这是一份数据量达41.7万开源表格数据集
近年来,自然语言处理(NLP,Natural Language Processing)技术的快速发展大力推动了人工智能的整体进展。尤其是在过去三年,机器学习给NLP所带来的进步,使计算机在机器翻译、阅读理解、语法检查等任务上,都达到了可以媲美人类的水平。
不过相比现实世界中的实际应用环境,研究中的NLP任务相对单纯。事实上,在NLP已经取得很多突破的今天,机器却连企业文档中最常见的Word、PDF也无法从头“读”到尾。如何能够让机器理解文档中的标题、段落、脚注、图片、表格等内容信息,是NLP能够处理更多实际应用场景的第一步。
最近,微软亚洲研究院自然语言计算组发表了一篇论文——TableBank: Table Benchmark for Image-based Table Detection and Recognition,致力于解决文档中的表格检测与表格信息识别,并首次在业界同时开源表格检测和表格结构识别数据集,供研究人员使用。
TableBank:高质量的标注表格数据集
虽然人类在视觉上可以很容易地判断出一个表格,但由于表格的布局、样式多种多样,对于机器而言判断“何为表格”以及表格中内容之间的关系却并不容易。传统的基于规则的表格识别方式,一旦换一份文档就需要大量在文档后台的手工操作;而现有的机器学习方法,又无法获得大量有效的标注数据,很难支持实际场景中的应用。于是,TableBank应运而生。
TableBank是一个表格检测与识别的数据集,基于公开的、大规模的Word文档和LaTex文档,通过弱监督方法创建而来。与传统的弱监督训练集不同,TableBank不仅数据质量高,而且数据规模比之前的人工标记的表格分析数据集大几个数量级,其表格数据量达到了41.7万。
然而要让机器读懂表格,首先要能够从文档中识别哪些是表格,随后再去识别表格区域内的信息。因此TableBank的实现主要分两步走:一,表格检测(Table Detection);二,表格结构识别(Table Structure Recognition)。
表格检测
如何能自动检测到文档中的表格?
通常每个Word文档都有一个对应的Office XML源代码文件,在代码中对应表格的位置,可以对其进行修改,让表格加上边框,以此来区分表格与文档的其他部分。对于LaTex文档(由LaTex编辑器生成的文档),则可以直接使用特殊命令将边界框添加到表格中,以此来确定表格在文档中的位置。
然后再将Word和LaTex文档中的表格转化为相对应的PDF页面(如下图所示),便可获得带有表格信息的PDF页面,且该文档对表格的位置已经进行了标注。这些标注过的表格,都可以放到训练数据集中,并且越来越多。目前,该表格检测模型采用了计算机视觉研究中常用的Faster R-CNN 算法。

表格结构识别
表格结构识别的目的是识别表格文档中的文字信息、表格中行和列的布局信息,以及理解行与列之间的关系。从PDF或图像中识别出文字,大家的第一反应都是使用OCR(光学字符识别)技术,确实OCR技术可以识别出文字,但它只能将其转换成文本格式,再按照在图像中出现的先后顺序依次填入到可编辑的文档中,而无法确定文字之间的逻辑关系,更难于理解表格的行、列信息。
在TableBank的论文里,研究员们一方面结合OCR技术,识别出表格里每个单元格中的文本内容,另一方面,使用了创新方法去自动识别出表格在文档中的位置,以及行与列的布局,明确表格中行列交叉所形成的单元格之间的关系。
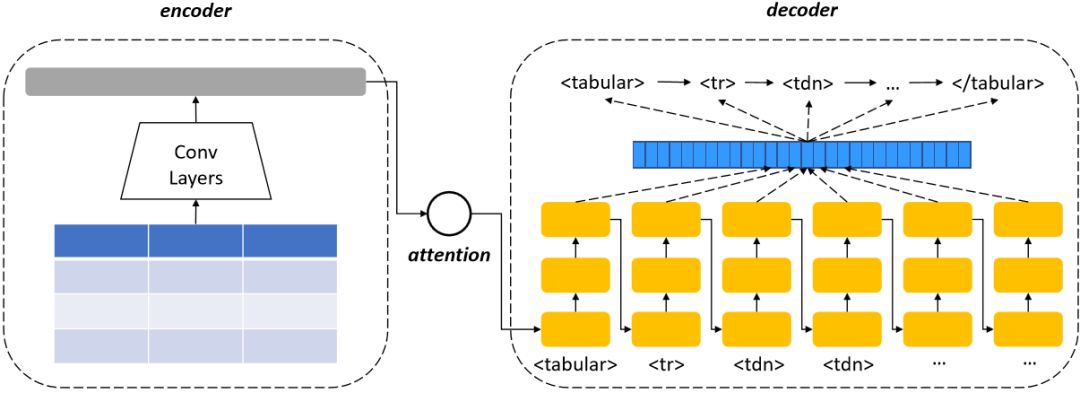
对于形式、来源不同的表格,研究员们给出了相应的方法来实现表格结构的识别。Word文档中的表格可直接将XML源代码文件转换为HTML标记序列;LaTex文档则先生成XML再转换为HTML,然后框定表格中行和列的位置。这样表格中的行、列信息也就有了标注数据。
目前,TableBank数据集已经在GitHub社区开源,其中表格检测数据有41.7万个,表格结构识别数据有14.5万个。
数据集地址:https://github.com/doc-analysis/TableBank。
表格检测与识别: 文档智能分析的第一步
高质量、大规模、带有标注的表格数据集的建立,意味着表格识别相关的机器学习训练可大规模开展,并将逐步提升表格识别的准确率。集成了计算机视觉、OCR等跨领域技术的TableBank为NLP在实际场景中的应用,做好了智能分析表格数据的前期准备。
未来,在企业文档分析中,无论是扫描件还是纸质文件中的表格识别,都可以基于TableBank训练的模型进行。同样的场景也可以延伸到由PDF转成Word的文档中的表格转换,企业年报、员工报销发票中的表格信息提取等等。
当然,表格只是各类文档中的一小部分,表格检测与识别是NLP在文档分析研究领域的第一步,文档中的标题、段落、脚注、图片等其他非结构化数据的检测与识别,也是微软亚洲研究院自然语言计算组的研究范畴。要想真正实现对文档里的内容的智能分析和理解,还有很多研究课题亟待解决。

时间:2019-05-06 22:49 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















