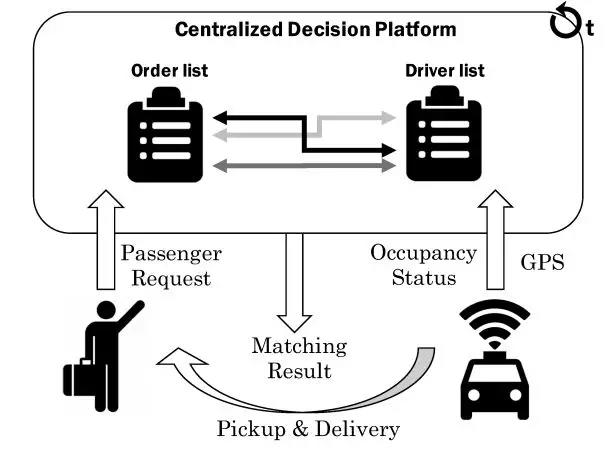
基于 “ 滴滴 KDD 2018 论文:基于强化学习技术的
文章作者:洪九 滴滴 高级算法工程师
内容来源:作者授权
出品社区:DataFun
注:欢迎转载,转载请注明出处
最近拜读了滴滴 2018 年在 KDD 发表的一篇论文《 Large-Scale Order Dispatch in On-Demand Ride-Hailing Platforms: A Learning and Planning Approach 》。意犹未尽,假如让我来设计这样一个调度系统该如何做呢?
司乘匹配一般来说,分为两步完成,第一步是为乘客找到合适的司机,第二步是将订单指派给系统认为最优的司机。那怎么样的匹配才是好的匹配呢?显而易见,好的匹配应该让所有人都满意。一个出行平台涉及乘客、司机以及平台自身三方的的利益。因此在思考分单策略之前,需要先从业务上分析他们的诉求是什么:
乘客诉求: 及时应答、接驾距离短、价格低、规划路径短。
司机诉求: 接驾距离短、减少空驶、订单价值高。
平台诉求: 最大化运力效率、单量、GMV。
理想的分单引擎应该可以同时满足上述三方的诉求,然而现实是残酷的,各方诉求其实存在着相互冲突,如此看来分单引擎必须在三者之间做好 trade-off 。平台不同发展阶段的业务目标,决定着如何在各方诉求的之间做倾斜,比如当前平台的目标是拉单量、提升 GMV 还是提升留存等等。
论文中将分单引擎的目标形式化表达成如下最优化形式:

公式 1 分单引擎最优化目标函数
其中 ,
,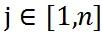 是当前时空未分配的订单。
是当前时空未分配的订单。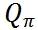 为订单 j 分配给司机 i 的价值函数。
为订单 j 分配给司机 i 的价值函数。
公式 1 的含义是在司乘 1:1 的匹配 (拼车与外卖场景为 1:N 匹配) 前提下,使得最终匹配结果的司乘匹配对 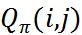 之和最大。
之和最大。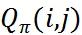 刻画了我们对司乘匹配好坏的预期,同时
刻画了我们对司乘匹配好坏的预期,同时 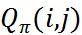 是整个分单引擎设计的核心,可以考虑接驾距离、订单价值、司机倾斜、乘客倾斜、实时供需状况等各种各样的因素,后面会对
是整个分单引擎设计的核心,可以考虑接驾距离、订单价值、司机倾斜、乘客倾斜、实时供需状况等各种各样的因素,后面会对 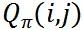 的设计思考做详细的讨论。
的设计思考做详细的讨论。
同时对于订单数量 N 和司机数量 M 的关系也需要做一下讨论。
如果 N>M : 供不应求,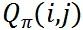 越大的订单越优先得到司机。
越大的订单越优先得到司机。
如果 N=M : 供需平衡,每个订单都会得到匹配,当然可能需要过滤极端情况。
如果 N : 供大于求,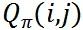 越大的司机越优先接到订单。
越大的司机越优先接到订单。
如果对一个城市的所有订单和司机按照 公式 1 的目标同时做匹配,计算量会非常大。因此为了计算的实时性,通常需要在时间和空间两个维度上对原始问题降维。根据行业最佳实践,空间可以采用六边形格子 (google S2) 对地图进行划分,单独的格子可能会有稀疏问题,因此可以对相邻的格子依据供需状况做聚类,最终作为统一的空间分片。时间上可以依据实时性要求划分成 N 秒的时间片。
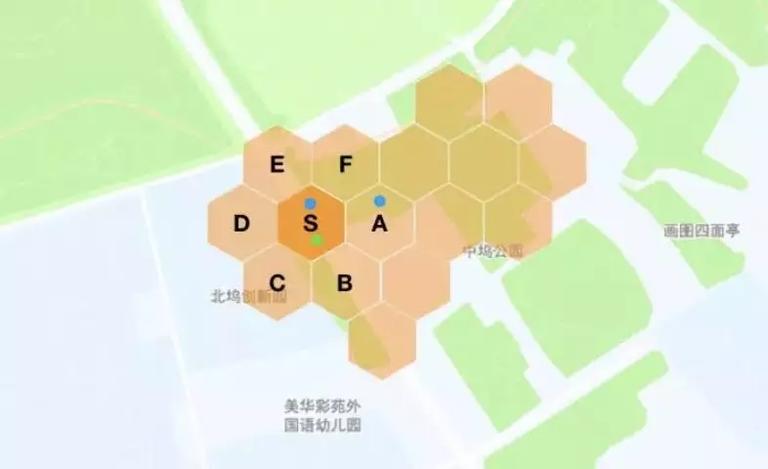
图 1 地图格子划分图
假如在某一时空有 N 个订单,M 个司机,同时  形式已知。那 公式 1 的优化目标可以抽象成如 图 2 所示的二部图。D 表示司机,O 表示乘客,OD 之间的连线代表可以将该乘客分派给司机,OD 的权重代表司乘对之间的价值
形式已知。那 公式 1 的优化目标可以抽象成如 图 2 所示的二部图。D 表示司机,O 表示乘客,OD 之间的连线代表可以将该乘客分派给司机,OD 的权重代表司乘对之间的价值  。
。
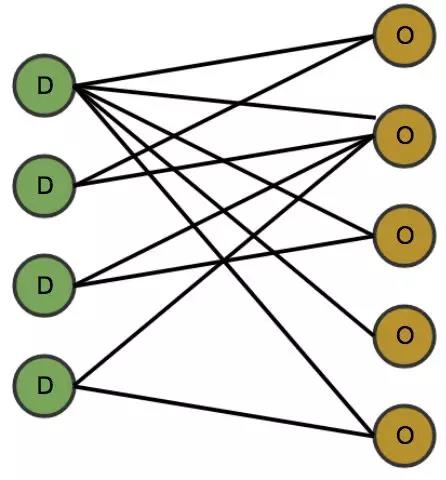
图 2 二部图示意图
在涉及到匹配的领域,比如外卖骑手订单匹配、客服工单匹配等,二部图的建模方式应该是通用解法。解这类问题通常有两种类型的算法:**1. 贪心法,2. KM 算法。** 无论那种方法,都会事先构造一张打分表格,表中元素值就是上面提到的 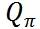 。
。
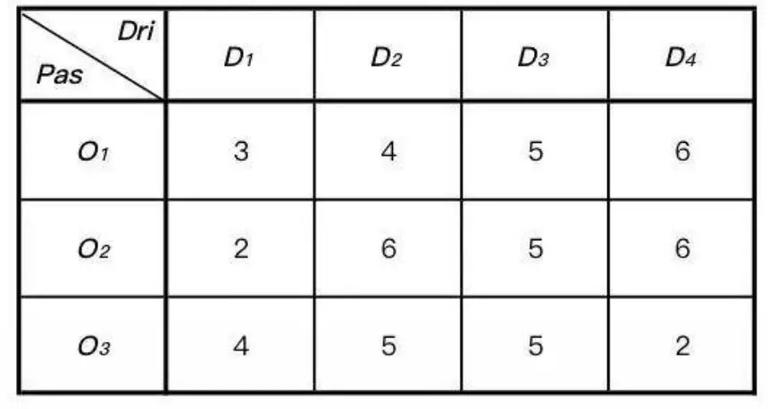
图 3 司乘匹配打分表
首先说下贪心法。** 贪心法,简而言之就是一单一单的分配。** 每次挑选  最大的司乘对分派,然后删除该司乘对,并且更新打分表 ( 在外卖场景,一个骑手可以接多单的情况下,当一对司乘分派后,其他的
最大的司乘对分派,然后删除该司乘对,并且更新打分表 ( 在外卖场景,一个骑手可以接多单的情况下,当一对司乘分派后,其他的 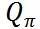 值也会收到影响 ) 。继续上面的过程,直到达到停止条件。贪心法简单、易实现、速度快,适合业务初期快速上线。但是贪心法的缺点也是显而易见的,贪心法容易陷入局部最优解,无法保证全局最优。
值也会收到影响 ) 。继续上面的过程,直到达到停止条件。贪心法简单、易实现、速度快,适合业务初期快速上线。但是贪心法的缺点也是显而易见的,贪心法容易陷入局部最优解,无法保证全局最优。
接着介绍的就是专门用于解决二部图完美匹配的 KM ( Kuhn-Munkres) 算法。KM 用于解决带权二部图最优匹配问题,与这里的场景正好 Match 。这里借用网上一个相亲的例子简单介绍下 KM 算法。
问题定义: 话说有 N 男 N 女,男生和女生每两个人之间有好感度,希望把他们两两配对,并且最后希望好感度之和最大。
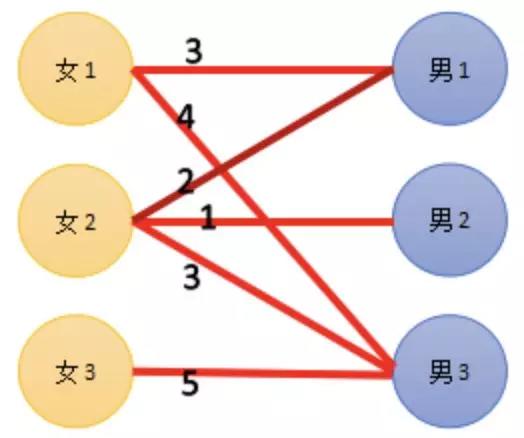
图 4 KM 算法示例图
图中红线表示女生对男生的好感度。在这个男多女少的年代,男生的期望为零,反正只要是女的就行。一个女生可能同时对多个男生有好感,但是喜欢的程度不同,这就是传说中的备胎吧!一个男生也可能同时被多个女生喜欢,男 2 好惨! 不出意外男 3 应该是男神!唉,各位好友不要千万不要自行代入,我不希望大家含着泪读完本文,写到这里是本人泪以沾襟。我是含着泪写完本文的呀!
首先把每个女生的期望度标一下,女生的期望度就是有好感度的男生中好感度最高的值。这也很好理解,比如一个女生喜欢宋仲基,那她大概率也会找宋仲基那样的。
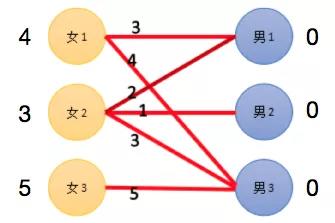
图 5 KM 算法示例图
第一轮匹配:
女 1:首先选择男 3。每个女生当然会先选自己最喜欢的,不然这个世界上怎么会存在备胎这种物种。
女 2:首先也会选男 3,但男 3 已经名草有主,女 2 失望离开。同时也不肯降低自己的要求 ( 考虑人家一下吗?_ ) 。所以本轮匹配宣告失败。
怎么办呢?让女 1 和女 2 打一架。NO,我们是和谐社会。
那就让女 1 和女 2 都降低一下期望吧,没有宋仲基,宋仲猫,宋仲猴之类的也阔以的。那降多少是可行的呢? 总不能一下子从宋仲基降成宋小宝吧,这落差也太大了。两个女生都在能选择的其他男生中,也就是男 1 男 2 中,选择一个期望值降低的尽可能小的人,就是给别人一点点机会喽。比如,女 1 选男 1,期望值要降低 1,女 2 选择男 1 期望值要降低 1。女 2 选择男 2,期望值要降低 2。那就都降低 1 好了。
同时男 3 发现自己被这么多女生喜欢,竟然飘了,居然也有期望了,女生降多少我就升多少。更新后的期望值如下图:
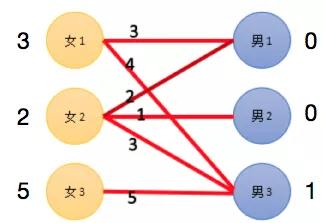
图 6 KM 算法示例图
第二轮匹配:
女 1:在第一轮中已经选择男 3。
女 2:选择男 1。
女 3:由于女 3 的选择只有男 3,而此时男 3 已经被女 1 抢走。此轮匹配宣告失败。
好吧,只能再次降低期望值了。痴情的女生,为了你的幸福,大家的期望值都要降低了,果然专一的女生最好命。
那需要怎么调整呢?参与此次分配的男生都加 1,所有女生都降 1。再次为男 2 默哀!
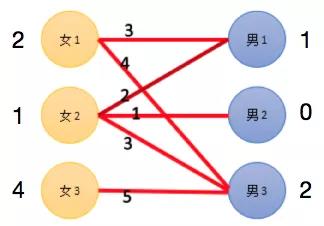
图 7 KM 算法示例图
第三轮匹配:
上一轮中的匹配结果,女 1 : 男 3,女 2 : 男 1。
女 3:选择男 3。男 3 终于被女 3 的专一打动,于是和女 1 分手,最终选择了女 3。
女 1:被分手后的女 1,开始向备胎男 1 表白心意。此时男 1 已经和女 2 在一起,但是男 1 心中依然惦记着初恋女 1,渣男本质暴露无遗,依然抛弃了女 2,重新选择了女 1。
女 2:同样是被分手的女 2,看破了红尘,选择了一直默默喜欢这自己的男 2,最终过上了幸福美满的生活。
一场爱恨情仇就此结束。当我们回顾上面的过程,整体理解一下,为什么最后的总好感度之和是最大的?在这里不想讲数学证明 (其实我不会) 。整个过程来看是一个不断妥协的过程,每个人都选择自己最喜欢的,然后一点一点降低自己的期望,直到一个可行解。就好比一个女生把她班里最帅最豪的男生从高到低排序,然后挨个去试,那最后匹配成功的那个就是在这个女生条件下最好的选择。都是为了帮大家理解,我是相信缘分的,我不是那样的人!
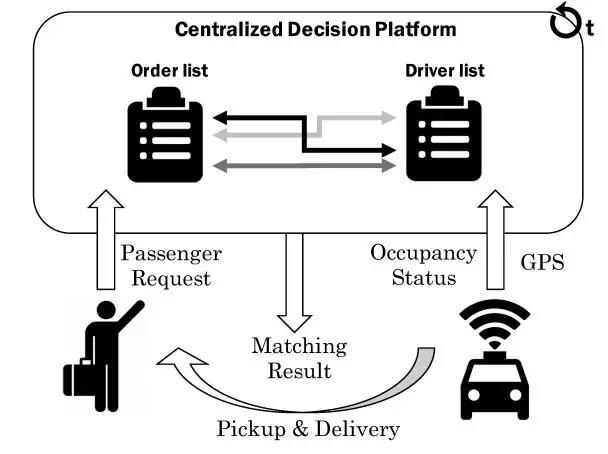
图 8 分单引擎简图
在上面介绍的基础上,不难总结出分单引擎 (如图 8) 要做的事情。在每个时空分片,从 Order List 和 Driver List 中分别取出 N 个订单和 M 个司机,用贪心法或 KM 算法求解使得公式 1 所示目标函数最大的匹配方案,该轮匹配结束后把结果推送到端上,之后再进行下一轮的匹配。当然实际系统要复杂的多,鉴于目前还没有相关 Paper,更细节的实现方案还无法得知。
其实无论在出行和外卖领域,匹配的基本算法框架就是这样。真正复杂的是价值函数 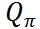 的设计。不然,公司那么多人都在干嘛呢?
的设计。不然,公司那么多人都在干嘛呢?
一个出行平台初期,处于业务试错阶段,此时要做的首要事情就是快速扩大司乘规模,通过烧钱的方式拉新引流,GMV 可能并不是平台的首要目标。运营抓手比较粗放,只要保证乘客打上车司机接到单就可以。所以,此时 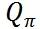 最简单的形式可以如下:
最简单的形式可以如下:
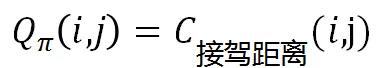
其中  为订单 i 和司机 j 之间的距离的代价函数,
为订单 i 和司机 j 之间的距离的代价函数, 为反函数。显然我们希望分单引擎的匹配结果使得司乘之间的接驾距离最小。其实这样的策略非常符合用户心智,因为用户总希望最近的司机来接自己。同时,对于平台来说此时运力效率也是比较高的,因为接驾距离小意味着空驶距离占比相对也小。
为反函数。显然我们希望分单引擎的匹配结果使得司乘之间的接驾距离最小。其实这样的策略非常符合用户心智,因为用户总希望最近的司机来接自己。同时,对于平台来说此时运力效率也是比较高的,因为接驾距离小意味着空驶距离占比相对也小。
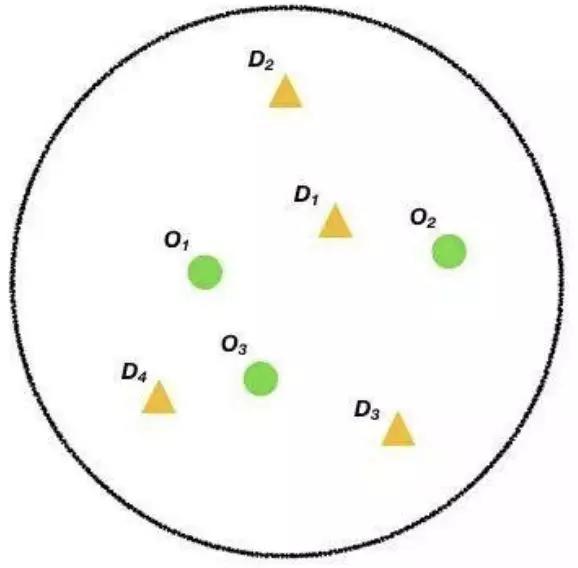
图 9 司乘分布示意图
那这种初期仅考虑司乘距离的匹配策略有什么问题呢?一方面可能会导致作弊,另一方面涉及到对订单结构的认知。这里简单以订单实际距离 (起终点路面距离) 为维度将订单拆分为长单和短单,显然长单的价值更高一些。在平台发展到一定规模后,用户已经逐渐养成打车习惯,第一道护城河基本建成,此时平台的业务目标可能会从单量规模到 GMV 规模过度。因此希望提高长单占比来提升平台的 GMV。显然开始的策略是无法对长短单做出区分的。要改进策略也很简单,继续在  上加目标项,如下:
上加目标项,如下:
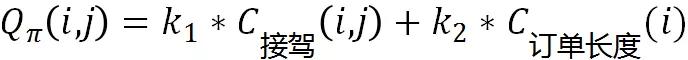
其中  为订单长度的代价函数,
为订单长度的代价函数, 与订单长度正相关。通过加权将多目标问题转换成单一目标优化问题,这样分单引擎的分配策略兼顾接驾距离和订单长度。
与订单长度正相关。通过加权将多目标问题转换成单一目标优化问题,这样分单引擎的分配策略兼顾接驾距离和订单长度。
说到这里,我们一直在关注订单的当前价值。这里对订单价值做解构,订单价值 = 当前价值 + 未来价值。如何理解未来价值呢?举个例子,在早上 9:00 某某小区,有两个订单 A 和 B 同时产生,A 订单的目的地是用友产业园,B 订单的目的地是北京南站。假设两个订单都在 9:30 左右到达目的地。请问 A 与 B 哪个订单的未来价值更高呢?
答案是 B 订单。站在司机师傅的角度来看这个问题,9:30 的用友产业园是上班高峰期,司机师傅在送达该乘客后不容易马上接另一单。相反,9:30 的北京南站,司机师傅送达乘客后可以相对容易的接到另一单。这样司机师傅的空驶率会进一步减小,提高了司机体验。同样从平台角度看提高了运力效率,对单量和 GMV 都有一定的提升作用。通过这个 Case 相信对于订单的未来价值有了概念上的认识。我们的 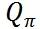 可以进一步更新成如下形式:
可以进一步更新成如下形式:
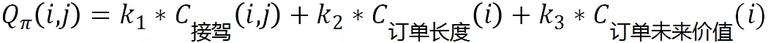
接下来的问题就是如何量化订单的未来价值  ?
?
我们暂且不考虑 Paper 中是怎么实现的,如果自己简单设计一个方案来估计订单的未来价值可以怎么做呢。订单的未来价值可以近似看成订单终点在订单结束时间片 (比如 10 分钟的时间片) 的价值。这里的价值如果理解?订单越多司机师傅越容易接上单,说明价值越高。所以,可以简单的通过历史数据统计下历史上每个格子在每个时间片的 (10 分钟粒度下每天 144 个时间片) 平均订单量不就可以了。这可能是一种简单可行的思路,不过我没有尝试过,只是为了帮助大家理解。
在 Paper 中,作者将该问题建模成一个用于解决序列决策的强化学习问题,也就是MDP ( Markov Decision Process ) 问题。一个 MDP 问题可以用四个最基本的要素描述 - 状态空间,行为空间,奖励函数和状态转移矩阵。求解 MDP 问题就是给出智能体在某种状态下应该采取哪种动作,以最大化收益。在分单问题中,每个司机看做是独立的智能体,这样会使得问题足够简单。
在分单问题中,MDP 定义如下:
** 状态空间:** 对所有时间 T (比如 10 分钟粒度) ,和所有的区域 G (六边形格子) ,进行离散化,那么时间和空间的笛卡尔积就是所有状态集 S,其中一个状态表示为 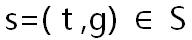 ,其中
,其中  是时间离散化的索引,
是时间离散化的索引,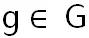 是空间离散化的索引。
是空间离散化的索引。
** 奖励函数:** 因为分单的目标是最大化 GMV,immediate reward (不知道怎么翻译) 就是该订单的价格。但是在分单问题中,一个订单的价格需要在订单完成以后才能确定,所以需要预估价格。我们对于未来的不确定性,包括预估的不确定性,这里需要一个折扣因子,即时奖励表达式如下:
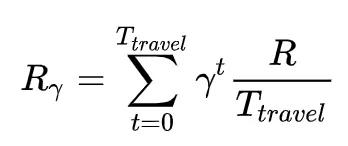
其中 R 是订单的预估价格,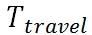 为订单的预估到达时间 (ETA),整个式子可以理解为将订单预估价格进行分段折扣。
为订单的预估到达时间 (ETA),整个式子可以理解为将订单预估价格进行分段折扣。
** 行为空间:** 分单问题中有两种行为,第一种是某个司机被分配一个订单,该司机会去一个约定的地点接乘客,并经过一段时间,到达目的地。第二种行为是,在该时间片中,该司机没有被分配任何订单,它将闲置 (idle) 一个时间片,并进入下一轮分单中。
** 状态转移:** 状态转移是伴随着行为发生的,对于 idle 司机,状态从 s=( t , g)-> s’=(t+1 , g) ,即时间片加 1,地区不变;对于分配了订单的司机,s=( t ,g)->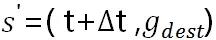 ,其中
,其中 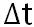 表示预估接驾时间与送达时间之和,
表示预估接驾时间与送达时间之和,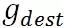 表示目标地点的索引。
表示目标地点的索引。
截一张论文中示例图解释下时空价值 V(S) 的计算。
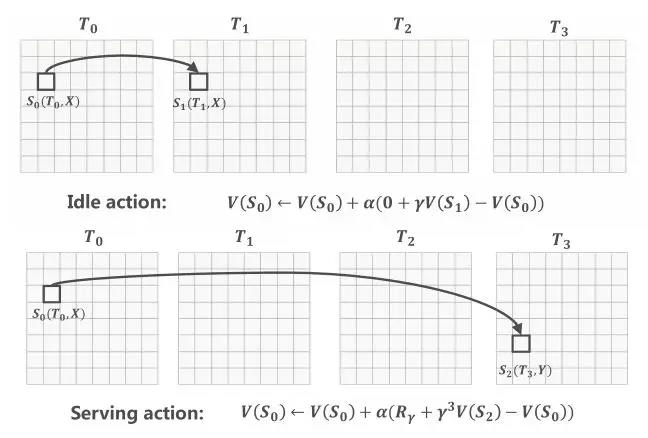
图 10 论文中价值函数计算示意图
Idle action:在空闲状态司机没有接单,因此订单收益 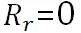 。
。
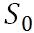 时空状态原有的价值加上
时空状态原有的价值加上 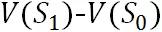 的差值等于
的差值等于 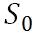 时空新的价值函数。
时空新的价值函数。
Serving action:与空闲状态不同的是,此时订单收益 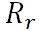 不为 0。
不为 0。
从上面的价值函数更新公式可以看出, 的更新依赖于后续
的更新依赖于后续 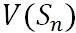 、
、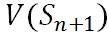 等的计算。因此价值函数的整个更新过程从后往前推的过程,本质是动态规划求解。
等的计算。因此价值函数的整个更新过程从后往前推的过程,本质是动态规划求解。
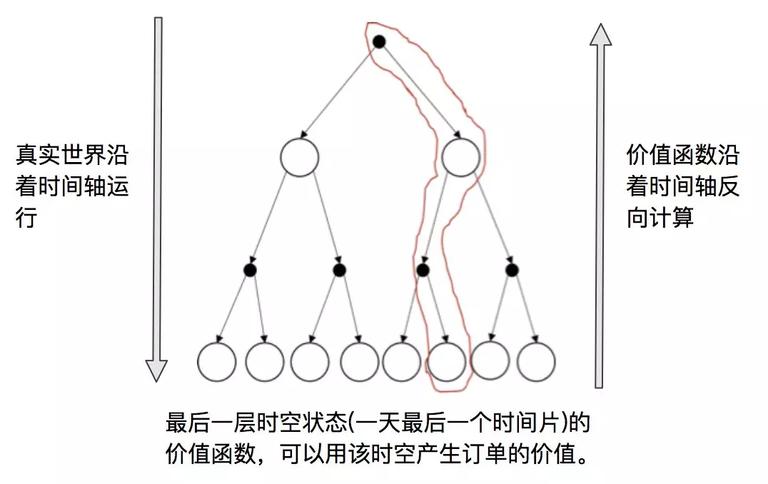
图 11 动态规划求解

图 12 价值函数求解过程
通过上面的算法求解到每个时空格子的时空价值后,可以 look-up table 的形式保存起来。线上可以根据订单结束时的时空格子查询时空价值。
说到这,我们的分单引擎还可以往哪些方向优化呢?任何交易平台做大之后,精细化运营是必不可少的一步。在电商领域,我们可以从人、货、场景三个维度考虑做精细化运营。同样在出行领域,我们也可以从乘客、司机、场景三个维度考虑。
对于司机生态,可以从司机等级、司机类型 (是否专职) 等维度对司机分层,我们希望等级越高的司机分配到更多更好的订单从而保证运力的良性发展,避免劣币驱逐良币;同时我们希望专职司机分配更多更好的订单,保证专职司机的基本收入。说到这里,专职司机是一个出行平台的支柱,而兼职司机是一个平台运力弹性的保证。在供需失衡的场景,通过奖励等运营抓手,可以调度大量的兼职司机上线,保证基本的用户体验。就好像,现役军队和预备役的关系是差不多的。
对于乘客生态,可以从乘客等级 (黑金、白金) 等维度对乘客分层,我们希望等级越高的乘客越优先获得运力,从而保证头部乘客用户的体验。通过权益分层的方式,激励用户往高价值用户转化,提高平台粘性和留存。
对于场景生态,不同打车场景对打车的需求强度是不一样的。假设我们可以区分不同的打车场景,比如上下班通勤、接送机、医院等等。举个例子,在同一时刻同一地区有两个订单 A 和 B,A 订单去往住宅区,B 订单去往某某酒店。猜测 A 订单可能是普通的下班通勤场景,B 订单可能是去会相亲或是别的什么事情,所以 B 订单的需求强度会更大一些。
与之前的思路相同,可以在目标函数中添加司机倾斜分和乘客倾斜分项来达到我们的业务目的。如下所示:
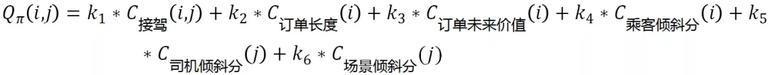
分单策略是一个不断演化的过程,只有与平台当前发展目标匹配的策略才是好的策略。同时,评价策略的好坏评价必须站在整体分布上衡量,不能保证单次出行一定是好的。
好吧,讲到这里也该接近尾声了。以上只是本人阅读 Paper 后,并结合自己对出行行业的理解 YY 的设计方案。实际情况肯定要复杂的多。希望与大家共同讨论。
参考资料:
KDD 2018: Large-Scale Order Dispatch in On-Demand Ride-Hailing Platforms: A Learning and Planning Approach
https://www.kdd.org/kdd2018/accepted-papers/view/large-scale-order-dispatch-in-on-demand-ride-sharing-platforms-a-learning-a
作者介绍:
洪九,曾任阿里巴巴高级开发工程师,现在滴滴担任高级算法工程师,喜欢钻研技术,推崇全栈工程师文化,注重业务 sense 。

时间:2019-05-25 00:15 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]人工智能十年回顾:CNN、AlphaGo、GAN……它们曾这
- [机器学习]机器学习基础图表:概念、原理、历史、趋势和算法
- [机器学习]20年以后,半数工作将被人工智能取代?这些“高危行业”有哪些
- [机器学习]人工智能十年回顾:CNN、AlphaGo、GAN……它们曾这
- [机器学习]AI 发展方向大争论:混合AI ?强化学习 ?将实际
- [机器学习]年终总结:2021年五大人工智能(AI)和机器学习(ML)发展趋势
- [机器学习]神经科学如何影响人工智能?看DeepMind在NeurIPS2
- [机器学习]美俄人工智能军事应用
- [机器学习]民调不靠谱?人工智能预测拜登获胜
- [机器学习]ResNet、Faster RCNN、Mask RCNN是专利算法吗?盘点何恺
相关推荐:
网友评论:















