论机器学习模型的可解释性
在2019年2月,波兰政府增加了一项银行法修正案,该修正案赋予了客户在遇到负面信用决策时可获得解释的权利。这是GDPR在欧盟实施的直接影响之一。这意味着如果决策过程是自动的,银行需要能够解释为什么不批准贷款。
在2018年10月,“亚马逊人工智能招聘工具偏向男性”的报道登上了全球的头条新闻。亚马逊的模型是基于有偏见的数据进行训练的,这些数据偏向于男性应聘者。该模型构建了不利于含有“Women's”一词的简历的规则。
“不理解模型预测”产生的影响
上述两个例子的共同之处在于,银行业中的模型和亚马逊构建的模型都是非常复杂的工具,即所谓的黑盒分类器,它们不提供简单且可解释的决策规则。
如果金融机构想要继续使用基于机器学习的解决方案,就必须投资于模型可解释性的研究。这些机构可能确实会这么做,因为这样的算法在预测信用风险方面会更准确。另一方面,如果模型经过适当的验证和理解,亚马逊本可以节省大量资金并避免负面报道。
为什么是现在?数据建模的趋势
自2014年以来,机器学习一直保持在Gartner的Hype Cycle(技术成熟度曲线)的最顶端,直至2018年被深度学习(机器学习的一种形式)所取代,这表明其普及尚未达到峰值。
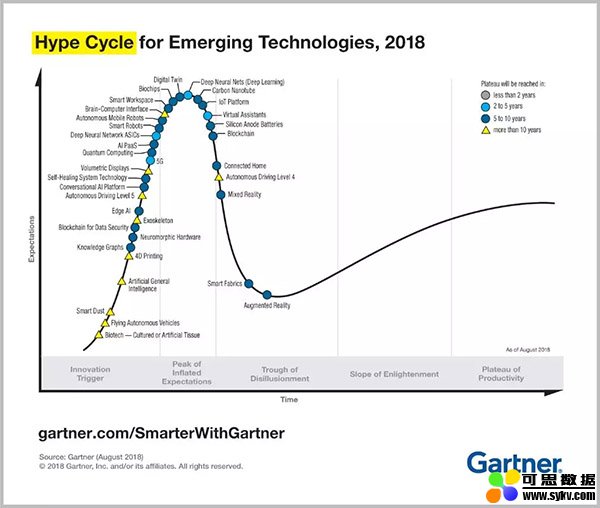
来源:https://www.gartner.com/smarterwithgartner/5-trends-emerge-in-gartner-hype-cycle-for-emerging-technologies-2018/
机器学习增长预计将进一步加速。根据Univa的调查报告,96%的公司预计在未来两年内将机器学习用于生产。
其背后的原因是:广泛的数据收集、大量计算资源的可获得性以及活跃的开源社区。机器学习采用的增长伴随着解释性研究的增加,而研究的增加是由像GDPR这样的法规、欧盟的“解释权”、对(医疗、自动驾驶汽车)安全性以及可重现性和偏见的担忧,或者最终用户的期望(调试优化模型或者学习一些关于研究对象的新知识)所驱动的。
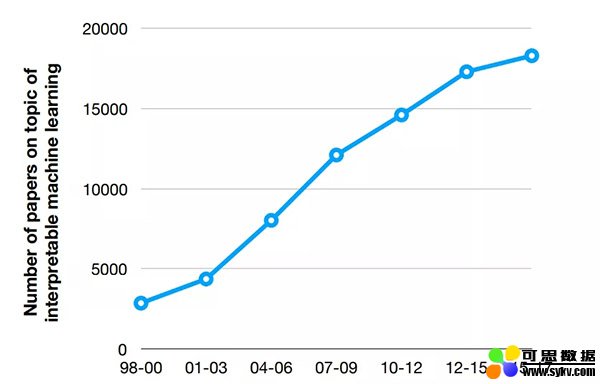
来源:http://people.csail.mit.edu/beenkim/papers/BeenK_FinaleDV_ICML2017_tutorial.pdf
黑盒算法可解释性的可能性
作为数据科学家,我们应该能够向最终用户提供有关模型如何工作的解释。但是,这并不一定意味着理解模型的每个部分或需要根据模型生成一组决策规则。
同时,如下情况也不需要解释模型:
- 问题被完美研究
- 模型结果没有后果
- 最终用户理解模型可能会给系统带来博弈风险
如果我们看看2018年Kaggle所做的机器学习和数据科学调查结果,大约60%的受访者认为他们可以解释大多数机器学习模型(有些模型仍难以解释)。用于机器学习理解的最常用方法,是通过查看特征重要性和特征相关性来分析模型特征。
特征重要性分析提供了对模型学习内容以及哪些因素可能重要的初步的良好洞察。但是,如果特征之间是相关的则该方法会不太可靠。只有模型变量可解释时,它才能提供良好的洞察。对于许多GBMs库(Gradient Boosting Machine),绘制关于特征重要性的图表非常容易。
对于深度学习来说,情况要复杂得多。使用神经网络时,可以查看权重,因为它们包含关于输入的信息,但信息是压缩的。此外,你只能分析第一层的连接,因为在更深的层次上它太复杂了。
难怪2016年LIME(局部可解释的模型-可解释的说明)论文在NIPS会议上发表时,它产生了巨大的影响。LIME的模式是在可解释的输入数据上构建一个易于理解的白盒模型去局部模拟一个黑盒模型。已经证明它在为图像分类和文本提供解释方面获得很棒的结果。但是,对于列表数据,很难找到可解释的特征,其局部解释可能会产生误导。
LIME通过Python(lime和Skater)和R(lime包和iml包、live包)实现,并非常容易使用。
另一个有前景的想法是SHAP(Shapley Additive Explanations)。它基于博弈论。它将特征当做玩家、将模型当做联盟,用Shapley值说明各特征分别带来了怎样的“影响(Payout)”。该方法公平地衡量(各特征的)作用,易于使用并提供吸引人的可视化实现。
以R提供的DALEX软件包(描述性机器学习说明)提供了一组工具,可帮助了解复杂模型的工作原理。使用DALEX,可以创建模型解释器并通过可视化进行检查,例如分解绘图。你可能也会对DrWhy.Ai感兴趣,它和DALEX是由同一组研究人员开发的。
实际用例
1、检测图片上的对象
图像识别已被广泛使用,其中在自动驾驶汽车中用于检测汽车、交通信号灯等,在野生动物保护中用于检测图像中的某种动物,或在保险中用于检测毁于洪涝的农作物。
我们将使用原始LIME论文中的“哈士奇 vs 狼的例子”来说明模型解释的重要性。该分类器的任务是识别图片上是否有狼,但它错误地将西伯利亚哈士奇分类为狼。感谢LIME的研究人员能够识别图片上的哪些区域对模型比较重要,最终发现如果图片包含雪就会被归类为狼。

该算法使用了图片的背景并完全忽略了动物的特征。模型原本应该关注动物的眼睛。由于这一发现,就可以修复模型并扩展训练样本以防止推理为雪=狼。
2、将分类作为决策支持系统
阿姆斯特丹UMC的重症监护室希望预测出院时患者再入院和/或死亡的可能性。目标是帮助医生选择将病人移出ICU的合适时机。如果医生了解模型正在做什么,就更有可能在做最终判断时使用它的建议。
为了展示如何使用LIME解释这种模型,我们可以看另一个旨在早期预测ICU死亡率的研究。其使用了随机森林模型(黑盒模型)预测死亡率情况,使用LIME局部解释每个患者的预测分数。
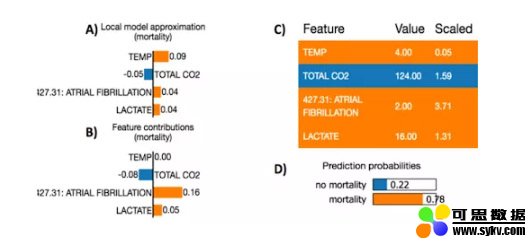
来源:https://www.researchgate.net/publication/309551203_Machine_Learning_Model_Interpretability_for_Precision_Medicine
来自所选样本中的一个患者被预测具有高死亡概率(78%)。导致死亡的模型特征为更高的房颤次数和更高的乳酸水平,这与当前的医学理解是一致的。
人类和机器 - 完美搭配
为了在构建可解释的AI方面取得成功,我们需要将数据科学知识、算法和最终用户的专业知识结合起来。创建模型之后,数据科学的工作还没有结束。这是一个可迭代的、经由专家提供反馈闭环的通常很漫长的过程,以确保结果是可靠的并且可被人类所理解。
我们坚信,通过结合人类的专业知识与机器的性能,我们可以获得最佳结论:改进机器结果并克服人类直觉的偏差。
参考资料:
- On-line and web-based: Analytics, Data Mining, Data Science, Machine Learning education:https://www.kdnuggets.com/education/online.html
- Software for Analytics, Data Science, Data Mining, and Machine Learning:https://www.kdnuggets.com/software/index.html
相关信息:
- Are BERT Features InterBERTible:https://www.kdnuggets.com/2019/02/bert-features-interbertible.html
- Artificial Intelligence and Data Science Advances in 2018 and Trends for 2019:https://www.kdnuggets.com/2019/02/ai-data-science-advances-trends.html
- The year in AI/Machine Learning advances: Xavier Amatriain 2018 Roundup:https://www.kdnuggets.com/2019/01/xamat-ai-machine-learning-roundup.html

时间:2019-09-04 09:35 来源:可思数据 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]Facebook新AI模型SEER实现自监督学习,LeCun大赞最有
- [机器学习]一文详解深度学习最常用的 10 个激活函数
- [机器学习]增量学习(Incremental Learning)小综述
- [机器学习]盘点近期大热对比学习模型:MoCo/SimCLR/BYOL/SimSi
- [机器学习]AAAI21最佳论文Informer:效果远超Transformer的长序列
- [机器学习]深度学习中的3个秘密:集成、知识蒸馏和蒸馏
- [机器学习]堪比当年的LSTM,Transformer引燃机器学习圈:它是
- [机器学习]深度学习三大谜团:集成、知识蒸馏和自蒸馏
- [机器学习]论机器学习领域的内卷:不读PhD,我配不配找工
- [机器学习]Facebook新AI模型SEER实现自监督学习,LeCun大赞最有
相关推荐:
网友评论:















