二叉树,则检索 Top K 的时间复杂度是 2KlogN,N 为 item 个数,且随着 N 的增长,相比暴力全量检索的性能提升更为明显。
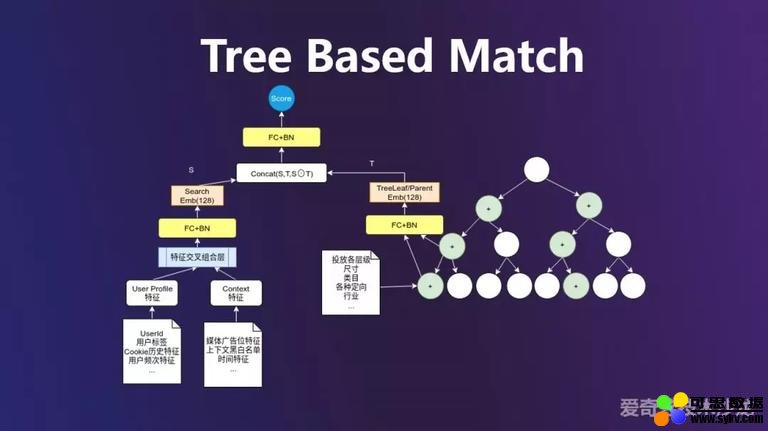
深度树模型的大致结构如上图所示,分为两部分,左边是流量端,包括用户 profile 特征(如标签、cookie 历史行为、频次等)和上下文特征(如媒体广告位属性、黑白名单、时间特性等)。首先把这两种特征 dense 化变成 embedding,再做特征交叉组合,在我们场景下特征交叉采用的是 IPNN 方式,然后再经过 FC+BN 的多层 NN 网络,最终转化为 Search 端的 embedding,线上处理时,左边这个流程每次请求都会计算。右边是候选集端,是一颗检索树,叶节点就包含了广告投放信息,包括尺寸、类目、行业等广告主设置的定向信息,叶节点和父节点本质都是同一维度的 embedding,都会进入 FC+BN 层,形成与 Search 端 embedding 相同维度的 Tree Leaf 和 Parent embedding。左右两端的 embedding 做交叉 +concat 操作进入 FC+BN 层,最终得到一个分数,与样本 label 按交叉熵损失进行训练。整体的模型架构就是这样。
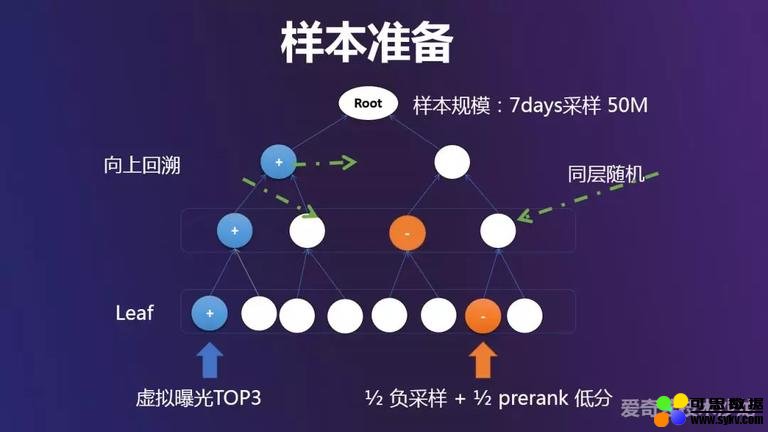
那我们要怎么准备这颗树模型的样本呢?有两部分,分别为 leaf 样本和 parent 样本,对于 leaf 节点,选取精排模型输出的虚拟曝光 Top3 作为正例。负例包括两部分,第一部分是在正例叶子节点同层,随机选取其他叶子节点作为负例,第二部分是选择粗排阶段的一些负分 item 标识为负例。对于父节点,基于 ecpm 最大堆原理,将正例向上回溯的所有父节点都标记为正例,同层随机标记为负例。整体的样本规模是用了 7 天的采样曝光样本,大概在 5000 千万左右。

接下来我们该如何生成这颗树呢?我们这里有两种方式,第一种方式就是随机生成,将 item 随机放到叶结点上,当然也可以根据标签体系手动把相近的 item 放在同一个父节点下,基于随机深度树训练一轮,将叶子结点的 embedding 导出来,然后聚类,这样就可以根据聚类的结果重新生成一颗树,然后再去训练,一直迭代到指标变化不大。第二种方式就是自下而上合成树,先当这颗树不存在,只训练每个叶子结点的 embedding,然后根据叶子结点的 embedding 向上聚类回溯成一颗树(kmeans 或者根据曝光频次来聚类),接着就可以与第一种方式一样一直迭代直到指标变化不大。

我们最后选择方式是第二种方式,第一步就是先训练叶子,把叶子 embedding 导出来,然后聚类生成一颗树,基于这颗树结构重新训练叶子结点和父节点的 embedding,得到最终上线的模型。

接着我们来讲一下这个模型的 loss,我们的目标是去拟合曝光,所以 loss 由两部分组成,第一部分是交叉熵损失,去拟合对应的样本是否曝光。第二部分是 triplet loss,含义是叶子节点中正样本之间距离尽可能相近,而与负样本之间的距离尽可能远,来约束叶子距离。第一部分 loss 考虑的是拟合曝光,并没有考虑点击,所以可以把实际用户点击的样本进行加权,把即曝光又点击的样本着重考虑,体现重要性。

线上如何检索呢?因为我们是基于最大堆的,所以采用的基于 beam search 的方式,就是逐层往下的检索,每一层都保留 K 个节点并往下扩展。
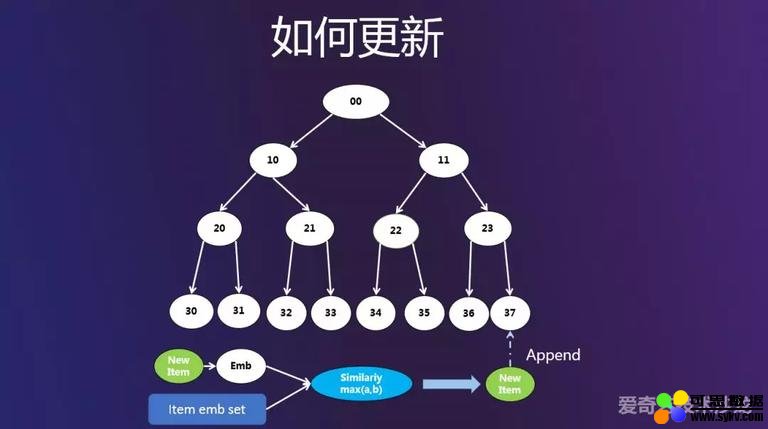
实际线上投放是有变化的,广告主会新增一些投放,对于这种新增投放怎么添加到这颗树中呢?比如新增一个 item,我们会根据训练好的模型把 item 对应特征转换为 embedding,然后把之前训练的叶子节点的 embedding set 拿出来,然后做一个相似度检索,得到 item embedding 最接近的叶子节点 37,将该新 item 加入这个叶子节点 37 的 list 中去(线上训练时,叶子节点实际是一个 cluster,一个列表,并不是一个单一的节点)。
▌4. 性能优化

最后提一下我们在实际中做的一些性能优化工作,主要介绍两方面:
第一方面是在检索阶段,针对树的最上几层,会根据 Top K 的大小,进行跳层(父节点个数
第二方面是训练阶段,因为我们是基于 tensorflow 构建模型的,所以有常见的几种优化方式,比如避免使用 feed dict,使用 dataset 这种高阶可以并行化的 api。同时可以使用 Timeline Profile 等工具分析性能瓶颈,进行针对性的优化。针对 python GIL 的缺点,将高频调用的 python function 利用 c++ 实现进行调用,并在调用前将 GIL release 掉,避免锁带来的性能影响。
▌参考资料:
1. Learning Tree-based Deep Model for Recommender Systems
https://arxiv.org/abs/1801.02294
2. 微软 DSSM 项目地址:
https://www.microsoft.com/en-us/research/project/dssm/

时间:2019-10-26 11:10 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















