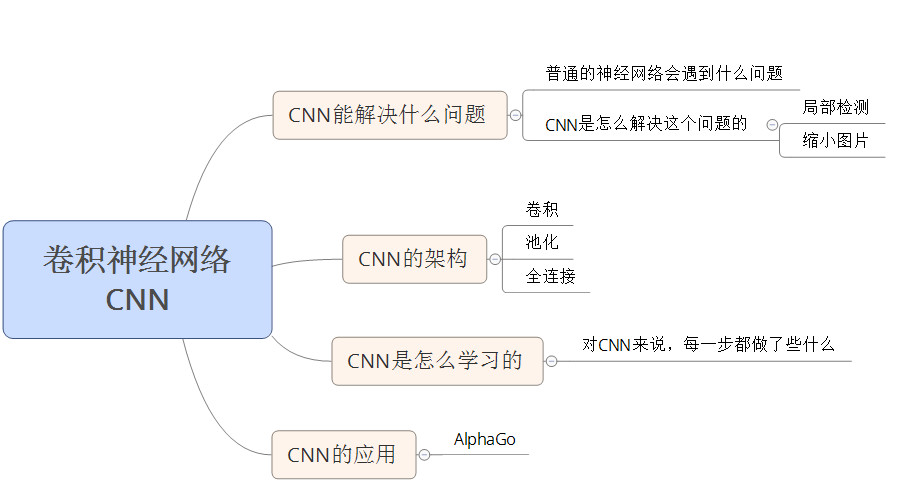
AI入门:卷积神经网络
讲到AI不得不讲深度学习,而讲到深度学习,又不能不讲卷积神经网络。如果把深度学习比作中国的互联网界,那卷积神经网络和循环神经网络就是腾讯和阿里级别的地位。今天我们主要讨论的卷积神经网络,到底卷积神经网络能解决什么问题,它的结构是怎样的?是怎么学习的?应用在哪些具体的产品上?本文将为大家一一解答。

如果对深度学习还不了解的同学,建议你先看下之前的文章《深度学习到底有多深?》,对深度学习有一定的认知,对接来了的讨论可能会更容易理解。
以下是本文讨论内容的大纲:
下文的卷积神经网络,我们用简称CNN表示。
01 为什么需要用到CNN?
1. 普通的神经网络会遇到什么问题?
假设我们要做图像识别,把一张图片丢到机器,机器能理解的就是每个像素点的值,如下图:
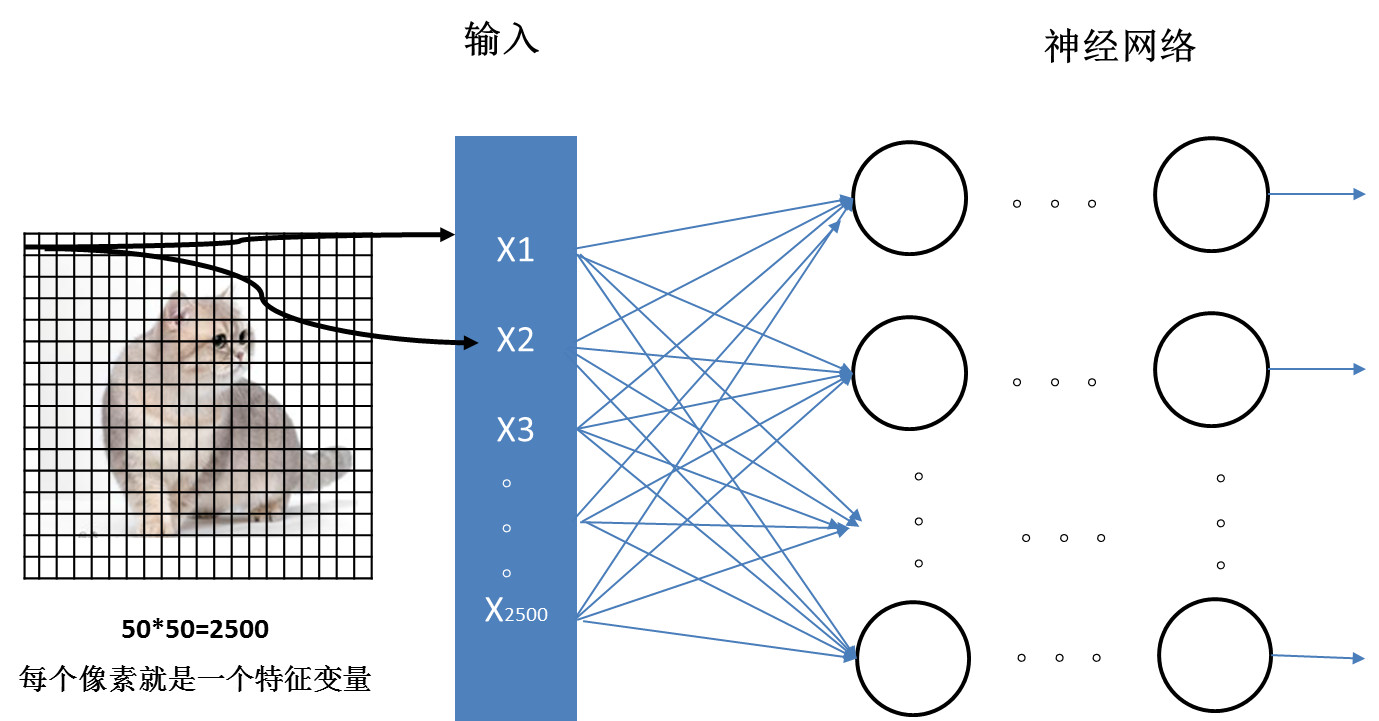
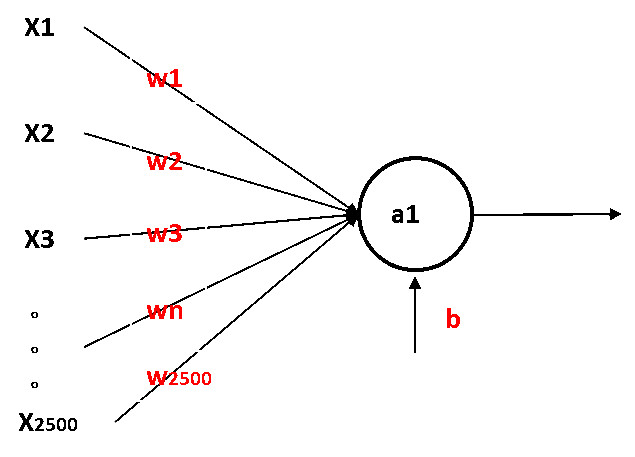
我们在搭建好神经网络模型之后,需要做的就是用数据训练,最终需要确定的是每一个神经元参数w和b,这样我们就可以确定模型了。
假设我们输入的是50*50像素的图片(图片已经很小了),这依然有2500个像素点,而我们生活中基本都是RGB彩色图像,有三个通道,那么加起来就有2500*3=7500个像素点。
如果用普通的全连接,深度比较深时,那需要确认的参数太多了,对于计算机的计算能力,和训练模型来说都是比较困难一件事。
因此,普通神经网络的问题是:需要确认的参数太多。
那CNN是怎么解决这个问题的呢?请接着往下看。
2. CNN是怎么解决这个问题的?
第一步:局部监测
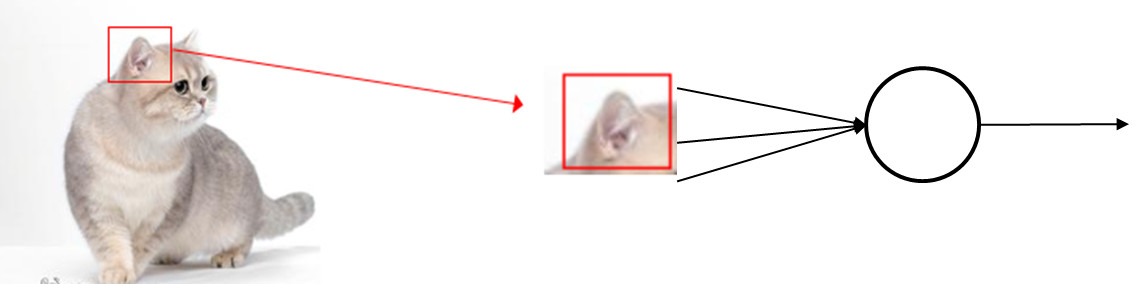
假设我们要看一张图片中有没有猫耳朵,也许我们不需要看整张图片,只需要看一个局部就行了。因此看是否是一只猫,只需要看是否有猫尾、是否有猫嘴、是否有猫眼,如果都有,那机器就预测说这张图片是一只猫。
因为这种方法看的是图片的局部,而不是全部,也就是说神经元连接的是部分的特征变量,而不是全部的特征变量,因此参数比较少。(如果这里看不懂没关系,我们后面会详细解释)。
看到这里你可能会疑问,我怎么知道取哪个局部,我怎么知道猫耳在图片的哪个部位?不着急,后面会讲到。
第二步:抽样,缩小图片

假设我们要识别一张50*50像素的猫相片,如果我们把图片缩小到25*25个像素点,那其实还是能看出这是一只猫的照片。
因此,如果把图片缩小了,就相当于输入的特征变量变少了,这样也能减少参数的量。
卷积神经网络就是用上面这两步的思想来减少参数,那具体CNN的架构是怎样的?又是怎么运行的?我们接下来详细讨论。
02 CNN的架构
CNN的架构流程图:
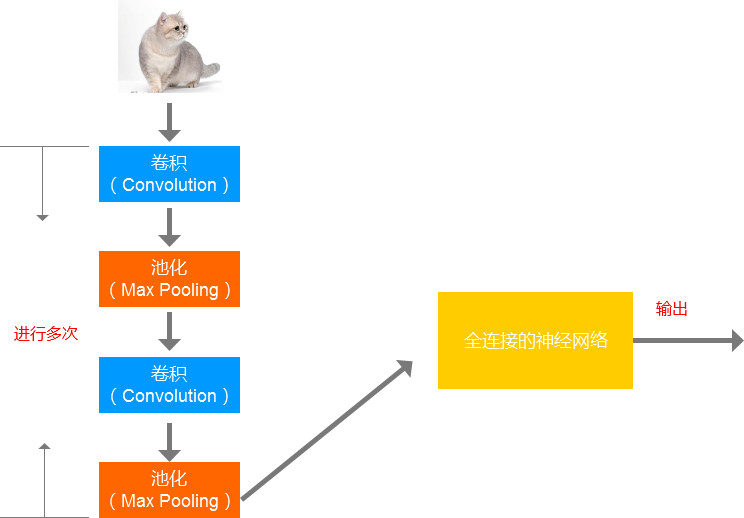
第一步:卷积,即局部监测。
第二步:特征抽样,即缩小图片。
然后重复第一、第二步(具体重复多少次,人为决定)。
第三步:全连接,把第一、二步的结果,输入到全连接的神经网络中,最后输出结果。
1. 卷积(Convolution)
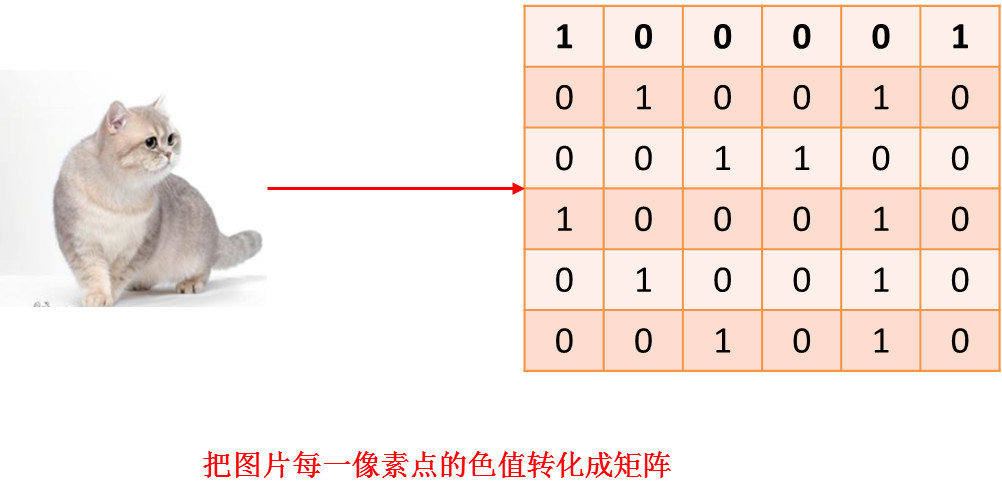
首先,把图片转化成机器可以识别的样子,把每一个像素点的色值用矩阵来表示。这里为了方便说明,我们就简化,用6*6像素来表示,且取只RGB图片一层。
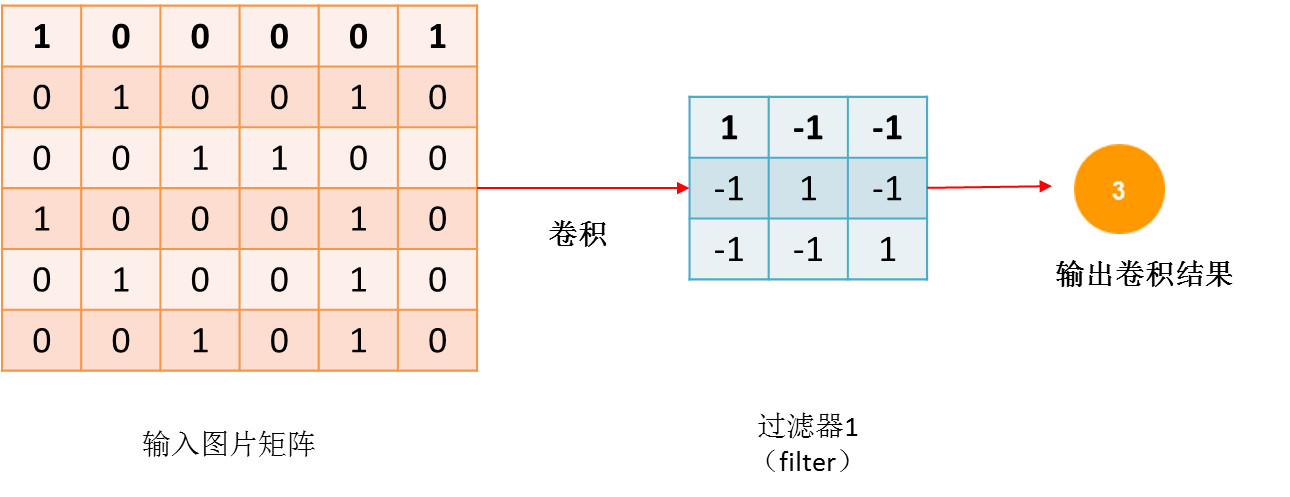
然后,我们用一些过滤器跟输入的图片的矩阵做卷积。(如果不知道卷积怎么运行的话,可以去问下百度)
那过滤器是什么呢?
——过滤器就是用来检测图片是否有某个特征,卷积的值越大,说明这个特征越明显。
说到这里,我们回顾一下前面提到的问题:我怎么知道取哪个局部,我怎么知道猫耳在图片的哪个部位?
用的办法就是:移动窗口卷积。
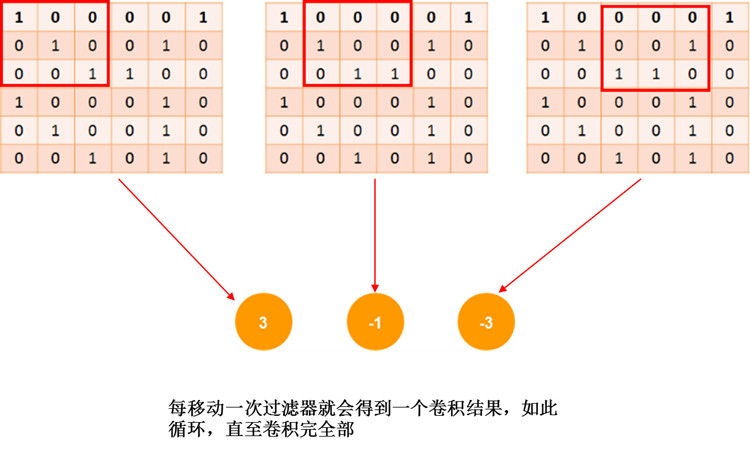

同一个过滤器,会在原图片矩阵上不断的移动,每移动一步,就会做一次卷积。(每一移动的距离是人为决定的)
因此移动完之后,就相当于一个过滤器就会检测完整张图片,哪里有相似的特征。
卷积跟神经元是什么样的关系呢?
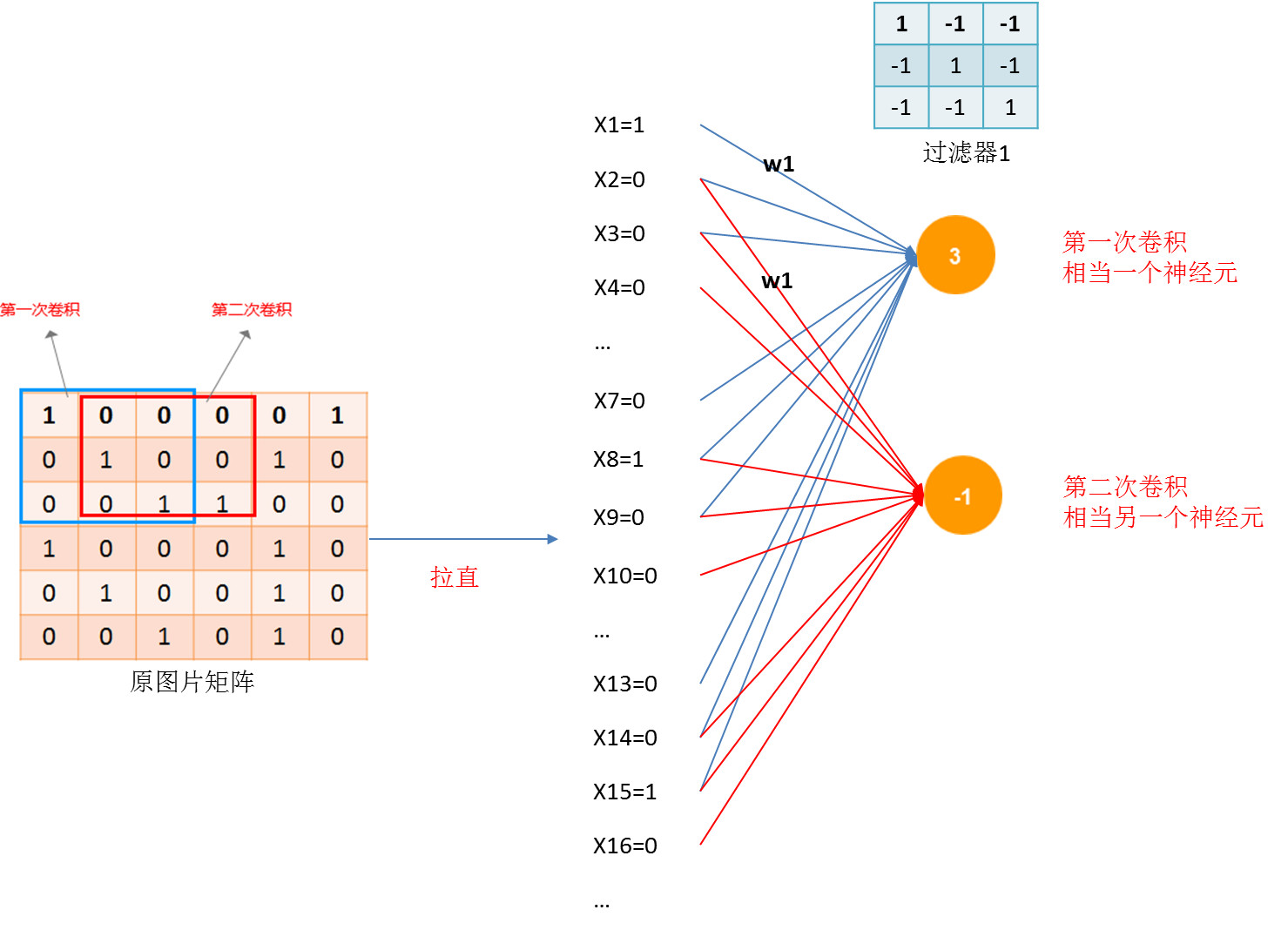
上图所示有3点需要说明:
1)每移动一下,其实就是相当于接了一个神经元。
2)每个神经元,连接的不是所有的输入,只需要连接部分输出。
说到这里可能你又会有疑问了,移动一下就是一神经元,这样不就会有很多神经元了吗?那不得又有很多参数了吗?
确实可能有很多神经元,但是同一个过滤器移动时,参数是强行一致的,公用参数的。
3)所以同一个过滤器移动产生的神经元可能有很多个,但是他们的参数是公用的,因此参数不会增加。
跟不同过滤器卷积:
同一层可能不止是跟一个过滤器卷积,可能是多个。
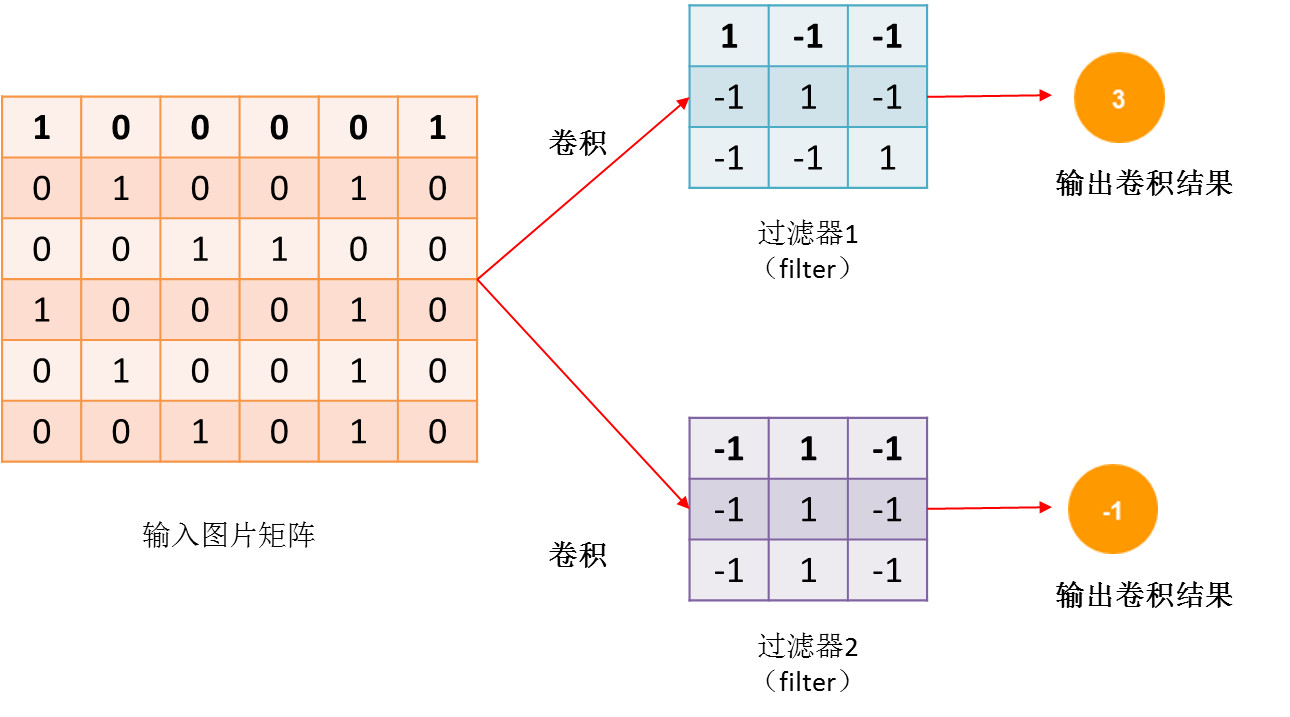
不同的过滤器识别不同的特征,因此不同的过滤器,参数不一样。但相同的过滤器,参数是一样的。
因此卷积的特点是:
- 局部检测
- 同一个过滤器,共享参数
3. 池化(Max pooling)
先卷积,再池化,流程图:
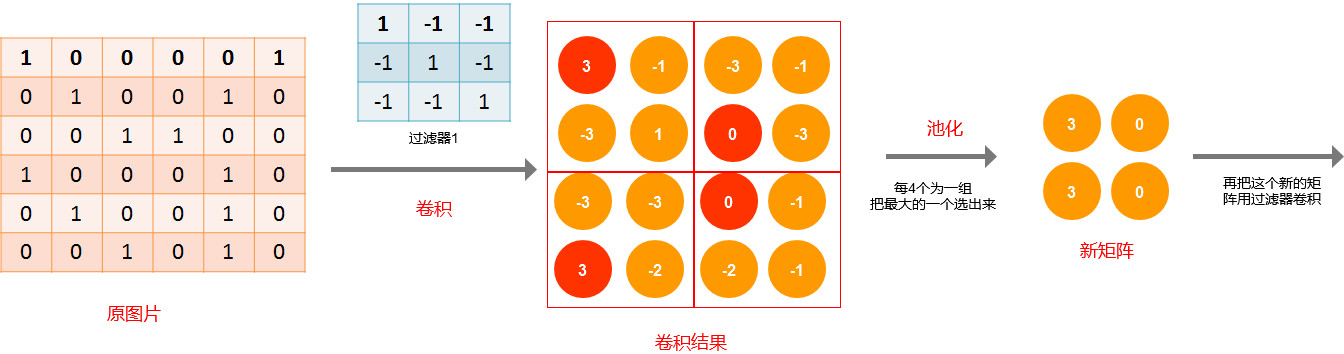
用过滤器1卷积完后,得到了一个4*4的矩阵,假设我们按每4个元素为一组(具体多少个为一组是人为决定的),从每组中选出最大的值为代表,组成一个新的矩阵,得到的就是一个2*2的矩阵。这个过程就是池化。
因此池化后,特征变量就缩小了,因而需要确定的参数也会变少。
4. 全连接
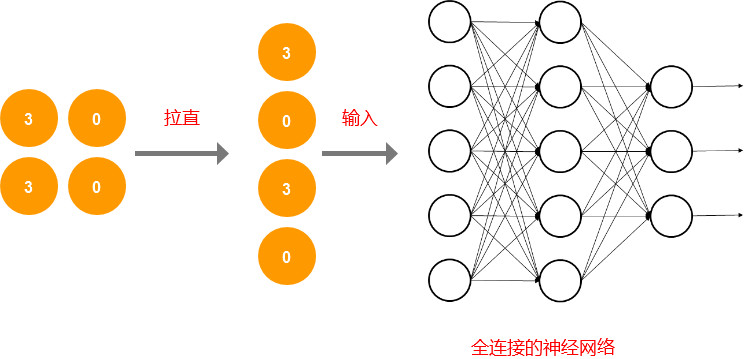
经过多次的卷积和池化之后,把最后池化的结果,输入到全连接的神经网络(层数可能不需要很深了),最后就可以输出预测结果了。
那到这里,我们把CNN的工作流程就讲完了,但是每一步具体的意义是什么,怎么理解?
可能你还不太理的顺,接下来我们会用一些可视化的方式帮助大家理解。
03 CNN是怎样学习的?
我们以AlexNet为例,给大家展示下CNN大致的可视化过程。
AlexNet是Alex Krizhevsky等人于2012年的ImageNet比赛中提出了新型卷积神经网络,并获得了图像分类问题的最好成绩(Top-5错误率为15.3%)。
AlexNet的网络架构:
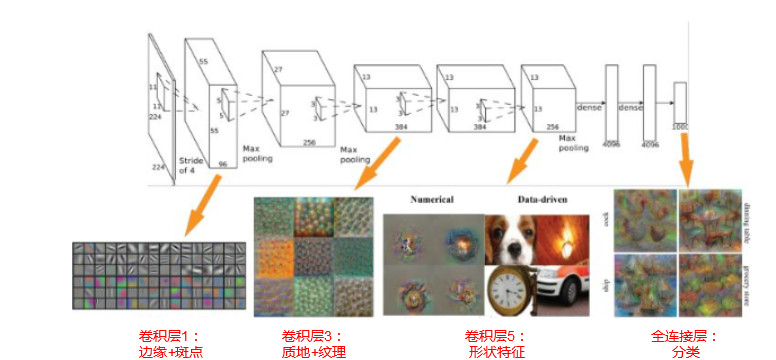
其实AlexNet的结构很简单,输入是一个224×224的图像,经过5个卷积层,3个全连接层(包含一个分类层),达到了最后的标签空间。
AlexNet学习出来的特征是什么样子的?
- 第一层:都是一些填充的块状物和边界等特征。
- 中间层:学习一些纹理特征。
- 更高层:接近于分类器的层级,可以明显的看到物体的形状特征。
- 最后一层:分类层,完全是物体的不同的姿态,根据不同的物体展现出不同姿态的特征了。
所以,它的学习过程都是:边缘→部分→整体。
关于卷积神经网络的可视化,大家想了解更多的话,可以参考文章《卷积神经网络超详细介绍》。
04 AlphaGo
前面我们提到了AlphaGo有用到CNN,那具体是怎么应用的呢,这里简答给大家科普下:
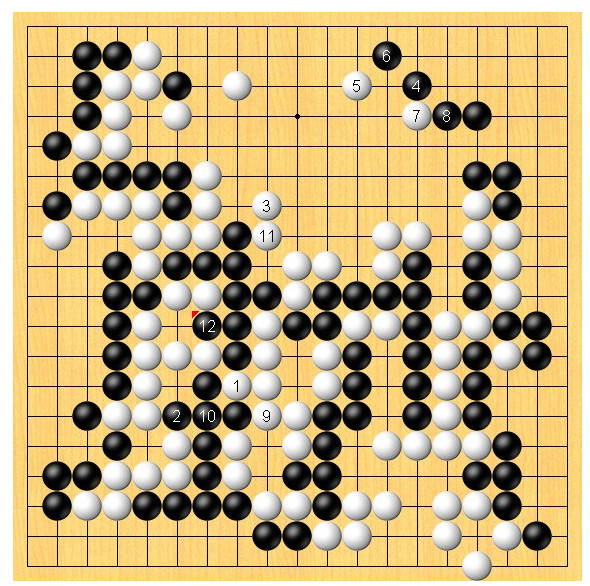
我们把围棋看成是一个19*19像素的图片,,每个像素点的取值:有黑子是1、有白子是-1,空为0。
因此,输入棋盘就是所有像素点的矩阵值,输出是下一步落子的位置。
那这个跟CNN有什么关系?
我们知道CNN擅长做的事情就是检测局部特征,那也可以把这项技能运用到下围棋上。

比如说上图这种特征,检测盘面上有没有这样的特征,如果有的话,通常下一步的落子是怎样。就好比玩剪刀石头布,检测到对方出剪刀,那机器的应对策略就是出石头。
同样可能有很多不同的特征,因此需要用不同的过滤器去检测。
而且,同一个特征可能会出现在不同的位置,因此也可以用过滤器移动的方法去检测。
AlphaGo 有没有池化?
讲到这里你会不会好奇,AlphaGo到底有没有用到CNN的池化。因为池化是把图片缩小的,围棋是19*19个点,如果缩成10*10个点,能行吗?
实际上AlphaGo是没有用到池化这一步的,所以说CNN也未见得一定要使用池化,还是需要实际问题实际解决,灵活应用。
好了,到这里就介绍完了CNN,后续我会写一篇文章介绍深度学习的另一大门派:循环神经网络RNN,感兴趣的同学记得关注哦。

时间:2019-07-27 21:03 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]2021年进入AI和ML领域之前需要了解的10件事
- [机器学习]来自Facebook AI的多任务多模态的统一Transformer:向
- [机器学习]来自Facebook AI的多任务多模态的统一Transformer:向
- [机器学习]AI已能求解微分方程,数学是这样一步步“沦陷”
- [机器学习]龙泉寺贤超法师:用 AI 为古籍经书识别、断句、
- [机器学习]2021年的机器学习生命周期
- [机器学习]AI 发展方向大争论:混合AI ?强化学习 ?将实际
- [机器学习]吴恩达:2020 年,这些 AI 大事件让我无法忘怀.
- [机器学习]年终总结:2021年五大人工智能(AI)和机器学习(ML)发展趋势
- [机器学习]AI种草莓,比最强人类多两倍:首次农业人机大战
相关推荐:
网友评论:















