知识图谱 |298 万条三元组生成方法 (一)
本篇文章接《Python 爬虫 |Get 豆瓣电影与书籍详细信息》,学习如何利用爬取的数据,构建知识图谱所需的三元组。主要内容包括如何从 Json 类型的数据,转换成 RDF 数据,并最终存储到 Jena 之中,然后利用 SPARQL 进行查询。数据链接: https://pan.baidu.com/s/1cLdsAXLGH2akJqMIsGdoig 提取码: n97y。
实践之前,请自主学习相关背景知识。
-
语义网络, 语义网, 链接数据, 知识图谱是什么。
-
RDF, RDFS, OWL, Protege, 本体构建。
-
MySQL 数据库, pymysql。
-
D2rq, Jena, fuseki, SPARQL。
1. 数据清洗
- 电影信息包括电影 id、图片链接、名称、导演名称、编剧名称、主演名称、类型、制片国家、语言、上映日期、片长、季数、其他名称、剧情简介、评分、评分人数,共67245 条数据信息。虽说是电影信息,但其中也包括电视剧、综艺、动漫、纪录片、短片。
- 电影演员信息包括演员 id、姓名、图片链接、性别、星座、出生日期、出生地、职业、更多中文名、更多外文名、家庭成员、简介,共89592 条数据信息。这里所指的演员包括电影演员、编剧、导演。
- 书籍信息包括书籍 id、图片链接、姓名、子标题、原作名称、作者、译者、出版社、出版年份、页数、价格、内容简介、目录简介、评分、评分人数,共64321 条数据信息。
- 书籍作者信息包括作者 id,姓名、图片链接、性别、出生日期、国家、更多中文名、更多外文名、简介,共6231 条数据信息。这里作者包括书籍作者和译者。
上述为我们爬取的数据类别,但数据有很多噪音,比如中文电影名称会外接英文电影名称、某些类型数据严重缺失、数据格式不统一等等,这就需要我们根据具体数据进行具体分析。此处需要多搬搬砖,没什么技术,不多讲。
2. Json2MySQL
首先我们将 json 类型的数据存储到 MySQL 之中,这里共构建了 13 个表,包含
-
movie_genre: 包含 movie_genre_id, movie_genre_name 属性,表示 movie 类别信息。
-
movie_info: 包含 movie_info_id, movie_info_name, movie_info_image_url, movie_info_country, movie_info_language, movie_info_pubdate, movie_info_duration, movie_info_other_name, movie_info_summary, movie_info_rating, movie_info_review_count 属性,表示 movie 信息。
-
movie_person: 包含 movie_person_id, movie_person_name, movie_person_image_url, movie_person_gender, movie_person_constellation, movie_person_birthday, movie_person_birthplace, movie_person_profession, movie_person_other_name, movie_person_introduction 属性,表示 movie_person 信息。
- movie_to_gender: 包含 movie_info_id, movie_genre_id 属性,设置两个外键,分别关联到 movie_info 表和 movie_genre 表,表示 movie 到 genre 的关联。
- actor_to_movie: 包含 movie_info_id, movie_actor_id 属性,设置两个外键,分别关联到 movie_info 表和 movie_person 表,表示 movie 到 actor 的关联。
- writer_to_movie: 包含 movie_info_id, movie_writer_id,设置两个外键,分别关联到 movie_info 表和 movie_person 表,表示 movie 到 writer 的关联。
- director_to_movie: 包含 movie_info_id, movie_director_id,设置两个外键,分别关联到 movie_info 表和 movie_person 表,表示 movie 到 director 的关联。
- 同理,根据图书信息构建book_genre, book_info, book_person_info, book_to_genre, author_to_book, translator_to_book表。
表构建好之后,利用 pymysql 将 Json 类型数据导入到 MySQL 之中。
3. RDB2RDF
我们已经将 Json 类型的数据导入到关系型数据库 RDB 之中,现在问题是怎么将 RDB Data 转换成 RDF。转换之前,我们先根据数据构建本体。
3.1 本体构建
什么是本体?本体有点哲学的含义,在计算机领域,可以理解为一种模型,用于描述由一套对象类型(概念或者说类)属性以及关系类型所构成的世界。此处我们使用 Protege 进行本体建模。
首先下载 protege,下载链接为https://protege.stanford.edu/。安装完成之后,新建 class,如果没有的话,在 window->Tabs->Classes 寻找。根据 MySQL 之中构建的表,此处构建相应的类,如下所示。红色箭头表示的是构建子类,右边图标指的是构建兄弟类,最右边指的是删除当前类。
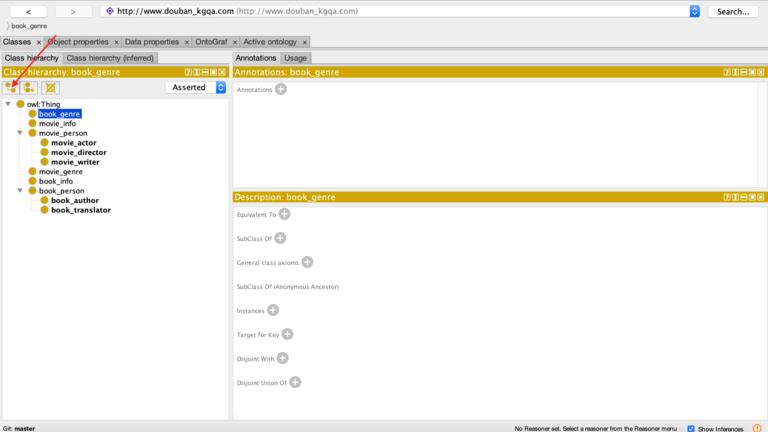
类构建完成之后,进行构建对象属性,共包含
- has_movie_genre: domains 为 movie_info, ranges 为 movie_genre,表示某电影有某类别。
- has_book_genre: domains 为 book_info, ranges 为 book_genre,表示某书籍有某类别。
- has_actor: domains 为 movie_info, ranges 为 movie_actor,表示某电影有某演员。和 has_acted_in 为互逆关系。
- has_acted_in: domains 为 movie_actor, ranges 为 movie_info,表示某演员出演了某电影。和 has_actor 为互逆关系。
- 同理has_writer, has_writed_in, has_director, has_directed_in, has_author, has_authored_in, has_translator, has_translator_in构建方法相同。

对象属性构建完成之后,进行构建数据属性。数据属性构建比较简单,指明数据类别和值类别即可。
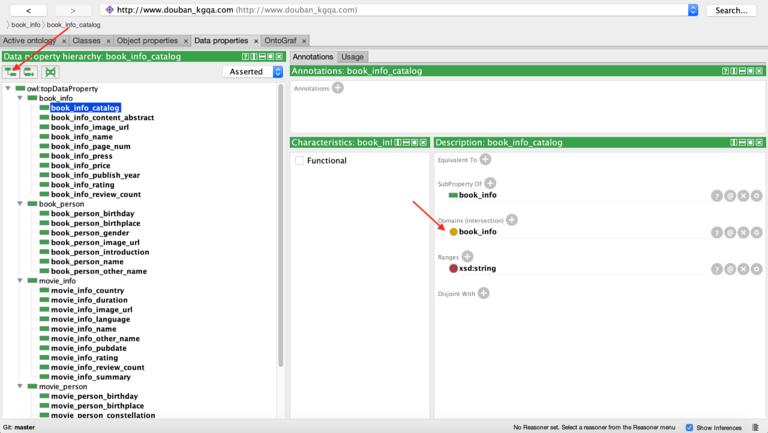
构建完成之后,可以通过 OntoGrap 看到关系图。可以去 window->Tabs->OntoGrap 寻找 OntoGrap。
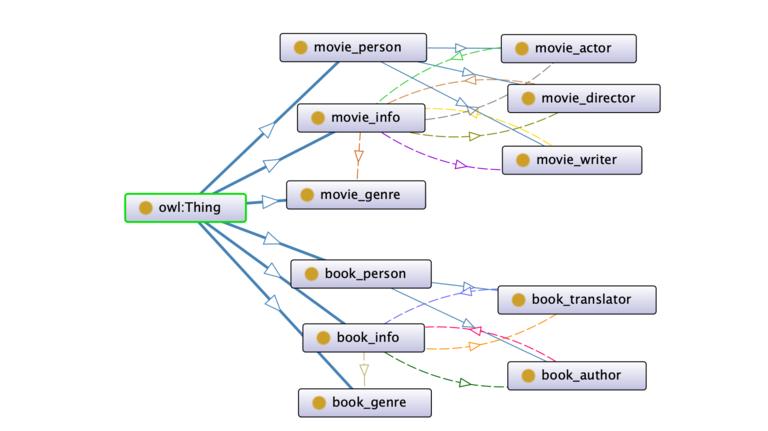
最后通过 File->Save as 保存成 Turtle Syntax 形式,命名为douban_kgqa_ontology.owl。
3.2 D2RQ
RDB 转换成 RDF 有两种方式,一是 direct mapping,即直接映射。规则为
- 数据库的表作为本体中的类(Class)。
- 表的列作为属性(Property)。
- 表的行作为实例 / 资源。
- 表的单元格值为字面量。
- 如果单元格所在的列是外键,那么其值为 IRI,或者说实体 / 资源。
但实际中,我们很少使用这种方法,因为不能把 RDB 中数据映射到我们定义的本体上面。因此我们采用另外一种方法,R2RDF(RDB to RDF Mapping Language),链接为https://www.w3.org/TR/r2rml/。下面我们使用 D2RQ 工具将 RDB 数据转换到 RDF 形式。
D2RQ 提供了自己的 mapping language,其形式和 R2RML 类似,具体语法链接为https://www.w3.org/TR/2004/REC-owl-features-20040210/。D2RQ 有一个比较方便的地方,可以根据已定义的数据库自动生成预定义的 mapping 文件,用户可以在 mapping 文件上修改,把数据映射到自己的本体上。
首先下载 D2RQ 文件,链接为http://d2rq.org/,进入到目录之中,利用下列命令生成douban_kgqa_mapping.ttl文件。
mac, linux 系统命令为
./generate-mapping -u root -p 123456 -o douban_kgqa_mapping.ttl jdbc:mysql:///douban_kgqa
windows 系统命令为
generate-mapping.bat -u root -o douban_kgqa_mapping.ttl jdbc:mysql:///douban_kgqa
参数解读:root 是 mysql 用户名,123456 是 root 密码,douban_kgqa_mapping.ttl 是输出文件名称,douban_kgqa 是 MySQL 数据库名称。注:如果 Mac 用户如果提示 permission denied, 可以用 chmod 改变访问权限,chmod 777 generate-mapping。
现在根据我们的 MySQL 数据库已经生成了默认的douban_kgqa_mapping.ttl文件,然后根据douban_kgqa_ontology.owl中定义的本体修改douban_kgqa_mapping.ttl文件。修改规则如下
- 将id和label属性删除,因为我们不需要这两个属性。
- 修改类型值,将 vocab:xxxx 修改为我们 owl 文件中定义的类。例如将d2rq:class vocab: movie_genre;修改为d2rq:class :movie_genre;
3.3 D2RQ RDF
利用下列命令将数据转换成我们需要的 RDF 数据。
mac, linux 命令为
./dump-rdf -o douban_kgqa.nt ./douban_kgqa_mapping.ttl
windows 命令为
.\dump-rdf -o douban_kgqa.nt .\douban_kgqa_mapping.ttl
参数解读:douban_kgqa_mapping.ttl 是我们修改后的 mapping 文件,其支持导出的 RDF 格式有 TURTLE, RDF/XML, RDF/XML-ABBREV, N3, N-TRIPLE,N-TRIPLE 是默认的输出格式。
利用下列命令,我们能够在http://localhost:2020/ 上进行 SPARQL 数据查询,有兴趣的读者可以尝试一下。
./d2r-server ./douban_kgqa_mapping.ttl
最后查看一下我们生成的 RDF 数据,可以看到共 298 万行,前 10 行的数据格式。其实我们爬虫只运行了两天,数据还是太少,以后有空闲时间再更新更多数据。
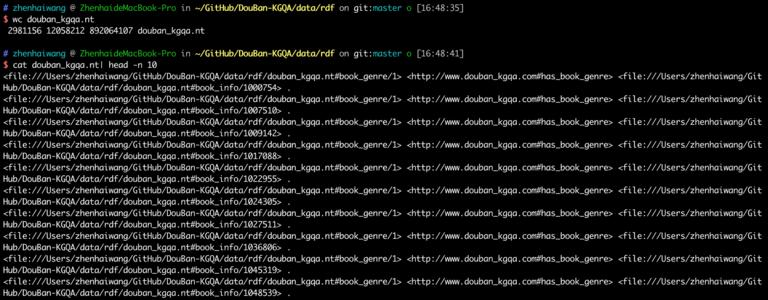
4. 总结
本篇文章主讲了如何将 Json 数据存储到关系型数据库之中,Protege 构建本体方法,如何将 RDB 数据转换成 RDF 类型数据。篇幅有限,下篇文章再讲如何将 RDF 数据转换成 TDB 数据并存储到 Jena 之中,如何利用 Fuseki, SPARQL 进行查询,如何自定义推理规则。欢迎关注公众号谓之小一阅读更多内容。

时间:2019-03-30 23:31 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]人工智能十年回顾:CNN、AlphaGo、GAN……它们曾这
- [机器学习]机器学习基础图表:概念、原理、历史、趋势和算法
- [机器学习]20年以后,半数工作将被人工智能取代?这些“高危行业”有哪些
- [机器学习]技术实践:大规模知识图谱预训练及电商应用
- [机器学习]人工智能十年回顾:CNN、AlphaGo、GAN……它们曾这
- [机器学习]年终总结:2021年五大人工智能(AI)和机器学习(ML)发展趋势
- [机器学习]神经科学如何影响人工智能?看DeepMind在NeurIPS2
- [机器学习]美俄人工智能军事应用
- [机器学习]民调不靠谱?人工智能预测拜登获胜
- [机器学习]ResNet、Faster RCNN、Mask RCNN是专利算法吗?盘点何恺
相关推荐:
网友评论:















