深度学习在 360 搜索广告 NLP 任务中的应用
360 搜索广告成立于 2012 年,到今年是第 8 个年头了。
今天分享的内容分为两部分,第一部分是搜索广告和广告召回。我会介绍搜索广告的业务逻辑,以及召回模块的逻辑。第二部分是语义相关和深度学习,这部分会介绍语义相关的计算方法以及使用的深度学习模型。
▌搜索广告 & 广告召回
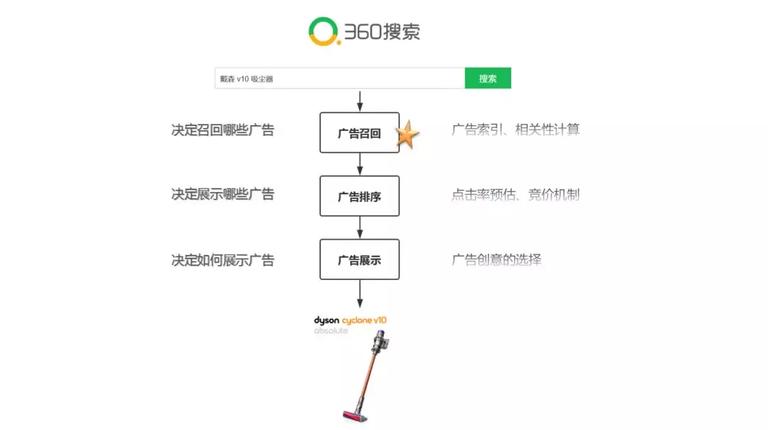
360 的搜索广告系统从逻辑上可以划分为三个模块:广告召回、广告排序和广告展示。
-
广告召回:这个模块决定召回哪些广告,涉及到广告索引和相关性计算;
-
广告排序:这个模块决定展示哪些广告,涉及到点击率预估和竞价机制;
-
广告展示:这个模块决定如何展示广告,涉及到广告创意的选择。
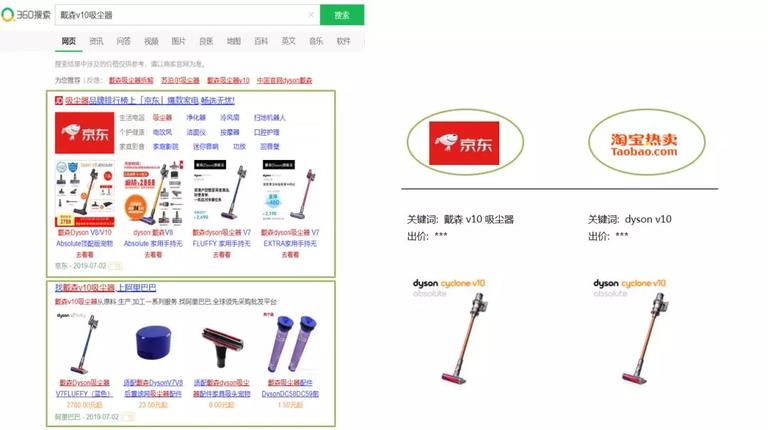
下面通过一个 Case,来说明 360 搜索广告系统的业务逻辑:
-
假设,我们两个电商行业的广告主,都购买了某品牌吸尘器的广告。他们向广告系统提交了关键词,和出价。
-
召回模块会计算 query 与广告关键词的相关性,根据相关性来决定是否召回这两个广告,结果是两个广告都相关,所以两个广告都召回。
-
广告排序模块,会计算两个广告的点击率和质量分,并根据竞价机制,来决定他们是否可以展示,以及展示位置。
-
最后,广告展示模块会根据广告主提供的物料以及展示位置,来选择广告创意。
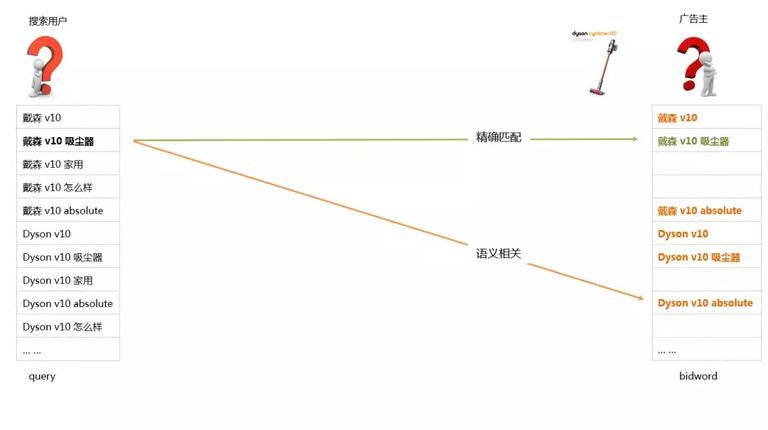
接下来继续应用这个 Case 来说明广告召回模块的召回逻辑:左边是用户搜索的 query,右边是广告主购买的关键词,这里有俩种召回方式,第一种是精确匹配召回,第二种是语义相关召回。

精确匹配召回对应的是一个 Match 的逻辑,可以理解成字符串的匹配,当然还有一些规则的匹配,比如这里会做一个切词之后的乱序的重排序,重排序之后如果能匹配上,我们也算是精确召回。
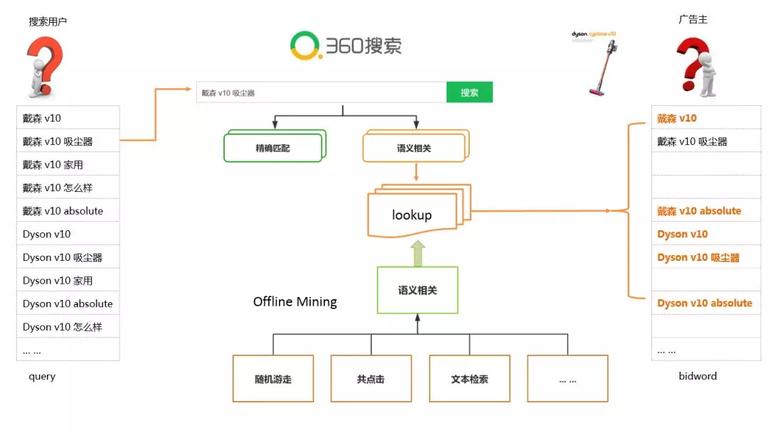
语义相关召回对应的是一个 lookup 的逻辑,这里查找的是一个 query 到 bidwords 的映射表, 这个映射表是由一个离线挖掘的流程提供的。而离线挖掘的流程是一个漏斗的逻辑。漏斗的上方是多种数据挖掘方法,比如随机游走,文本检索,等。这些方法提供 query 到关键词的候选集。漏斗的下方是一个相关性模块,这个模块对候选集进行相关性过滤,把过滤后的数据提供给线上的映射表。
所以处在漏斗下方的相关性模块直接决定了线上数据的质量。
▌语义相关 & 深度学习****
我们进入第二部分,语义相关和深度学习。
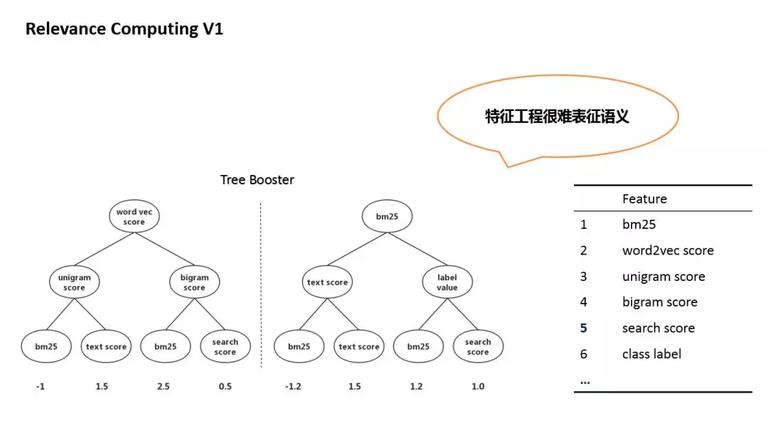
早些时候,计算语义相关性的方法,主要是特征工程 + GBDT。特征包括:文本相似度,embedding 相似度,bm25,以及搜索引擎提供的一些特征,等等。特征工程的问题在很难表征语义,所以准确率得不到保证。

随着 DeepLearning 技术的发展,nlp 领域的多个任务,相继提出了深层语义模型。
2013 年,web search 任务提出了 DSSM 模型,DSSM 对 query 和 doc 独立进行编码,编码层可以选择 FNN,CNN,或者 RNN,输出层用 cosine 和 sigmoid 来计算相关性。DSSM 的特点是 query 和 doc 独立编码,doc 的编码可以离线计算,线上只做 cosine 和 sigmoid 计算。
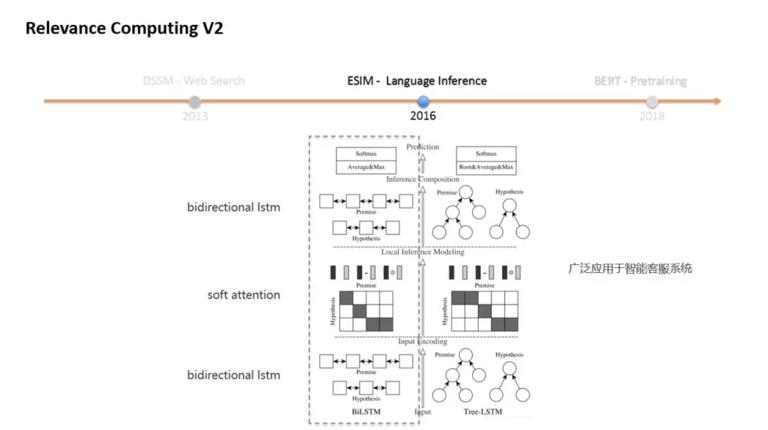
2016 年,language inference 提出了 ESIM 模型,ESIM 采用了两层 bidirectional LSTM,中间引入了 soft attention。这个模型广泛应用于智能客服系统。如果大家对智能客服了解的话,大概会知道客服系统一般会构建一个问答库,ESIM 用于计算问题和问题的相关性,然后把语义相同的问题归结到同一个答案上。这个就跟我们的广告词召回非常像了,我们的任务是让语义相同的 query 可以召回相同的广告关键词。
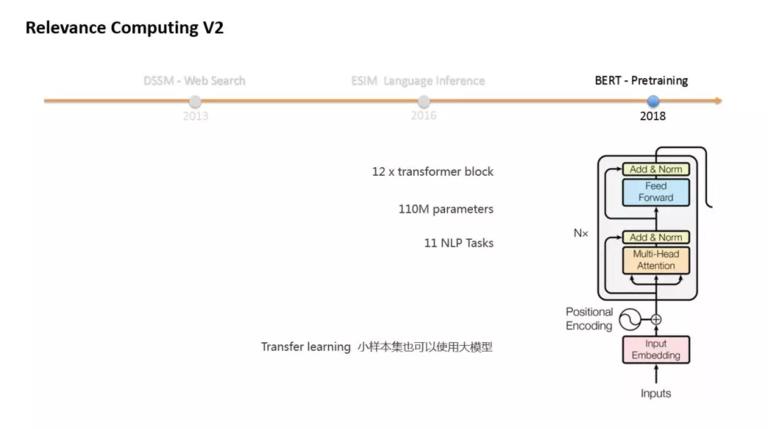
2018 年,也就去年,我们说,Bert 模型横空出世。Bert 采用了 pre-training 和 fine-tuning 的方式,真正意义上 实现了 NLP 领域的迁移学习。Bert 刷新了 11 项 NLP 任务的记录,其中就有两项语义相关的任务。
我想大家对 Bert 的评价主要是两种,第一种是,Bert 让我们看到了深层的 Transformer encoder 具有强大的语义表征能力。第二种更实际一点,是 Google 发布的 pretrain 的 model,中文方面就是那个 base 版的 Chinese model。他的意义在于,对于一些小样本的问题,我们用有限的样本,去 fine-tune 这个 model,就可以获得不错的效果。小样本使用大模型,这在之前是做不到的。
1. Models
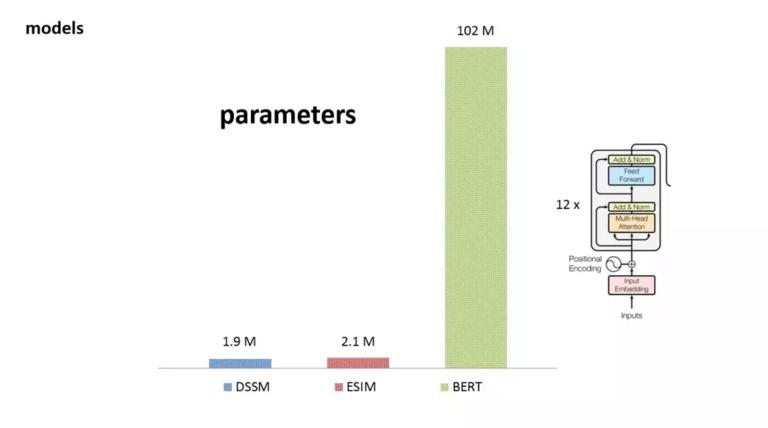
这是我们在实际工作中使用用的三个模型的参数对照。其中,DSSM 和 ESIM 参数数量都在 2M 这个量级。而 BERT 参数总量超过了 100M。之所有这么多的参数,是因为 bert 将 transformer 层累加了 12 层。而且每个 transformer 层又是一个 12 个 head 的 multi head Attention。
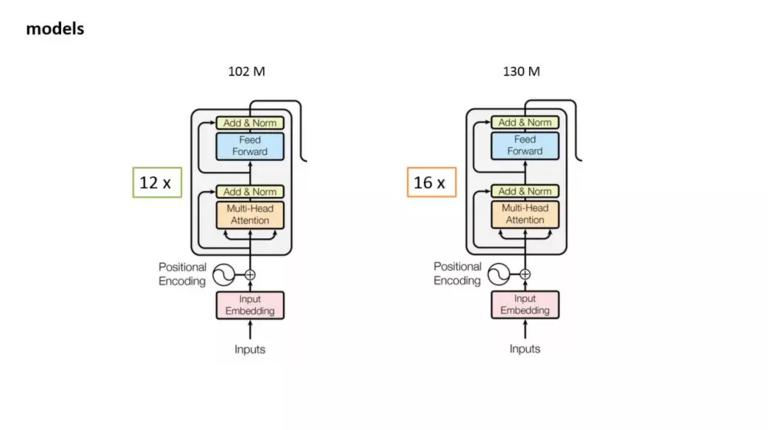
我们知道,Google 发布的中文的 model 是 12 层的 base 版 ,没有发布 24 层的 large 版。出于一个贪婪的想法,我们在 12 层上又累加了 4 层 transformer block,这时候,参数量从 102M 增加到 130M。如果大家有足够的训练数据,可以往上增加层数,如果数据量不够的话,使用原始的 12 层是足够的。
2. Data********

关于数据,我们把相关性的大小,定义为 0 到 4 的五个分值,相关性依次升高 。这和 bert 刷榜的 11 个任务中的 Semantic Text Similarity Benchmark 这个任务是一样的。同时,我们把 0 分和 1 分定义为负例,把 2 分,3 分,和 4 分定义为正例。
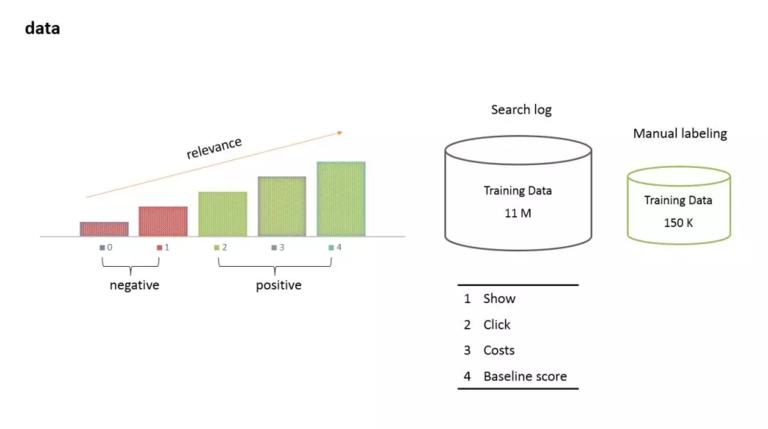
我们维护了两个样本集。大样本集有近 11M 样本,主要是通过广告点击日志筛选出来的。通常我们的筛选方式是结合展示,点击,消费数据,然后再加上一个 baseline 的预测值,综合几个维度,按照经验阈值来筛选。这个样本集的特点是样本量大,混淆度也大。我们还有一个小样本集有近 15 万样本,通过长期的人工标注和运营同学反馈得来的。
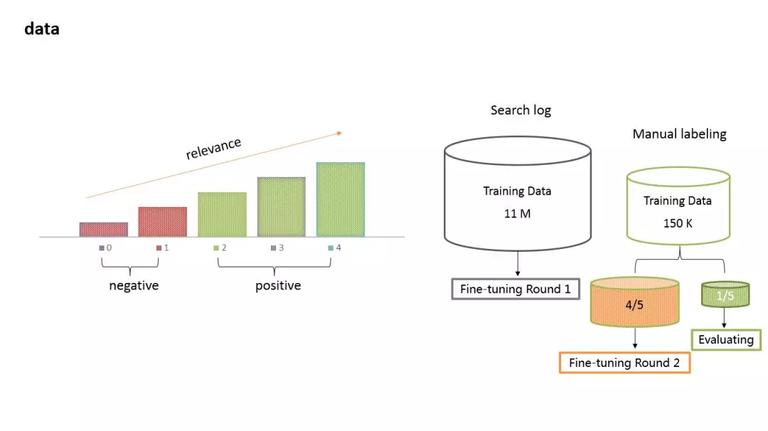
两个数据集使用的方式:首先用大数据集,来做第一轮的 training 或 fine-tuning;然后,从小数据集中选取 4/5 来训练第二轮,用剩余的 1/5 来做评测。
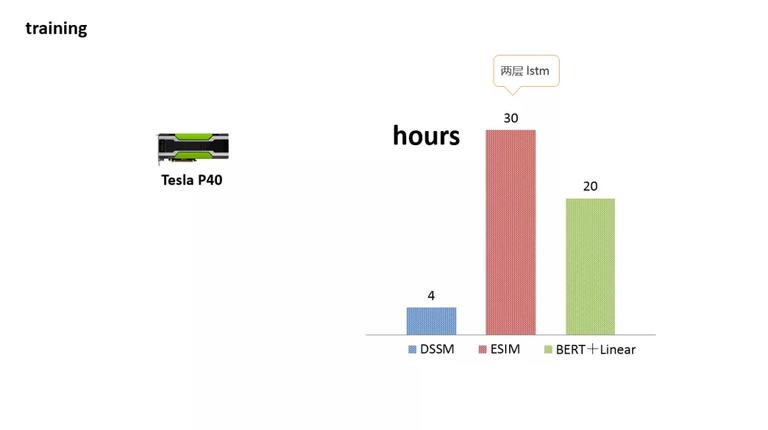
这是我们在一个 Tesla P40 上,训练三个模型的耗时。可以看到, 由于采用了两层 LSTM,ESIM 的耗时是最长的。
3. 性能评测********
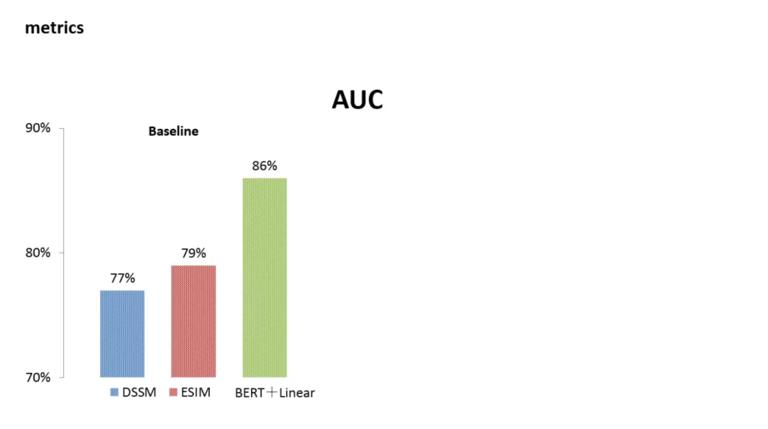
在衡量模型的指标上,我们选择了 AUC。DSSM 和 ESIM 的 auc 是比较接近的,ESIM 表现更好一些。通过分析 badcases,我们看到 DSSM 和 ESIM 还是比较依赖字面相关的,对语义的捕捉不是很好。而 Bert 的 Auc 达到了 86%。

以前面的模型为基础,我们又尝试了一些特征工程。我们结合了 bert 和 dssm 和其他十几维特征,训练 tree booster,AUC 可以达到 87 %。不过考虑到特征工程的复杂性,我们没有采用这个方案。最终,只采用单独 BERT 去做相关性服务。
4. 离线挖掘

这是我们的一个离线挖掘流程:
整个流程是个漏斗的逻辑。首先是用一些离线挖掘的方法,从日志中找到 pairs,或者用文本检索的方法,获取到候选集。然后通过相关性的预测,再通过 CTR 预测,最后把过滤后的结果发布到线上的 KV 系统。
所以,整个 360 的广告召回模块就是这样,按照两种召回方式,其中语义相关召回方式会提供一个非常大的空间,这个召回方式采用了一个离线的挖掘流程。然后采用相关性计算、CTR 预估过滤流程来提供映射表。这是今天分享的全部内容,谢谢大家。

嘉宾介绍
高凯明,360 算法专家。主要研究方向为自然语言处理,信息检索和机器学习。目前从事搜索广告业务中 NLP 相关的算法工作,负责搜索广告 query 改写,相关性计算等。

时间:2019-07-23 22:34 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















