使用深度学习检测疟疾

人工智能结合开源硬件工具能够提升严重传染病疟疾的诊断。
人工智能(AI)和开源工具、技术和框架是促进社会进步的强有力的结合。“健康就是财富”可能有点陈词滥调,但它却是非常准确的!在本篇文章,我们将测试 AI 是如何与低成本、有效、精确的开源深度学习方法结合起来一起用来检测致死的传染病疟疾。
我既不是一个医生,也不是一个医疗保健研究者,我也绝不像他们那样合格,我只是对将 AI 应用到医疗保健研究感兴趣。在这片文章中我的想法是展示 AI 和开源解决方案如何帮助疟疾检测和减少人工劳动的方法。

Python 和 TensorFlow: 一个构建开源深度学习方法的很棒的结合
感谢 Python 的强大和像 TensorFlow 这样的深度学习框架,我们能够构建健壮的、大规模的、有效的深度学习方法。因为这些工具是自由和开源的,我们能够构建非常经济且易于被任何人采纳和使用的解决方案。让我们开始吧!
项目动机
疟疾是由疟原虫造成的致死的、有传染性的、蚊子传播的疾病,主要通过受感染的雌性按蚊叮咬传播。共有五种寄生虫能够引起疟疾,但是大多数病例是这两种类型造成的:恶性疟原虫和间日疟原虫。
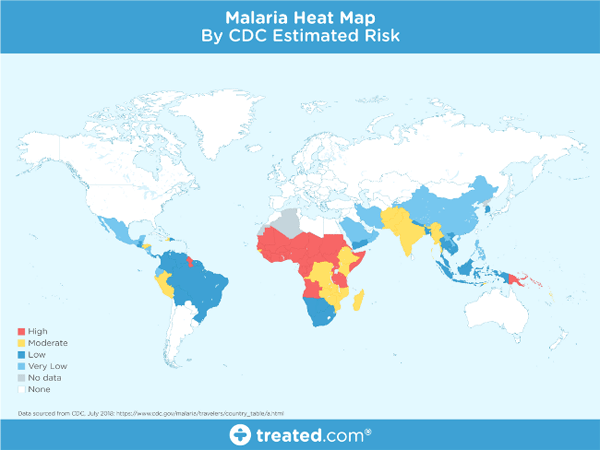
疟疾热图
这个地图显示了疟疾在全球传播分布形势,尤其在热带地区,但疾病的性质和致命性是该项目的主要动机。
如果一只受感染雌性蚊子叮咬了你,蚊子携带的寄生虫进入你的血液,并且开始破坏携带氧气的红细胞(RBC)。通常,疟疾的最初症状类似于流感病毒,在蚊子叮咬后,他们通常在几天或几周内发作。然而,这些致死的寄生虫可以在你的身体里生存长达一年并且不会造成任何症状,延迟治疗可能造成并发症甚至死亡。因此,早期的检查能够挽救生命。
世界健康组织(WHO)的疟疾实情表明,世界近乎一半的人口面临疟疾的风险,有超过 2 亿的疟疾病例,每年由于疟疾造成的死亡将近 40 万。这是使疟疾检测和诊断快速、简单和有效的一个动机。
检测疟疾的方法
有几种方法能够用来检测和诊断疟疾。该文中的项目就是基于 Rajaraman, et al. 的论文:“预先训练的卷积神经网络作为特征提取器,用于改善薄血涂片图像中的疟疾寄生虫检测”介绍的一些方法,包含聚合酶链反应(PCR)和快速诊断测试(RDT)。这两种测试通常用于无法提供高质量显微镜服务的地方。
标准的疟疾诊断通常是基于血液涂片工作流程的,根据 Carlos Ariza 的文章“Malaria Hero:一个更快诊断疟原虫的网络应用”,我从中了解到 Adrian Rosebrock 的“使用 Keras 的深度学习和医学图像分析”。我感激这些优秀的资源的作者,让我在疟原虫预防、诊断和治疗方面有了更多的想法。
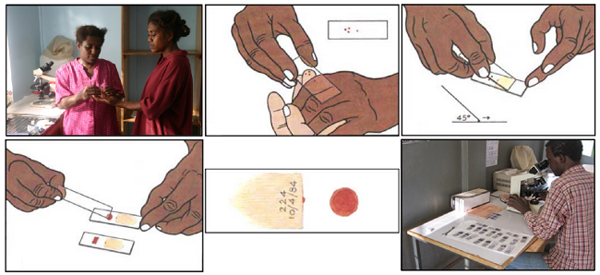
一个疟原虫检测的血涂片工作流程
根据 WHO 方案,诊断通常包括对放大 100 倍的血涂片的集中检测。受过训练的人们手工计算在 5000 个细胞中有多少红细胞中包含疟原虫。正如上述解释中引用的 Rajaraman, et al. 的论文:
厚血涂片有助于检测寄生虫的存在,而薄血涂片有助于识别引起感染的寄生虫种类(疾病控制和预防中心, 2012)。诊断准确性在很大程度上取决于诊断人的专业知识,并且可能受到观察者间差异和疾病流行/资源受限区域大规模诊断所造成的不利影响(Mitiku, Mengistu 和 Gelaw, 2003)。可替代的技术是使用聚合酶链反应(PCR)和快速诊断测试(RDT);然而,PCR 分析受限于它的性能(Hommelsheim, et al., 2014),RDT 在疾病流行的地区成本效益低(Hawkes, Katsuva 和 Masumbuko, 2009)。
因此,疟疾检测可能受益于使用机器学习的自动化。
疟疾检测的深度学习
人工诊断血涂片是一个繁重的手工过程,需要专业知识来分类和计数被寄生虫感染的和未感染的细胞。这个过程可能不能很好的规模化,尤其在那些专业人士不足的地区。在利用最先进的图像处理和分析技术提取人工选取特征和构建基于机器学习的分类模型方面取得了一些进展。然而,这些模型不能大规模推广,因为没有更多的数据用来训练,并且人工选取特征需要花费很长时间。
深度学习模型,或者更具体地讲,卷积神经网络(CNN),已经被证明在各种计算机视觉任务中非常有效。(如果你想更多的了解关于 CNN 的背景知识,我推荐你阅读视觉识别的 CS2331n 卷积神经网络。)简单地讲,CNN 模型的关键层包含卷积和池化层,正如下图所示。
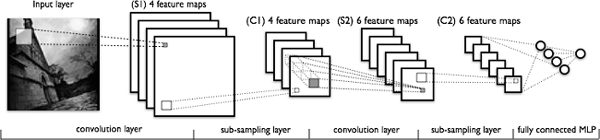
一个典型的 CNN 架构
卷积层从数据中学习空间层级模式,它是平移不变的,因此它们能够学习图像的不同方面。例如,第一个卷积层将学习小的和局部图案,例如边缘和角落,第二个卷积层将基于第一层的特征学习更大的图案,等等。这允许 CNN 自动化提取特征并且学习对于新数据点通用的有效的特征。池化层有助于下采样和减少尺寸。
因此,CNN 有助于自动化和规模化的特征工程。同样,在模型末尾加上密集层允许我们执行像图像分类这样的任务。使用像 CNN 这样的深度学习模型自动的疟疾检测可能非常有效、便宜和具有规模性,尤其是迁移学习和预训练模型效果非常好,甚至在少量数据的约束下。
Rajaraman, et al. 的论文在一个数据集上利用六个预训练模型在检测疟疾对比无感染样本获取到令人吃惊的 95.9% 的准确率。我们的重点是从头开始尝试一些简单的 CNN 模型和用一个预训练的训练模型使用迁移学习来查看我们能够从相同的数据集中得到什么。我们将使用开源工具和框架,包括 Python 和 TensorFlow,来构建我们的模型。
数据集
我们分析的数据来自 Lister Hill 国家生物医学交流中心(LHNCBC)的研究人员,该中心是国家医学图书馆(NLM)的一部分,他们细心收集和标记了公开可用的健康和受感染的血涂片图像的数据集。这些研究者已经开发了一个运行在 Android 智能手机的疟疾检测手机应用,连接到一个传统的光学显微镜。它们使用吉姆萨染液将 150 个受恶性疟原虫感染的和 50 个健康病人的薄血涂片染色,这些薄血涂片是在孟加拉的吉大港医学院附属医院收集和照相的。使用智能手机的内置相机获取每个显微镜视窗内的图像。这些图片由在泰国曼谷的马希多-牛津热带医学研究所的一个专家使用幻灯片阅读器标记的。
让我们简要地查看一下数据集的结构。首先,我将安装一些基础的依赖(基于使用的操作系统)。
Installing dependencies
我使用的是云上的带有一个 GPU 的基于 Debian 的操作系统,这样我能更快的运行我的模型。为了查看目录结构,我们必须使用 sudo apt install tree 安装 tree 及其依赖(如果我们没有安装的话)。
Installing the tree dependency
我们有两个文件夹包含血细胞的图像,包括受感染的和健康的。我们通过输入可以获取关于图像总数更多的细节:
- import os
- import glob
- base_dir = os.path.join('./cell_images')
- infected_dir = os.path.join(base_dir,'Parasitized')
- healthy_dir = os.path.join(base_dir,'Uninfected')
- infected_files = glob.glob(infected_dir+'/*.png')
- healthy_files = glob.glob(healthy_dir+'/*.png')
- len(infected_files), len(healthy_files)
- # Output
- (13779, 13779)
看起来我们有一个平衡的数据集,包含 13,779 张疟疾的和 13,779 张非疟疾的(健康的)血细胞图像。让我们根据这些构建数据帧,我们将用这些数据帧来构建我们的数据集。
- import numpy as np
- import pandas as pd
- np.random.seed(42)
- files_df = pd.DataFrame({
- 'filename': infected_files + healthy_files,
- 'label': ['malaria'] * len(infected_files) + ['healthy'] * len(healthy_files)
- }).sample(frac=1, random_state=42).reset_index(drop=True)
- files_df.head()

Datasets
构建和了解图像数据集
为了构建深度学习模型,我们需要训练数据,但是我们还需要使用不可见的数据测试模型的性能。相应的,我们将使用 60:10:30 的比例来划分用于训练、验证和测试的数据集。我们将在训练期间应用训练和验证数据集,并用测试数据集来检查模型的性能。
- from sklearn.model_selection import train_test_split
- from collections import Counter
- train_files, test_files, train_labels, test_labels = train_test_split(files_df['filename'].values,
- files_df['label'].values,
- test_size=0.3, random_state=42)
- train_files, val_files, train_labels, val_labels = train_test_split(train_files,
- train_labels,
- test_size=0.1, random_state=42)
- print(train_files.shape, val_files.shape, test_files.shape)
- print('Train:', Counter(train_labels), '\nVal:', Counter(val_labels), '\nTest:', Counter(test_labels))
- # Output
- (17361,) (1929,) (8268,)
- Train: Counter({'healthy': 8734, 'malaria': 8627})
- Val: Counter({'healthy': 970, 'malaria': 959})
- Test: Counter({'malaria': 4193, 'healthy': 4075})
这些图片尺寸并不相同,因为血涂片和细胞图像是基于人、测试方法、图片方向不同而不同的。让我们总结我们的训练数据集的统计信息来决定最佳的图像尺寸(牢记,我们根本不会碰测试数据集)。
- import cv2
- from concurrent import futures
- import threading
- def get_img_shape_parallel(idx, img, total_imgs):
- if idx % 5000 == 0 or idx == (total_imgs - 1):
- print('{}: working on img num: {}'.format(threading.current_thread().name,
- idx))
- return cv2.imread(img).shape
- ex = futures.ThreadPoolExecutor(max_workers=None)
- data_inp = [(idx, img, len(train_files)) for idx, img in enumerate(train_files)]
- print('Starting Img shape computation:')
- train_img_dims_map = ex.map(get_img_shape_parallel,
- [record[0] for record in data_inp],
- [record[1] for record in data_inp],
- [record[2] for record in data_inp])
- train_img_dims = list(train_img_dims_map)
- print('Min Dimensions:', np.min(train_img_dims, axis=0))
- print('Avg Dimensions:', np.mean(train_img_dims, axis=0))
- print('Median Dimensions:', np.median(train_img_dims, axis=0))
- print('Max Dimensions:', np.max(train_img_dims, axis=0))
- # Output
- Starting Img shape computation:
- ThreadPoolExecutor-0_0: working on img num: 0
- ThreadPoolExecutor-0_17: working on img num: 5000
- ThreadPoolExecutor-0_15: working on img num: 10000
- ThreadPoolExecutor-0_1: working on img num: 15000
- ThreadPoolExecutor-0_7: working on img num: 17360
- Min Dimensions: [46 46 3]
- Avg Dimensions: [132.77311215 132.45757733 3.]
- Median Dimensions: [130. 130. 3.]
- Max Dimensions: [385 394 3]
我们应用并行处理来加速图像读取,并且基于汇总统计结果,我们将每幅图片的尺寸重新调整到 125x125 像素。让我们载入我们所有的图像并重新调整它们为这些固定尺寸。
- IMG_DIMS = (125, 125)
- def get_img_data_parallel(idx, img, total_imgs):
- if idx % 5000 == 0 or idx == (total_imgs - 1):
- print('{}: working on img num: {}'.format(threading.current_thread().name,
- idx))
- img = cv2.imread(img)
- img = cv2.resize(img, dsize=IMG_DIMS,
- interpolation=cv2.INTER_CUBIC)
- img = np.array(img, dtype=np.float32)
- return img
- ex = futures.ThreadPoolExecutor(max_workers=None)
- train_data_inp = [(idx, img, len(train_files)) for idx, img in enumerate(train_files)]
- val_data_inp = [(idx, img, len(val_files)) for idx, img in enumerate(val_files)]
- test_data_inp = [(idx, img, len(test_files)) for idx, img in enumerate(test_files)]
- print('Loading Train Images:')
- train_data_map = ex.map(get_img_data_parallel,
- [record[0] for record in train_data_inp],
- [record[1] for record in train_data_inp],
- [record[2] for record in train_data_inp])
- train_data = np.array(list(train_data_map))
- print('\nLoading Validation Images:')
- val_data_map = ex.map(get_img_data_parallel,
- [record[0] for record in val_data_inp],
- [record[1] for record in val_data_inp],
- [record[2] for record in val_data_inp])
- val_data = np.array(list(val_data_map))
- print('\nLoading Test Images:')
- test_data_map = ex.map(get_img_data_parallel,
- [record[0] for record in test_data_inp],
- [record[1] for record in test_data_inp],
- [record[2] for record in test_data_inp])
- test_data = np.array(list(test_data_map))
- train_data.shape, val_data.shape, test_data.shape
- # Output
- Loading Train Images:
- ThreadPoolExecutor-1_0: working on img num: 0
- ThreadPoolExecutor-1_12: working on img num: 5000
- ThreadPoolExecutor-1_6: working on img num: 10000
- ThreadPoolExecutor-1_10: working on img num: 15000
- ThreadPoolExecutor-1_3: working on img num: 17360
- Loading Validation Images:
- ThreadPoolExecutor-1_13: working on img num: 0
- ThreadPoolExecutor-1_18: working on img num: 1928
- Loading Test Images:
- ThreadPoolExecutor-1_5: working on img num: 0
- ThreadPoolExecutor-1_19: working on img num: 5000
- ThreadPoolExecutor-1_8: working on img num: 8267
- ((17361, 125, 125, 3), (1929, 125, 125, 3), (8268, 125, 125, 3))
我们再次应用并行处理来加速有关图像载入和重新调整大小的计算。最终,我们获得了所需尺寸的图片张量,正如前面的输出所示。我们现在查看一些血细胞图像样本,以对我们的数据有个印象。
- import matplotlib.pyplot as plt
- %matplotlib inline
- plt.figure(1 , figsize = (8 , 8))
- n = 0
- for i in range(16):
- n += 1
- r = np.random.randint(0 , train_data.shape[0] , 1)
- plt.subplot(4 , 4 , n)
- plt.subplots_adjust(hspace = 0.5 , wspace = 0.5)
- plt.imshow(train_data[r[0]]/255.)
- plt.title('{}'.format(train_labels[r[0]]))
- plt.xticks([]) , plt.yticks([])
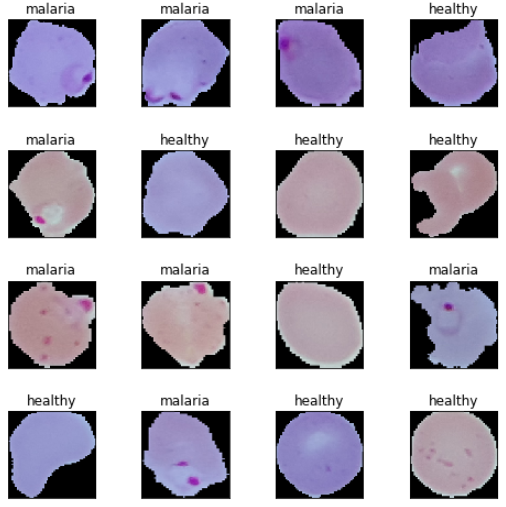
Malaria cell samples
基于这些样本图像,我们看到一些疟疾和健康细胞图像的细微不同。我们将使我们的深度学习模型试图在模型训练中学习这些模式。
开始我们的模型训练前,我们必须建立一些基础的配置设置。
- BATCH_SIZE = 64
- NUM_CLASSES = 2
- EPOCHS = 25
- INPUT_SHAPE = (125, 125, 3)
- train_imgs_scaled = train_data / 255.
- val_imgs_scaled = val_data / 255.
- # encode text category labels
- from sklearn.preprocessing import LabelEncoder
- le = LabelEncoder()
- le.fit(train_labels)
- train_labels_enc = le.transform(train_labels)
- val_labels_enc = le.transform(val_labels)
- print(train_labels[:6], train_labels_enc[:6])
- # Output
- ['malaria' 'malaria' 'malaria' 'healthy' 'healthy' 'malaria'] [1 1 1 0 0 1]
我们修复我们的图像尺寸、批量大小,和纪元,并编码我们的分类的类标签。TensorFlow 2.0 于 2019 年三月发布,这个练习是尝试它的完美理由。
- import tensorflow as tf
- # Load the TensorBoard notebook extension (optional)
- %load_ext tensorboard.notebook
- tf.random.set_seed(42)
- tf.__version__
- # Output
- '2.0.0-alpha0'
深度学习训练
在模型训练阶段,我们将构建三个深度训练模型,使用我们的训练集训练,使用验证数据比较它们的性能。然后,我们保存这些模型并在之后的模型评估阶段使用它们。
模型 1:从头开始的 CNN
我们的第一个疟疾检测模型将从头开始构建和训练一个基础的 CNN。首先,让我们定义我们的模型架构,
- inp = tf.keras.layers.Input(shape=INPUT_SHAPE)
- conv1 = tf.keras.layers.Conv2D(32, kernel_size=(3, 3),
- activation='relu', padding='same')(inp)
- pool1 = tf.keras.layers.MaxPooling2D(pool_size=(2, 2))(conv1)
- conv2 = tf.keras.layers.Conv2D(64, kernel_size=(3, 3),
- activation='relu', padding='same')(pool1)
- pool2 = tf.keras.layers.MaxPooling2D(pool_size=(2, 2))(conv2)
- conv3 = tf.keras.layers.Conv2D(128, kernel_size=(3, 3),
- activation='relu', padding='same')(pool2)
- pool3 = tf.keras.layers.MaxPooling2D(pool_size=(2, 2))(conv3)
- flat = tf.keras.layers.Flatten()(pool3)
- hidden1 = tf.keras.layers.Dense(512, activation='relu')(flat)
- drop1 = tf.keras.layers.Dropout(rate=0.3)(hidden1)
- hidden2 = tf.keras.layers.Dense(512, activation='relu')(drop1)
- drop2 = tf.keras.layers.Dropout(rate=0.3)(hidden2)
- out = tf.keras.layers.Dense(1, activation='sigmoid')(drop2)
- model = tf.keras.Model(inputs=inp, outputs=out)
- model.compile(optimizer='adam',
- loss='binary_crossentropy',
- metrics=['accuracy'])
- model.summary()
- # Output
- Model: "model"
- _________________________________________________________________
- Layer (type) Output Shape Param #
- =================================================================
- input_1 (InputLayer) [(None, 125, 125, 3)] 0
- _________________________________________________________________
- conv2d (Conv2D) (None, 125, 125, 32) 896
- _________________________________________________________________
- max_pooling2d (MaxPooling2D) (None, 62, 62, 32) 0
- _________________________________________________________________
- conv2d_1 (Conv2D) (None, 62, 62, 64) 18496
- _________________________________________________________________
- ...
- ...
- _________________________________________________________________
- dense_1 (Dense) (None, 512) 262656
- _________________________________________________________________
- dropout_1 (Dropout) (None, 512) 0
- _________________________________________________________________
- dense_2 (Dense) (None, 1) 513
- =================================================================
- Total params: 15,102,529
- Trainable params: 15,102,529
- Non-trainable params: 0
- _________________________________________________________________
基于这些代码的架构,我们的 CNN 模型有三个卷积和一个池化层,其后是两个致密层,以及用于正则化的失活。让我们训练我们的模型。
- import datetime
- logdir = os.path.join('/home/dipanzan_sarkar/projects/tensorboard_logs',
- datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
- tensorboard_callback = tf.keras.callbacks.TensorBoard(logdir, histogram_freq=1)
- reduce_lr = tf.keras.callbacks.ReduceLROnPlateau(monitor='val_loss', factor=0.5,
- patience=2, min_lr=0.000001)
- callbacks = [reduce_lr, tensorboard_callback]
- history = model.fit(x=train_imgs_scaled, y=train_labels_enc,
- batch_size=BATCH_SIZE,
- epochs=EPOCHS,
- validation_data=(val_imgs_scaled, val_labels_enc),
- callbacks=callbacks,
- verbose=1)
- # Output
- Train on 17361 samples, validate on 1929 samples
- Epoch 1/25
- 17361/17361 [====] - 32s 2ms/sample - loss: 0.4373 - accuracy: 0.7814 - val_loss: 0.1834 - val_accuracy: 0.9393
- Epoch 2/25
- 17361/17361 [====] - 30s 2ms/sample - loss: 0.1725 - accuracy: 0.9434 - val_loss: 0.1567 - val_accuracy: 0.9513
- ...
- ...
- Epoch 24/25
- 17361/17361 [====] - 30s 2ms/sample - loss: 0.0036 - accuracy: 0.9993 - val_loss: 0.3693 - val_accuracy: 0.9565
- Epoch 25/25
- 17361/17361 [====] - 30s 2ms/sample - loss: 0.0034 - accuracy: 0.9994 - val_loss: 0.3699 - val_accuracy: 0.9559
我们获得了 95.6% 的验证精确率,这很好,尽管我们的模型看起来有些过拟合(通过查看我们的训练精确度,是 99.9%)。通过绘制训练和验证的精度和损失曲线,我们可以清楚地看到这一点。
- f, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 4))
- t = f.suptitle('Basic CNN Performance', fontsize=12)
- f.subplots_adjust(top=0.85, wspace=0.3)
- max_epoch = len(history.history['accuracy'])+1
- epoch_list = list(range(1,max_epoch))
- ax1.plot(epoch_list, history.history['accuracy'], label='Train Accuracy')
- ax1.plot(epoch_list, history.history['val_accuracy'], label='Validation Accuracy')
- ax1.set_xticks(np.arange(1, max_epoch, 5))
- ax1.set_ylabel('Accuracy Value')
- ax1.set_xlabel('Epoch')
- ax1.set_title('Accuracy')
- l1 = ax1.legend(loc="best")
- ax2.plot(epoch_list, history.history['loss'], label='Train Loss')
- ax2.plot(epoch_list, history.history['val_loss'], label='Validation Loss')
- ax2.set_xticks(np.arange(1, max_epoch, 5))
- ax2.set_ylabel('Loss Value')
- ax2.set_xlabel('Epoch')
- ax2.set_title('Loss')
- l2 = ax2.legend(loc="best")
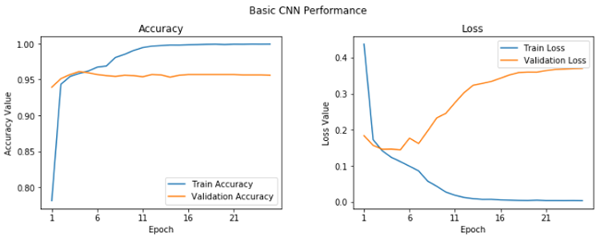
基础 CNN 学习曲线
我们可以看在在第五个纪元,情况并没有改善很多。让我们保存这个模型用于将来的评估。
- model.save('basic_cnn.h5')
深度迁移学习
就像人类有与生俱来在不同任务间传输知识的能力一样,迁移学习允许我们利用从以前任务学到的知识用到新的相关的任务,即使在机器学习或深度学习的情况下也是如此。如果想深入探究迁移学习,你应该看我的文章“一个易于理解与现实应用一起学习深度学习中的迁移学习的指导实践”和我的书《Python 迁移学习实践》。
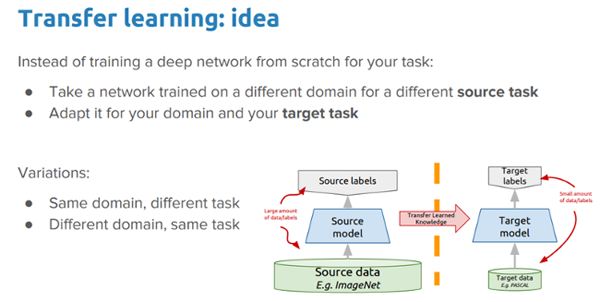
深度迁移学习的想法
在这篇实践中我们想要探索的想法是:
在我们的问题背景下,我们能够利用一个预训练深度学习模型(在大数据集上训练的,像 ImageNet)通过应用和迁移知识来解决疟疾检测的问题吗?
我们将应用两个最流行的深度迁移学习策略。
- 预训练模型作为特征提取器
- 微调的预训练模型
我们将使用预训练的 VGG-19 深度训练模型(由剑桥大学的视觉几何组(VGG)开发)进行我们的实验。像 VGG-19 这样的预训练模型是在一个大的数据集(Imagenet)上使用了很多不同的图像分类训练的。因此,这个模型应该已经学习到了健壮的特征层级结构,相对于你的 CNN 模型学到的特征,是空间不变的、转动不变的、平移不变的。因此,这个模型,已经从百万幅图片中学习到了一个好的特征显示,对于像疟疾检测这样的计算机视觉问题,可以作为一个好的合适新图像的特征提取器。在我们的问题中发挥迁移学习的能力之前,让我们先讨论 VGG-19 模型。
理解 VGG-19 模型
VGG-19 模型是一个构建在 ImageNet 数据库之上的 19 层(卷积和全连接的)的深度学习网络,ImageNet 数据库为了图像识别和分类的目的而开发。该模型是由 Karen Simonyan 和 Andrew Zisserman 构建的,在他们的论文“大规模图像识别的非常深的卷积网络”中进行了描述。VGG-19 的架构模型是:

VGG-19 模型架构
你可以看到我们总共有 16 个使用 3x3 卷积过滤器的卷积层,与最大的池化层来下采样,和由 4096 个单元组成的两个全连接的隐藏层,每个隐藏层之后跟随一个由 1000 个单元组成的致密层,每个单元代表 ImageNet 数据库中的一个分类。我们不需要最后三层,因为我们将使用我们自己的全连接致密层来预测疟疾。我们更关心前五个块,因此我们可以利用 VGG 模型作为一个有效的特征提取器。
我们将使用模型之一作为一个简单的特征提取器,通过冻结五个卷积块的方式来确保它们的位权在每个纪元后不会更新。对于最后一个模型,我们会对 VGG 模型进行微调,我们会解冻最后两个块(第 4 和第 5)因此当我们训练我们的模型时,它们的位权在每个时期(每批数据)被更新。
模型 2:预训练的模型作为一个特征提取器
为了构建这个模型,我们将利用 TensorFlow 载入 VGG-19 模型并冻结卷积块,因此我们能够将它们用作特征提取器。我们在末尾插入我们自己的致密层来执行分类任务。
- vgg = tf.keras.applications.vgg19.VGG19(include_top=False, weights='imagenet',
- input_shape=INPUT_SHAPE)
- vgg.trainable = False
- # Freeze the layers
- for layer in vgg.layers:
- layer.trainable = False
- base_vgg = vgg
- base_out = base_vgg.output
- pool_out = tf.keras.layers.Flatten()(base_out)
- hidden1 = tf.keras.layers.Dense(512, activation='relu')(pool_out)
- drop1 = tf.keras.layers.Dropout(rate=0.3)(hidden1)
- hidden2 = tf.keras.layers.Dense(512, activation='relu')(drop1)
- drop2 = tf.keras.layers.Dropout(rate=0.3)(hidden2)
- out = tf.keras.layers.Dense(1, activation='sigmoid')(drop2)
- model = tf.keras.Model(inputs=base_vgg.input, outputs=out)
- model.compile(optimizer=tf.keras.optimizers.RMSprop(lr=1e-4),
- loss='binary_crossentropy',
- metrics=['accuracy'])
- model.summary()
- # Output
- Model: "model_1"
- _________________________________________________________________
- Layer (type) Output Shape Param #
- =================================================================
- input_2 (InputLayer) [(None, 125, 125, 3)] 0
- _________________________________________________________________
- block1_conv1 (Conv2D) (None, 125, 125, 64) 1792
- _________________________________________________________________
- block1_conv2 (Conv2D) (None, 125, 125, 64) 36928
- _________________________________________________________________
- ...
- ...
- _________________________________________________________________
- block5_pool (MaxPooling2D) (None, 3, 3, 512) 0
- _________________________________________________________________
- flatten_1 (Flatten) (None, 4608) 0
- _________________________________________________________________
- dense_3 (Dense) (None, 512) 2359808
- _________________________________________________________________
- dropout_2 (Dropout) (None, 512) 0
- _________________________________________________________________
- dense_4 (Dense) (None, 512) 262656
- _________________________________________________________________
- dropout_3 (Dropout) (None, 512) 0
- _________________________________________________________________
- dense_5 (Dense) (None, 1) 513
- =================================================================
- Total params: 22,647,361
- Trainable params: 2,622,977
- Non-trainable params: 20,024,384
- _________________________________________________________________
从整个输出可以明显看出,在我们的模型中我们有了很多层,我们将只利用 VGG-19 模型的冻结层作为特征提取器。你可以使用下列代码来验证我们的模型有多少层是实际可训练的,以及我们的网络中总共存在多少层。
- print("Total Layers:", len(model.layers))
- print("Total trainable layers:",
- sum([1 for l in model.layers if l.trainable]))
- # Output
- Total Layers: 28
- Total trainable layers: 6
我们将使用和我们之前的模型相似的配置和回调来训练我们的模型。参考我的 GitHub 仓库以获取训练模型的完整代码。我们观察下列图表,以显示模型精确度和损失曲线。
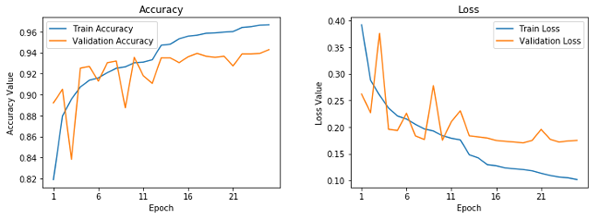
冻结的预训练的 CNN 的学习曲线
这表明我们的模型没有像我们的基础 CNN 模型那样过拟合,但是性能有点不如我们的基础的 CNN 模型。让我们保存这个模型,以备将来的评估。
- model.save('vgg_frozen.h5')
模型 3:使用图像增强来微调预训练的模型
在我们的最后一个模型中,我们将在预定义好的 VGG-19 模型的最后两个块中微调层的位权。我们同样引入了图像增强的概念。图像增强背后的想法和其名字一样。我们从训练数据集中载入现有图像,并且应用转换操作,例如旋转、裁剪、转换、放大缩小等等,来产生新的、改变过的版本。由于这些随机转换,我们每次获取到的图像不一样。我们将应用 tf.keras 中的一个名为 ImageDataGenerator 的优秀工具来帮助构建图像增强器。
- train_datagen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255,
- zoom_range=0.05,
- rotation_range=25,
- width_shift_range=0.05,
- height_shift_range=0.05,
- shear_range=0.05, horizontal_flip=True,
- fill_mode='nearest')
- val_datagen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255)
- # build image augmentation generators
- train_generator = train_datagen.flow(train_data, train_labels_enc, batch_size=BATCH_SIZE, shuffle=True)
- val_generator = val_datagen.flow(val_data, val_labels_enc, batch_size=BATCH_SIZE, shuffle=False)
我们不会对我们的验证数据集应用任何转换(除非是调整大小,因为这是必须的),因为我们将使用它评估每个纪元的模型性能。对于在传输学习环境中的图像增强的详细解释,请随时查看我上面引用的文章。让我们从一批图像增强转换中查看一些样本结果。
- img_id = 0
- sample_generator = train_datagen.flow(train_data[img_id:img_id+1], train_labels[img_id:img_id+1],
- batch_size=1)
- sample = [next(sample_generator) for i in range(0,5)]
- fig, ax = plt.subplots(1,5, figsize=(16, 6))
- print('Labels:', [item[1][0] for item in sample])
- l = [ax[i].imshow(sample[i][0][0]) for i in range(0,5)]
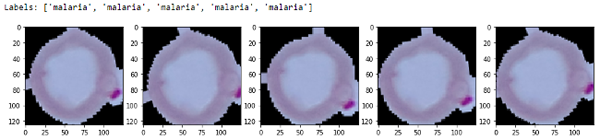
Sample augmented images
你可以清晰的看到与之前的输出的我们图像的轻微变化。我们现在构建我们的学习模型,确保 VGG-19 模型的最后两块是可以训练的。
- vgg = tf.keras.applications.vgg19.VGG19(include_top=False, weights='imagenet',
- input_shape=INPUT_SHAPE)
- # Freeze the layers
- vgg.trainable = True
- set_trainable = False
- for layer in vgg.layers:
- if layer.name in ['block5_conv1', 'block4_conv1']:
- set_trainable = True
- if set_trainable:
- layer.trainable = True
- else:
- layer.trainable = False
- base_vgg = vgg
- base_out = base_vgg.output
- pool_out = tf.keras.layers.Flatten()(base_out)
- hidden1 = tf.keras.layers.Dense(512, activation='relu')(pool_out)
- drop1 = tf.keras.layers.Dropout(rate=0.3)(hidden1)
- hidden2 = tf.keras.layers.Dense(512, activation='relu')(drop1)
- drop2 = tf.keras.layers.Dropout(rate=0.3)(hidden2)
- out = tf.keras.layers.Dense(1, activation='sigmoid')(drop2)
- model = tf.keras.Model(inputs=base_vgg.input, outputs=out)
- model.compile(optimizer=tf.keras.optimizers.RMSprop(lr=1e-5),
- loss='binary_crossentropy',
- metrics=['accuracy'])
- print("Total Layers:", len(model.layers))
- print("Total trainable layers:", sum([1 for l in model.layers if l.trainable]))
- # Output
- Total Layers: 28
- Total trainable layers: 16
在我们的模型中我们降低了学习率,因为我们不想在微调的时候对预训练的层做大的位权更新。模型的训练过程可能有轻微的不同,因为我们使用了数据生成器,因此我们将应用 fit_generator(...) 函数。
- tensorboard_callback = tf.keras.callbacks.TensorBoard(logdir, histogram_freq=1)
- reduce_lr = tf.keras.callbacks.ReduceLROnPlateau(monitor='val_loss', factor=0.5,
- patience=2, min_lr=0.000001)
- callbacks = [reduce_lr, tensorboard_callback]
- train_steps_per_epoch = train_generator.n // train_generator.batch_size
- val_steps_per_epoch = val_generator.n // val_generator.batch_size
- history = model.fit_generator(train_generator, steps_per_epoch=train_steps_per_epoch, epochs=EPOCHS,
- validation_data=val_generator, validation_steps=val_steps_per_epoch,
- verbose=1)
- # Output
- Epoch 1/25
- 271/271 [====] - 133s 489ms/step - loss: 0.2267 - accuracy: 0.9117 - val_loss: 0.1414 - val_accuracy: 0.9531
- Epoch 2/25
- 271/271 [====] - 129s 475ms/step - loss: 0.1399 - accuracy: 0.9552 - val_loss: 0.1292 - val_accuracy: 0.9589
- ...
- ...
- Epoch 24/25
- 271/271 [====] - 128s 473ms/step - loss: 0.0815 - accuracy: 0.9727 - val_loss: 0.1466 - val_accuracy: 0.9682
- Epoch 25/25
- 271/271 [====] - 128s 473ms/step - loss: 0.0792 - accuracy: 0.9729 - val_loss: 0.1127 - val_accuracy: 0.9641
这看起来是我们的最好的模型。它给了我们近乎 96.5% 的验证精确率,基于训练精度,它看起来不像我们的第一个模型那样过拟合。这可以通过下列的学习曲线验证。
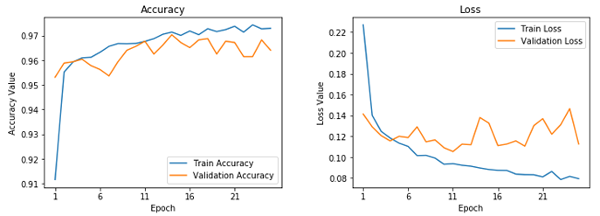
微调过的预训练 CNN 的学习曲线
让我们保存这个模型,因此我们能够在测试集上使用。
- model.save('vgg_finetuned.h5')
这就完成了我们的模型训练阶段。现在我们准备好了在测试集上测试我们模型的性能。
深度学习模型性能评估
我们将通过在我们的测试集上做预测来评估我们在训练阶段构建的三个模型,因为仅仅验证是不够的!我们同样构建了一个检测工具模块叫做 model_evaluation_utils,我们可以使用相关分类指标用来评估使用我们深度学习模型的性能。第一步是扩展我们的数据集。
- test_imgs_scaled = test_data / 255.
- test_imgs_scaled.shape, test_labels.shape
- # Output
- ((8268, 125, 125, 3), (8268,))
下一步包括载入我们保存的深度学习模型,在测试集上预测。
- # Load Saved Deep Learning Models
- basic_cnn = tf.keras.models.load_model('./basic_cnn.h5')
- vgg_frz = tf.keras.models.load_model('./vgg_frozen.h5')
- vgg_ft = tf.keras.models.load_model('./vgg_finetuned.h5')
- # Make Predictions on Test Data
- basic_cnn_preds = basic_cnn.predict(test_imgs_scaled, batch_size=512)
- vgg_frz_preds = vgg_frz.predict(test_imgs_scaled, batch_size=512)
- vgg_ft_preds = vgg_ft.predict(test_imgs_scaled, batch_size=512)
- basic_cnn_pred_labels = le.inverse_transform([1 if pred > 0.5 else 0
- for pred in basic_cnn_preds.ravel()])
- vgg_frz_pred_labels = le.inverse_transform([1 if pred > 0.5 else 0
- for pred in vgg_frz_preds.ravel()])
- vgg_ft_pred_labels = le.inverse_transform([1 if pred > 0.5 else 0
- for pred in vgg_ft_preds.ravel()])
下一步是应用我们的 model_evaluation_utils 模块根据相应分类指标来检查每个模块的性能。
- import model_evaluation_utils as meu
- import pandas as pd
- basic_cnn_metrics = meu.get_metrics(true_labels=test_labels, predicted_labels=basic_cnn_pred_labels)
- vgg_frz_metrics = meu.get_metrics(true_labels=test_labels, predicted_labels=vgg_frz_pred_labels)
- vgg_ft_metrics = meu.get_metrics(true_labels=test_labels, predicted_labels=vgg_ft_pred_labels)
- pd.DataFrame([basic_cnn_metrics, vgg_frz_metrics, vgg_ft_metrics],
- index=['Basic CNN', 'VGG-19 Frozen', 'VGG-19 Fine-tuned'])
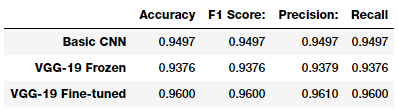
Model accuracy
看起来我们的第三个模型在我们的测试集上执行的最好,给出了一个模型精确性为 96% 的 F1 得分,这非常好,与我们之前提到的研究论文和文章中的更复杂的模型相当。
总结
疟疾检测不是一个简单的过程,全球的合格人员的不足在病例诊断和治疗当中是一个严重的问题。我们研究了一个关于疟疾的有趣的真实世界的医学影像案例。利用 AI 的、易于构建的、开源的技术在检测疟疾方面可以为我们提供最先进的精确性,因此使 AI 具有社会效益。
我鼓励你查看这篇文章中提到的文章和研究论文,没有它们,我就不能形成概念并写出来。如果你对运行和采纳这些技术感兴趣,本篇文章所有的代码都可以在我的 GitHub 仓库获得。记得从官方网站下载数据。
让我们希望在健康医疗方面更多的采纳开源的 AI 能力,使它在世界范围内变得更便宜、更易用。

时间:2019-05-26 23:41 来源:未知 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]Facebook新AI模型SEER实现自监督学习,LeCun大赞最有
- [机器学习]一文详解深度学习最常用的 10 个激活函数
- [机器学习]增量学习(Incremental Learning)小综述
- [机器学习]盘点近期大热对比学习模型:MoCo/SimCLR/BYOL/SimSi
- [机器学习]深度学习中的3个秘密:集成、知识蒸馏和蒸馏
- [机器学习]【模型压缩】深度卷积网络的剪枝和加速
- [机器学习]堪比当年的LSTM,Transformer引燃机器学习圈:它是
- [机器学习]深度学习三大谜团:集成、知识蒸馏和自蒸馏
- [机器学习]论机器学习领域的内卷:不读PhD,我配不配找工
- [机器学习]芯片自主可控深度解析
相关推荐:
网友评论:















