一部电影能否大卖?用机器学习来精准预测吧
电影数据库(TMDB)为电影数据提供了一个API,人们可以从该数据库中下载数据。那么,在仅知道电影上映前的部分信息的情况下,是否能预测电影的评分和票房?什么参数最能预测一部好的或最卖座的电影?采用什么阵容或用什么演员是否能帮助预测电影票房?
我们随机地在90%的电影上做了一个模型,并在剩下的10%的电影上测试了该模型。而对于这些测试模型的电影:
准确地预测电影票房具有一定的挑战性。按照外行的说法,在电影发行前,只知道有关电影的一些事实,这个模型( R² = 0.77)可以做出准确的预测——例如,电影公司可以提前决定是否在一段时间内发行一部电影。
预测电影评分更为困难。如果和仅预测每部电影的平均评分(得到 R² 值为 0.53)相比,我们或许可以做得更好一些。
知道Denny Caira吗?电影摄制组被认为是在评分预测中区分电影好坏的关键因素,也是好评和差评电影间最大的区别。摄制组对电影好坏的影响程度比演员要大得多。
我们发现了一些有趣的东西。下面可以查看与高分和高票房电影最相关的演员名单。
数据
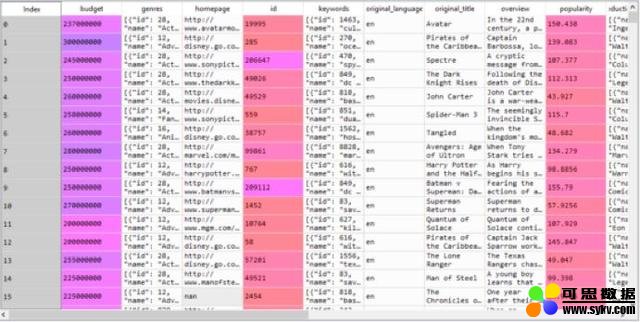
数据标记得很好,但会涉及太多细节。我们作如下总结:
电影数据库是基于电影界建立的,其数据由大众提供,因此,并非所有数据都确实存在或十分准确。例如,该数据库中有900多个收益值缺失。
忽略了一些无用变量,例如片名和主页。显然这些变量并不能用于预测电影是否成功。
一些变量由于某些原因被移除:(1)出品国,因为其中的信息存储在出品公司;(2)原版语言,因为该部分主要为口语,除了少数例外;(3)受欢迎程度,因为很明显这是电影上映后衡量的。
作为输入项的变量为:
预算
题材列表
上映日期——分为年份和日期
语言列表
上映时长
出品制作公司名单
演员阵容
摄制团队阵容
关键词——提示用户的关键词列表。诚然,一些关键词只有在电影上映后才会知道,但并没有透露太多。代表性关键词是“基于小说”给出的。
用于预测模型的变量有:
用户投票(类似于IMDb评级,本文称为“评分”)
用户报告的票房收入(本文称为“票房/收入”)
数据准备
源链接: https://github.com/rian-van-den-ander/explorations/tree/master/film_success/data_prep.py
问题1:票房数据不够好
我们移除了零收入行,共900行。这样做并不好,但不能通过零收入行预测电影票房。
我们调整了票房收入以适应通胀。最初,我们以为这并不会有什么不同,但事实上将R²值提高了0.02。
问题2:如何表示上映日期?
我们决定将变量分为具体年和一年中的具体天。分为具体年是因为票房收入肯定与世界人口和社会模式相关。分为一年中的具体天是因为电影票房可能与圣诞节或暑期等时间上映有关。这么做是有效果的,因为用一年中的具体天预测票房收入是预测模型中前30个重要变量。
一个更大的问题3:许多是JSON列表
一些专栏有内置的列表:每种题材、关键词、出品制作公司、语言、演员阵容、摄制组事实上都是题材、关键词等的列表。我们所知的机器学习并不能处理这些数据。
必须创建一个新的库来将这些列表转换成适应模型的专栏,这个过程称为分类特征编码。
这产生了一个新的问题:有太多的演员,摄制组人员和关键词,电脑难以处理。因此,必须限制每个输入列的值。这对模型来说不太好,因为我们现在只选了500名最普通的演员,500名最强演员,100个关键词和100个电影制片厂。不过,这一问题可以通过把解决方案托管在云端,并在模型训练中投入更多精力,或投入更多耐心而得到解决。
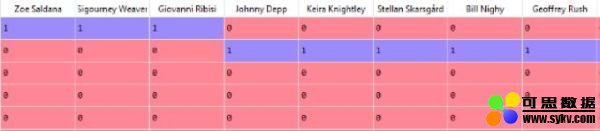
JSON演员列表行就如以下列举的一样:
[{"cast_id": 242, "character": "Jake Sully", "credit_id": "5602a8a7c3a3685532001c9a", "gender": 2, "id": 65731, "name": "Sam Worthington", "order": 0}, {"cast_id": 3, "character": "Neytiri", "credit_id": "52fe48009251416c750ac9cb", "gender": 1, "id": 8691, "name": "Zoe Saldana", "order": 1}, ....
它们将被转化为更适合模型的列表,其中包含1s和0s
检验模型的成功性
我们选择用一个普通的系数r²来表示模型的成功性。这是数据科学家处理回归问题的默认选项,也是一个衡量作者的模型比预测每部电影的平均评分或票房要好多少的一个指标。
如果模型比选择的平均值差,则为负。负值越大,则模型越差。
如果模型只选择每部电影的平均评分或票房,则为零。
如果模型比选择的平均值好,则为正,“1”为最佳模型。
当然,在某一时刻,当解决方案足够好时,可以停止衡量而采用该方案。这个根据解决的问题不同而不同,但一般来说:
0.6-0.9指较好的模型。
以上任何一点如果太过完美,则会不够真实,会存在不公平的变量输入或过度拟合的问题。例如,在第一次模型运行中意外地包括了行计数,由于数据是按收入排序的,所以该模型几乎完美地预测了票房。
0–0.6意味着至少选择了一些平均值数据,但可能不够好,以致模型无法用于作出重要的商业决策。
电影评分预测
源链接:
https://github.com/rian-van-den-ander/explorations/blob/master/film_success/film_rating_with_cast_best_regressor.py
对于模型选择,使用XGBoost回归器通过超参数网格搜索运行数据。我们在网格搜索中尝试了其他几个库,包括随机森林回归器(random forest regressors)和一个性能非常好的神经网络。网格搜索大大提高了 XGBoost回归器的性能,它在速度和精度方面都非常值得推荐。
当然,想要纯粹地靠电影元数据准确预测电影评分有点像做白日梦。因为在元数据中,有很多变量是看不到的,比如脚本质量,或者这是否是演员(如Johnny Depp)表现得最好的一个角色。
也就是说,我们得到的最好的模型结果是r²=0.53。按照机器学习标准,这是可以的。该模型解释了超过平均评分的53%方差部分的差异。换句话说,模型虽然漏掉了许多变量,但仍然清楚地预测大多数电影比平均水平更好还是更差。

有趣的是,图表展示了直观的立竿见影的成效。为了更好地预测,模型必须是倾斜的。
什么是与电影评分最相关的变量?
XGBoost库的输出提供了它用于预测的性能(输入变量)的重要性。考虑到模型本身并没有做出完美的预测,这一点必须稍加考虑。然而,输出提供了一个非常清晰的一点:
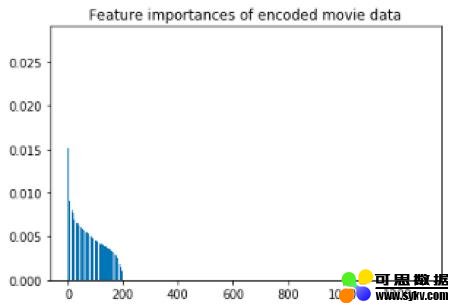
在这里,可以看到只有大约200个输入变量较为重要。而剩下的部分基本上被算法移除了。未来有了更好的计算机,我们只需选择更多的输入变量(摄制团队和演员阵容),并通过提前分析处理,挑选出那些与电影评分没有关联的变量。
在文本形式中,与电影评分最相关的变量如下。
免责声明:这些可能会对评分产生负面影响,因为人们可能从其中几个词(恐怖、青少年)中进行挑选。该算法只输出对其预测器影响最大的那些变量。
('Drama', 0.02771771)('Film runtime', 0.017870583) - !('Horror', 0.015099976)('Animation', 0.010213515)('John Lasseter', 0.0099559575) - of Pixar fame('Family', 0.009091541)('Comedy', 0.009024642)('Harvey Weinstein', 0.009003568)('Whoopi Goldberg', 0.008995796) - ?!('Bill Murray', 0.008862046)('Action', 0.008832617)('Documentary', 0.008824027)('Morgan Creek Productions', 0.008456202)('Franchise Pictures', 0.008374982)('Hans Zimmer', 0.008047262)('DreamWorks Animation', 0.007945064)('Hospital', 0.007892966)('Janet Hirshenson', 0.007849025)('Jason Friedberg', 0.007827318)('en', 0.0077783377) - English movies('Teenager', 0.0077319876)
电影收益预测——一项更为简单的任务
源链接: https://github.com/rian-van-den-ander/explorations/blob/master/film_success/film_revenue_with_cast_best_regressor.py
正如人们所料,考虑到以下因素,这将是一项更简单的任务:
电影的预算很可能是一个很好的指标,表明它是否会成为卖座影片。
许多高收益电影都是超级英雄电影。
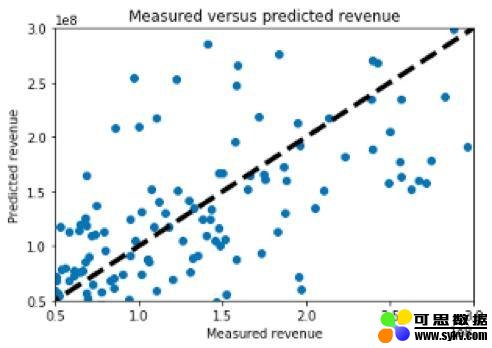
与前面的方法一样,这个预测模型为R²=0.77。换言之,一个人可以在电影上映前基于输入项建立一个非常好的收益预测模型。这会对现实世界产生影响:例如,一家电影院可以用它来提前预测他们想放映一部电影的时间长短。

这个看起来比我们的评分预测要好得多。当然,也有异常值,但它们在预测线的上方和下方的间隔十分均匀。
什么是与电影收益最相关的变量?
这个变量列表不会让人感到惊讶。不过,免责声明也同样适用。变量可能会对收益产生负面影响,模型也并不完美。但这份列表证实了预算和收入之间的紧密联系。毕竟,如果投资没有回报,为什么会有人拍电影呢?
不出所料,超级英雄电影皮克斯动画工作室 (Pixar) 的电影在这方面有着很强的表现力,其关键词、工作室、题材和摄制组都排在列表前列。令人惊讶的是,制作出品人Denny Caira,比预算更重要。显然,他在电影行业中是大名鼎鼎的人物!
('Denny Caira', 0.037734445)('Film Budget', 0.03122561)('Adventure', 0.025690554)('James Cameron', 0.024247296)('Pixar Animation Studios', 0.022682142)('David B. Nowell', 0.022539908)('marvel comic', 0.022318095)('Terry Claborn', 0.01921264)('John Williams', 0.015954955)('3d', 0.014985539)('Animation', 0.013459805)('John Ratzenberger', 0.013009616)('Christopher Boyes', 0.012793044)('Fantasy', 0.012175937)('Gwendolyn Yates Whittle', 0.011877648)('Lucasfilm', 0.011471849)('Christopher Lee', 0.011401703)('superhero', 0.010956859)('Jim Cummings', 0.010577998)('John Lasseter', 0.010427481)('Drama', 0.010378849)
片酬:演员与之最为相关
源链接:
https://github.com/rian-van-den-ander/explorations/blob/master/film_success/film_actors_to_ratings.py
因收益而改变的量。
注意:对于这个问题,我们在算法中涵盖了更多的演员,并且没有考虑其他变量,如摄制团队和预算。这是在纯粹讨论演员与成功的电影之间的关系。这就是这里的变量列表与上文不完全一致的原因。
哪些演员与电影评分最相关?
('Robert Duvall', 0.011352766) - of Godfather fame('Morgan Freeman', 0.010981469)('Scarlett Johansson', 0.010919917)('Paul Giamatti', 0.0108840475)('Helena Bonham Carter', 0.010548236)('Jim Broadbent', 0.010294276)('Harrison Ford', 0.010112257)('Leonardo DiCaprio', 0.010015999)('Mark Ruffalo', 0.009964598)('Matthew Lillard', 0.00989507)('Ian Holm', 0.009870403)('Timothy Spall', 0.009850885)('Philip Seymour Hoffman', 0.009718503)('Rachel McAdams', 0.00953982)('Emily Watson', 0.009512347)('Alan Rickman', 0.009455477)('Keira Knightley', 0.009296855)('Eddie Marsan', 0.009277014)('Stan Lee', 0.0092619965)('Emma Thompson', 0.009148427)('Edward Norton', 0.00904271)
哪些演员与电影收益最相关?
显然,Stan Lee并不能使电影制片人变得富有。他只不过是拍了漫威所有的电影。以下列表显示的是演员与高票房(通常是超级英雄)电影的关联性,而非显示让电影卖座的演员名单。
('Stan Lee', 0.04299625)('Hugo Weaving', 0.030377517) - "You hear that Mr, Anderson? That is the sound of inevitability. That is the sound of profit"('John Ratzenberger', 0.024940673) - In every Pixar film('Frank Welker', 0.018594962)('Alan Rickman', 0.01844035)('Gary Oldman', 0.018401919)('Geoffrey Rush', 0.018003061)('Christopher Lee', 0.017147299)('Robbie Coltrane', 0.015522939)('Ian McKellen', 0.015420574)('Timothy Spall', 0.0151223475)('Zoe Saldana', 0.014832611)('Stellan Skarsgård', 0.014798376)('Maggie Smith', 0.014290353)('Will Smith', 0.01418642)('Tom Cruise', 0.013842676)('Jeremy Renner', 0.013476725)('Alan Tudyk', 0.013410641)('Judi Dench', 0.01316438)('Leonardo DiCaprio', 0.01244637)('Liam Neeson', 0.012093888)
摄制团队
最初,在构建模型时,我们并没有对摄制团队进行分析。这是一个巨大的疏忽。模型中仅包括前200名制片人、编剧和导演,将票房预测R²从0.68提高到0.77。
令人印象更深刻的是,仅添加一种类型变量,评分预测R²从0.19提高到0.53。摄制团队可以对电影评分预测产生30%多的方差。
提升空间
这一的方法并不完美,走捷径放弃了大量有用的数据。如果要寻求最好的解决方案,特别是提高模型的评分预测,可以考虑以下问题:
考虑演员、关键词、题材方面的所有数据。这将需要更高的处理能力,但可能有助于模型挑选出许多异常值,尤其是那些神秘的演员和导演,他们不仅仅是票房机器。
训练模型:将模型超参数调回到评分预测将会略微提高其预测准确度。
运用PCA或LDA消除明显不相关的变量。
选择更好的参数,通过更严格的参数网格运行XGBoost模型。
考虑到这个问题的严肃性,需探索神经网络解决方案。

时间:2019-09-14 22:10 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]堪比当年的LSTM,Transformer引燃机器学习圈:它是
- [机器学习]论机器学习领域的内卷:不读PhD,我配不配找工
- [机器学习]机器学习基础图表:概念、原理、历史、趋势和算法
- [机器学习]分析了 600 多种烘焙配方,机器学习开发出新品
- [机器学习]2021年的机器学习生命周期
- [机器学习]物联网和机器学习促进企业业务发展的5种方式
- [机器学习]机器学习中分类任务的常用评估指标和Python代码实现
- [机器学习]机器学习和深度学习的区别是什么?
- [机器学习]堪比当年的LSTM,Transformer引燃机器学习圈:它是
- [机器学习]年终总结:2021年五大人工智能(AI)和机器学习(ML)发展趋势
相关推荐:
网友评论:















