微博广告策略工程架构体系演进
导读: 本次分享的主题为微博广告策略工程架构体系演进,将介绍微博广告在从 0 到 1,从 1 到 N 的过程中,微博广告架构是如何支持策略、算法、模型迭代的,包括以下几部分:
-
概述
-
微博广告策略工程架构体系演进
-
精益驱动思想工具:“两翼计划”
▌概述
1. 广告样式与场景
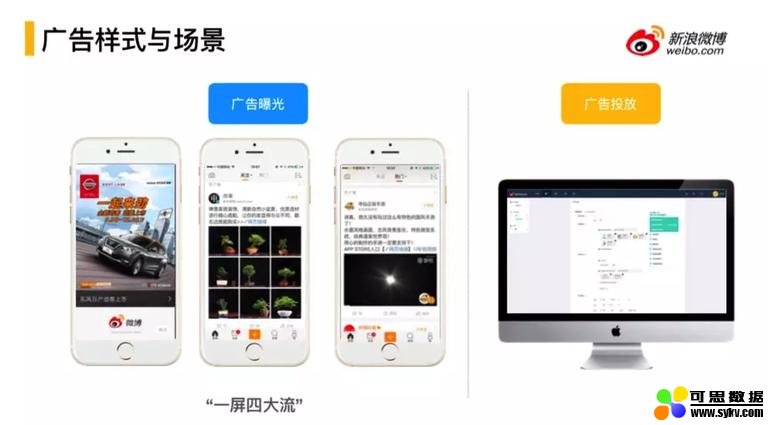
上图是微博广告目前商业场景流,“一屏四大流”。“一屏”指打开微博的 Fashion,“四大流”指占据微博商业化的主体,包括关系信息流、热门流、评论流和热搜流。右图为广告投放的后台。
2. 广告参与方

如上图,做计算广告首先面临这些概念,根据不同的广告主的规模和对公司的重要程度分为 KA 类和中小类。KA 类往往是进行广量式的购买。中小类,常规的客户会进行竞价。
常见的计费方式有:CPE,CPM,CPD。
目前在互联网市场在大规模推广 OCPX,OCPX 作为一种需要很高的技术含量,也是一种很好的降低广告主投放风险的售卖方式。
3. 计算广告核心问题
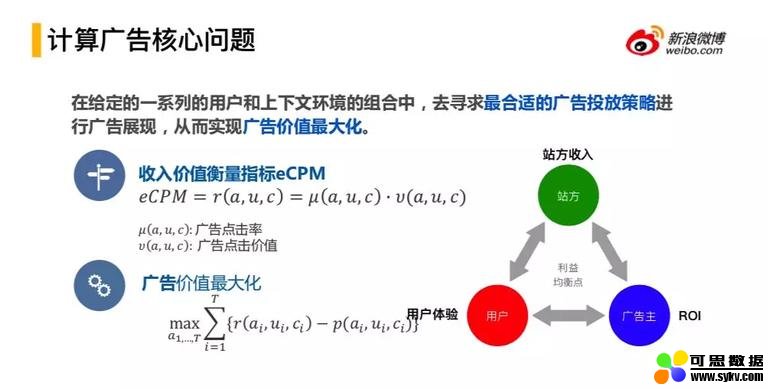
这是广告涉及到的三方:平台(站方)、用户、广告主,在计算广告设计时的核心问题是如何追求三方之间均衡的、整体的利益最大化。
4. 广告投放流程
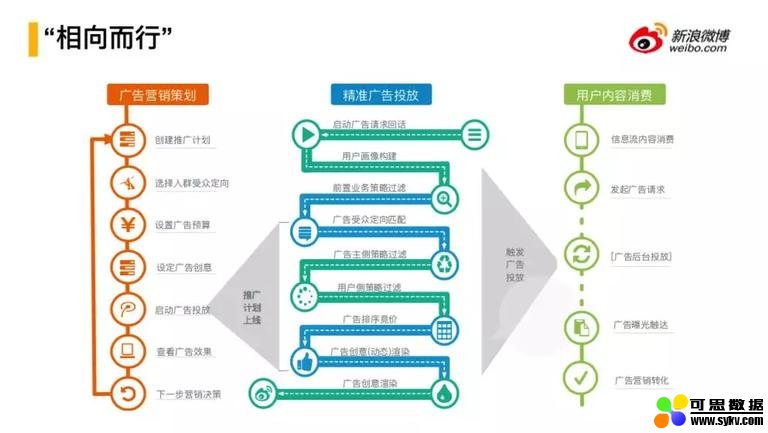
以上是一般的广告的投放流程。这是从广告主的视角、平台的视角以及从用户的视角来公共完成三方“相向而行”的活动:
广告营销策划的流程:创建推广计划 -> 选择人群受众定向 -> 设置广告预算 -> 设定广告创意 -> 启动广告投放 -> 查看广告效果 -> 下一步营销决策。
精准广告投放:针对广告库存请求,会对用户进行精准用户画像刻画,然后做广告的召回,对广告进行粗排和精排,挑选广告,根据不同平台进行广告创意渲染工作,最后展示给用户。
用户内容消费,比较简单请看图中流程。
▌微博广告策略工程架构体系演进********
**1. 微博广告工程架构发展史
**
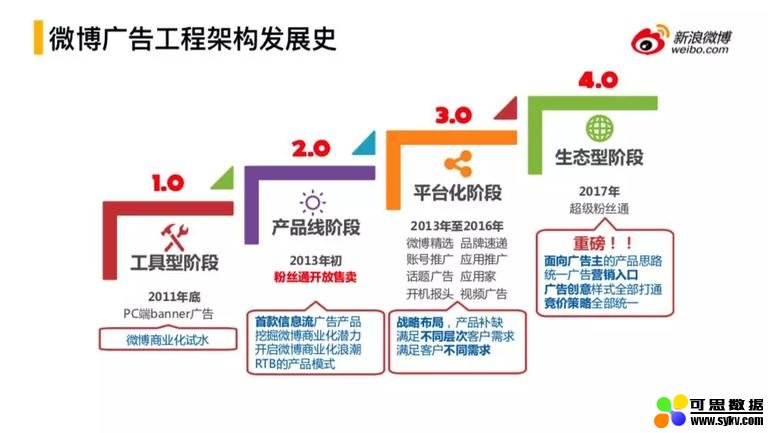
微博商业化进程不断的发展,支撑商业化的工程架构会随着具体的业务需求做改变。
刚开始做的是非信息流的广告,按照传统的方式会试投一些 banner 在微博,目前 banner 在微博的移动端已经没有了。从 1.0 版本简单弹窗式的广告系统,到 2.0 版本以粉丝通为代表的产品线陆续的孵化出来,这时候微博开始进行信息流广告的研发。微博是国内信息流广告的第一家,在探索中孵化出一系列的广告产品矩阵,为了产品的快速上线,复制了大量的广告系统,为了改变这一状况,随着 17 年底超级粉丝通的上线,对广告系统进行了整体重构,从此微博广告工程架构进入了 4.0 时代。
2. 投放系统架构 4.0
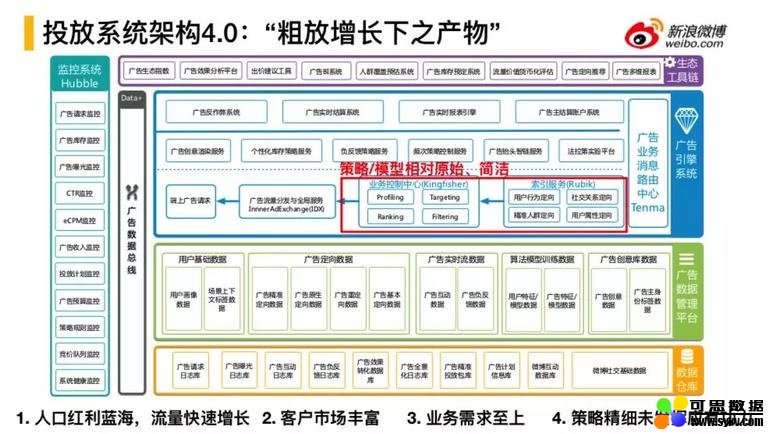
上图是 17 年的工程架构图,是随着微博广告产品线的探索演化出的工程架构 4.0 版本,当时处于流量的蓝海阶段,所以通过配合广告客户和广告预算的不断增加,不断提升广告系统的稳定性、高可用性、高并发来不断的实现广告收入的增长。因此我们也对系统进行了分层化的梳理,图中蓝色的区域是线上广告投放系统最核心的链路。通过广告请求,流量统一接入,接入包括微博多个产品矩阵,广告的请求会对多个产品矩阵进行请求分发,通过统一流量价格评估,对用户的请求进行响应。整体上这样一个引擎结构是为了不断的满足产品提出的面对客户的需求来进行的架构设定。
其基本流程是广告请求,广告库存接入,到总体流量的分发,请求用户的画像,经过竞价服务,会进行广告触发,会请求在线索引服务,形成比较完善的行为定向体系,包括:
1. 用户的行为定向。在微博上的行为定向,比如,对话题的互动,热门微博的互动,热搜人群的互动等。
2. 社交关系定向。比如关注的大 V 信息,如果在某个大 V 信息下用户的群体能理解为自然形成的社会群体,那么这个大 V 信息下面的粉丝群是可以进行选择投放的。
3. 精准人群定向。是由平台方或第三方的数据加工,或广告主根据一次投放效果进行的召回,或已有的客户信息形成的用户粒度聚合后的数据包,这个就是精准用户的集合。
4. 用户属性定向。包括用户画像,年龄、地域等。
以上是整体的在线投放流程,但是投放流程仅仅有以上这些是不够的,还包括个性化库存策略,广告的负反馈的策略,智能频次控制策略等,以及配套的 A/B Test 系统,这样就形成了广告投放的在线服务群。
由于流量来自于微博站方,所以微博广告请求是无需流量反作弊的。存在的反作弊主要是针对互动回传,也就是说广告投后的后链路数据的回传会有大规模的反作弊策略,当然也包括社交互动。然后会有一个实时的结算中心—结算系统,提供给广告主需要的报表,以及与广告主密切相关的账户系统,总体上形成了投后链路在线服务群。
之下是属于近线的数据访问,按照数据分类:用户基础数据、广告定向数据、广告实时流数据、算法模型训练数据、广告创意库数据来制定线上这种实时访问的需求。
最下面属于线下的数据仓库。线上投放完的数据会进入数据仓库落地。
这就是广告数据总线,实现数据流的方式一般通过 kafka 机制等实现,然后汇聚到数据仓库里,对数据进行分门别类。
图中最左边广告的监控系统,会从系统的各个层面对系统进行业务运行状况的监控以及服务稳定性的监控、可用性的监控。这些就是业务层面完整的一个工具链。原来多个产品线就逐渐聚合到这样的一个系统当中。
4.0 时代的架构在整体上是为了“粗放式增长”而设定的工程架构体系。这种粗放增长的客观现实是,广告预算供应的持续提升和微博不断供给的流量变现规模,以及不断增加广告主的数量、预算和规模,来实现广告数的增长。这时对系统最大的考验是系统的高可用性,以及做业务需求时,对研发效率的保证,这样的架构就是“粗放增长之下的产物”。
这个架构体系是存在一些问题的(即红框中的):相对来说对策略模型是相当淡化的,也就是从功能架构层面对算法模型的迭代是比较简单的。比如 A/B Test 使用的是非常原始的 A/B Test,在这种在人口红利的情况下能够快速支撑广告业务的增长,但是随着人口红利的消失,已经不能很好的支撑广告业务的增长,这时系统对策略模型的支持显得异常重要。
3. 系统如何支持广告增长的转型
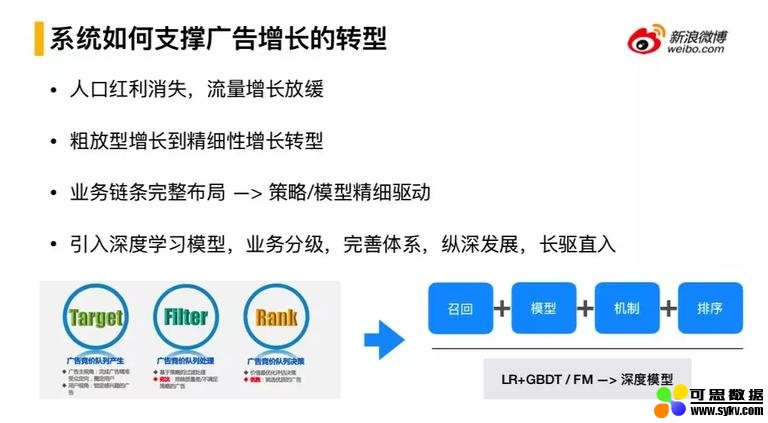
如何支撑广告增长的转型,会通过粗放型增长(扩流、扩广告主、扩预算)转型到精细化的增长,不断的提升投放效果来促进收入的增长。这时对应的系统需要进行转型,在系统不断完善的基础上,实现策略模型的良好驱动。在这种情况下随着算法不断引入新的深度学习模型,整体的工程架构也不断的深耕细作,从原来的业务划分方式(Target、Filter、Rank)转型成面向算法策略(召回、模型、机制、排序)的划分方式。
4. 流量漏斗模型 +
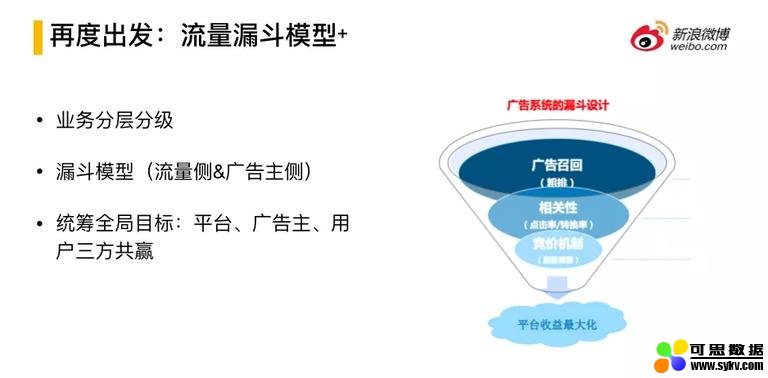
广告系统常用的模型:流量漏斗模型。对其重新进行思考和定义:开始是对广告进行召回,完成基于精准的最大概率展现,到相关性的挑选,再到以模型为核心的竞价排序机制。
本文不会从算法角度去讲解如何召回和相关性的机制等,主要是介绍工程是如何支持算法模型迭代的。
5. 面向策略的下一代投放架构
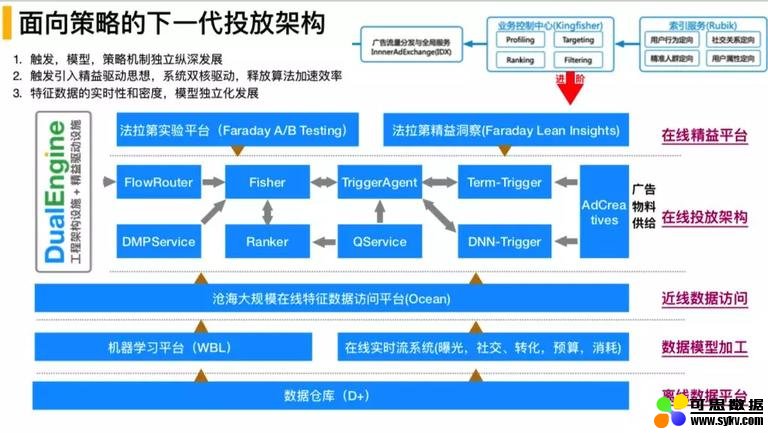
在架构系统 4.0 中的基础上对在线投放引擎进行业务分级,以满足新的流量漏斗模型。有以下关键点:
① 触发、模型、策略机制向独立纵深发展
系统在支持触发、模型、策略迭代上能够实现很好的各自的独立纵深发展,能够做到各自的快速迭代,互不影响。
② 引入精益驱动思想,系统双核驱动,释放算法迭代效率
在做整体的精细化转型的时候,系统需要不断的进行尝试,而尝试要有一个很好的尝试平台,所以引入了精益驱动的思想。在线精益平台包括:法拉第实验平台和法拉第精益洞察,这是一个比较好的促进业务模型迭代的工具链,更加注重数据的实时性和数据的密度。
系统架构总体上分为:在线精益工具平台、在线投放系统、近线数据访问、数据模型加工(曝光机器学习平台和在线实时流的机制)和离线数据平台
③ 特征数据的实时性和密度,模型独立化发展
重点说下在线投放服务,在服务中,会有流量接入,会有流量的触发,会有触发机制,包括多路触发,通过多路触发体制后,会有机制策略,包括模型预估服务,模型预估服务是聚合服务,会进行粗排、对数据进行裁剪,会在大规模分布式预估服务中完成,Ranker 也会基于预估进行精排。
特别说明一下,为什么进行粗排和精排,粗排我的理解是为了精排的性能考虑的,因为精排会涉及到大规模的精细计算,性能有可能会扛不住,所以需要粗排,而且在保证效果的情况下,为了性能的保证会有多级粗排。
最上面是法拉第实验平台和法拉第精益洞察。整体上会形成双核引擎:一个良好的工程架构体系和精益驱动的工具平台。
- 本文地址:http://www.6aiq.com/article/1568618069945
- 本文版权归作者和AIQ共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出
- 知乎专栏 点击关注
6. 如何支持广告物料的精准召回
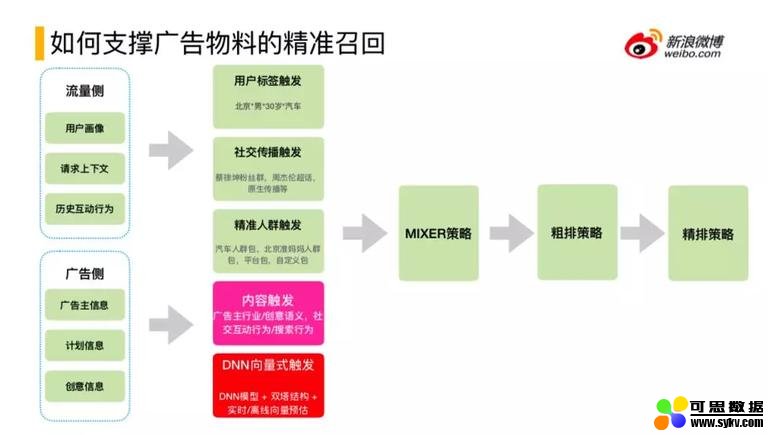
从微博广告的召回机制来看会有用户标签触发、社交传播触发、精准人群触发、内容触发、DNN 向量式触发,经过 5 路触发,会进行 MIXER 广告召回级的汇总,汇总后会有粗排策略、精排策略。
这里用到的信息,包括流量侧和广告侧。
- 流量策:
用户画像、请求上下文、历史互动行为
- 广告侧:
广告主信息、计划信息、创意信息
7. DNN 向量触发模型
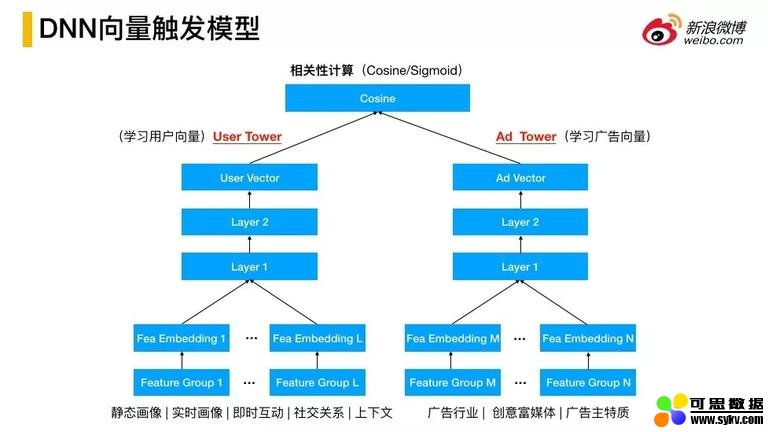
这里介绍下深度向量触发模型,用到的是双塔模型,包括用户侧和广告侧。用户侧根据用户信息进行训练生成用户侧的向量,用到了三层的神经网络,广告侧也是一样,整体来说训练都是采用离线的方式完成的,接下来会做实时的向量预估。进而在双塔汇合点进行相关性的判定,使用了简单的 cos 和 sigmoid 进行相关性的判定。
8. 触发工程架构
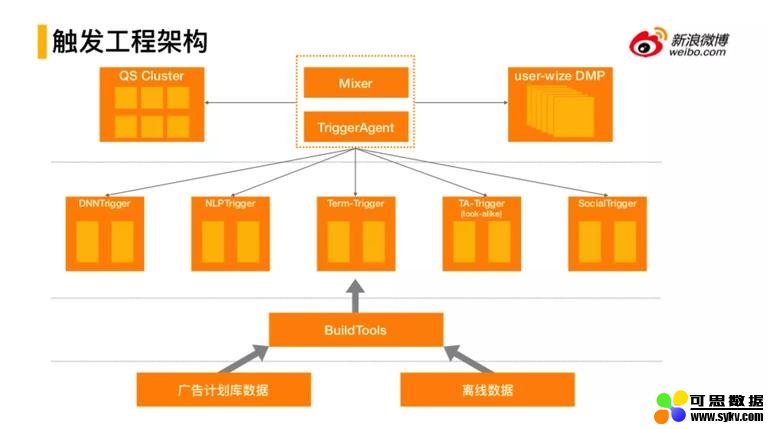
触发工程体系在如何更好的支持触发角度来说,研发了对应的服务体系。请求在请求召回时会触发 Agent 进行五路召回,包括双塔的召回、内容定向的召回、用户画像的召回、精准人群的召回、微博社交关系的召回,召回之后进行 Mixer,会结合质量预估服务进行裁剪。然后,线上会有实时的广告计划库数据和离线数据会对线上的五路触发分别根据需求进行访问,这样会形成一个整体的广告触发工程架构。
▌精益渠道思想工具:“两翼计划”
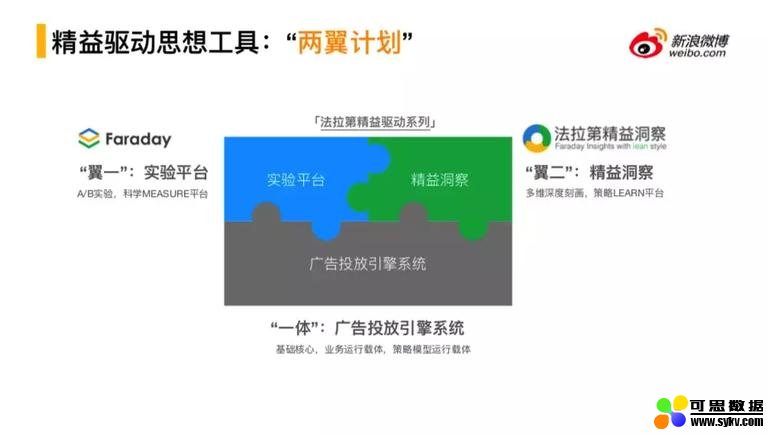
随着超级粉丝通在 17 年上线,考虑到微博广告从粗放式增长到精细化增长的转型,需要有一个比较好的实验平台和一种线上运行洞察的方式和思想,这样就构成了精益驱动思想的来源。包括两部分:一是进行线上策略的实验和调控,一个是用于线上策略运行的精益洞察,与在线投放系统一起,构成一体两翼策略工程架构体系。
1. 法拉第实验平台
① 法拉第分层实验模型
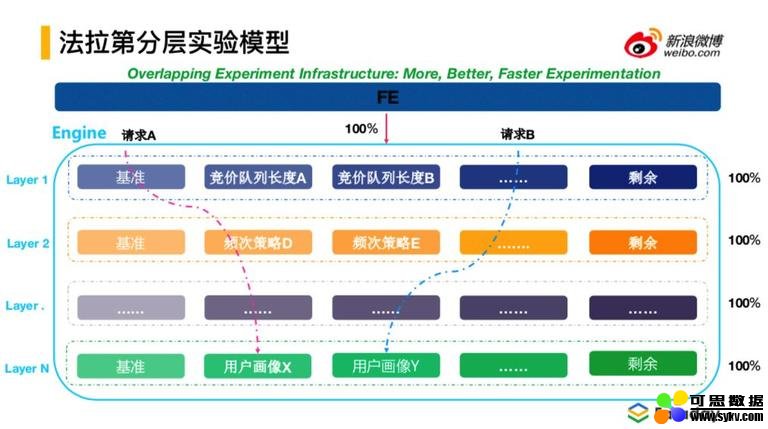
法拉第实验采用正交分层模型,这种模型在互联网行业一般都会使用,包括百度的爱迪生、阿里的特斯拉等。微博法拉第模型思想来自于 Google 流量正交分解模型的经典论文,为多层的独立实验提供了理论基础,当然实验也结合了微博广告的实际情况,包括刚开始解决从无到有的问题,对论文中的模型进行了简化。最开始是没有域的概念,整体上每一层都会使用 hash 函数。
② 实验分桶

虽然每个实验层共享 hash 函数,但是 hash 函数参数不同,参数包括流量标识和实验 id 标识,呈现出的是不同层的流量分桶划分是正交的。另外,也引入 Google 论文中提到的分配条件,场景应用很经典,例如做一个实验,会考虑流量的重用或者实验的一些特征,包括实验的地域、性别等,这样的话,使用圈定或限定下的流量而不是使用全部的流量;如果使用全部流量的话会造成实验效果不显著,实验效果被稀释,容易引起不置信。这样可以使流量重复复用,并且能很好的观测到策略所产生的实验效果。这就是流量分桶类型和进行流量圈定的分配条件。
③ 法拉第实验平台
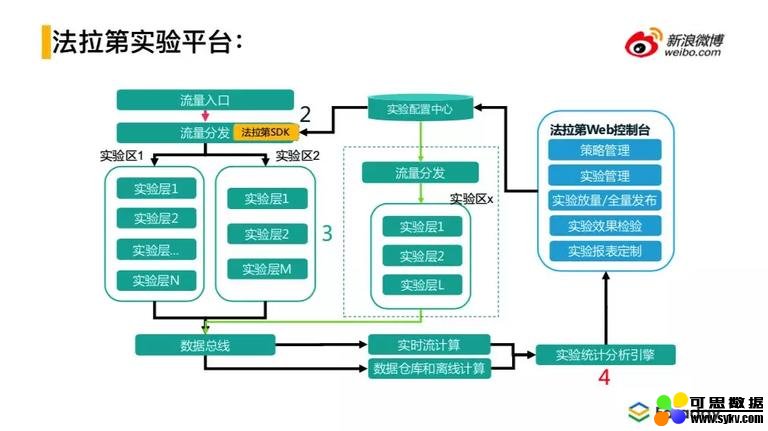
这个是法拉第实验平台的整体架构图。采用全程自动化的机制。通过法拉第的 Web 入口,进行实验信息的记录,在线上流量入口处进行实验的下发和解析,根据实验的数据信息,进行线上策略的调控,会对实验命中数据进行解析,进行实验的埋点,然后进入实时的分析引擎,统计实验效果。
实验的下发和解析有两种方式:
一种是在流量的总入口处统一进行实验的下发和解析,一步到位,然后请求信息一块下发,随着请求链路走,最后返回,命中那些策略会有对应的标识。如果实验数比较少时,解析无压力,实验相关性解析比较小,实验消耗带宽不大,此时是合适的。但是随着实验规模的增大,由于现在的广告系统是分布式的系统,如果完整的实验信息一直随着请求下发的话带宽消耗会非常严重,造成返回结果超时,可用性下降,实验时间就会变得很长。因此出现了另一种方式,由对应的服务分别对对应策略的实验情况进行解析,而其他策略的实验情况则不需要解析,这样就只获取自己感兴趣的信息,避免了信息的冗余。
为什么刚开始没有进行这样的设计,因为系统刚开始是解决从无到有的问题而不是一到多的问题。第一步是实验平台的创建,采用第一种方式比较简单,可以很快的将实验下发。
④ 广告侧 A/B 实验
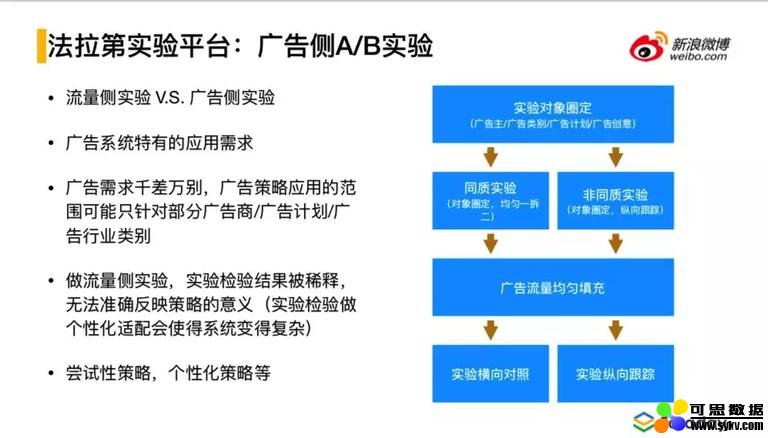
常用的 A/B 实验是关于流量侧的分桶实验,根据流量的不同配比进行不同实验的对比。但是这种流量侧的分桶实验不能满足广告的一些需求。在实际的广告系统中,会出现针对某些广告行业或者广告主,进行尝试性的策略,关注的实验效果也是被关注的广告行业或者广告主的效果。如果用流量侧实验的话也不是不行,但是在进行实验效果分析时候,数据分析需要具体到广告主粒度,会给统计分析引擎带来极大的挑战;如果不这么做,仍然只看整体的效果,实验分析效果必定是被稀释的,无法准确的反映出策略的意义。这样就需要进行广告侧实验的机制设计:
首先会进行实验对象的圈定,包括:广告主 、广告类别、广告计划、广告创意等。
然后进行同质或非同质实验:
同质实验(即对一个推广计划的受众进行随机的划分,一分为二,在一分为二的基础上作用不同的策略进行对比),一个计划,可能会创建两个类似于“伪计划”的概念,然后对伪计划同时进行系统投放。进入两个人群的划分当中,然后进行效果对比。
非同质实验,这个是尝试性的圈定一波人去进行实验,这种往往是没有对照的是根据实验效果进行纵向的对比判定,也就是当前的策略实验效果与之前没有进行的实验的策略运行效果进行对比判断。
⑤ 广告预算独立 A/B 实验
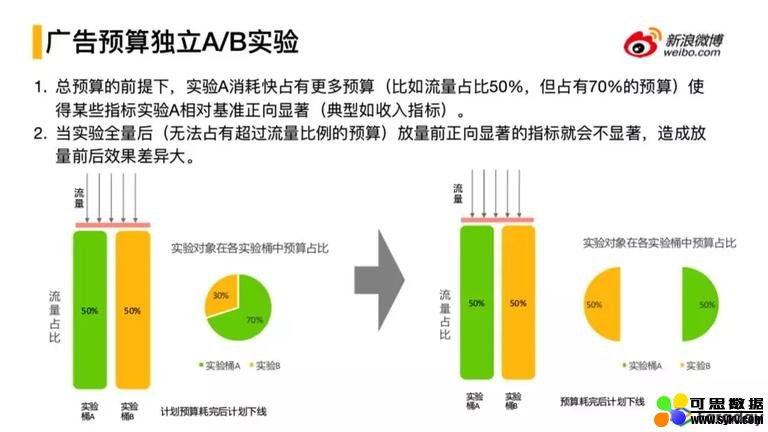
广告实验平台在具体的广告实验中会遇到的问题,这种问题在非广告业务中是没有的。因为在广告领域涉及到 A、U、C 这三方,这三方是个有效的完整回路,一个简单的回路就考虑到计划的投放 -> 花钱 -> 广告下线,这里会涉及预算,预算没有了就会下线。这里会涉及个问题,如果在进行这种简单的流量分桶实验的话,一分为二,上不同的策略,这两个策略的结果对广告主预算的消耗速度是不一样的,带来的结果是,假如某个分桶(五五分),一段时间会发现 A 桶消耗的快,如果没有进行预算的独立,会把 B 桶的预算拉过去,具体表现就是广告主的钱,在 A 桶花费的更多,如果流量小的时候效果可能非常好,但是随着流量的不断的放大会发现策略的实验效果会变的很小。所以广告预算的独立性会在广告主侧实验的时候就考虑到,比如说计划的一分为二,预算平均分配,各自独立,互不影响。最后会考虑将预算独立实验应用在流量侧分桶,目前没有做但是经过论证是可行的。
⑥ 实验检验与效果评估
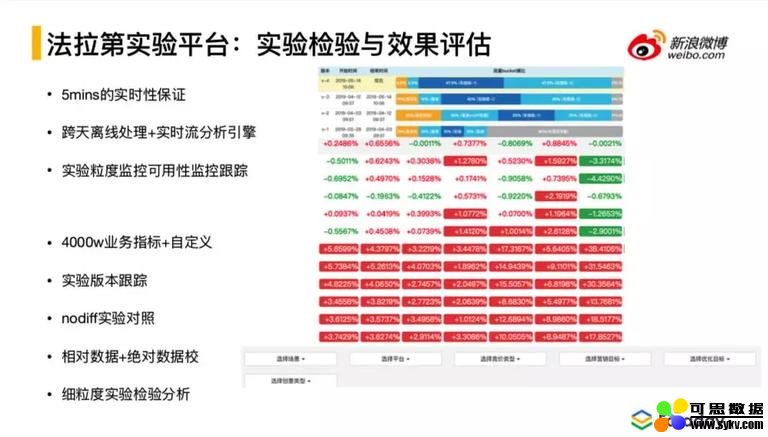
实验检验与效果评估,是实时的效果评估,能够做到 5 分钟(保守的)内的数据延迟,如果 1 分钟也可以,但是问题点在于涉及广告效果衡量时,比如 ctr= 互动 / 曝光,互动可能会有延迟,会造成计算出的结果飘忽不定,所以为了让实验效果趋于稳定会 5 分钟计算一次。
对于跨多天的实验效果分析采取的机制是离线跨天 + 实时流分析引擎。由于实时流机制的效果不如离线的,这里又进行了优化,比如几个小时之前的,如果离线进行这种任务的调度都能跑出来的话,也会用离线的方式进行批量的处理来替换今天早些时候的实时流分析数据,实时流会倾向于用最近比如一个小时或两个小时的数据。在实验决策角度来说,实时流主要是看实验效果会不会带来严重的缺陷,以便进行实验的及时终止,离线的数据处理带来的实时报表主要作为实验效果的评定。
整体的实验效果会有可用性的监控(例如对流量分桶的监控,不同策略对流量层面的可用性是不一样的),保证两个实验分桶的可用性在同一个水平上的。
实验平台支持的业务指标将近 4000 万~1 亿的规模,而且支持自定义指标的方式。同时实验支持版本的跟踪,也支持 nodiff 的对照实验等。
2. 广告精益洞察
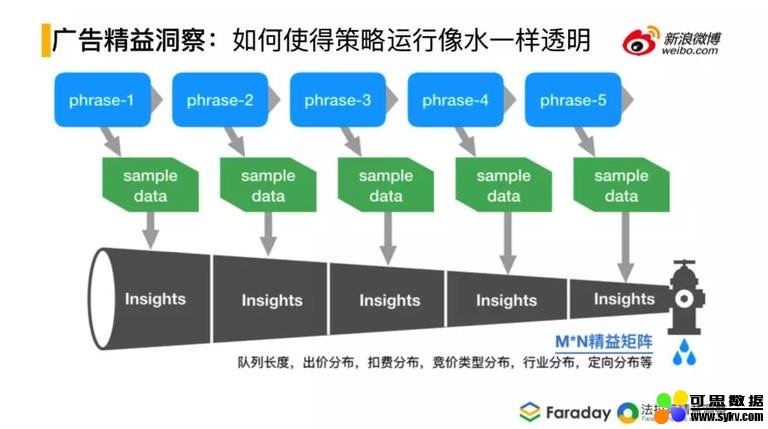
精益洞察想解决的问题是:由于线上的策略很多,怎样让策略运行的时候,在系统之外能很好的看到系统的运行状态,使得策略运行的像水一样透明,后来提出了精益矩阵的描述方法,整体上的业务分为多层次的业务阶段,每个阶段都会有完整的洞察。
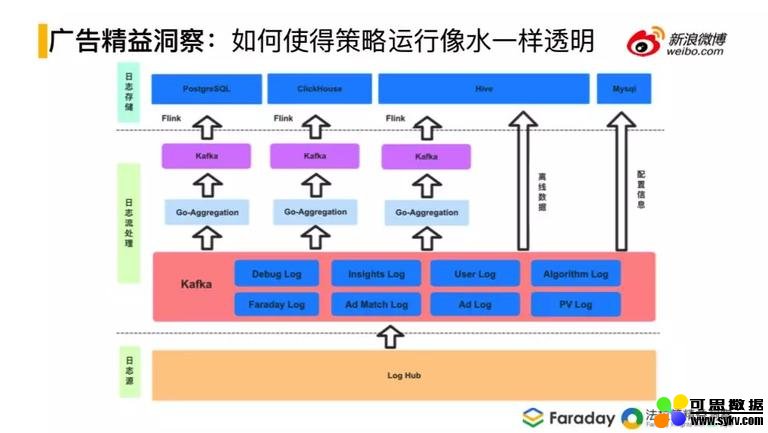
上图是系统的架构图。数据落地,进入到实时流机制,实时流机制中的数据类别是分类的,之间是通过 key 进行关联,将日志构建组件化,包括线上的调试日志,用户的信息日志、线上跑策略跑模型的日志、广告日志等等,再往上会进行日志处理存储,分为离线存储和在线存储,在线存储会用到 PG 和 clickHouse 这种列式存储,以便在线即时访问。
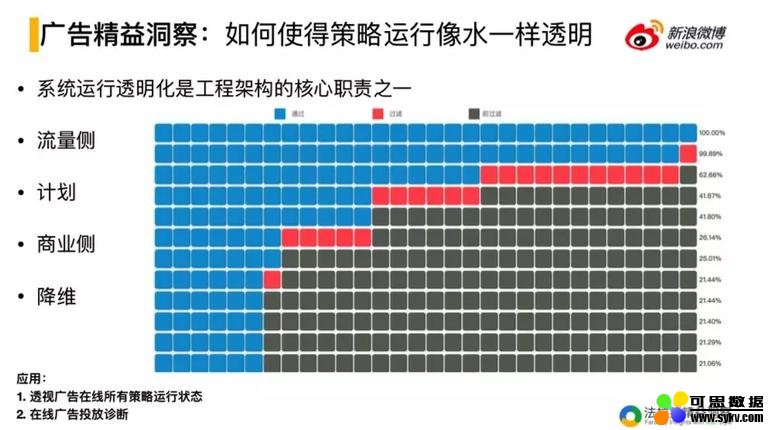
整体的呈现效果是:每一层是一个业务策略阶段;请求访问或者广告召回集的处理,整体看是一个漏斗,从广告数量来看是二维的,一个广告召回集的数量,随着策略的运行,数量在不断的减少。每个层面上都可以更细粒度看,例如不同的竞价类型占比的分布情况以及整体的出价水平都可以细粒度的查看,分辨出在不同策略层之间的表现差异,洞察策略的具体影响效果。
精益洞察提供了不同的视角:
流量侧:看总体的流量的漏斗运行情况;
用户粒度:实现 debug 功能,对单个用户的请求在策略漏斗中的表现情况;
计划粒度:商业侧,比如某广告主计划的推广运行情况都可以洞察到。
本次的分享就到这里,谢谢大家。
PS:微博广告研发中心,招募广告引擎高级工程师 / 技术专家(广告策略方向、分布式架构方向)中,团队技术氛围浓厚,技术至上,技术偏执狂,开放,自由,优秀者有股票,有意者请发送简历至:
tieniu@staff.weibo.com****
广告策略方向:参与广告投放体系的实现,基于大规模用户行为数据,优化在线广告策略与模型,提高在线广告的相关度,优化广告投放效果。
分布式架构方向:负责微博广告引擎设计、重构、优化,支持大数据、高并发和高性能要求; 负责广告数据服务的研发,支持亿级用户的广告动态实时计算和匹配,以及数据分布式存储和访问; 对现有系统的不足进行分析,找到目前系统的瓶颈,改进广告系统的架构,提高系统性能以及效果。

嘉宾介绍
李铁牛,微博广告引擎技术专家,微博广告投放系统负责人。2012 年加入微博广告团队,微博广告创始团队核心成员,微博广告法拉第 A/B 分层实验系统设计者。对广告触发机制,广告智能频控,市场机制设计,精准受众定向技术, 广告策略实验框架等计算广告技术有深入研究,对广告服务模型建模和百亿级高并发广告系统有丰富的设计经验。
编辑整理:崔媛媛
内容来源:DataFun AI Talk
出品社区:DataFun
编辑整理:崔媛媛
内容来源:DataFun AI Talk
出品社区:DataFun

时间:2019-09-16 22:57 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















