推荐系统工程难题:如何做好深度学习 CTR 模型线
这篇文章希望讨论的问题是深度学习 CTR 模型的线上 serving 问题。对于 CTR 模型的离线训练,很多同学已经非常熟悉,无论是 TensorFlow,PyTorch,还是传统一点的 Spark MLlib 都提供了比较成熟的离线并行训练环境。但 CTR 模型终究是要在线上环境使用的,如何将离线训练好的模型部署于线上的生产环境,进行线上实时的 inference,其实一直是业界的一个难点。本篇文章希望跟大家讨论一下几种可行的 CTR 模型线上 serving 方法。
自研平台
无论是在五六年前深度学习刚兴起的时代,还是 TensorFlow,PyTorch 已经大行其道的今天,自研机器学习训练与上线的平台仍然是很多大中型公司的重要选项。为什么放着灵活且成熟的 TensorFlow 不用,而要从头到尾进行模型和平台自研呢?重要的原因是由于 TensorFlow 等通用平台为了灵活性和通用性支持大量冗余的功能,导致平台过重,难以修改和定制。而自研平台的好处是可以根据公司业务和需求进行定制化的实现,并兼顾模型 serving 的效率。笔者在之前的工作中就曾经参与过 FTRL 和 DNN 的实现和线上 serving 平台的开发。由于不依赖于任何第三方工具,线上 serving 过程可以根据生产环境进行实现,比如采用 Java Server 作为线上服务器,那么上线 FTRL 的过程就是从参数服务器或内存数据库中得到模型参数,然后用 Java 实现模型 inference 的逻辑。
但自研平台的弊端也是显而易见的,由于实现模型的时间成本较高,自研一到两种模型是可行的,但往往无法做到数十种模型的实现、比较、和调优。而在模型结构层出不穷的今天,自研模型的迭代周期过长。因此自研平台和模型往往只在大公司采用,或者在已经确定模型结构的前提下,手动实现 inference 过程的时候采用。
预训练 embedding+ 轻量级模型
完全采用自研模型存在工作量大和灵活性差的问题,在各类复杂模型演化迅速的今天,自研模型的弊端更加明显,那么有没有能够结合通用平台的灵活性、功能的多样性,和自研模型线上 inference 高效性的方法呢?答案是肯定的。
现在业界的很多公司其实采用了“复杂网络离线训练,生成 embedding 存入内存数据库,线上实现 LR 或浅层 NN 等轻量级模型拟合优化目标”的上线方式。百度曾经成功应用的“双塔”模型是非常典型的例子(如图 1)。
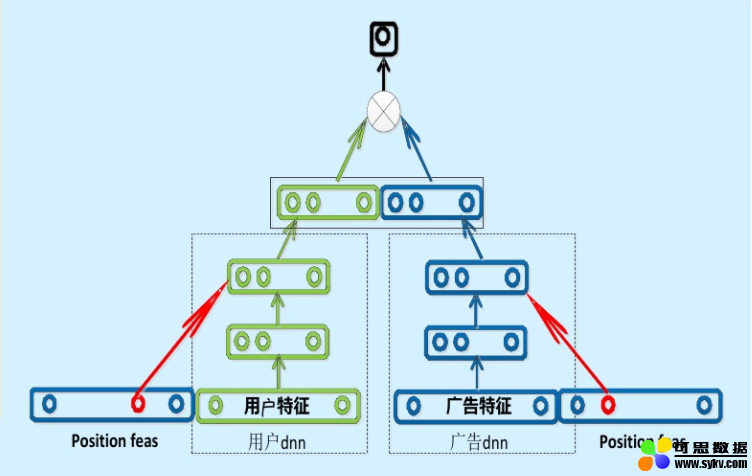
图 1 百度的“双塔”模型
百度的双塔模型分别用复杂网络对“用户特征”和“广告特征”进行了 embedding 化,在最后的交叉层之前,用户特征和广告特征之间没有任何交互,这就形成了两个独立的“塔”,因此称为双塔模型。
在完成双塔模型的训练后,可以把最终的用户 embedding 和广告 embedding 存入内存数据库。而在线上 inference 时,也不用复现复杂网络,只需要实现最后一层的逻辑,在从内存数据库中取出用户 embedding 和广告 embedding 之后,通过简单计算即可得到最终的预估结果。
同样,在 graph embedding 技术已经非常强大的今天,利用 embedding 离线训练的方法已经可以融入大量 user 和 item 信息。那么利用预训练的 embedding 就可以大大降低线上预估模型的复杂度,从而使得手动实现深度学习网络的 inference 逻辑成为可能。
PMML
Embedding+ 线上简单模型的方法是实用却高效的。但无论如何还是把模型进行了割裂。不完全是 End2End 训练 +End2End 部署这种最“完美”的形式。有没有能够在离线训练完模型之后,直接部署模型的方式呢?本小节介绍一种脱离于平台的通用的模型部署方式 PMML。
PMML 的全称是“预测模型标记语言”(Predictive Model Markup Language, PMML)。是一种通用的以 XML 的形式表示不同模型结构参数的标记语言。在模型上线的过程中,PMML 经常作为中间媒介连接离线训练平台和线上预测平台。
这里以 Spark MLlib 模型的训练和上线过程为例解释 PMML 在整个机器学习模型训练及上线流程中扮演的角色(如图 2)。
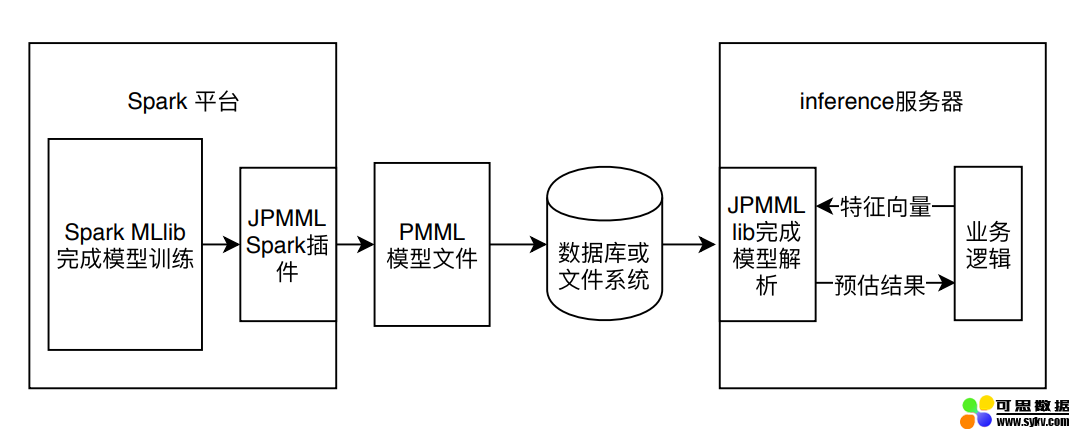
图 2 Spark 模型利用 PMML 的上线过程
图 2 中的例子使用了 JPMML 作为序列化和解析 PMML 文件的 library。JPMML 项目分为 Spark 和 Java Server 两部分。Spark 部分的 library 完成 Spark MLlib 模型的序列化,生成 PMML 文件并保存到线上服务器能够触达的数据库或文件系统中;Java Server 部分则完成 PMML 模型的解析,并生成预估模型,完成和业务逻辑的整合。
由于 JPMML 在 Java Server 部分只进行 inference,不用考虑模型训练、分布式部署等一系列问题,因此 library 比较轻,能够高效的完成预估过程。与 JPMML 相似的开源项目还有 Mleap,同样采用了 PMML 作为模型转换和上线的媒介。
事实上,JPMML 和 MLeap 也具备 sk-learn,TensorFlow 简单模型的转换和上线能力。但针对 TensorFlow 的复杂模型,PMML 语言的表达能力是不够的,因此上线 TensorFlow 模型就需要 TensorFlow 的原生支持——TensorFlow Serving。
TensorFlow Serving
TensorFlow Serving 是 TensorFlow 推出的原生的模型 serving 服务器。本质上讲 TensorFlow Serving 的工作流程和 PMML 类的工具的流程是一致的。不同之处在于 TensorFlow 定义了自己的模型序列化标准。利用 TensorFlow 自带的模型序列化函数可将训练好的模型参数和结构保存至某文件路径。
TensorFlow Serving 最普遍也是最便捷的 serving 方式是使用 Docker 建立模型 Serving API。在准备好 Docker 环境后,仅需要 pull image 即可完成 TensorFlow Serving 环境的安装和准备:
复制代码
docker pull tensorflow/serving
在启动该 docker container 后,也仅需一行命令就可启动模型的 serving api:
复制代码
tensorflow_model_server --port=8500 --rest_api_port=8501 \ --model_name=${MODEL_NAME} --model_base_path=${MODEL_BASE_PATH}/${MODEL_NAME}
这里仅需注意之前保存模型的路径即可。
当然,要搭建一套完整的 FensorFlow Serving 服务并不是一件容易的事情,因为其中涉及到模型更新,整个 Docker 容器集群的维护和按需扩展等一系列工程问题;此外,TensorFlow Serving 的性能问题也仍被业界诟病。但 Tensorflow Serving 的易用性和对复杂模型的支持仍使其是上线 TensorFlow 模型的第一选择。
总结
深度学习 CTR 模型的线上 serving 问题是非常复杂的工程问题,因为其与公司的线上服务器环境、硬件环境、离线训练环境、数据库 / 存储系统都有非常紧密的联系。正因为这样,各家采取的方式也都各不相同。可以说在这个问题上,即使本文已经列出了 4 种主要的上线方法,但也无法囊括所有业界的 CTR 模型上线方式。甚至于在一个公司内部,针对不同的业务场景,模型的上线方式也都不尽相同。
因此,作为一名算法工程师,除了应对主流的模型部署方式有所了解之外,还应该针对公司客观的工程环境进行综合权衡后,给出最适合的解决方案。

时间:2019-08-15 18:22 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















