贝壳智搜:月老手中那一根根红线
作为个性化推荐系统中重要的一环,构建一个成熟、健全、相互关联的标签体系至关重要。相较于粗粒度分类,标签可以更为灵活、精准地定义某个人或物的多属性,宛若一根根线头,穿穿绕绕,勾连起这个世界。程序眼中万物皆对象,而在标签建设者眼中,则万物皆可有标签。
现实搜房场景中,客户的找房意图多种多样,不同阶段对房产知识、资讯的需求也千变万化。贝壳找房作为中国最大的居住服务平台,拥有海量的房源、客户、经纪人和文本内容数据。本文主要探讨如何依托这些数据构建和利用标签体系,为客户和房子牵线搭桥,从而满足客户个性化的找房需求,为经纪人提效赋能。鉴于作者工作方向专注于文本内容挖掘,本次分享内容侧重于文本标签的构建方法。
一、 数据背景
以数据和科技为核心驱动力的贝壳找房,拥有庞大的数据资产。这些数据包括耗费十数年积累的房屋数据、客户数据、交易数据以及内容文本数据。其中,房屋数据包含上百种房子的属性、小区属性和周边各种 poi 地理实体信息;客户数据包括用户的搜索记录、向经纪人表述的口语化的找房对话、内容阅读历史等;内容文本数据则包括房产知识文章、房产资讯、房产问答、房屋评价等文本类数据。
所谓找房,自然是要为用户找到满意的房子,或者想要了解的房产知识和资讯。然而用户的找房意图千变万化,时而明确,时而模糊抽象,简单的属性召回已经不能满足更为广泛、个性化的找房需求。标签作为实体的一种重要属性,其灵活性和易关联性为匹配用户需求提供了一种解决方案。
二、 标签体系结构
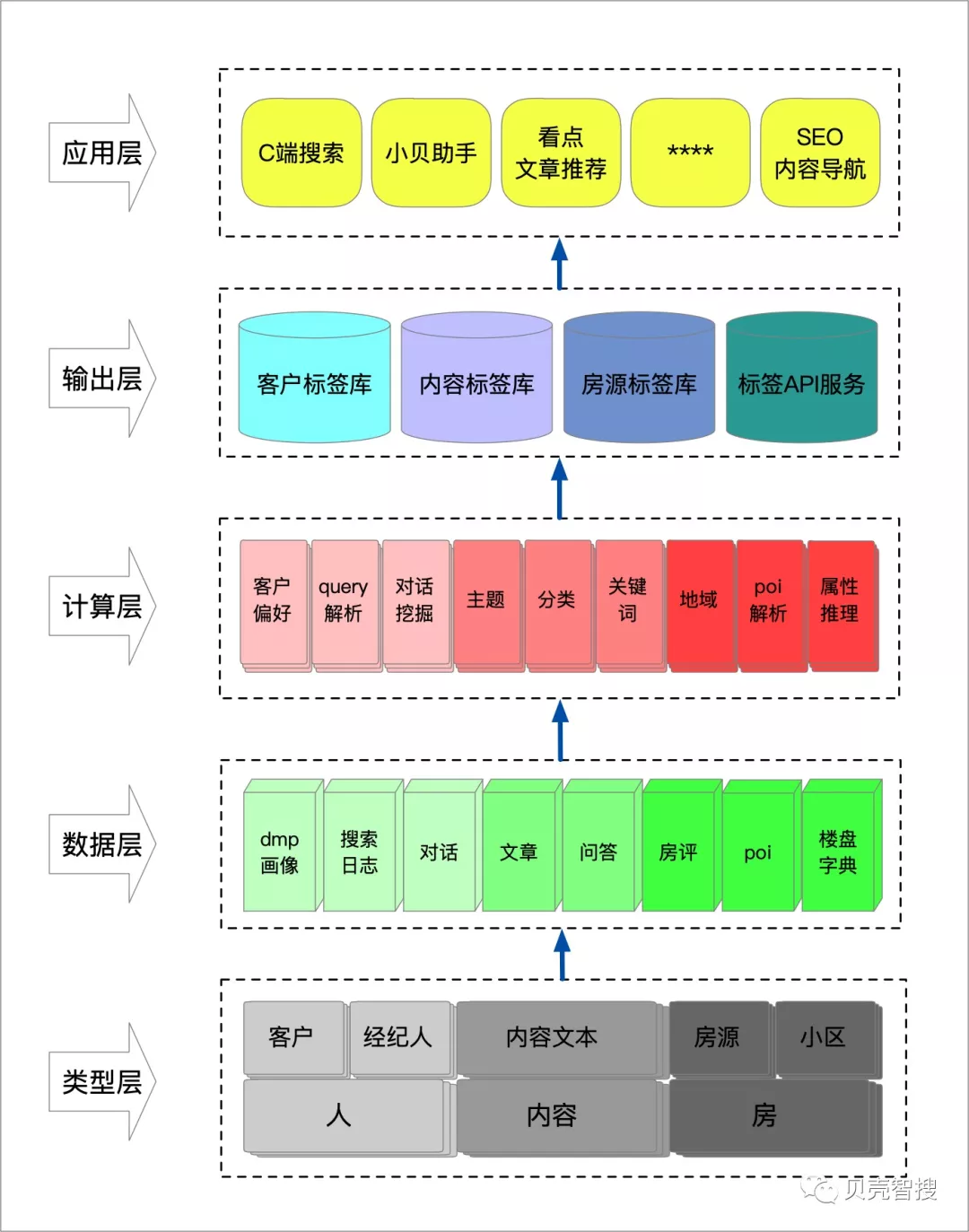
标签体系的构建和应用,自底向上大致划分为如下几个层次:
-
类型层
人、房、内容是标签体系中重要的三种实体类型,标签从他们中来,最终也要到他们中去。“人”是数据的核心,贝壳找房主要服务于两群“人”,C 端的客户,以及 B 端的经纪人;而内容类型主要指各式的文本数据;房子类型实体则分为房源和小区两种。 -
数据层
数据层罗列了构建标签体系的基础数据来源。与客户、经纪人直接相关的数据有 dmp 画像、搜索日志、找房会话等;内容文本主体由文章和问答构成;房源和小区标签的产生则依托于健全的楼盘字典数据、百度 poi 地标数据、和房源小区评价数据。 -
计算层
计算层针对结构化和非结构化的基础数据,进行标签构建和挖掘。对于结构化和半结构化的数据,如 dmp 画像、poi 信息和楼盘字典,一般采取归纳推理的方式推断标签;而对于非结构化的文本数据,标签化的方式则主要包括正则挖掘、主题归纳、构建分类模型、抽取关键词、地域多模匹配等。 -
输出层
输出层包含标签库和 API 两种形式。构建的标签库以离线 hive 表的形式存储输出,根据检索需求可导入 ES 或 Redis;同时文本类标签模型以 API 服务的形式对外提供打标签服务。API 与应用层交互存在有三种形态:API(正排),API 召回(倒排),以及一种衍射态:相似实体扩展(正排后倒排)。 -
应用层
标签体系可应用于多个应用场景,现阶段可支持的项目有 C 端自然语言搜索、小贝智能助手、Feed 看点文章推荐、SEO 内容导航等。
三、 构建方法
对标签体系层次有一定概念后,本小节主要阐述各种标签及其挖掘流程。单纯就标签挖掘而言,并不存在技术上的难点,困难在于如何在标签挖掘过程中建立各种标签之间的联系。因为我们的最终的目的是以标签的方式为人、房、文本牵线搭桥,在构建过程中,标签之间的对应关系就显得尤为重要。
因为篇幅和作者水平有限,本节侧重于介绍非结构化的文本标签体系的构建。客户方面已有 DMP 团队积累的用户画像标签,房源的各字段属性前期也已经作为标签应用于智能搜索中,本节不进行过多阐述,仅简单介绍一些更抽象的推理性质的客户和房源标签。构建过程涉及的技术原理不多,更多的是在于标签种类和挖掘流程的沉淀。
3.1 内容标签
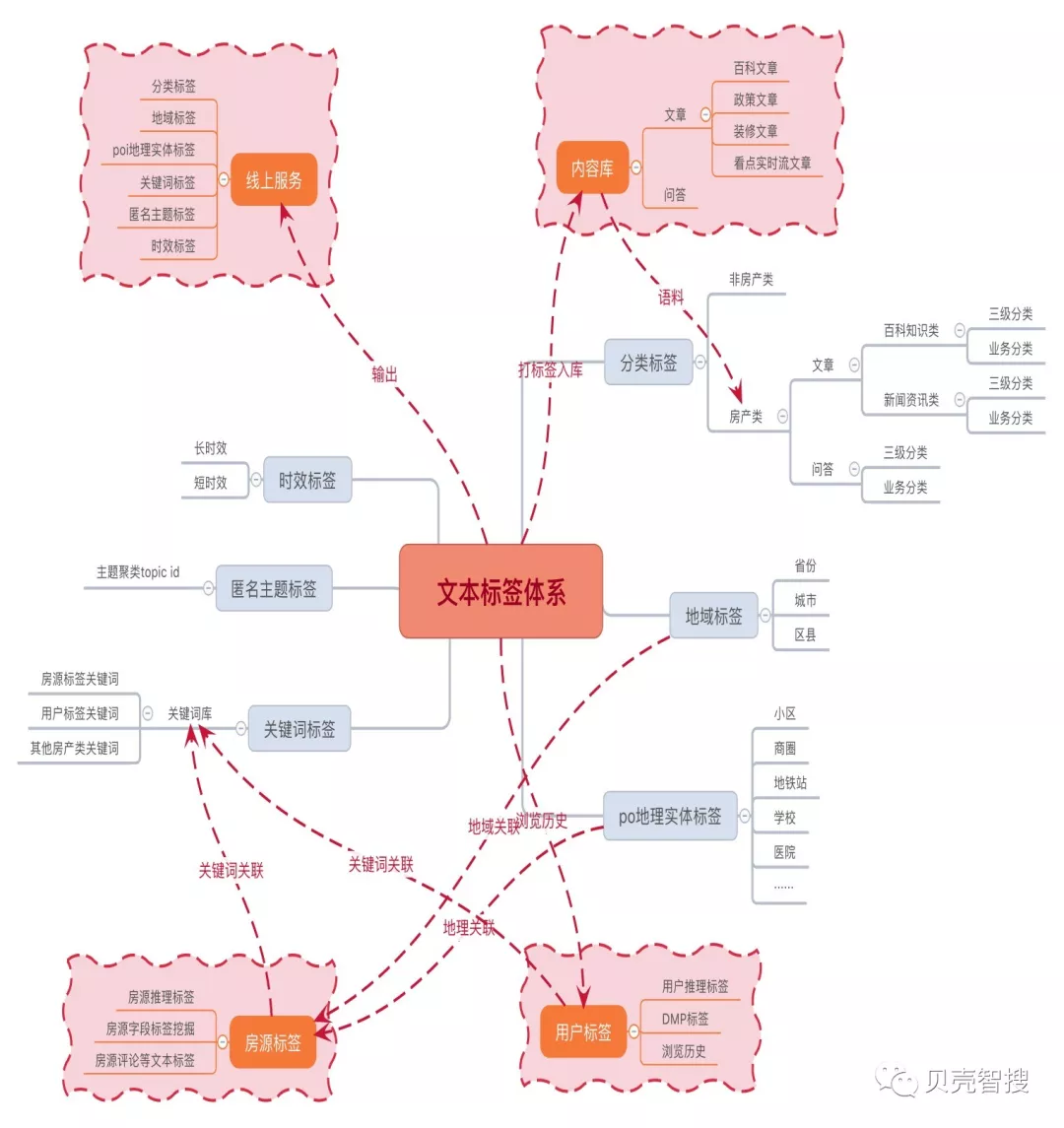
如图中所示,文本标签体系涵盖了文本内容挖掘的各个方面。这里的标签是一种广义性质上的定义,包含了粗粒度的分类标签、地域性的城市地标标签、动态灵活的关键词标签、匿名主题聚类标签和长短时效的时效性标签。其中文本关键词、涉及地理实体可以与房屋属性、周边 poi 进行关联,可用于文本嵌入房源卡片。而文本的分类和关键词标签则可与用户的阅读历史关联,用于用户偏好归纳和资讯、房源推荐。最终,文本内容以离线数据库的形式存储,并输出线上的打标签服务。
3.1.1 分类标签构建
分类作为一种粗粒度的标签,虽然没有那么精细,但是应用在内容导航和相似召回中,可以起到很好的效果。在房产垂直领域,房产知识和资讯构成了内容库的主体。我们在构建房产文章分类体系过程中,摸索了一套快速构建三级分类体系的流程。

-
面对杂糅在一起的文章,聚类分析是要进行的第一步工作。文本聚类可以用于分析文章内容的大致主题分布,方便人工抽象和归纳。我们尝试了两种方式进行主题聚类:(LDA)和 (文本向量化 + k-means)。实验结果表明采用 LDA 的效果较好。而 k-means 向量化聚类效果的好坏很大程度上取决于文本语义向量的优劣,相对更不可控。
-
得到聚类后的主题和关键词后,结合文本分布,我们联合运营的专业人员对主题进行了归纳和总结。参照其他相关的分类体系,抽象出初始的类别体系,并将主题关键词挂靠到相应类别。
-
使用主题和关键词正则筛选出初始训练集,并进行人工标注。标注时标注人员只进行对错标注,只对分类错误的文章进行矫正,这样可以大大提高标注人员的标注效率。
-
根据初始的训练集,采用 fasttext 训练模型,并生成新的预标注训练集,进行标注评估和校准,补充训练集,更新模型。循环迭代,快速提升分类效果。
-
由于定义的类别可能不合理,在标注训练集的同时,要对类别体系进行优化。合并区分度低的类别,并逐步细化粒度过粗的分类。如此,不断循环。训练集不断扩充,类别体系也逐渐趋于合理。
在训练模型过程中,也存在一些需要小心克服的困难,不解决这些问题,就很难得到理想的分类准确率。
-
训练集每个类别的文章量可能极度不均衡,这在很大程度上会影响 fasttext 模型的效果。算法上可以考虑上下采样的方式均衡训练集,而人工层次上则可以考虑归并文量过少的类别和细分文量过大的类别。
-
由于文章篇幅一般较长,一篇文章可能同属于多个分类,这些文章存在于训练集中会模糊类别边界,给分类准确率带来不好的影响。所以在标注训练集时尽量选取内容偏单一类别的文章,而忽略内容宽泛的文章。虽然这样有可能容易导致训练集过拟合,但是在判断新文章时,单一分类的文章准确性可以提高,多分类的文章各个类别的概率值也会比较相近,便于 top 选取。
3.1.2 其他文本标签
相对于分类,其他文本标签没有那么复杂。下面简要列举一下每种标签的挖掘算法和策略
-
关键词标签
-
算法:tf-idf + textrank
-
策略
-
抽取关键词,按权重排序,选取 top n。
-
维护一个动态审核更新的标签池,过滤掉不在池子中关键词,以防止非房产类等词语出现。
-
城市、省份地域标签
-
算法:ac 自动机 多模匹配
-
策略:
-
如果有标题等概要式文本,提高标题权重。
-
使用简称增大匹配召回。
-
使用子级匹配父级行政区,如通过海淀匹配北京。
-
选举匹配度最高的城市、省份,无匹配则默认全国。
-
poi 地理实体标签
文本中可能会涉及某某学校、医院、地铁站、商圈等地理实体数据。短文本可以通过智搜团队的 query 解析进行精准识别。而对于文章类长文本,我们仍然采用多模匹配算法进行识别。
-
算法:ac 自动机 多模匹配
-
策略:
-
整理获取地标类实体名称及别名挖掘数据,百万量级。
-
构建 ac 自动机模型。
-
限定文本、poi 地理实体同城市匹配,减少重名误判率。
-
准确度,覆盖度评估。
-
匿名主题标签
-
算法:LDA、doc2vec + kmeans
-
策略:有时推荐和相似性文本召回,并不需要定义好的类别。直接使用聚类 id, 就可以达到很好的效果。相比人工抽象和构建分类体系,匿名主题标签虽然牺牲了可展示性,但是应用上却省心省力了很多。
-
时效标签
-
算法:规则 + fastext
-
策略:
-
长时效文章多为知识性文本,诸如看房技巧、买房知识等,短时效文章则多为资讯类文章。
-
先采用时效关键词规则判断短时效文章。
-
再使用 fastext 模型对文本时效进行分类。
3.2 客户 & 房源推理标签
在搜房场景中,客户的需求可能是模糊而抽象的。例如客户想要找到一些方便孩子上学的,或是适合老人的,或是安静的房子,而对于房子具体要在哪个位置,几室几厅没有明确的要求。单纯的房屋面积、楼层、位置等属性已经不能满足这种口语化的找房需求。此时,高层次的、抽象化的推理标签挖掘就显得很有必要了。
上图以老人、孩子、汽车为例,简要展示了客户和房源推理标签的挖掘步骤和关联关系。其中用户的推理标签可以基于 dmp 画像、query 历史、找房对话数据进行归纳和挖掘。而房源推理标签标签则主要依赖房源固有字段和对周边 poi 地标信息解析,以房源评论和小区攻略信息作为补充,建立打分规则,进行归纳和筛选。
客户会在对话和搜索中表达购房意愿,比如想要环境安静、方便照顾老人等等。我们可以从这些文本信息中挖掘用户的找房意图,同时结合用户的 dmp 画像,为客户归纳出一些抽象标签。最终得到的推理标签也可以反馈补充到 dmp 画像。
而在房源端,根据房源及周边数据,可以推断出与客户相同类型的标签。例如,可以通过低楼层、南北通透、靠近综合医院、公园、超市等推断房子适合老人;通过靠近学校、绿化率高、有门禁、人车分流等推断房子适合孩子。我们利用贝壳文章库、知识库和知乎等第三方平台,搜索了大量诸如“什么样的房子适合老人”的相关知识,为每一个推理标签建立了一套打分规则,应用到房源和小区,生成房源推理标签。
最终客户和房源推理标签采用相同的 id 直接进行关联,导入 ES 或 Redis,以支持房源检索召回。
四、 小结与展望
本文主要介绍了基于文本、房源和客户的标签体系构建方法。内容以文本标签为主,阐述了每一种标签的挖掘流程和方式。标签构建在算法难度上门槛比较低,而且构建初期基本采用规则的方式以便快速应用,后期有了数据积累才逐渐转化为算法的方式。为了方便标签的使用,不同种类标签的关联性应该是构建过程中应该着重考虑的部分。文中第三小节,以简单的老人、孩子、汽车为例,简单介绍了客户和房源推理标签如何进行关联。
标签库的建设仍然处在初级阶段,虽然结构较为清晰,但标签的种类仍然较为单一,很多细节也需要优化。增加标签种类,提升准确度和覆盖度,加强标签间的联系是健壮和健全现有标签体系的三个方向。 每一种标签,都是一个线头。学好针线活,把握每一个线头,加油,少年~
本文作者
-
【苏文博】2018年毕业于日本早稻田大学,9月加入贝壳,主要从事文本类挖掘工作。

时间:2019-07-26 18:22 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















