机器学习和深度学习中值得弄清楚的一些问题
问题1、线性回归的损失函数是凸函数的证明
假设有l个训练样本,特征向量为xi,标签值为yi,这里使用均方误差(MSE),线性回归训练时优化的目标为:
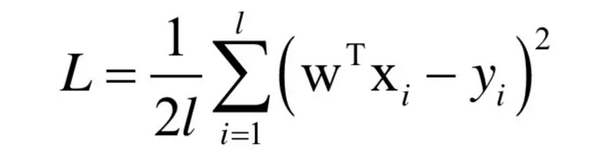
损失函数对权重向量w的一阶偏导数为:
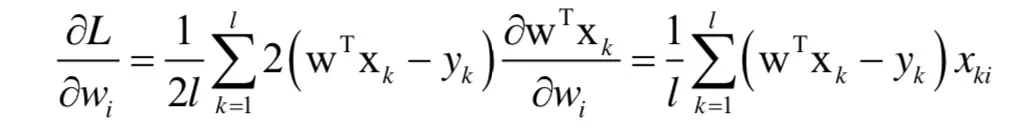
损失函数对权重向量w的二阶偏导数为:
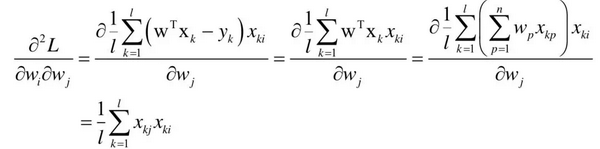
因此目标函数的Hessian矩阵为:

写成矩阵形式为:
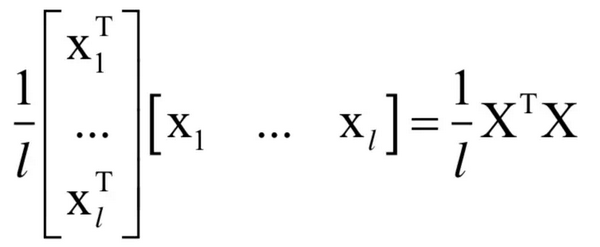
其中X是所有样本的特征向量按照列构成的矩阵。对于任意不为0的向量x,有:
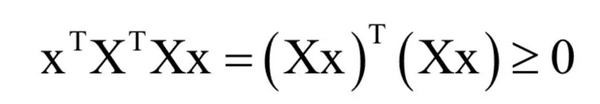
因此Hessian矩阵半正定,目标函数是凸函数。
问题2、L1和L2正则化的选定标准?
这个问题没有理论上的定论。在神经网络中我们一般选择L2正则化。以线性回归为例,使用L2正则化的岭回归和和使用L1正则化的LASSO回归都有应用。如果使用L2正则化,则正则化项的梯度值为w;如果是L1正则化,则正则化项的梯度值为sgn(w)。一般认为,L1正则化的结果更为稀疏。可以证明,两种正则化项都是凸函数。
问题3、什么时候用朴素贝叶斯,什么时候用正态贝叶斯?
一般我们都用朴素贝叶斯,因为它计算简单。除非特征向量维数不高、特征分量之间存在严重的相关性我们才用正态贝叶斯,如果特征向量是n维的,正态贝叶斯在训练时需要计算n阶矩阵的逆矩阵和行列式,这非常耗时。
问题4、可否请雷老师讲解一下discriminative classifier 和generative classifier的异同?
判别模型直接得到预测函数f(x),或者直接计算概率值p(y|x),比如SVM和logistic回归,softmax回归。SVM直接得到分类超平面的方程,logistic回归和softmax回归,以及最后一层是softmax层的神经网络,直接根据输入向量x得到它属于每一类的概率值p(y|x)。判别模型只关心决策面,而不管样本的概率分布。生成模型计算p(x, y)或者p(x|y) ,通俗来说,生成模型假设每个类的样本服从某种概率分布,对这个概率分布进行建模。

问题5、雷老师下回可以分享一下自己的学习方法吗? 机器学习的内容又多又难,涉及理论与实践,很容易碰到问题卡壳的情况。
首先要确定:卡壳在什么地方?数学公式不理解?算法的思想和原理不理解?还是算法的实现细节不清楚?
如果是数学知识欠缺,或者不能理解,需要先去补数学。如果是对机器学习算法本身使用的思想,思路不理解,则重点去推敲算法的思路。如果是觉得算法太抽象,则把算法形象化,用生动的例子来理解,或者看直观的实验结果。配合实验,实践,能更清楚的理解算法的效果,实现,细节问题。
问题6、流形学习,拉普拉斯特征映射,证明拉普拉斯矩阵半正定
假设L是图的拉普拉斯矩阵,D是加权度对角矩阵,W是邻接矩阵。对于任意不为0的向量f,有:
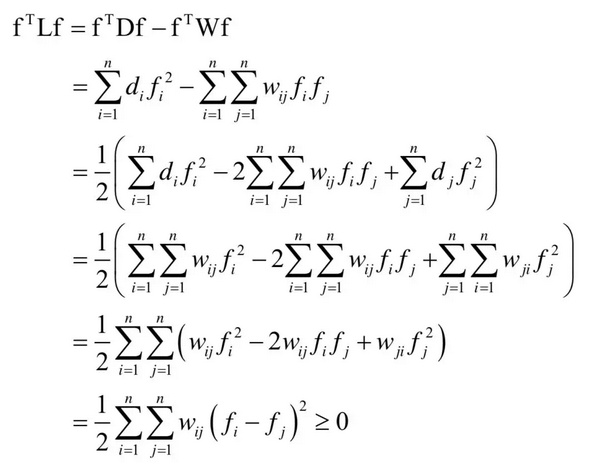
因此拉普拉斯矩阵半正定。这里矩阵D的对角线元素是矩阵W的每一行元素的和。
问题7、线性判别分析:优化目标有冗余,这个冗余怎么理解呢?
线性判别分析优化的目标函数为:
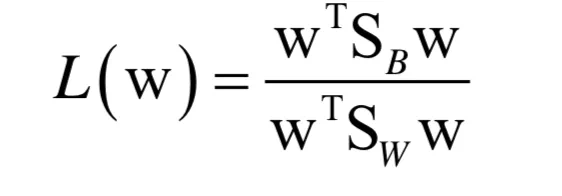
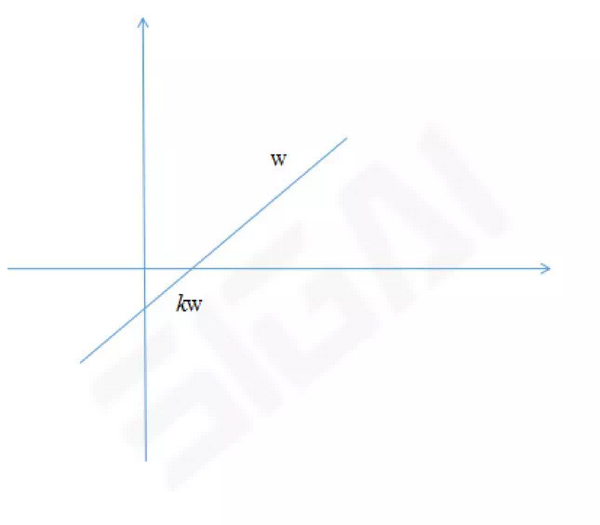
如果向量w是最优解,则将其乘以不为0的系数k之后,向量kw仍然是最优解,证明如下:
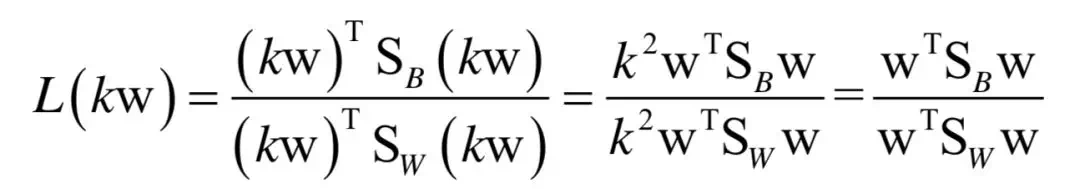
从几何上看,w可kw这两个向量表示的是一个方向,如果w是最佳投影方向,则kw还是这个方向:
问题8、决策树,如果是回归树,在寻找最佳分裂时的标准
对于回归树,寻找最佳分裂的标准是分裂之后的回归误差最小化。这等价于让分裂之前的回归误差减去分裂之后的回归误差最大化:
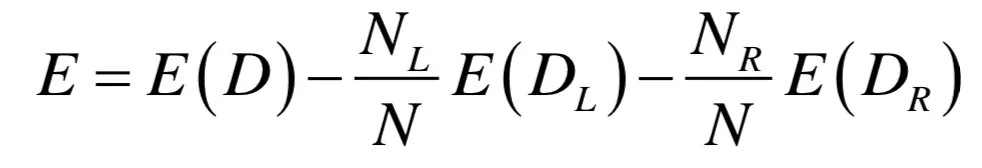
展开之后为:
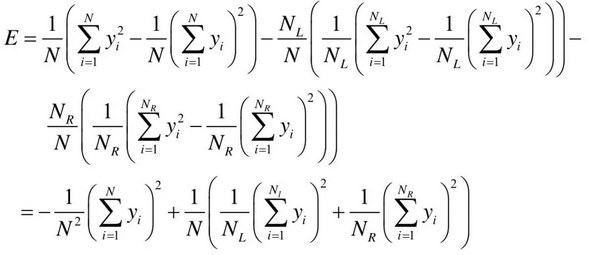
由于前面的都是常数,因此这等价于将下面的值最大化:
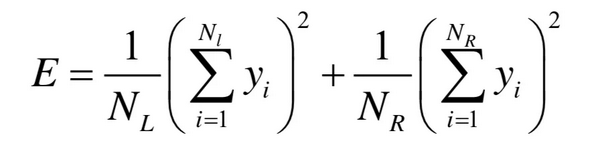
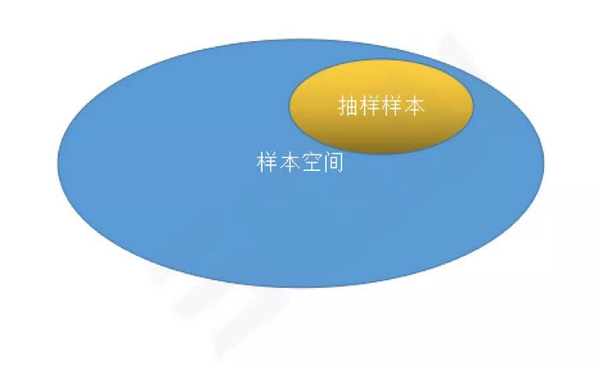
问题9、抽样误差是怎么判定的?能否消除抽样误差?
只要抽样的样本不是整个样本空间,理论上就会有抽样误差,只是是否严重而已。对于一个一般性的数据集,无法从理论上消除抽样误差。在机器学习中,我们无法得到所有可能的训练样本,只能从中抽取一部分,一般要让样本尽量有代表性、全面。
问题10、卷积神经网络中的w到底是怎么更新的,我知道利用梯度下降法和误差函数可以更新w值,但是对具体更新的过程还不是很理解。比如每次怎么调整,是一层一层调整还是整体调整,调整的结果是遵循最小化误差函数,但是过程中怎么能体现出来?
反向传播时对每一层计算出参数梯度值之后立即更新;所有层都计算出梯度值之后一起更新,这两种方式都是可以的。所有层的参数都按照梯度下降法更新完一轮,才算一次梯度下降法迭代。

问题11、对于凸优化问题的理解,我自己感觉这个很难实现,首先实际问题中有许多问题是不知道约束问题和目标函数的,不知道是不是我做的图像识别的问题,我之前对于目标函数的认识就是使用softmax的交叉损失函数,这里可能是我自己的理解不够吧,还需要老师给点提示。
所有机器学习算法的优化目标函数都是确定的,如果带有约束条件,约束条件也是确定的,不会存在不知道目标函数和约束条件的算法
问题12、如何选择机器学习算法是映射函数f(x)?
映射函数的选取没有一个严格的理论。神经网络,决策树可以拟合任意目标函数,但决策树在高维空间容易过拟合,即遇到维数灾难问题。神经网络的结构和激活函数确定之后,通过调节权重和偏置项可以得到不同的函数。决策树也是如此,不同的树结构代表不同的函数,而在训练开始的时候我们并不知道函数具体是什么样子的。其他的算法,函数都是确定的,如logistic回归,SVM,我们能调节的只有它们的参数。每类问题我们都要考虑精度,速度来选择适合它的函数。
问题13、梯度下降法的总结
1.为什么需要学习率?保证泰勒展开在x的邻域内进行,从而可以忽略高次项。
2.只要没有到达驻点,每次迭代函数值一定能下降,前提是学习率设置合理。
3.迭代终止的判定规则。达到最大迭代次数,或者梯度充分接近于0。
4.只能保证找到梯度为0的点,不能保证找到极小值点,更不能保证找到全局极小值点。
梯度下降法的改进型,本质上都只用了梯度即一阶导数信息,区别在于构造更新项的公式不同。
问题14、牛顿法的总结
1.不能保证每次迭代函数值下降。
2.不能保证收敛。
3.学习率的设定-直线搜索。
4.迭代终止的判定规则。达到最大迭代次数,或者梯度充分接近于0。
5.只能保证找到梯度为0的点,不能保证找到极小值点,更不能保证找到全局极小值点。
问题15、为什么不能用斜率截距式的方程?
无法表达斜率为正无穷的情况-垂直的直线。直线方程两边同乘以一个不为0的数,还是同一条直线。

问题16、神经网络的正则化项和动量项的比较。
正则化项的作用:缓解过拟合,迫使参数尽可能小。以L2正则化为例:
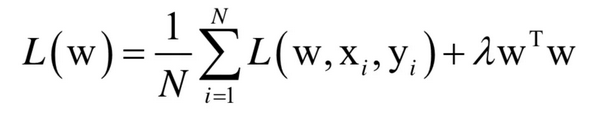
动量项的作用:加速收敛,减少震荡。计算公式为:
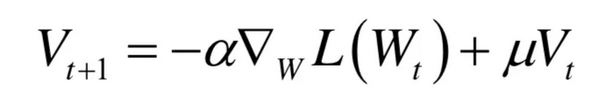

这相当于累积了之前的梯度信息,并且呈指数级衰减。实现时,先加正则化项,计算动量项。

时间:2019-05-26 00:47 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















