机器学习 | 关于聚类算法,你知道多少?
本文笔者将对聚类算法的基本概念以及常见的几类基本的聚类算法的运作逻辑以及思路,还有优缺点进行分析。

基本概念
1. 定义
聚类就是对大量未知标注的数据集,按照数据内部存在的数据特征将数据集划分为多个不同的类别,使类别内的数据比较相似。类别之间的数据相似度比较小,属于无监督学习。
聚类算法的重点是计算样本项之间的相似度,有时候也称为样本间的距离。
2. 相似度
距离计算公式:
闵可夫斯基距离(Minkowski):
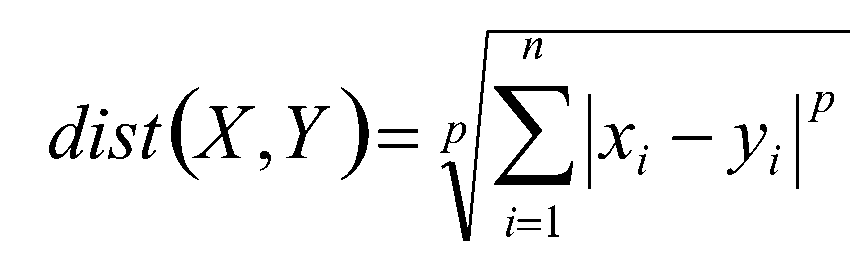
当p为1的时候是曼哈顿距离(Manhattan):
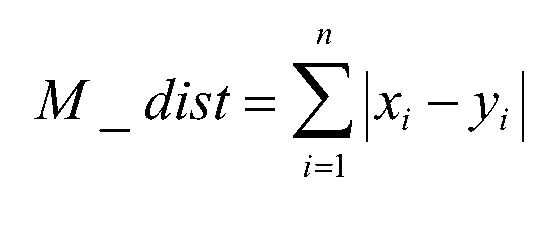
当p为2的时候是欧式距离(Euclidean):
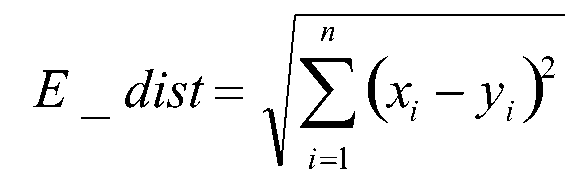

当p为无穷大的时候是切比雪夫距离(Chebyshev):
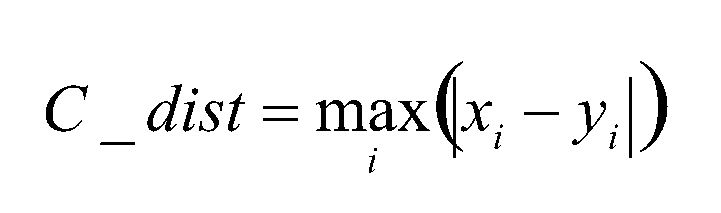
夹角余弦相似度(Cosine):
余弦相似度用向量空间中两个向量夹角的余弦值,作为衡量两个个体间差异的大小。相比距离度量,余弦相似度更加注重两个向量在方向上的差异,而非距离或长度上。
假设两个向量a,b:
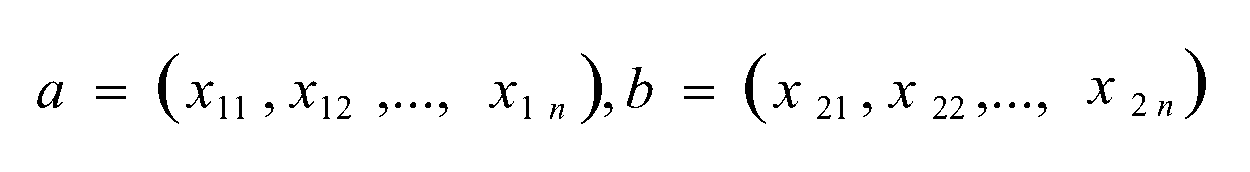





杰卡德相似系数(Jaccard):
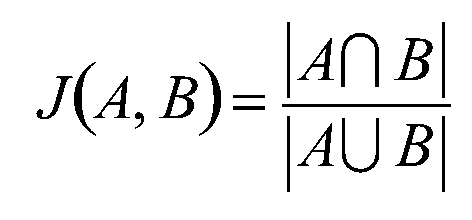

Pearson相关系数:
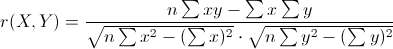
3. 与分类算法的区别
相同点:
聚类算法和分类算法一样,都是用于样本的类别划分的
不同点:
分类算法是有监督的算法,也就是算法找到是特征属性x和类别属性y之间的关系,基于这样的关系,对样本数据x做类别的划分预测
聚类算法是无监督的算法,也就是说训练数据中只有特征属性x,没有类别属性y,模型是通过找x的特征信息,将数据划分为不同的类别,基于这样的划分,对于样本数据x认为和那个类别最接近来产生预测。
分类算法的效果要比聚类算法的好,如果可以的情况下,一般选择分类算法。
4. 常用的聚类算法
KMeans、GMM高斯混合聚类、LDA(主题模型,非聚类算法,但是可以用到聚类中)
5. 聚类算法应用场景
作为前期的数据处理过程的一种数据标注的方式。
基本的聚类算法
主体思想:有M个对象的数据集,构建一个具有k个簇(类别)的模型,其中k<=M。
首先给定初始划分,通过迭代改变样本和簇的隶属关系,使的每次处理后得到的划分方式比上一次的好(总的数据集之间的距离和变小了)
1. K-means
K-means是一种使用广泛的最基础的聚类算法。
1)思路
- 假设输入样本为T=X1,X2,…,Xm
- 选择初始化的k个类别中心a1,a2,…ak
- 对于每个样本Xi,计算Xi到aj的距离,并将Xi标记为里类别中心aj最近的类比j
- 更新每个类别的中心点aj,用每个类比的所有样本的均值代替
- 重复上面两步操作,直到达到某个中止条件
- 终止条件(迭代次数、最小平方误差MSE(样本到中心的距离平方和)、簇中心点变化率)
2)计算步骤
记K个簇中心分别为a1,a2,…ak;每个簇的样本数量为N1,N2,…,NK
使用平方误差作为目标函数(使用欧几里得距离),计算当前划分情况下,所有样本到所有中心的距离平方和公式如下:
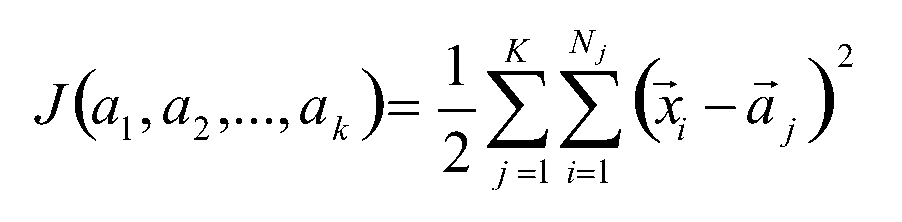
求解目标函数,我们希望的是在当前划分情况下,有一组新的a1,a2,…ak,使得MSE最小,对J进行求偏导:
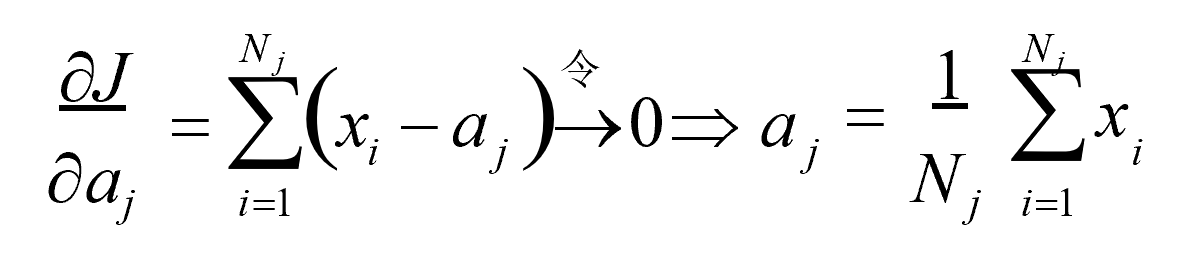
3)优缺点
缺点:
K值是用户给定的,在进行数据处理前,K值是未知的,不同的K值得到的结果也不一样;对初始簇中心点是敏感的。
不适合发现非凸形状的簇或者大小差别较大的簇特殊值(离群值)对模型的影响比较大。
优点:
理解容易,聚类效果不错处理大数据集的时候,该算法可以保证较好的伸缩性和高效率当簇近似高斯分布的时候,效果非常不错。
4)K-means存在的问题
问题:K-means算法在迭代的过程中使用所有点的均值作为新的质点(中心点),如果簇中存在异常点,将导致均值偏差比较严重。
初始解决方案:使用中位数6可能比使用均值的想法更好,使用中位数的聚类方式叫做K-Mediods聚类(K中值聚类)。
问题:K-means算法是初值敏感(K值的给定和K个初始簇中心点的选择)的,选择不同的初始值可能导致不同的簇划分规则。
初始解决方案:为了避免这种敏感性导致的最终结果异常性,可以采用初始化多套初始节点构造不同的分类规则,然后选择最优的构造规则。
2. 二分K-Means
解决K-means初值敏感问题,二分K-Means算法是一种弱化初始质心的一种算法。
1)思路
- 将所有样本数据作为一个簇放到一个队列中。
- 从队列中选择一个簇进行K-means算法划分,划分为两个子簇,并将子簇添加到队列中。
- 循环迭代第二步操作,直到中止条件达到(主要是聚簇数量)。
- 队列中的簇就是最终的分类簇集合。
2)如何选择簇进行划分
a. 对所有簇计算误差和SSE,选择SSE最大的聚簇进行划分操作:
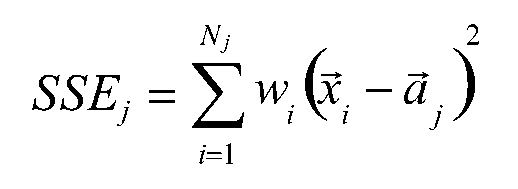
b. 选择样本数据量最多的簇进行划分操作。
3. K-Means++
也是解决K-means初值敏感问题,问题产生原因是K-means算法一个簇中间选择了两个中心点,K-Means++算法优化初始的K个中心点的方式,避免上述情况的发生。
1)思路
- 从数据集中任选一个节点作为第一个聚类中心。
- 对数据集中的每个点x,计算x到所有已有聚类中心点的距离和D(X),基于D(X)采用线性概率选择出下一个聚类中心点(距离较远的一个点成为新增的一个聚类中心点)。
- 重复步骤2直到找到k个聚类中心点。
2)缺点
第k个聚类中心点的选择依赖前k-1个聚类中心点的值,拓展性差。
4. K-Means||
解决K-Means++依赖问题,主要思路是:改变每次遍历时候的取样规则,并非按照K-Means++算法每次遍历只获取一个样本,而是每次获取K个样本,重复该取样操作O(logn)次,然后再将这些抽样出来的样本聚类出K个点。最后使用这K个点作为K-Means算法的初始聚簇中心点。实践证明:一般5次重复采用就可以保证一个比较好的聚簇中心点。
5. MiniBatchK-Means
解决K-means算法中每一次都需要计算所有样本到簇中心的距离。
1)思想
MiniBatchK-Means算法是K-Means算法的一种优化变种,采用小规模的数据子集(每次训练使用的数据集是在训练算法的时候随机抽取的数据子集)减少计算时间,同时试图优化目标函数;MiniBatchK-Means算法可以减少K-Means算法的收敛时间,而且产生的结果效果只是略差于标准K-Means算法
2)步骤
- 首先抽取部分数据集,使用K-Means算法构建出K个聚簇点的模型。
- 继续抽取训练数据集中的部分数据集样本数据,并将其添加到模型中,分配给距离最近的聚簇中心点。
- 更新聚簇的中心点值(每次更新都只用抽取出来的部分数据集)。
- 循环迭代第二步和第三步操作,直到中心点稳定或者达到迭代次数,停止计算操作。
衡量指标
混淆矩阵、均一性、完整性、V-measure、兰德系数(ARI)、互信息(AMI)、轮廓系数(Silhouette)
均一性
一个簇中只包含一个类别的样本,则满足均一性;其实也可以认为就是正确率(每个聚簇中正确分类的样本数占该聚簇总样本数的比例和)
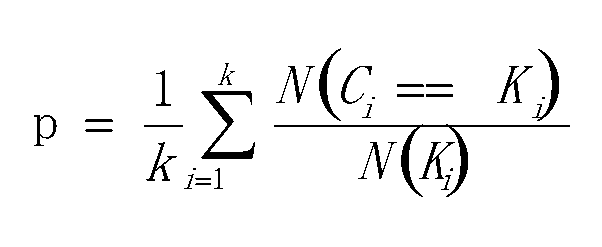
完整性
同类别样本被归类到相同簇中,则满足完整性;每个聚簇中正确分类的样本数占该类型的总样本数比例的和:
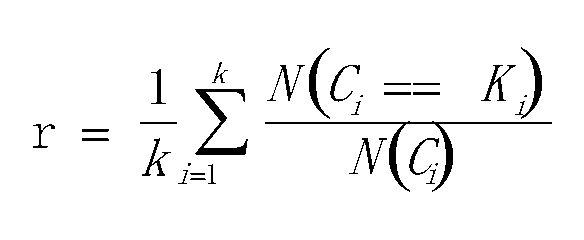
V-measure
均一性和完整性的加权平均:
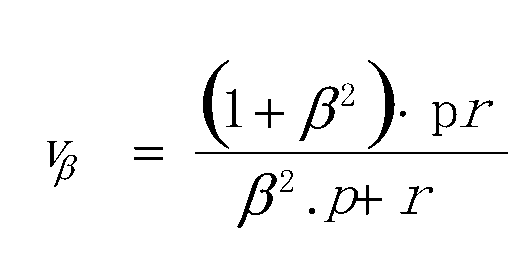
Rand index(兰德指数)(RI)

其中C表示实际类别信息,K表示聚类结果,a表示在C与K中都是同类别的元素对数。
b表示在C与K中都是不同类别的元素对数,表示数据集中可以组成的对数。
调整兰德系数(ARI,Adjusted Rnd Index)
ARI取值范围[-1,1],值越大,表示聚 类结果和真实情况越吻合。从广义的角度来将,ARI是衡量两个数据分布的吻合程度:
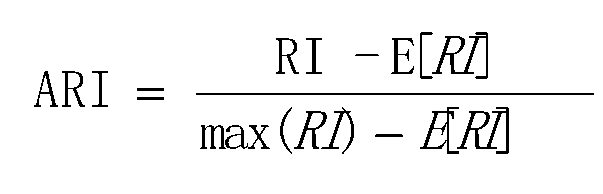

时间:2019-05-04 17:39 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















