新手必看的Top10个机器学习算法 学会了你就是老手
总共有多少机器学习的模型?不知道,没人统计过,如果加上各种变体的话,那就更加多了去了。想到这个,你头大不大?那是不是所有都要去学,都要去了解呢?当然不是,不过,下面的这10个算法,如果你是新手的话,一定要去好好学学,搞懂了这些,其他的就是举一反三的事情了。
在机器学习中,有一个叫做“没有免费午餐”的定理。简而言之,它指出,没有一种算法对每一个问题都是最有效的,它尤其适用于监督学习(即预测建模)。
例如,你不能说神经网络总是比决策树好,反之亦然。有很多因素在起作用,比如数据集的大小和结构。
因此,你应该针对你的问题尝试许多不同的算法,同时使用一组保留的“测试集”数据来评估性能并选择获胜者。
当然,你尝试的算法必须适合你的问题,这就是选择正确的机器学习任务的原因。打个比方,如果你需要打扫房子,你可以用吸尘器、扫帚或拖把,但你不会拿出铁锹开始挖。
大的原则
然而,所有用于预测建模的监督机器学习算法都有一个共同的原则。
机器学习算法被描述为学习一个目标函数(f),该目标函数将输入变量(X)映射到输出变量(Y): Y = f(X)
这是一个一般的学习任务,我们想在给定输入变量(X)的新样本下对未来的(Y)进行预测,我们不知道函数(f)是什么样子或它的形式,因为如果我们知道的话,我们就直接使用它就完了,我们就不需要使用机器学习算法从数据中学习它了。
最常见的机器学习类型是学习映射Y = f(X),对新的X做出Y的预测,这被称为预测建模或预测分析,我们的目标是尽可能做出最准确的预测。
对于那些渴望了解机器学习基础知识的机器学习新手来说,以下是数据科学家使用的十大机器学习算法的快速介绍。
1 — 线性回归
线性回归可能是统计学和机器学习中最著名和最容易理解的算法之一。
预测建模主要关注的是最小化模型的误差,或者尽可能做出最准确的预测,可以牺牲掉一些可解释性。我们将从许多不同的领域借用、重用和窃取算法,包括统计学,并将它们用于这些目的。
线性回归的表示是一个方程,它描述了一条最适合输入变量(x)和输出变量(y)之间的关系的直线,通过找出称为系数(B)的输入变量的特定权重。
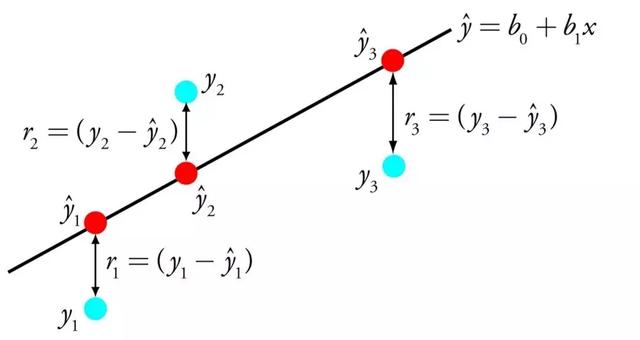
线性回归
例如: y = B0 + B1 * x
我们要在给定输入x的情况下预测y,线性回归学习算法的目标是找到系数B0和B1的值。
从数据中学习线性回归模型可以采用不同的技术,如普通最小二乘的线性代数解和梯度下降优化。
线性回归已有200多年的历史,并得到了广泛的研究。使用这种技术时,一些好的经验法则是删除非常相似(相关)的变量,如果可能的话,从数据中删除噪声。这是一种快速、简单的技术,也是一种很好的首先尝试的算法。
2 — 逻辑回归
逻辑回归是机器学习从统计学领域借用的另一种技术。它是二元分类问题(具有两个类值的问题)的首选方法。
逻辑回归与线性回归相似,其目标是找到每个输入变量权重系数的值。与线性回归不同,输出的预测是使用一个称为logistic函数的非线性函数进行转换的。
logistic函数看起来像一个大S,它将把任何值转换成0到1的范围。这很有用,因为我们可以对logistic函数的输出应用一个规则,将值限制到到0和1(例如,如果小于0.5,则输出1)并预测一个类值。
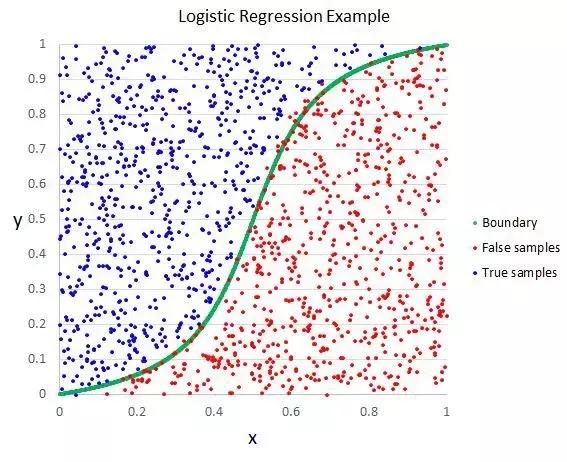
逻辑回归
由于模型的学习方式,通过逻辑回归所做的预测也可以用作给定数据实例属于类0或类1的概率。这对于需要为预测提供更多解释的问题非常有用。
与线性回归一样,当你删除与输出变量无关的属性以及彼此非常相似(相关)的属性时,逻辑回归的效果更好。它是一种快速学习和有效解决二元分类问题的模型。
3 — 线性判别分析
逻辑回归是一种传统上仅限于两类分类问题的分类算法。如果你有两个以上的类,那么线性判别分析算法是首选的线性分类技术。
LDA的表示非常直接,它由数据的统计属性组成,每个类都会计算。对于单个输入变量,包括:
- 每个类的平均值。
- 所有类计算的方差。
线性判别分析
预测是通过计算每个类的判别值并对最大的类进行预测来实现的。该技术假定数据具有高斯分布(钟形曲线),因此在处理之前从数据中删除离群值是一个好主意。它是一种简单而强大的分类预测建模方法。
4 — 分类和回归树
决策树是预测建模的一种重要算法。
决策树模型的表示是一个二叉树。这就是算法和数据结构的二叉树,没什么特别的。每个节点表示单个输入变量(x)和该变量上的分叉点(假设该变量是数值型的)。
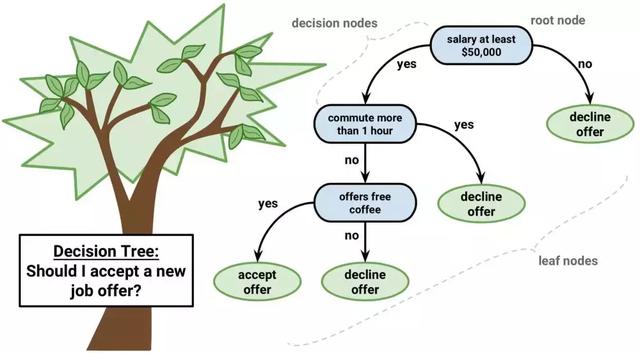
决策树
树的叶节点包含一个用于进行预测的输出变量(y)。预测是通过遍历树的分割直到到达叶节点并在该叶节点输出类值来完成的。
树学起来很快,预测起来也很快。它们通常也适用于各种各样的问题,不需要为数据做任何特别的准备。
5 —朴素贝叶斯
朴素贝叶斯算法是一种简单但功能惊人的预测建模算法。
该模型由两种概率组成,可以直接从训练数据中计算出来:1)每个类的概率;2)给定每个x值的每个类的条件概率。概率模型一旦计算出来,就可以利用贝叶斯定理对新数据进行预测。当你的数据是实数时,通常会假设是高斯分布(钟形曲线),这样你就可以很容易地估计这些概率。
贝叶斯定理
朴素贝叶斯之所以被称为朴素贝叶斯,是因为它假定每个输入变量都是独立的。这是一个强烈的假设,对于真实的数据来说是不现实的,然而,这项技术对于许多复杂的问题是非常有效的。
6 — K-近邻
KNN算法非常简单有效。KNN的模型表示是整个训练数据集。简单吧?
通过搜索整个训练集中最相似的K个样本(邻居),并汇总K个样本的输出,对新的数据点进行预测。对于回归问题,这可能是平均输出值,对于分类问题,这可能是多数的(或最常见的)类值。
诀窍在于如何确定数据实例之间的相似性。如果你的属性都是相同的比例(例如,都是英寸),最简单的方法是使用欧几里德距离(Euclidean distance),这个数字可以根据每个输入变量之间的差异直接计算。
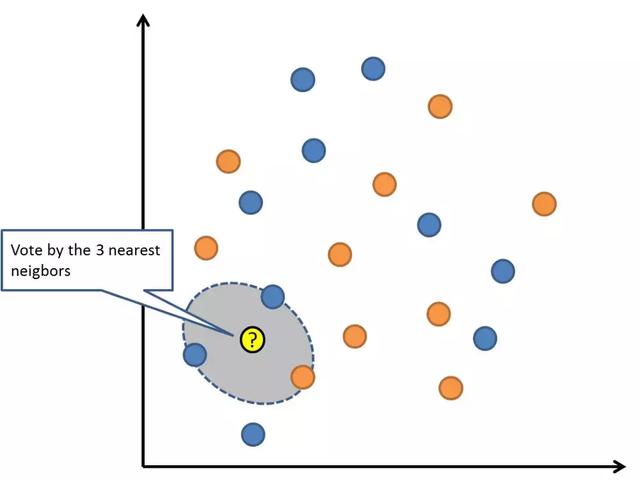
K-近邻
KNN可能需要大量内存或空间来存储所有数据,但只有在需要预测时才执行计算(或学习)。你还可以随着时间的推移更新和管理你的训练样本,以保持预测的准确性。
KNN中的距离或靠近的概念可以分解为非常高的维度(许多输入变量),这会对算法在问题上的性能产生负面影响。这被称为维度诅咒。建议你只使用与预测输出变量最相关的输入变量。
7 — 学习向量量化
k近邻的缺点是你需要保留整个训练数据集。学习向量量化算法(简称LVQ)是一种人工神经网络算法,它允许你选择要挂起多少个训练样本,并准确地了解这些样本应该是什么样子。
学习向量量化
LVQ的表示是一组码本向量。这些在开始时是随机选择的,并且在学习算法的多次迭代中不断的自适应的对数据集进行最好的总结。经过学习,码本向量可以像k近邻一样进行预测。通过计算每个码本向量与新数据之间的距离,找到最相似的邻居(最匹配的码本向量)。然后返回最佳匹配单元的类值或(在回归情况下的实数值)作为预测。如果你将数据缩放到相同的范围,例如在0到1之间,则可以获得最佳结果。
如果你发现KNN在数据集中提供了良好的结果,可以尝试使用LVQ来减少存储整个训练数据集的内存需求。
8 — 支持向量机
支持向量机可能是最流行的机器学习算法之一。
超平面是一条分割输入变量空间的直线。在支持向量机中,选择超平面是为了根据类(class 0或class 1)最好地分离输入变量空间中的点。在二维中,你可以把它想象成一条直线假设所有的输入点都可以被这条直线完全隔开。支持向量机学习算法通过超平面找到最优的分割系数。
支持向量机
超平面与最近数据点之间的距离称为margin。能够分隔两个类的最佳或最优超平面是具有最大边距的直线。只有这些点与超平面的定义和分类器的构造有关。这些点称为支持向量。它们支持或定义超平面。在实际应用中,采用了一种优化算法,求出了使margin最大化的系数的值。
SVM可能是最强大的开箱即用分类器之一,值得一试。
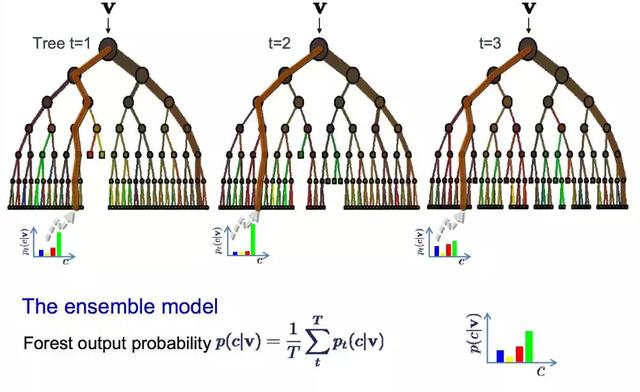
9 — bagging和随机森林
随机森林是目前最流行、最强大的机器学习算法之一。它是一种集成机器学习算法,称为bootstrap Aggregation或bagging。
bootstrap是一种用于从数据样本中估计量的强大统计方法,例如平均数。对你的数据进行多次的采样,计算均值,然后求均值的平均值,以便更好地估计真实均值。
在bagging中,使用相同的方法,但用于估计整个统计模型,最常用的是决策树。获取训练数据的多个采样,然后为每个采样的数据集构建模型。当你需要对新数据进行预测时,每个模型都会进行预测,并对预测进行平均,以更好地估计真实的输出值。
随机森林
Random forest是对这种创建决策树的方法的一种改进,它不是选择最优的分割点,而是通过引入随机性来进行次优分割。
因此,为每个数据集的采样创建的模型比其他情况下更不同,但时仍然很准确。结合他们的预测,可以更好地估计实际的输出值。
如果你使用具有高方差的算法(如决策树)得到了好的结果,那么通常可以通过bagging该算法得到更好的结果。
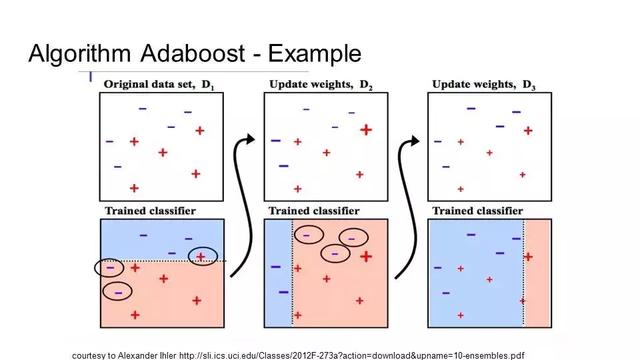
10 —提升算法和AdaBoost
增强是一种集成技术,它试图从一些弱分类器创建一个强分类器。通过从训练数据构建一个模型,然后创建第二个模型,试图纠正第一个模型中的错误,这样来实现。模型不断的被添加,直到训练集被完美地预测或者模型的数量达到了最大。
AdaBoost是第一个真正成功的应用是二元分类的增强算法。这是理解提升算法的最佳起点。现代的提升算法都是在AdaBoost的基础上发展起来的,最著名的是随机梯度提升算法。
Adaboost
AdaBoost用于短决策树。在创建第一个树之后,用这棵树来计算每个样本的performance(和label之间的差别),用来衡量下一棵树将更多的注意哪些样本。难预测的训练数据被赋予更多的权重,而容易预测的数据被赋予较少的权重。模型依次创建,每个模型更新训练样本的权重,这些样本影响序列中下一棵树执行的学习。所有的树都建好之后,对新数据进行预测,每棵树根据在训练数据集上的performance来设定权重。
由于算法对错误的纠正给予了如此多的关注,因此重要的是要有去除离群值的干净数据。
划重点,记得带走
当面对各种各样的机器学习算法时,初学者通常会问这样一个问题:”我应该使用哪种算法?“这个问题的答案取决于许多因素,包括:(1)数据的规模、质量和性质;(2)可用计算时间;(三)任务的紧迫性;以及(4)如何处理数据。
在尝试不同的算法之前,即使是经验丰富的数据科学家也无法判断哪种算法会表现最好。虽然还有许多其他的机器学习算法,但这些是最流行的。如果你是机器学习的新手,那么这将是一个很好的学习起点。
英文原文:https://towardsdatascience.com/a-tour-of-the-top-10-algorithms-for-machine-learning-newbies-dde4edffae11

时间:2019-07-31 23:29 来源:可思数据 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]GPU必知必会 | 哪款显卡配得上我的炼丹炉
- [机器学习]GPU必知必会 | 哪款显卡配得上我的炼丹炉
- [机器学习]线性Attention的探索:Attention必须有个Softmax吗?
- [机器学习]线性Attention的探索:Attention必须有个Softmax吗?
- [机器学习]GPT-3诞生,Finetune也不再必要了!NLP领域又一核弹
- [机器学习]10本关于机器学习(AI)的必读书籍
- [机器学习]人工智能背后的人工力量:机器学习必需数据标注
- [机器学习]21个必知的机器学习开源工具,涵盖5大领域
- [机器学习]Google 科学家最新整理,给新手推荐的十篇最佳数
- [机器学习]10款必备神器:机器学习开源工具助你从新手到高
相关推荐:
网友评论:















