不是码农,也能看懂的“机器学习”原理
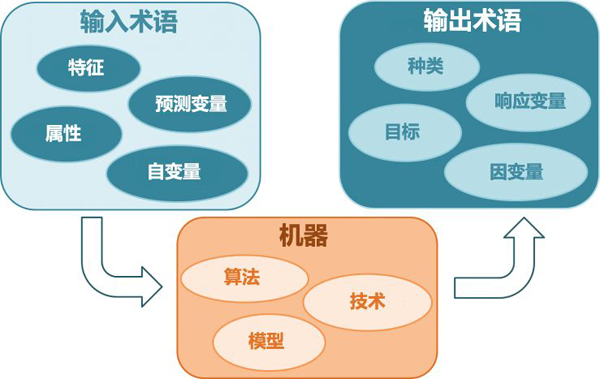
什么是机器学习?
我们先来说个老生常谈的情景:
某天你去买芒果,小贩有满满一车芒果,你一个个选好,拿给小贩称重,然后论斤付钱。
自然,你的目标是那些最甜最成熟的芒果,那怎么选呢?你想起来,外婆说过,明黄色的比淡黄色的甜。你就设了条标准:只选明黄色的芒果。于是按颜色挑好、付钱、回家。啊哈,人生完整了?
呵呵呵。告诉你吧人生就是各种麻烦
等你回到家,尝了下芒果。有些确实挺甜,有些就不行了。额~显然,外婆教的金科玉律还不够用,光看颜色不靠谱哪。
闭关研究大半天以后,你得出结论:大个的明黄色芒果必然甜,小个的,就只有一半几率会是甜的了。
于是下次,你满意地带着这个结论再去买芒果,却发现你经常光顾的那个小贩关门度假去了。好吧,换家店,结果人家的进货渠道还不一样,你这套法则不管用了,又得从头再来。好吧,这家店里每种芒果你都尝了下,总结出来小个淡黄色的最甜。
还没结束。你远房表妹又来找你玩了。但她说了,无所谓芒果甜不甜,汁水多就行。好呗,你还得再做一次实验,找到芒果越软汁水越多的规律。
接着你又移民了。一尝这边的芒果,咦,新世界的大门打开了。绿色的芒果居然比黄色的好吃……

有请码农
好了,现在想象下,这一路辛酸曲折的,你写了组程序帮忙减轻负担。那程序逻辑基本应该类似这样:
预设变量 颜色、大小、店家、硬度
如 颜色=明黄
大小=大
店家=经常光顾的小贩
则 芒果=甜
如 硬度=软
则 芒果=多汁
用着很爽吧,你甚至可以把这套玩意儿发给你小弟,他挑来的芒果也包你满意。
但每做一次新实验,你就得人肉改一次程序逻辑。而且你得首先保证自己已经理解了选芒果那套错综复杂的艺术,才能把它写进程序里。
如果要求太复杂、芒果种类太多,那光把所有挑选规则翻译成程序逻辑就够你出一身大汗,相当于读个“芒果学”博士了。
不是所有人都有“读博”的功夫的。
有请“机器学习”算法
机器学习算法其实就是普通算法的进化版。通过自动学习数据规律,让你的程序变得更聪明些。
你从市场上随机买一批芒果(训练数据),把每只芒果的物理属性列一个表格出来,比如颜色、大小、形状、产地、店家,等等(特征),对应芒果的甜度、汁水多少、成熟度,等等(输出变量)。然后把这些数据扔给机器学习算法(分类/回归),它就会自己计算出一个芒果物理属性与其品质之间的相关性模型。
等下一次你去采购时,输入店里在卖的芒果的物理属性(测试数据),机器学习算法就会根据上次计算出来的模型来预测这些芒果品质如何。机器用的算法可能跟你人肉写的逻辑规则类似(比如决策树),也有可能更先进,但反正基本上你不用多虑。
好啦,现在你可以信心满满去买芒果了,颜色大小啥的都是浮云,交给机器去操心呗。更妙的是,你的算法还会逐渐进化(强化学习):根据其预测结果的正误,算法会自行修正模型,那么随着训练数据的积累,到后来它的预测就会越来越准确。
最妙的来了,用同一个算法,你可以做好几个模型,苹果桔子香蕉葡萄各给爷来上一套。
用一句话总结机器学习就是:走自己的屌丝路,让你的算法牛逼去吧。
机器学习常见算法分类汇总
一、学习方式
根据数据类型的不同,对一个问题的建模有不同的方式。
在机器学习或者人工智能领域,人们首先会考虑算法的学习方式。
在机器学习领域,有几种主要的学习方式。将算法按照学习方式分类是一个不错的想法,这样可以让人们在建模和算法选择的时候考虑能根据输入数据来选择最合适的算法来获得最好的结果。
监督式学习:
在监督式学习下,输入数据被称为“训练数据”,每组训练数据有一个明确的标识或结果,如对防垃圾邮件系统中“垃圾邮件”“非垃圾邮件”,对手写数字识别中的“1“,”2“,”3“,”4“等。在建立预测模型的时候,监督式学习建立一个学习过程,将预测结果与“训练数据”的实际结果进行比较,不断的调整预测模型,直到模型的预测结果达到一个预期的准确率。监督式学习的常见应用场景如分类问题和回归问题。常见算法有逻辑回归(Logistic Regression)和反向传递神经网络(Back Propagation Neural Network)
非监督式学习:
在非监督式学习中,数据并不被特别标识,学习模型是为了推断出数据的一些内在结构。常见的应用场景包括关联规则的学习以及聚类等。常见算法包括Apriori算法以及k-Means算法。
半监督式学习:

在此学习方式下,输入数据部分被标识,部分没有被标识,这种学习模型可以用来进行预测,但是模型首先需要学习数据的内在结构以便合理的组织数据来进行预测。应用场景包括分类和回归,算法包括一些对常用监督式学习算法的延伸,这些算法首先试图对未标识数据进行建模,在此基础上再对标识的数据进行预测。如图论推理算法(Graph Inference)或者拉普拉斯支持向量机(Laplacian SVM.)等。
强化学习:
在这种学习模式下,输入数据作为对模型的反馈,不像监督模型那样,输入数据仅仅是作为一个检查模型对错的方式,在强化学习下,输入数据直接反馈到模型,模型必须对此立刻作出调整。常见的应用场景包括动态系统以及机器人控制等。常见算法包括Q-Learning以及时间差学习(Temporal difference learning)
在企业数据应用的场景下, 人们最常用的可能就是监督式学习和非监督式学习的模型。
在图像识别等领域,由于存在大量的非标识的数据和少量的可标识数据, 目前半监督式学习是一个很热的话题。
而强化学习更多的应用在机器人控制及其他需要进行系统控制的领域。
二、算法类似性
根据算法的功能和形式的类似性,我们可以把算法分类,比如说基于树的算法,基于神经网络的算法等等。当然,机器学习的范围非常庞大,有些算法很难明确归类到某一类。而对于有些分类来说,同一分类的算法可以针对不同类型的问题。这里,我们尽量把常用的算法按照最容易理解的方式进行分类。
回归算法:
回归算法是试图采用对误差的衡量来探索变量之间的关系的一类算法。回归算法是统计机器学习的利器。在机器学习领域,人们说起回归,有时候是指一类问题,有时候是指一类算法,这一点常常会使初学者有所困惑。常见的回归算法包括:最小二乘法(Ordinary Least Square),逻辑回归(Logistic Regression),逐步式回归(Stepwise Regression),多元自适应回归样条(Multivariate Adaptive Regression Splines)以及本地散点平滑估计(Locally Estimated Scatterplot Smoothing)
基于实例的算法
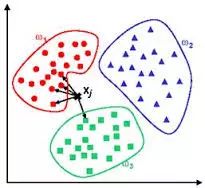
基于实例的算法常常用来对决策问题建立模型,这样的模型常常先选取一批样本数据,然后根据某些近似性把新数据与样本数据进行比较。通过这种方式来寻找最佳的匹配。因此,基于实例的算法常常也被称为“赢家通吃”学习或者“基于记忆的学习”。常见的算法包括 k-Nearest Neighbor(KNN), 学习矢量量化(Learning Vector Quantization, LVQ),以及自组织映射算法(Self-Organizing Map , SOM)
正则化方法
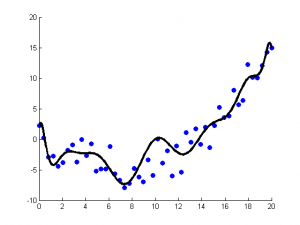
正则化方法是其他算法(通常是回归算法)的延伸,根据算法的复杂度对算法进行调整。正则化方法通常对简单模型予以奖励而对复杂算法予以惩罚。常见的算法包括:Ridge Regression, Least Absolute Shrinkage and Selection Operator(LASSO),以及弹性网络(Elastic Net)。
决策树学习
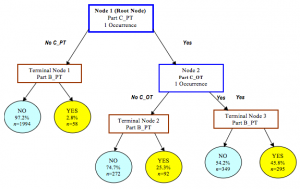
决策树算法根据数据的属性采用树状结构建立决策模型, 决策树模型常常用来解决分类和回归问题。常见的算法包括:分类及回归树(Classification And Regression Tree, CART), ID3 (Iterative Dichotomiser 3), C4.5, Chi-squared Automatic Interaction Detection(CHAID), Decision Stump, 随机森林(Random Forest), 多元自适应回归样条(MARS)以及梯度推进机(Gradient Boosting Machine, GBM)
贝叶斯方法
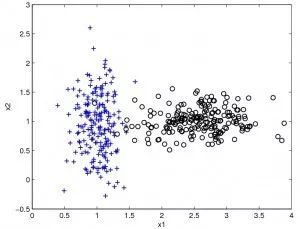
贝叶斯方法算法是基于贝叶斯定理的一类算法,主要用来解决分类和回归问题。常见算法包括:朴素贝叶斯算法,平均单依赖估计(Averaged One-Dependence Estimators, AODE),以及Bayesian Belief Network(BBN)。
基于核的算法
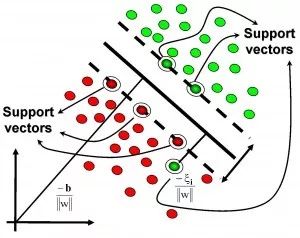
基于核的算法中最著名的莫过于支持向量机(SVM)了。 基于核的算法把输入数据映射到一个高阶的向量空间, 在这些高阶向量空间里, 有些分类或者回归问题能够更容易的解决。 常见的基于核的算法包括:支持向量机(Support Vector Machine, SVM), 径向基函数(Radial Basis Function ,RBF), 以及线性判别分析(Linear Discriminate Analysis ,LDA)等
聚类算法

聚类,就像回归一样,有时候人们描述的是一类问题,有时候描述的是一类算法。聚类算法通常按照中心点或者分层的方式对输入数据进行归并。所以的聚类算法都试图找到数据的内在结构,以便按照最大的共同点将数据进行归类。常见的聚类算法包括 k-Means算法以及期望最大化算法(Expectation Maximization, EM)。
关联规则学习
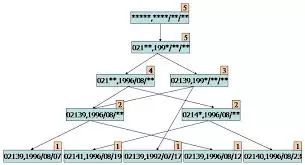
关联规则学习通过寻找最能够解释数据变量之间关系的规则,来找出大量多元数据集中有用的关联规则。常见算法包括 Apriori算法和Eclat算法等。
人工神经网络
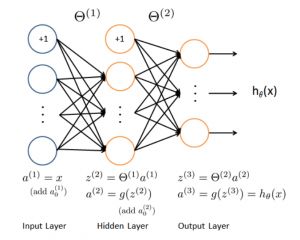
人工神经网络算法模拟生物神经网络,是一类模式匹配算法。通常用于解决分类和回归问题。人工神经网络是机器学习的一个庞大的分支,有几百种不同的算法。(其中深度学习就是其中的一类算法,我们会单独讨论),重要的人工神经网络算法包括:感知器神经网络(Perceptron Neural Network), 反向传递(Back Propagation), Hopfield网络,自组织映射(Self-Organizing Map, SOM)。学习矢量量化(Learning Vector Quantization, LVQ)
深度学习
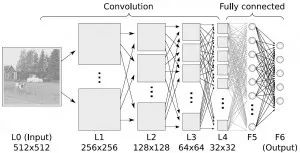
深度学习算法是对人工神经网络的发展。 在近期赢得了很多关注, 特别是百度也开始发力深度学习后, 更是在国内引起了很多关注。 在计算能力变得日益廉价的今天,深度学习试图建立大得多也复杂得多的神经网络。很多深度学习的算法是半监督式学习算法,用来处理存在少量未标识数据的大数据集。常见的深度学习算法包括:受限波尔兹曼机(Restricted Boltzmann Machine, RBN), Deep Belief Networks(DBN),卷积网络(Convolutional Network), 堆栈式自动编码器(Stacked Auto-encoders)。
降低维度算法

像聚类算法一样,降低维度算法试图分析数据的内在结构,不过降低维度算法是以非监督学习的方式试图利用较少的信息来归纳或者解释数据。这类算法可以用于高维数据的可视化或者用来简化数据以便监督式学习使用。常见的算法包括:主成份分析(Principle Component Analysis, PCA),偏最小二乘回归(Partial Least Square Regression,PLS), Sammon映射,多维尺度(Multi-Dimensional Scaling, MDS), 投影追踪(Projection Pursuit)等。
集成算法:
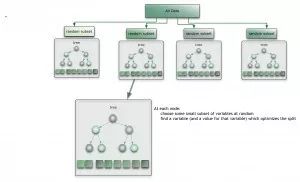
集成算法用一些相对较弱的学习模型独立地就同样的样本进行训练,然后把结果整合起来进行整体预测。集成算法的主要难点在于究竟集成哪些独立的较弱的学习模型以及如何把学习结果整合起来。这是一类非常强大的算法,同时也非常流行。常见的算法包括:Boosting, Bootstrapped Aggregation(Bagging), AdaBoost,堆叠泛化(Stacked Generalization, Blending),梯度推进机(Gradient Boosting Machine, GBM),随机森林(Random Forest)。

时间:2019-03-31 00:23 来源:未知 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]堪比当年的LSTM,Transformer引燃机器学习圈:它是
- [机器学习]论机器学习领域的内卷:不读PhD,我配不配找工
- [机器学习]机器学习基础图表:概念、原理、历史、趋势和算法
- [机器学习]分析了 600 多种烘焙配方,机器学习开发出新品
- [机器学习]2021年的机器学习生命周期
- [机器学习]物联网和机器学习促进企业业务发展的5种方式
- [机器学习]机器学习中分类任务的常用评估指标和Python代码实现
- [机器学习]机器学习和深度学习的区别是什么?
- [机器学习]堪比当年的LSTM,Transformer引燃机器学习圈:它是
- [机器学习]年终总结:2021年五大人工智能(AI)和机器学习(ML)发展趋势
相关推荐:
网友评论:















