两张流程图解释什么是机器学习/人工智能
算法利用统计数据从大量数据中找到数据的模式。这里的数据可以有很多形式,如数值、文字、图像,甚至你点一次鼠标也算,反正就是你周围的一切一切。
只要它能被数据化,它就能用到机器学习算法中。

我们眼下用到的许多服务都得到了机器学习的赋能,如Netflix,youtube及spotify上的推荐系统,或是谷歌和百度等搜索引擎,或是Facebook和Twitter等社交媒体,或者Siri和Alexa这样的语言助手。它的应用场景还在不断扩大。
对于上述这些场景,每个平台都会尽可能多地收集关于你的信息,如你喜欢看什么书,或是你喜欢的网站,或是你当下的心情,然后用机器学习预测一下你的学历或是未来的学历。再或者,有了语音助手,无论你的口音多迷,都能给你匹配出词句。
说实话,这个过程挺简单的:找出模式,应用模式。这套路几乎全世界通用。

上图准确的说明了机器学习以及AI的模式
深度学习是什么?
深度学习是机器学习的一种:它用了一项技术,使得计算机找到数据中的最小模式并放大。这项技术叫做深度神经网络,称得上深度那是因为它将基本计算节点划分为多层,这些计算节点同时工作
神经网络是什么?
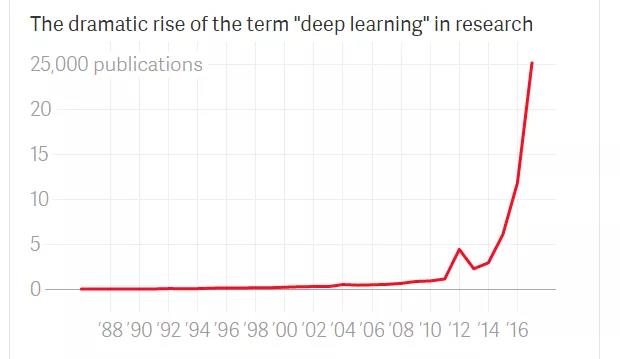
神经网络是由人脑内部构造启发的,这种网络结构有点像大脑本身。Hinton发表重要论文的时候神经网络已经不流行了。没人真知道怎么训练这个算法,所以也没人获得有效结果。这个技术花了三十年才重返潮流。天知道它是不是真的有转机。
你首先得知道的一件事是:机器(以及深度)学习分三种:监督式,非监督式和强化式。其中最热门的监督学习中,数据被标记好以告知计算机它所寻找的数据模式。请把它想象成一条一旦探知目标就会进行光速追捕的嗅探犬。当你在Netflix上点击播放按钮的那一秒,你在告诉算法获取相似影剧。
无监督学习是什么?
在无监督学习中,数据是没有被标记。我们只是让计算机看它能自行发现什么模式。这就好像让一条狗去闻无数不同的物品并把它们分类进相似的气味分组一样。无监督技术并不流行是因为他们没那么多典型应用。有意思的是,这些技术在信息安全方面获得了更多关注。
最后,我们还有强化学习,机器学习中最前沿的分支。强化学习算法通过反复实验来达成清晰目标。它尝试大量不同的事项,并基于它的行为对最终目的有帮助或是有阻碍来获得奖惩。
这就像在给狗训练新把戏的时候给它奖励品一样。AlphaGo,在复杂围棋比赛中击败最强人类选手而出名的Google程序的基础就是强化学习。
你想了解的机器学习基本都在这里。再次看一下机器学习流程图吧~
AI的更多背景知识流程图
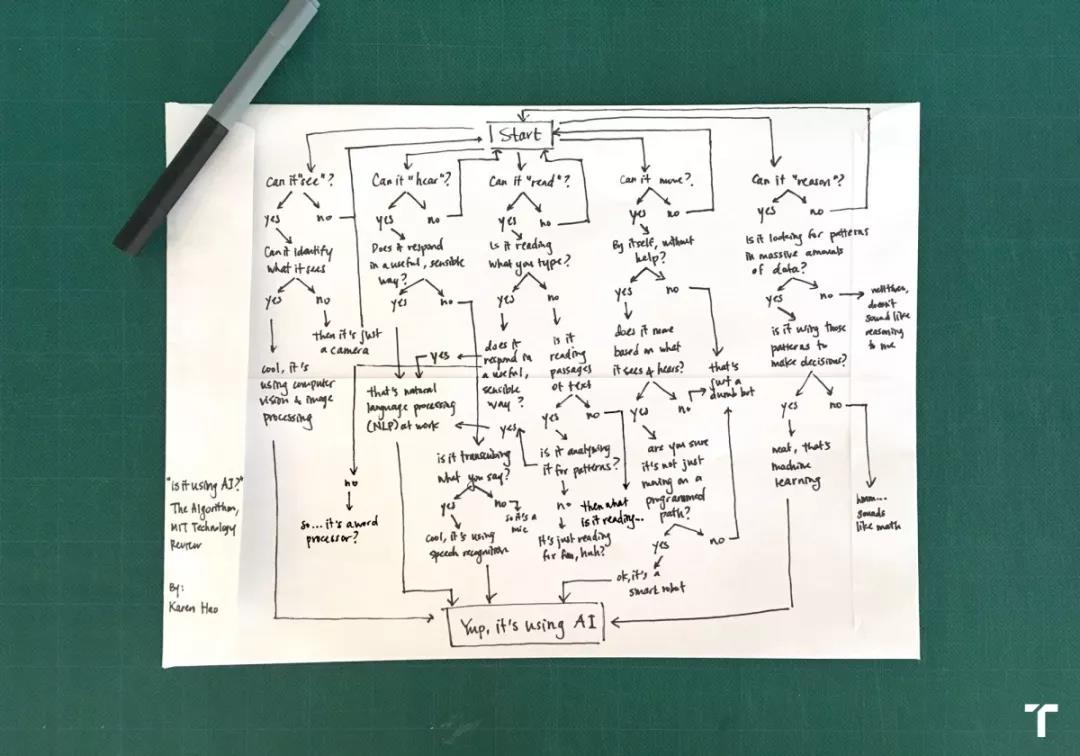
由于业界对AI的定义是不断变化的,这个术语也经常被弄的乱七八糟。例如过去被认为的人工智能系统,在今天看来或许有点牵强了
所以读AI背景知识进行梳理可以让你准确的掌握这个知识点。上图的梳理就能很好的帮助判断是否为使用了AI技术。
在最广泛的意义上,人工智能指的是能够为自己学习、推理和行动的机器。
也就是说当面对新的情况时,这些机器可以做出自己的决定,就像人类和动物一样可以思考。这通常被称为“强人工智能”或“AGI”。
一些专家认为,机器学习和深度学习如果有了足够多的数据,最终将使我们我们进入AGI。
虽然在其他方面它仍然比一个蹒跚学步的孩子笨得多,但确确实实通过数据AI已经掌握了围棋。

时间:2019-07-27 21:31 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















