如何又快又好地搜索代码?Facebook 提出基于机器
日前,Facebook 提出了新型代码搜索工具——神经代码搜索(NCS),能够基于机器学习直接使用自然语言处理(NLP)和信息检索(IR)技术处理源代码文本,可大大提高代码检索效率。Facebook 在官网博客上对这项新成果进行了介绍,编译如下。
当工程师能够很容易地找到代码示例来指导他们完成特定的编码任务时,他们的工作状态最佳。对于一些问题——例如,「如何通过编程关闭或隐藏 Android 软键盘?」——相关信息随时可以从像 Stack Overflow 这样的常用资源中获得。但是,专有代码或 APIs(或用不太常见的编程语言编写的代码)的特定问题需要不同的解决方案,而论坛往往也不会探讨这些问题。
为了满足这一需求,我们开发了一个代码搜索工具,它能够直接使用自然语言处理(NLP)和信息检索(IR)技术处理源代码文本。这个工具叫做神经代码搜索(NCS),它接收自然语言作为查询,并返回直接从代码库中检索到的相关代码片段。而它的前提是有可使用的大型代码库,从而有可能搜索到与开发者的查询相关的代码片段。在本文中,我们将介绍两种模型来完成这一任务:
NCS 是一种结合 NLP 和 IR 技术的无监督模型。查看链接:https://dl.acm.org/citation.cfm?id=3211353&fbclid=IwAR2kUqUhkBP6tRlMJwvCWA-6vWWKccnckXeybOYEZpT1OpUZlIJ6q1l7SCA
UNIF 是 NCS 的一个扩展,它使用有监督的神经网络模型来提升使用良好监督数据训练时的性能。查看链接:https://arxiv.org/pdf/1905.03813.pdf?fbclid=IwAR3B0S-IMkHnhzBvCrnTaRu827HzjPJVMIxKDFghNJ8XKXDsGHcElX96HX0
利用开源 Facebook AI 工具(包括 fastText、FAISS 和 PyTorch),NCS 和 UNIF 均将自然语言查询和代码片段表示为向量,然后训练一个网络,使语义相似的代码片段和查询内容的向量表征在向量空间中紧密结合。通过这些模型,我们可以直接从代码库中找到代码片段,从而有效地回答工程师的问题。为了评估 NCS 和 UNIF,我们使用了在 Stack Overflow 上新创建的公共查询数据集。我们的模型可以准确的回答这个数据集中的问题,例如:
如何关闭/隐藏 Android 软键盘?
如何在 Android 中把位图转换成可绘制的?
如何删除整个文件夹和内容?
如何处理活动中的后退按钮?
NCS 的表现显示,相对简单的方法在源代码领域可以表现良好。UNIF 的表现显示,当有标记的数据可用时,一个简单的有监督学习方法可以带来显著的额外收益。本项目与其他 Facebook 构建的系统(如 Aroma 和 Getafix)一起,能为我们的工程师提供了一个广泛的、不断增长的 基于机器学习 工具包,帮助他们更有效地编写和管理代码。
NCS 如何使用嵌入
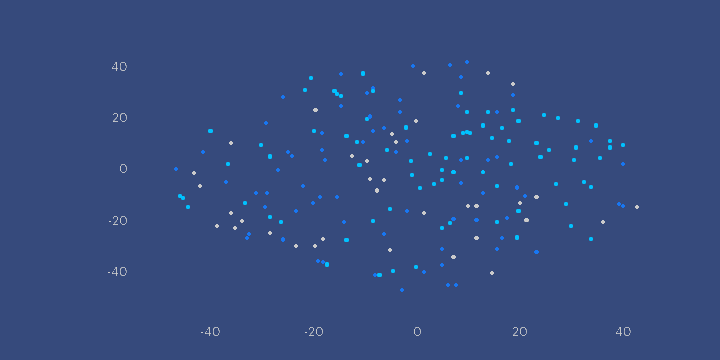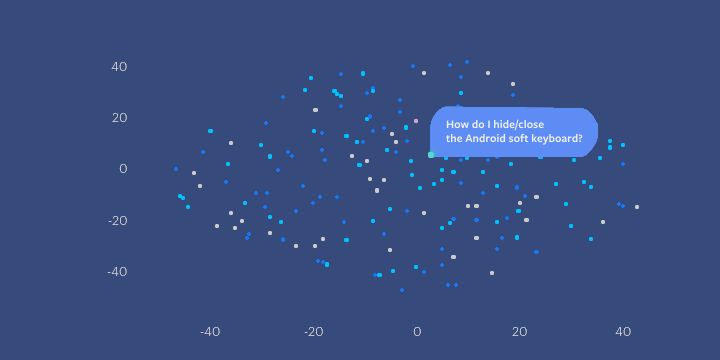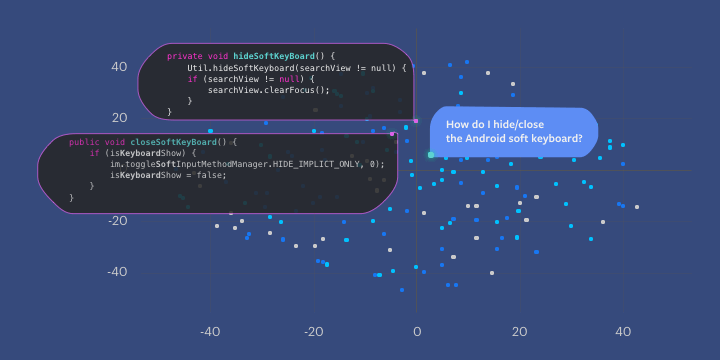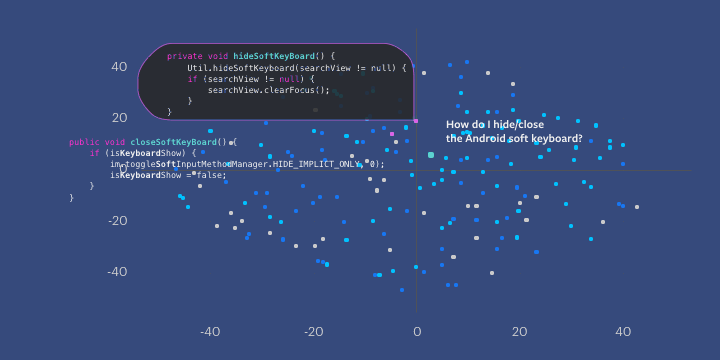
NCS 模型通过使用嵌入来捕获程序语义(在本例中是代码段的意思),即当适当计算连续向量表征时,能够获得将语义相似的实体彼此靠近放置在向量空间中的期望属性。在下面的示例中,有两个不同的方法体,它们都与关闭或隐藏 Android 软键盘(上面的第一个问题)有关。因为它们具有相似的语义意思,即使它们没有完全相同的代码行,它们也由向量空间中彼此接近的点表示。
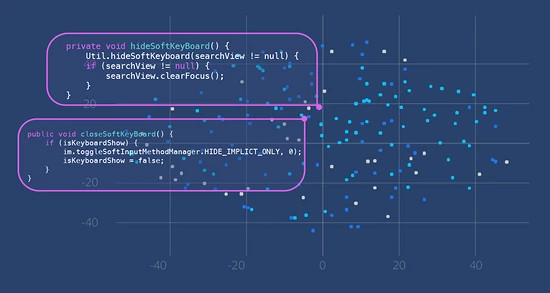
此图显示了相似的代码段在向量空间中是如何聚集的。
(此图显示的公共代码来源于 Github(https://github.com/kabouzeid/Phonograph/blob/master/app/src/main/java/com/kabouzeid/gramophone/ui/activities/SearchActivity.java#L162-L167,https://github.com/RooyeKhat-Media/iGap-Android/blob/master/app/src/main/java/net/iGap/module/SoftKeyboard.java#L78-L83),在 GNU 通用公共许可证下可共享使用。
我们使用这个概念来构建 NCS 模型。在高层次上,模型生成过程中的每个代码片段都以方法级粒度嵌入到向量空间中。一旦模型建立完成,给定的查询将映射到相同的向量空间,并使用向量距离来评估代码片段与查询的相关性。本节将更详细地描述模型生成和搜索检索管道,如下图所示。
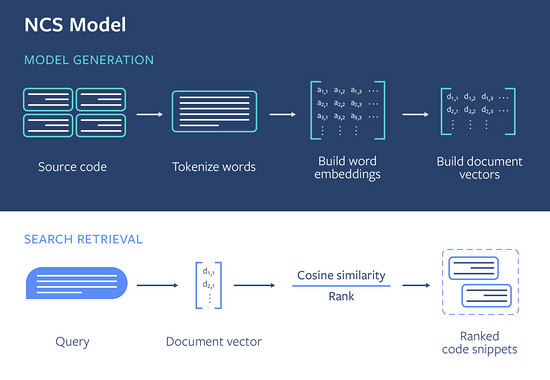
此图显示了 NCS 的整体模型生成和搜索检索过程。
模型生成
要生成模型,NCS 必须提取单词,构建单词嵌入,然后构建文档嵌入。(这里的「文档」参考了一种方法体。)
提取单词

NCS 从源代码中提取单词并标记它们以生成单词的线性序列。
(这里显示的示例数据来自 GitHub 上公开可用的代码,这些代码在 Apache 2.0 许可下共享使用,地址为 https://github.com/sockeqwe/SecureBitcoinWallet/blob/master/app/src/main/java/de/tum/in/securebitcoinwallet/util/DimensUtils.java#L33-L36)
为了生成表示方法体的向量,我们将源代码视为文本,并从以下语法类别中提取:方法名、方法调用、枚举、字符串文本和注释。然后,我们根据标准的英语惯例(如空格、标点符号)和与代码相关的标点符号(如蛇形命名法和驼峰命名法)对其进行标记。例如,对于上图中的方法体「pxToDp」,源代码可以被视为单词的集合:「converts pixelin dp px to dp get resources get display metrics」。
对于语料库中的每个方法体,我们可以用这种方式标记源代码,并学习每个单词的嵌入。在此步骤之后,我们为每个方法体提取的单词列表类似于自然语言文档。
构建单词嵌入

在这个矩阵中,如果相应的单词经常出现在相似的上下文中,那么两个向量表征就会很接近。我们使用与此相反的语句来帮助定义语义关系:向量越近的单词应该具有相关的含义。这在 NLP 文献(相关文献链接:https://www.tandfonline.com/doi/abs/10.1080/00437956.1954.11659520?fbclid=IwAR1xVI93AjRCAUKVRIr0g4PqzHi1ehZwwqDVdjumfshNVEEy14RK2e_5cAY)中被称为分布假设,我们认为同样的概念也适用于源文本。
构建文档嵌入
下一步是使用方法体中出现的单词来表达方法体的总体意图。为此,我们对方法体中单词集的单词嵌入向量取加权平均值。我们称之为文档嵌入。
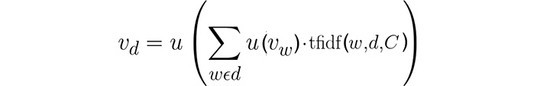
上式中,d 是代表方法体的单词组,![]() 是单词 w 的 fastText 单词嵌入,C 是包含所有文档的语料库,u 是一个归一化函数。
是单词 w 的 fastText 单词嵌入,C 是包含所有文档的语料库,u 是一个归一化函数。
我们使用词频-逆本文频率函数(TF-IDF),它为给定文档中的给定单词分配权重。它的目标是突出文档中最具代表性的单词——如果一个单词经常出现在文档中,它的权重就会更高,但是如果它出现在语料库中过多的文档里,它也会受到惩罚。
在这一步的末尾,我们有了语料库中每个方法体到其文档向量表征的索引,并且模型生成已经完成。
搜索检索
搜索查询用自然语言语句进行表示,如「关闭/隐藏软键盘」或「如何创建没有标题的对话框」。我们采用与源代码相同的方式对查询进行标记,并使用相同的 fastText 嵌入矩阵 T,我们对单词的向量表征进行简单平均来为查询语句创建文档嵌入;不含查询单词的词会被删除。然后,我们使用标准的相似度搜索算法 FAISS 来找到距离查询余弦距离最近的文档向量,并返回 topn 结果(加上一些后处理的排序,该文有进一步解释,论文链接:https://dl.acm.org/citation.cfm?id=3211353)。
这两个方法体和查询被映射到同一向量空间中相邻的点。这意味着查询和这两个方法体在语义上是相似的,并且与查询相关。
结果
我们使用 Stack Overflow 问题评估了 NCS 的性能,用标题进行查询,回答中的代码片段作为所需的代码答案。给定一个查询,测量我们的模型是否能够从 GitHub 存储库的集合中检索并在前 1、5 和 10 个结果中得出正确答案(分别在下面的表中标记为 Answered@1、5、10)。我们还给出了平均倒数秩(MRR),以衡量 NCS 能够在第几个结果中正确地回答问题。我们将在下文更详细地解释实验设置。在我们创建的 Stack Overflow 评估数据集里的 287 个问题中,NCS 在前 10 个结果中正确地回答了 175 个问题;这相当于整个数据集的 60% 以上。我们还将 NCS 的表现与传统的 IR 技术 BM25 进行了比较。如表所示,NCS 优于 BM25。

NCS 表现良好的一个问题例子是「从 APP 中启动 Android 市场」,其中 NCS 返回的第一个结果如下:
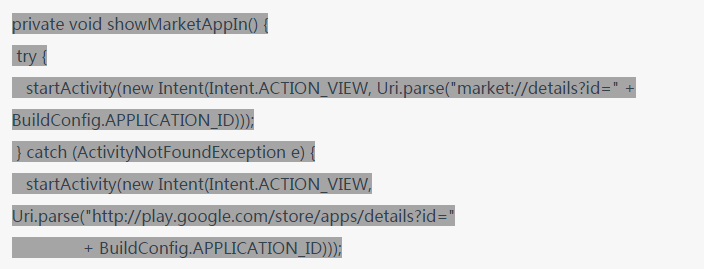
(该代码片段来自 Github 上公开可用的代码,在 MIT 许可下共享使用,链接:https://github.com/mobulum/android-receipts/blob/master/app/src/main/java/tech/receipts/ui/activity/MainActivity.java?fbclid=IwAR3so6yP5Tr0NkwBakiS_kioKckldh_Z97IpxmDy8H8O2scBfKKAK31MHhs#L388-L395)
UNIF:探索监督方法
NCS 的关键在于它使用了单词嵌入。因为 NCS 是一个无监督的模型,它有几个显著的优点:它可以通过搜索语料库直接学习,并且可以快速、方便地进行训练。NCS 假定查询中的单词与从源代码中提取的单词来自同一域,因为查询和代码片段都映射到同一向量空间。然而,情况并非总是如此。例如,查询「Get free space on internal memory」中没有任何单词出现在下面的代码段中。我们想要的是将查询词「free space」映射到代码中的「available」一词。
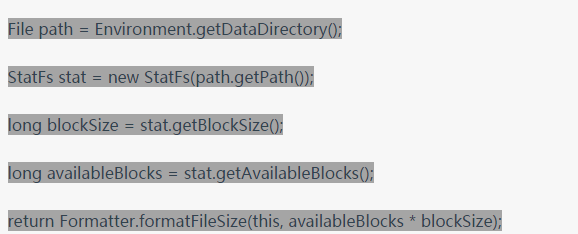
(该代码片段取自 Stack Overflow 上的公开可用代码,在 CC-By-SA 3.0 许可下共享使用,链接:https://stackoverflow.com/questions/4595334/get-free-space-on-internal-memory?fbclid=IwAR1wMoa6js7pSDmzuXZERspW4FUqdwY6tEtmbvOlN8hVFbu8OAAWCa2yDdE)
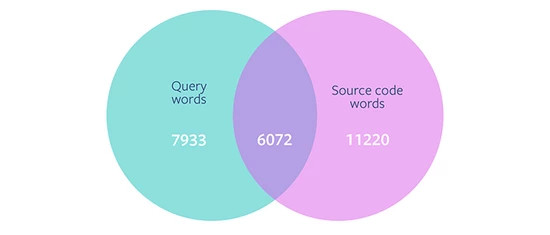
从 14,005 个 Stack Overflow 帖子的数据集中,我们分析了查询中的单词与源代码中的单词的重叠情形。我们发现,在查询中的 13,972 个单独单词中,只有不到一半(6,072 个单词)同时存在于源代码域中。这表明,如果查询包含源代码中不存在的单词,那么我们的模型将不能进行有效地正确检索,因为我们删除了与查询词无关的单词。这种观察促使我们探索监督学习,将查询中的单词映射到源代码中的单词。
我们决定使用 UNIF(NCS 技术的监督最小扩展)进行实验,以弥补自然语言单词和源代码单词之间的差距。在该模型中,我们使用监督学习方法对嵌入矩阵 T 进行修改,生成两个分别用于代码和查询标记的嵌入矩阵 ![]() 和
和 ![]() 。我们还用一种学习的注意力机制权重方案替换了代码标记嵌入的 TF-IDF 权重方案。
。我们还用一种学习的注意力机制权重方案替换了代码标记嵌入的 TF-IDF 权重方案。
UNIF 模型如何工作
我们对 UNIF 进行与 NCS 相同的(c,q)数据点集合的训练,其中 c 和 q 分别表示代码和查询符号(有关此数据集的详细信息,请参见下面的部分)。模型体系结构可描述如下:令 ![]()
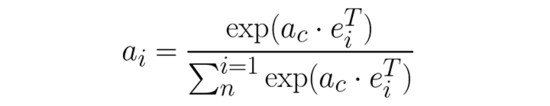
然后将文档向量计算为注意力权重加权后的单词嵌入向量之和:
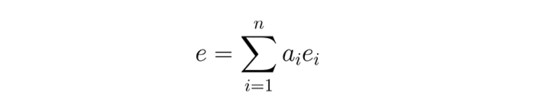

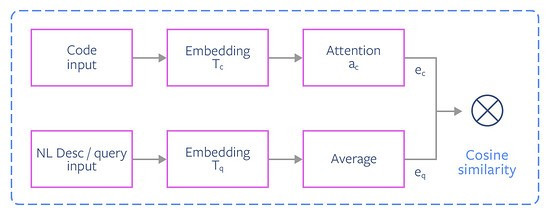
UNIF网络
检索的工作方式与 NCS 的方式相同。对于给定的查询,我们使用上述方法将其表示为文档向量,并使用 FAISS 查找与查询余弦距离最近的文档向量。(原则上,UNIF 也会像 NCS 一样从后处理排名中受益。)
与 NCS 进行结果比较
我们基于 Stack Overflow 评估数据集将 NCS 和 UNIF 进行比较,看看模型是否能在前 1、5 和 10 个结果中正确地回答查询,以及相应的 MRR 评分。下表显示,相比 NCS,UNIF 显著提高了回答的问题数量。

这突出表明,如果能够访问理想的训练语料库,监督技术可以提供令人印象深刻的搜索性能。例如,使用搜索查询「如何退出应用程序并显示主屏幕?」,NCS 返回结果:

(第一个代码片段来自于 GitHub 上的公共可用代码,在 Apache 2.0 许可下共享使用,链接:https://github.com/selendroid/selendroid/blob/master/selendroid-test-app/src/main/java/io/selendroid/testapp/WebViewActivity.java?fbclid=IwAR222brn93ZC3KK8kcTJhDhNMv8hc6JYSxv6KfQSSaklcm5WtLvmsc0uBQ0#L111-L114。第二个来自于 GitHub,在 MIT 许可下共享使用,链接:https://github.com/JosielSantos/android-metronome/blob/master/app/src/main/java/com/josantos/metronome/ui/activity/Base.java?fbclid=IwAR2xhso5v0vCAQBcNJ0DDg1DZLVdtC1hf5doVqwC1ib_rTB5bm38VSzLomo#L28-L36)
另一个例子是查询「如何获得 ActionBar 的高度?」NCS 返回结果:

(第一个代码片段来自于 GitHub 上的公共可用代码,在 Apache 2.0 许可下共享使用,链接:https://github.com/RealMoMo/Android_Utils/blob/master/SystemBarTintManager.java?fbclid=IwAR0SaLCK1xR18fxlfSvG72wcD4RBLnh7aZLNvCIls-Pe926LOpQ-2rmKPd0#L495-L497。第二个来自于 GitHub,同样在 Apache 2.0 许可下共享使用,链接:https://github.com/hearsilent/Universal-CollapsingTabLayout/blob/master/app/src/main/java/hearsilent/universalcollapsingtoolbarlayouttablayoutexample/libs/Utils.java?fbclid=IwAR38dLHvVRwZWGZoFTW6aniRbWQ0OAXAptH1lF-t1zyFuhopAJJVbGzkMpU#L36-L47)
本文还提供了关于 UNIF 表现的其他数据,链接:https://arxiv.org/abs/1905.03813?fbclid=IwAR10r1Y_3kKQ1nJ6OBWILQSa3xPS4rDjOBPQ2FC_SnwyNgJ532jwy-QfDHg。
构建基于机器学习的有效工具
创建一个成功的机器学习工具,关键之一在于获得高质量的训练数据集。对于我们的模型,我们使用了来自 GitHub 的大型开源代码库。此外,拥有高质量的评估数据集对于评估模型的质量同等重要。在探索一个相对较新的研究领域(如代码搜索)时,缺乏可用的评估数据集会限制我们通过各种代码搜索工具进行评估的能力。因此,为了帮助在这方面进行基准测试,我们从 Stack Overflow 整理了 287 个公共可用数据点的数据集,其中每个数据点由一个自然语言查询和一个「黄金」代码片段回答组成。
创建一个训练数据集
通过在 GitHub 上挑选 26,109 个最受欢迎的 Android 项目,我们直接在搜索语料库上训练我们的无监督模型 NCS。这也成为 NCS 返回代码片段的搜索语料库。
为了对我们的 UNIF 模型进行监督,我们需要一对对齐的数据点来学习映射。我们对 UNIF 进行了(c,q)数据点集合的训练,其中 q 是自然语言描述或查询,c 是相应的代码片段。我们通过从 Stack Exchange(CC-BY-SA 3.0 许可)公开发布的数据(链接:https://archive.org/details/stackexchange)中提取 Stack Overflow 问题标题和代码片段来获得这个数据集。在使用各种启发式方法过滤问题之后——例如,代码片段必须有一个 Android 标记,或者必须有一个方法调用,或者不能包含 XML 标记——我们最终得到了 451,000 个训练数据点。这个数据集与评估查询不相交。(这反映了训练数据集的最佳可用性;正如我们在一篇论文(该论文链接:https://arxiv.org/abs/1905.03813?fbclid=IwAR16thFXpe8iOKKfTNpGni9tpYDbYAxqRF8GotMPP-Jwhtja4CvBSvHmG0s)中所注意到的,基于文档字符串的训练没有得到好的结果。)
评估数据集
我们使用 Stack Overflow 问题评估 NCS 的有效性。Stack Overflow 是一种有用的评估资源,因为它包含大量的自然语言查询,以及可以作为可接受响应处理的向上投票的答案。给定一个 Stack Overflow 问题作为查询标题,NCS 从 GitHub 检索方法列表。在我们创建和改进 NCS 的工作中,我们认为如果来自 NCS 的 topn 结果中至少有一个与 Stack Overflow 应答代码片段中描述的方法匹配,那么搜索就成功了。(对于我们的评估,我们使用 top1、top5 和 top10 进行计算。)
我们使用脚本选择 Stack Overflow 问题,标准如下:1)问题包含「Android」和「Java」标签;2)有一个向上投票的代码答案;3)真值代码片段在我们的 GitHub Android repos 语料库中至少有一个匹配。通过人工处理确保问题是可接受的,我们得到了 287 个问题的数据集。
使用 Aroma 进行自动评价
我们发现,手工评估搜索结果正确性的操作很难重复进行,因为不同的作者和不同的人可能会有不同的观点。我们决定使用 Aroma 实现一个自动化的评估管道。Aroma 给出搜索结果与真值代码片段之间的相似性评分,以评估在得分超过阈值的情形下查询是否被正确回答。有了这个管道,我们可以用一种可重现的方式对模型进行评估。我们使用 Stack Overflow 上找到的代码答案作为评估的真值。
我们使用的上述评估过程不仅比较了 UNIF 和 NCS,还将 UNIF 与文献中其他一些代码搜索解决方案进行了比较。(相关比较的详细链接如下:https://arxiv.org/pdf/1812.01158.pdf?fbclid=IwAR0x2bvo-ItQHCeqdSb4f139HBpJdyzuQU0Famiwx52jCsWQKQu3MWuNdN4)
一个用于编写和编辑代码的基于机器学习的扩展工具包
随着大型代码存储库在当今生产环境中广泛可用,机器学习可以提取模式和观点,从而提高工程师的工作效率。在 Facebook,这些机器学习工具包括带有 Aroma 的代码到代码推荐和带有 Getafix 的自动 bug 修复。NCS 和 UNIF 是代码搜索模型的例子,它们可以在自然语言查询和查找相关代码片段之间架起桥梁。使用诸如此类的工具,工程师将能够轻松地找到并使用相关代码片段,即使是在使用专有源代码或使用不太常用的编程语言编写代码时也是如此。未来,我们希望在综合领域探索其他的深度学习模式,进一步提高工程师的工作效率。
相关文章
(1)Aroma: Using machine learning for code recommendation
链接:https://ai.facebook.com/blog/aroma-ml-for-code-recommendation/
(2)Recap of first-ever Glow Summit
链接:https://ai.facebook.com/blog/glow-summit-recap/
(3)Getafix: How Facebook tools learn to fix bugs automatically
链接:https://ai.facebook.com/blog/getafix-how-facebook-tools-learn-to-fix-bugs-automatically/
Via:https://ai.facebook.com/blog/neural-code-search-ml-based-code-search-using-natural-language-queries/

时间:2019-07-30 23:40 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]Facebook新AI模型SEER实现自监督学习,LeCun大赞最有
- [机器学习]来自Facebook AI的多任务多模态的统一Transformer:向
- [机器学习]更深、更轻量级的Transformer!Facebook提出:DeLigh
- [机器学习]堪比当年的LSTM,Transformer引燃机器学习圈:它是
- [机器学习]论机器学习领域的内卷:不读PhD,我配不配找工
- [机器学习]Facebook新AI模型SEER实现自监督学习,LeCun大赞最有
- [机器学习]来自Facebook AI的多任务多模态的统一Transformer:向
- [机器学习]更深、更轻量级的Transformer!Facebook提出:DeLigh
- [机器学习]机器学习基础图表:概念、原理、历史、趋势和算法
- [机器学习]分析了 600 多种烘焙配方,机器学习开发出新品
相关推荐:
网友评论:















