前端人工智能:通过机器学习推导函数方程式--铂金Ⅲ

什么是tensorflow.js
tensorflow.js是一个能运行在浏览器和nodejs的一个机器学习、机器训练的javascript库,众所周知在浏览器上用javascript进行计算是很慢的,而tensorflow.js会基于WebGL通过gpu进行运算加速来对高性能的机器学习模块进行加速运算,从而能让我们前端开发人员能在浏览器中进行机器学习和训练神经网络。本文要讲解的项目代码,就是要根据一些规则模拟数据,然后通过机器学习和训练,根据这些数据去反向推测出生成这些数据的公式函数。
基本概念
接下来我们用五分钟过一下tensorflow的基本概念,这一部分主要介绍一些概念,笔者会用一些类比方式简单的讲述一些概念,旨在帮助大家快速理解,但是限于精力和篇幅,概念的具体详细定义读者们还是多去参照官方文档。
张量(tensors)
张量其实就是一个数组,可以一维或多维数组。张量在tensorflow.js里就是一个数据单元。
- const tensors = tf.tensor([[1.0, 2.0, 3.0], [10.0, 20.0, 30.0]]);
- tensors.print();
在浏览器里将会输出:
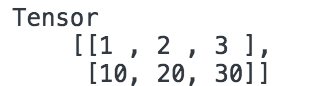
tensorflow还提供了语义化的张量创建函数:tf.scalar(创建零维度的张量), tf.tensor1d(创建一维度的张量), tf.tensor2d(创建二维度的张量), tf.tensor3d(创建三维度的张量)、tf.tensor4d(创建四维度的张量)以及 tf.ones(张量里的值全是1)或者tf.zeros(张量里的值全是0)。
变量(variable)
张量tensor是不可变的,而变量variable是可变的,变量是通过张量初始化而来,代码如下:
- const initialValues = tf.zeros([5]);//[0, 0, 0, 0, 0]
- const biases = tf.variable(initialValues); //通过张量初始化变量
- biases.print(); //输出[0, 0, 0, 0, 0]
操作(operations)
张量可以通过操作符进行运算,比如add(加法)、sub(减法)、mul(乘法)、square(求平方)、mean(求平均值) 。
- const e = tf.tensor2d([[1.0, 2.0], [3.0, 4.0]]);
- const f = tf.tensor2d([[5.0, 6.0], [7.0, 8.0]]);
- const ee_plus_f = e.add(f);
- e_plus_f.print();
上面的例子输出:
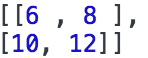
内存管理(dispose和tf.tidy)
dispose和tf.tidy都是用来清空GPU缓存的,就相当于咱们在编写js代码的时候,通过给这个变量赋值null来清空缓存的意思。
- var a = {num: 1};
- a = null;//清除缓存
dispose
张量和变量都可以通过dispose来清空GPU缓存:
- const x = tf.tensor2d([[0.0, 2.0], [4.0, 6.0]]);
- const xx_squared = x.square();
- x.dispose();
- x_squared.dispose();
- tf.tidy
当有多个张量和变量的时候,如果挨个调用dispose就太麻烦了,所以有了tf.tidy,将张量或者变量操作放在tf.tidy函数中,就会自动给我们优化和清除缓存。
- const average = tf.tidy(() => {
- const y = tf.tensor1d([4.0, 3.0, 2.0, 1.0]);
- const z = tf.ones([1]);
- return y.sub(z);
- });
- average.print()
以上例子输出:

模拟数据
首先,我们要模拟一组数据,根据 这个三次方程,以参数a=-0.8, b=-0.2, c=0.9, d=0.5生成[-1, 1]这个区间内一些有误差的数据,数据可视化后如下:
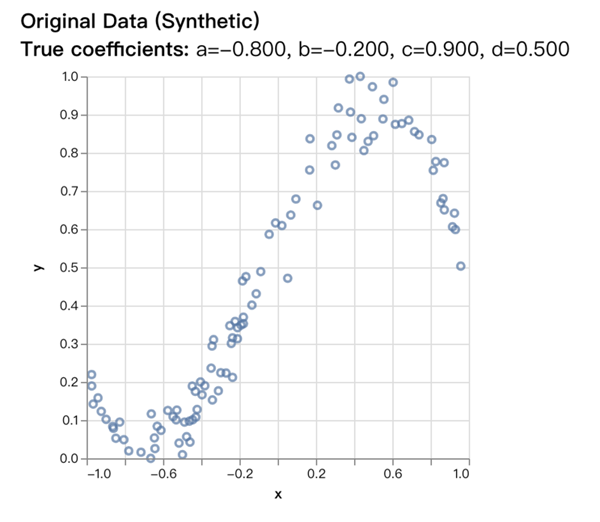
假设我们并不知道a、b、c、d这四个参数的值,我们要通过这一堆数据,用机器学习和机器训练去反向推导出这个多项式函数方程的和它的a、b、c、d这四个参数值。
设置变量(Set up variables)
因为我们要反向推导出多项式方程的a、b、c、d这四个参数值,所以首先我们要先定义这四个变量,并给他们赋上一些随机数当做初始值。
- const a = tf.variable(tf.scalar(Math.random()));
- const b = tf.variable(tf.scalar(Math.random()));
- const c = tf.variable(tf.scalar(Math.random()));
- const d = tf.variable(tf.scalar(Math.random()));
上面这四行代码,tf.scalar就是创建了一个零维度的张量,tf.variable就是将我们的张量转化并初始化成一个变量variable,如果通俗的用我们平时编写javascript去理解,上面四行代码就相当于:
- let a = Math.random();
- let b = Math.random();
- let c = Math.random();
- let d = Math.random();
当我们给a、b、c、d这四个参数值赋上了初始随机值以后,a=0.513, b=0.261, c=0.259, d=0.504,我们将这些参数放入方程式后得到的曲线图如下:
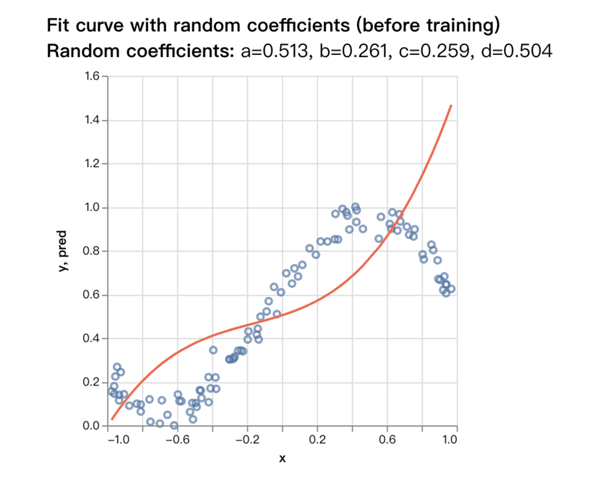
我们可以看到,根据随机生成的a、b、c、d这四个参数并入到多项式后生成的数据跟真正的数据模拟的曲线差别很大,这就是我们接下来要做的,通过机器学习和训练,不断的调整a、b、c、d这四个参数来将这根曲线尽可能的无限接近实际的数据曲线。
创建优化器(Create an optimizer)
- const learningRate = 0.5;
- const optimizer = tf.train.sgd(learningRate);
learningRate这个变量是定义学习率,在进行每一次机器训练的时候,会根据学习率的大小去进行计算的偏移量调整幅度,学习率越低,最后预测到的值就会越精准,但是响应的会增加程序的运行时间和计算量。高学习率会加快学习过程,但是由于偏移量幅度太大,容易造成在正确值的周边上下摆动导致运算出的结果没有那么准确。
tf.train.sgd是我们选用了tensorflow.js里帮我们封装好的SGD优化器,即随机梯度下降法。在机器学习算法的时候,通常采用梯度下降法来对我们的算法进行机器训练,梯度下降法常用有三种形式BGD、SGD以及MBGD。
我们使用的是SGD这个批梯度下降法,因为每当梯度下降而要更新一个训练参数的时候,机器训练的速度会随着样本的数量增加而变得非常缓慢。随机梯度下降正是为了解决这个办法而提出的。假设一般线性回归函数的函数为:
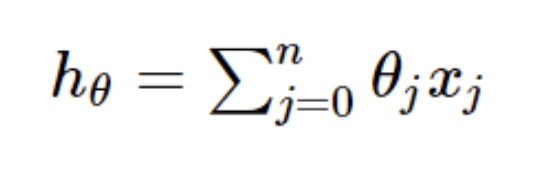
SGD它是利用每个样本的损失函数对θ求偏导得到对应的梯度,来更新θ:
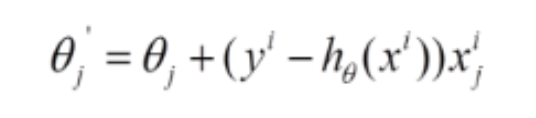
随机梯度下降是通过每个样本来迭代更新一次,对比上面的批量梯度下降,迭代一次需要用到所有训练样本,SGD迭代的次数较多,在解空间的搜索过程看起来很盲目。但是大体上是往着最优值方向移动。随机梯度下降收敛图如下:
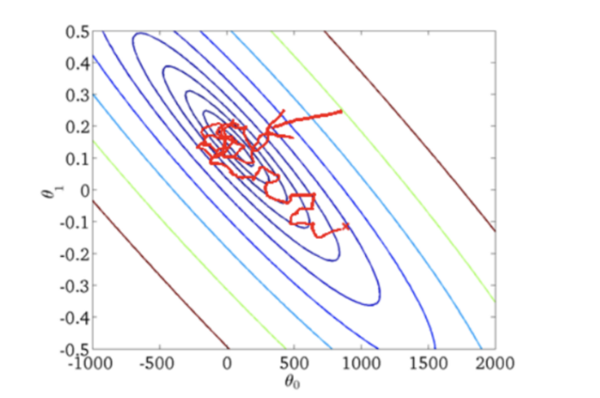
预期函数模型(training process functions)
编写预期函数模型,其实就是用一些列的operations操作去描述我们的函数模型
- function predict(x) {
- // y = a * x ^ 3 + b * x ^ 2 + c * x + d
- return tf.tidy(() => {
- return a.mul(x.pow(tf.scalar(3, 'int32')))
- .add(b.mul(x.square()))
- .add(c.mul(x))
- .add(d);
- });
- }
a.mul(x.pow(tf.scalar(3, 'int32')))就是描述了ax^3(a乘以x的三次方),b.mul(x.square()))描述了b x ^ 2(b乘以x的平方),c.mul(x)这些同理。注意,在predict函数return的时候,用tf.tidy包了起来,这是为了方便内存管理和优化机器训练过程的内存。
定义损失函数(loss)
接下来我们要定义一个损失函数,使用的是MSE(均方误差,mean squared error)。数理统计中均方误差是指参数估计值与参数真值之差平方的期望值,记为MSE。MSE是衡量“平均误差”的一种较方便的方法,MSE可以评价数据的变化程度,MSE的值越小,说明预测模型描述实验数据具有更好的精确度。MSE的计算非常简单,就是先根据给定的x得到实际的y值与预测得到的y值之差 的平方,然后在对这些差的平方求平均数即可。
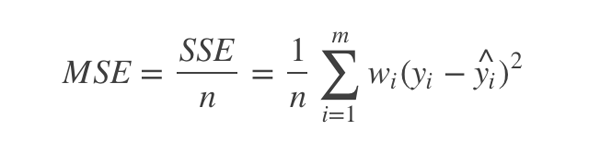
根据如上所述,我们的损失函数代码如下:
- function loss(prediction, labels) {
- const error = prediction.sub(labels).square().mean();
- return error;
- }
预期值prediction减去实际值labels,然后平方后求平均数即可。
机器训练(training)
好了,上面说了这么多,做了这么多的铺垫和准备,终于到了最关键的步骤,下面这段代码和函数就是真正的根据数据然后通过机器学习和训练计算出我们想要的结果最重要的步骤。我们已经定义好了基于SGD随机梯度下降的优化器optimizer,然后也定义了基于MSE均方误差的损失函数,我们应该怎么结合他们两个装备去进行机器训练和机器学习呢,看下面的代码。
- const numIterations = 75;
- async function train(xs, ys, numIterations) {
- for (let iter = 0; iter < numIterations; iter++) {
- //优化器:SGD随机梯度下降
- optimizer.minimize(() => {
- const pred = predict(xs);
- //损失函数:MSE均方误差
- return loss(pred, ys);
- });
- //防止阻塞浏览器
- await tf.nextFrame();
- }
- }
我们在外层定义了一个numIterations = 75,意思是我们要进行75次机器训练。在每一次循环中我们都调用了optimizer.minimize这个函数,它会不断地调用SGD随机梯度下降法来不断地更新和修正我们的a、b、c、d这四个参数,并且每一次return的时候都会调用我们的基于MSE均方误差loss损失函数来减小损失。经过这75次的机器训练和机器学习,加上SGD随机梯度下降优化器和loss损失函数进行校准,最后就会得到非常接近正确数值的a、b、c、d四个参数。
我们注意到这个函数最后有一行tf.nextFrame(),这个函数是为了解决在机器训练和机器学习的过程中会进行大量的机器运算,会阻塞浏览器,导致ui没法更新的问题。
我们调用这个机器训练的函数train:
- import {generateData} from './data';//这个文件在git仓库里
- const trainingData = generateData(100, {a: -.8, b: -.2, c: .9, d: .5});
- await train(trainingData.xs, trainingData.ys, 75);
调用了train函数后,我们就可以拿到a、b、c、d四个参数了。
- console.log('a', a.dataSync()[0]);
- console.log('b', b.dataSync()[0]);
- console.log('c', c.dataSync()[0]);
- console.log('d', d.dataSync()[0]);
最后得到的值是a=-0.564, b=-0.207, c=0.824, d=0.590,和原先我们定义的实际值a=-0.8, b=-0.2, c=0.9, d=0.5非常的接近了,对比图如下:
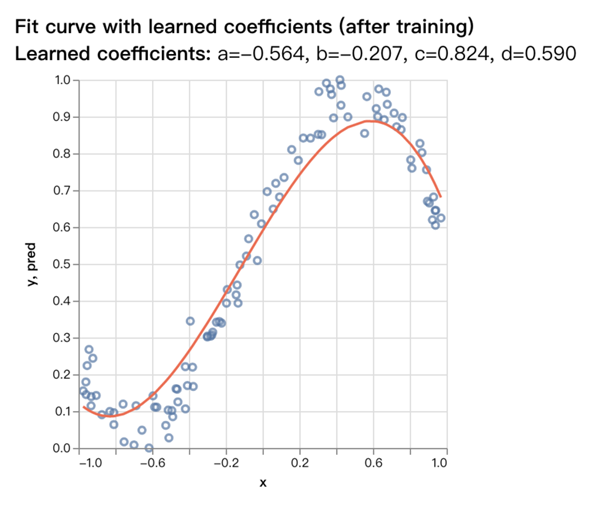
项目运行和安装
本文涉及到的代码安装和运行步骤如下:
- git clone https://github.com/tensorflow/tfjs-examples
- cd tfjs-examples/polynomial-regression-core
- yarn
- yarn watch
tensorflow.js的官方example里有很多个项目,其中polynomial-regression-core(多项式方程回归复原)这个例子就是我们本文重点讲解的代码,我在安装的过程中并不太顺利,每一次运行都会报缺少模块的error,读者只需要根据报错,把缺少的模块挨个安装上,然后根据error提示信息上google去搜索相应的解决方法,最后都能运行起来。
结语
bb了这么多,本来不想写结语的,但是想想,还是想表达一下本人内心的一个搞笑荒谬的想法。我为什么会对这个人工智能的例子感兴趣呢,是因为,在我广西老家(一个偏远的山村),那边比较封建迷信,经常拿一个人的生辰八字就去计算并说出这个人一生的命运,balabala说一堆,本人对这些风气一贯都是嗤之以鼻。但是,但是,但是。。。。荒谬的东西来了,我老丈人十早年前因为车祸而断了一条腿,几年前带媳妇和老丈人回老家见亲戚,老丈人觉得南方人这些封建迷信很好玩,就拿他自己的生辰八字去给乡下的老者算了一下,结果那个老人说了很多,并说出了我老丈人出车祸的那一天的准确的日期,精确到那一天的下午大致时间。。。。。这。。。。这就好玩了。。。当年整个空气突然安静的场景至今历历在目,这件事一直记在心里,毕竟我从来不相信这些鬼鬼乖乖的东西,一直信奉科学是至高无上带我们飞的唯一真理,但是。。。真的因为这件事,让我菊紧蛋疼不知道怎么去评价。。。。
咦?这跟人工智能有什么关系?我只是在思考,是不是我们每个人的生辰八字,就是笛卡尔平面坐标系上的维度,或者说生辰八字就是多项式函数的a、b、c、d、e系数,是不是真的有一个多项式函数方程能把这些生辰八字系数串联起来得到一个公式,这个公式可以描述你的一生,记录你的过去,并预测你的将来。。。。。。我们能不能找到自己对应的维度和发生过的事情联系起来,然后用人工智能去机器学习并训练出一个属于我们自己一生命运轨迹的函数。。。。行 不说了 ,各位读者能看到这里我也是觉得对不起你们,好好读书并忘掉我说的话。
上述观点纯属个人意淫,该搬砖搬砖,该带娃带娃,祝各位早日登上前端最强王者的段位。!^_^!

时间:2019-03-23 10:56 来源:未知 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]堪比当年的LSTM,Transformer引燃机器学习圈:它是
- [机器学习]论机器学习领域的内卷:不读PhD,我配不配找工
- [机器学习]人工智能十年回顾:CNN、AlphaGo、GAN……它们曾这
- [机器学习]机器学习基础图表:概念、原理、历史、趋势和算法
- [机器学习]分析了 600 多种烘焙配方,机器学习开发出新品
- [机器学习]2021年的机器学习生命周期
- [机器学习]物联网和机器学习促进企业业务发展的5种方式
- [机器学习]20年以后,半数工作将被人工智能取代?这些“高危行业”有哪些
- [机器学习]机器学习中分类任务的常用评估指标和Python代码实现
- [机器学习]机器学习和深度学习的区别是什么?
相关推荐:
网友评论:















