人工智能时代计算机架构的趋势与挑战
1 背景简介
主持人:Chulian Zhang, compute architect@NVIDIA
20世纪70年代以来微处理器的单线程性能一直保持着指数增长。而在2010年后,由于Moore's Law和Dennard scaling几近终结,其增长速度明显放缓。
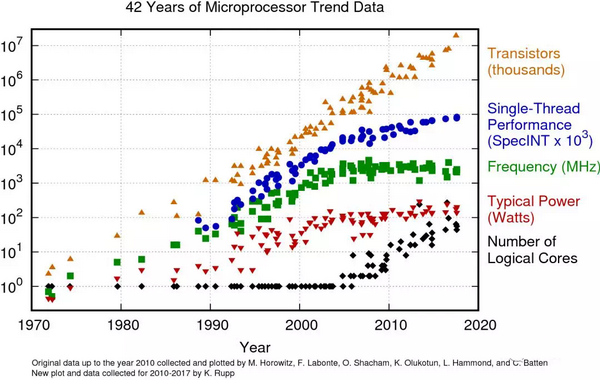
图片来源:www.karlrupp.net/2018/02/42-years-of-microprocessor-trend-data/
然而对算力的需求不仅没有减缓,反而越来越大,特别是深度学习的再次爆发更是让这种需求变得愈加紧迫。为了满足这种需求,一个有效的解决方案就是使用专用处理器。专用处理器的一个典型例子就是GPU,一种专门加速图形和并行计算的处理器。下图中可以看到在CPU 加速已经明显减缓的情况下,GPU加速的计算能力却还在快速上升。
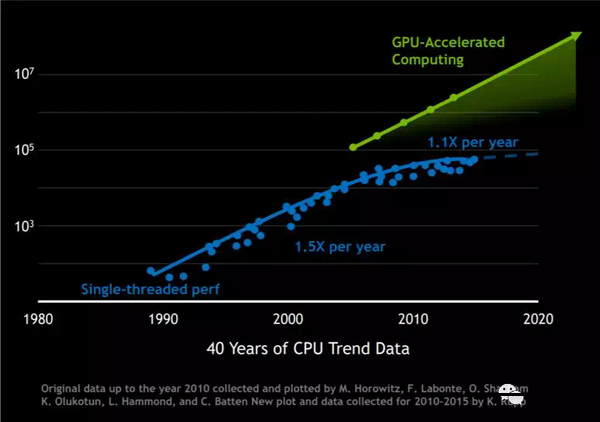
图片来源:https://www.nvidia.com/es-la/data-center/hpc/
随着深度学习日渐流行,几乎每家大公司都在打造深度学习处理器,其中Google的Tensor Processing Unit (TPU) 就是一个重要的代表。TPU的主要功能是处理神经网络,而神经网络中的大部分计算最终都归结于矩阵乘法,因此TPU的核心就是矩阵运算单元(MUX,即进行矩阵相乘计算的单元。
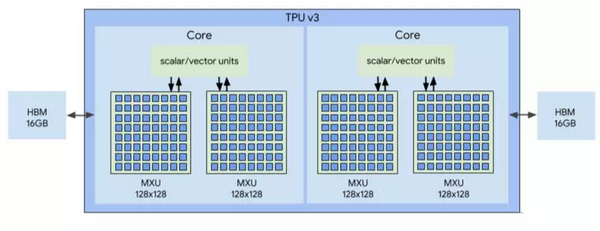
图片来源: https://cloud.google.com/tpu/docs/system-architecture
2 圆桌讨论要点
1. 机器学习应该在什么样的硬件环境下运行?是使用付费的云计算,还是只使用线下已有的专用计算和存储资源?
观点1:
TPU的主要作用是提供更多的计算能力。目前只有Google Cloud提供TPU,然而云资源非常昂贵,单是获得TPU的使用权限就要800美元,最终总费用是按小时数计算。所以计算的成本必须足够高才值得尝试在TPU上运行。
如果个人或者初创公司想要尝试,最划算的方法是购买廉价的GPU安装在自己的计算机上。对于初学者来说,可以尝试NVIDIA GTX 1060或RTX 2070。2070的性能更好一些,而2060或1060则更便宜。训练了一段时间之后,可以再看看其他选择。如果需要更强的计算能力,可以使用AWS或者Google Cloud。比如在我使用云的时候,通常一半的模型训练在本地运行,其余的在云上运行。
观点2:
我们还可以利用Google Colab(类似Python Jupyter Notebook)进行模型训练,通过浏览器访问免费的TPU资源和NVIDIA T4GPU。Colab的问题在于,如果你用的是自己的数据集,那么每次使用前都需要重新设置。如果把数据从网络硬盘导入Colab,再进行相同的操作,速度也会慢得多。不过对初学者来说,这是一个非常好的选择。
2. 在5G物联网时代,选择哪种设备进行边缘计算更合适:GPU、FPGA还是ASIC?
观点1:
目前市场上有几个解决方案。我认为在物联网设备的特定应用中采纳优化后的ASIC是一个很好的解决方案。但问题是,机器学习算法本身仍在快速发展,而GPU和FPGA可编程性的优势依然会持续。我们固然可以构建一个最优的ASIC设计,但是在流片(tape-out)的1.5年后,算法可能已经过时了。将来也许行业会趋同于使用某个特定的算法,那时候使用ASIC 就是最佳方案了。
观点2:
随着算法的发展,ASIC也在不断演变。每半年或一年就会有新一代物联网设备出现,能够执行更先进的算法。FPGA和ASIC实际上大同小异,都只是负责执行命令。FPGA可以用来开发程序,方便灵活,但是性能不佳;而ASIC则可以针对特定目的进行优化并不断更新迭代。两者的组合现在已经成了趋势。Intel支持的芯片创业公司SiFive最近收购了一家名为Open-Silicon的公司。他们的专用ASIC具有嵌入式编程功能,如eFPGA,能够重新编译和开发更多算法。
3.深度学习加速器目前主要用于模型训练和推理这两种功能,那么这两类加速器在将来会更加分化还是逐渐趋同?
观点1:
我认为它们不会趋同,因为提高应用能效和目标优化是两个完全不同的方向,最终它们将会拆分成两个市场。但即使是这两个市场的公司,也有不同的要求。以NVIDIA为例,他们在数据中心的训练方面做得很好,甚至还包括一些数据中心推理。但是如果是纯粹推理,市场上就出现了很多竞争对手。所以我认为这两种功能很难趋同,特别是考虑到边缘应用的专用程度。我认为除了NVIDIA或Google之外,很多其他公司都可以通过打开一个非常小众的市场并深入研究来立足。
观点2:
从架构的角度来看,我认为它们有可能趋同,因为它们仍然能够解决类似的问题。但是对于给定的架构,它们可以通过不同的方法实现。
观点3:
对于推理,我们通常更关心效率。我们通常在数据中心进行训练,而在边缘设备上进行推理,因此推理的架构的设计倾向于使用更少的bits。正因如此,才会有两种不同的设计方式。
观点4:
我认为这是两个不同的市场,目标也不尽相同。对于训练,我们希望吞吐量越大越好;对于推理,我们要考虑的则是减少延迟和功耗。因此,在设计架构时,首先要考虑最终目标,然后相应地设计架构。例如,对于在数据中心中进行训练,我们并不关心单个网络的延迟,只关心一小时内可以训练多少个网络。对于在边缘设备上进行推断,我们关心的是运行单个网络的延迟以及功耗。这样一来,我认为趋同的可能性不大。
4. Google近期开发了哪些加速器?
观点:
在TensorFlow的生态系统中,Google有许多加速器,如TPU和Edge TPU,还有许多非开源的内部开发项目。
除了硬件之外,Google最近发布了一个名为MLIR(multi-level intermediate representation)的开源项目。TensorFlow的图形结构使其并不能非常有效的构建连接不同后端的编译器,所以MLIR被用作中间语言,成为连接SLA (Specialized learning accelerator),TPU和不同后端的桥梁。
MLIR的快速开发过程得益于Chris Laettner的全力推动,他2017年加盟Google,是LLVM(编译器的框架系统)和Swift编程语言的设计者。(完)

时间:2019-05-15 23:41 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]人工智能十年回顾:CNN、AlphaGo、GAN……它们曾这
- [机器学习]20年以后,半数工作将被人工智能取代?这些“高危行业”有哪些
- [机器学习]人工智能十年回顾:CNN、AlphaGo、GAN……它们曾这
- [机器学习]年终总结:2021年五大人工智能(AI)和机器学习(ML)发展趋势
- [机器学习]神经科学如何影响人工智能?看DeepMind在NeurIPS2
- [机器学习]美俄人工智能军事应用
- [机器学习]民调不靠谱?人工智能预测拜登获胜
- [机器学习]人工智能正在误导我们的广告,是时候纠正这些错误了
- [机器学习]美国陆军研究如何组建人-人工智能系统团队
- [机器学习]人工智能的下一个拐点:图神经网络迎来快速爆发期
相关推荐:
网友评论:















