处理机器学习中不平衡类的5种策略
类失衡:假设您有一个罕见的疾病机器学习数据集,即大约8%的阳性。在这种情况下,即使你不训练,只是简单地说没有生病,这也会给出92%的准确率。因此,在类不平衡的情况下,准确性是不准确的。
在本指南中,我们介绍了处理机器学习中不平衡类的5种策略:
- 对少数类进行上采样
- 对多数类进行下采样
- 更改性能指标
- 惩罚算法
- 使用基于树的算法
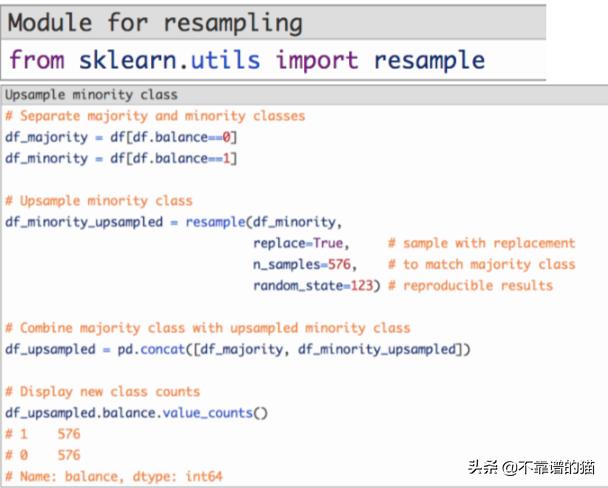
1. 上采样少数类:指随机复制少数类的观察结果,使样本数量与多数类匹配。
首先,我们将每个类的观察结果分成不同的DataFrame。
接下来,我们将使用替换重取样少数类,设置样本数以匹配多数类的样本数。
最后,我们将上采样的少数类DataFrame与原始的多数类DataFrame相结合。
创建合成样本(数据增强)
创建合成样本是上采样的近亲,有些人可能会将它们归类在一起。例如,SMOTE算法是一种从少数类中重新采样的方法,同时稍微调整特征值,从而创建“新的”样本。
2. 下采样多数类:下采样涉及从多数类中随机移除观测值,以防止其信号支配学习算法。
首先,我们将每个类的观察结果分成不同的DataFrame。
接下来,我们将重采样多数类而不进行替换,将样本数设置为与少数类相匹配。
最后,我们将下采样的多数类DataFrame与原始的少数类DataFrame结合起来。

3. 更改性能指标:AUROC(ROC曲线下面积)
假设我们有一个概率的二元分类器,如逻辑回归。
在呈现ROC曲线之前,必须理解混淆矩阵的概念。当我们进行二元预测时,可以有4种类型的结果:
- 我们预测0而真正的类实际上是0:这被称为真阴性,即我们正确地预测该类是负的(0)。例如,防病毒软件未将无害文件检测为病毒。
- 我们预测0而真正的类实际上是1:这被称为假阴性,即我们错误地预测该类是负的(0)。例如,防病毒软件无法检测到病毒。
- 我们预测1而真正的类实际上是0:这被称为假阳性,即我们错误地预测该类是正的(1)。例如,防病毒软件认为无害文件是病毒。
- 我们预测1而真正的类实际上是1:这被称为真阳性,即我们正确地预测该类是正的(1)。例如,防病毒软件正确地检测到了病毒。
为了获得混淆矩阵,我们回顾机器学习项模型所做的所有预测,并计算这4种结果中的每一种发生的次数:

在这个混淆矩阵的例子中,在被分类的50个数据点中,45个被正确分类,5个被错误分类。
由于为了比较不同的模型,通常使用单个度量比使用多个度量更方便,所以我们从混淆矩阵中计算两个度量,然后将其合并为一个:
- 真阳性率(TPR),又名灵敏度、命中率和召回率,定义为+TPTP+ FN。直观地,该度量对应于相对于所有正数据点被正确认为为正的正数据点的比例。换句话说,TPR越高,我们将错过的正数据点越少。
- 假阳性率(FPR),又名 fall-out,定义为+FPFP+ TN。直观地,该度量对应于相对于所有负数据点被错误地认为是正数的负数据点的比例。换句话说,FPR越高,更多的负数据点将被错误分类。
为了将FPR和TPR合并为一个度量,我们首先计算逻辑回归中具有许多不同阈值的前两个度量(例如0.00、0.01、0.02、……、1.000.00;0.01、0.02、……、1.00),然后将它们绘制在一个图上,横坐标上是FPR值,纵坐标上是TPR值。得到的曲线称为ROC曲线,我们考虑的度量是这条曲线的AUC,我们称之为AUROC。
下图以图形方式显示AUROC:
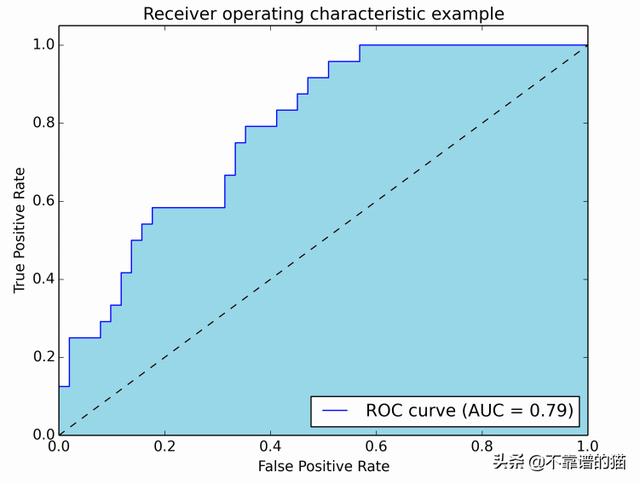
在该图中,蓝色区域对应于AUROC的曲线下面积。对角线中的虚线表示随机预测器的ROC曲线:它的AUROC为0.5。
AUROC介于0和1之间,AUROC = 1意味着预测模型是完美的。事实上,AUROC距离0.5越远越好:如果AUROC <0.5,那么你只需要反转模型所做的决定。因此,如果AUROC = 0,这是个好消息,因为您只需要反转模型的输出以获得完美的机器学习模型。
4. 惩罚算法:
下一个策略是使用惩罚学习算法,提高少数类的分类错误的成本。
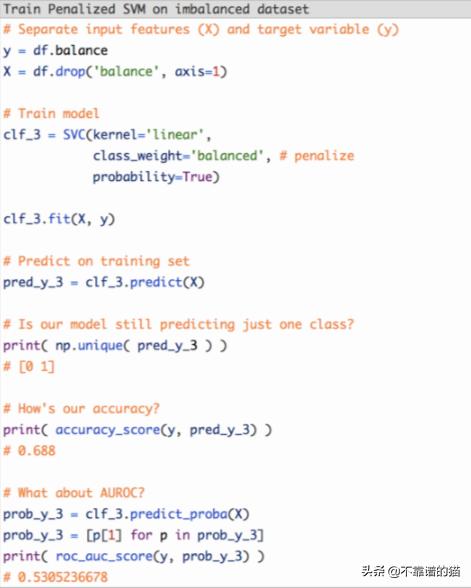
该技术的流行算法是Penalized-SVM:支持向量机
在训练期间,我们可以使用参数class_weight ='balanced'来惩罚少数群体类的错误,其数量与其代表性不足的数量成正比。
如果我们想为支持向量机算法启用概率估计,还需要包含参数probability=True。
让我们在原始不平衡数据集上使用Penalized-SVM训练模型:
5. 使用基于树的算法
我们将考虑的最后策略是使用基于树的算法。决策树通常在不平衡数据集上表现良好,因为它们的层次结构允许它们从两个类中学习信号。
在现代应用机器学习中,树集合(随机森林,梯度提升树等)几乎总是优于单一决策树:

97%的准确率和接近100%的AUROC。
树形组合已经变得非常流行,因为它们在许多现实问题上表现得非常好。
然而:虽然这些结果令人鼓舞,但机器学习模型可能过度拟合,因此在做出最终决策之前,您仍应在测试集上评估机器学习模型。

时间:2019-03-31 00:16 来源:未知 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]堪比当年的LSTM,Transformer引燃机器学习圈:它是
- [机器学习]论机器学习领域的内卷:不读PhD,我配不配找工
- [机器学习]机器学习基础图表:概念、原理、历史、趋势和算法
- [机器学习]分析了 600 多种烘焙配方,机器学习开发出新品
- [机器学习]2021年的机器学习生命周期
- [机器学习]物联网和机器学习促进企业业务发展的5种方式
- [机器学习]机器学习中分类任务的常用评估指标和Python代码实现
- [机器学习]机器学习和深度学习的区别是什么?
- [机器学习]堪比当年的LSTM,Transformer引燃机器学习圈:它是
- [机器学习]年终总结:2021年五大人工智能(AI)和机器学习(ML)发展趋势
相关推荐:
网友评论:















