深度学习在苏宁知识抽取领域的尝试与实践

近几年,随着海量数据的累积、计算能力的提升和算法模型的创新,无论是在学术界还是工业界,深度学习在NLP领域已经得到越来越多的关注与应用,并且有很多可喜的落地成果。知识的抽取和挖掘一直是Data Mining、Knowledge Graph等NLP子领域的重要问题,知识抽取的范围包括实体抽取、关系抽取、属性抽取等,本文主要介绍深度学习在苏宁小店商品标题上的应用,重点挖掘属性词、品牌词、物品词等和业务强相关的实体信息。
知识抽取任务按照文本结构可分为以下几类:
面向结构化数据的知识抽取:比如用D2R从结构化数据库中提取知识,其难点在于对复杂表数据的处理,包括嵌套表、多列、外键关联等;采用图映射的方式从链接数据中获取知识,难点在于数据的对齐。
面向半结构化的知识抽取:使用包装器从半结构化(比如网站)数据中获取知识,难点在于包装器的自动生成、更新与维护。
面向文本的知识抽取:与上面结构/半结构化方式不同,由于非结构文本的知识格式基本上没有固定的规则可寻,业界也缺乏能直接应用于中文的处理工具,所以本文采用深度学习方法,重点关注word embedding质量的角度,从随机初始化向量到主流预训练方法,去有效提升抽取结果的准确率和覆盖率。
B-LSTM+CRF模型
B-LSTM+CRF是2016年卡耐基梅隆大学和庞培法布拉大学NLP组提出的一种解决NER问题的网络架构,并经实验在4种语言(英语、德语、荷兰语、西班牙语)上表现亮眼,其中在德语和西班牙语上取得了SOA效果,所以本文将采用这种网络结构作为苏宁搜索知识抽取任务的关键模型之一,下面先简单介绍这种模型。
模型框架
模型数据的输入采用两种方案,第一种不使用任何分词算法,采用BIO的标注方法直接以“字”为单位做序列标注,第二种采用业务自定义的标签集对分词后的word进行标注。利用苏宁搜索平台累积的业务词表对苏宁小店的商品标题做自动标注,经过运营的筛选和剔除,获取干净的数据集。
这里以第一种标注方法为例(ATT:属性词,BRA:品牌词,GOD:物品词),以小店商品标题为单位,将一个含有n个字的title(字的序列)记作:
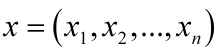
其中 xi 表示标题的第 i 个字在字典中的id,暂不考虑预训练,进而可以得到每个字的one-hot向量,维数是字典大小。

第一层:look-up 层,利用word2vec或随机初始化的embedding矩阵将title中的每个字 xi 由one-hot向量映射为低维稠密的字向量(character embedding)xi∈Rd ,d是embedding的维度。在输入下一层之前,设置dropout以缓解过拟合。
第二层:双向LSTM层,自动提取title特征。将一个title的各个字的char embedding序列 (x1,x2,...,xn) 作为双向LSTM各个时间步的输入,再将正向LSTM输出的隐状态序列
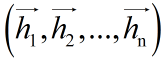
与反向LSTM的
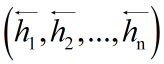
在各个位置输出的隐状态进行按位置拼接,
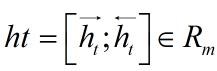
得到完整的隐状态序列
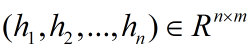
对隐层的输出设置dropout后,再外接一个线性层,将隐状态向量从 m 维映射到 k 维,k 是标注集的标签数,从而得到自动提取的title特征,记作矩阵 P=(p1,p2,...,pn)∈Rn×k 。可以把 pi∈Rk的每一维 pij 都视作将字 xi 分类到第 j 个标签的打分值,如果再对 P 进行Softmax的话,就相当于对各个位置独立进行 k 类分类。但是这样对各个位置进行标注时无法利用已经标注过的信息,所以接下来将接入一个CRF层来进行标注。
第三层:CRF层,进行title级的序列标注。CRF层的参数是一个(k+2)×(k+2)的矩阵A ,Aij表示的是从第 i 个标签到第 j 个标签的转移得分,进而在为一个位置进行标注的时候可以利用此前已经标注过的标签。如果记一个长度等于title长度的标签序列 y=(y1,y2,...,yn) ,那么模型将整个title x 的标签标注为序列 y 的打分函数为:(公式1)
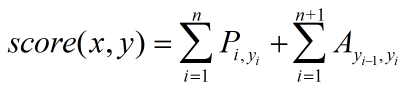
可以看出整个序列的打分等于各个位置的打分之和,而每个位置的打分由两部分得到,一部分是由LSTM输出的 pi 决定,另一部分则由CRF的转移矩阵 A 决定。进而可以利用Softmax得到归一化后的概率:(公式2)
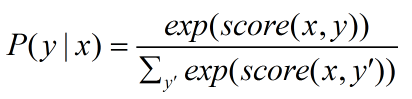
模型训练时通过最大化对数似然函数,下式给出了对一个训练样本 (x,y) 的对数似然:(公式3)
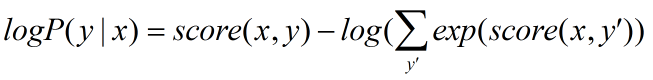
模型在预测过程时使用动态规划的Viterbi算法来求解最优路径,从而得到每个字的预测标签:(公式4)
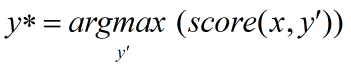
CRF层约束性规则
由于B-LSTM的输出为单元的每一个标签分值,我们可以挑选分值最高的一个作为该单元的标签。例如,对于单元w0,“I-BRA”有最高分值 1.5,因此我们可以挑选“I-BRA”作为w0的预测标签。同理,我们可以得到其他token的标签,w1:“B-BRA”,w2:“O” ,w3:“B-GOD”,w4:“O”。
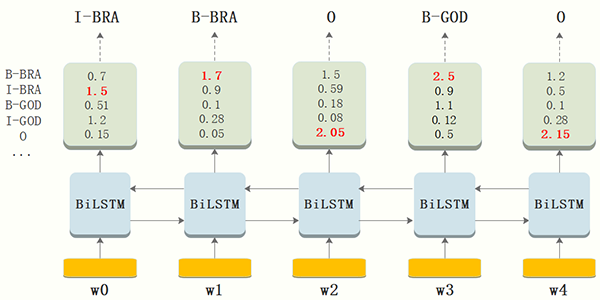
虽然单纯的通过B-LSTM我们可以得到title中每个token的标签,但是不能保证标签每次都是预测正确的。例如,上图中的例子,标签序列是“I-BRA B-BRA”很显然是错误的。
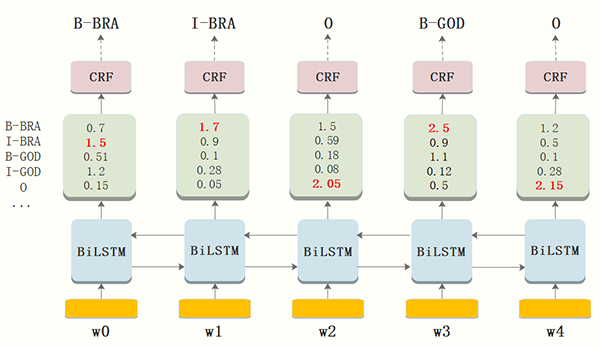
在神经网络的输出层接入CRF层(重点是利用标签转移概率)来做句子级别的标签预测,使得标注过程不再是对各个token独立分类。B-LSTM计算出的是每个词的各标签概率,而CRF层引入序列的转移概率,最终计算出loss反馈回网络,所以上图在CRF的作用下,序列能根据转移概率做出符合常理的调整。
CRF层可以为最后预测的标签添加一些约束来保证预测的标签是符合规则的,这些约束可以在训练数据训练过程中,通过CRF层自动学习到。
比如:
1、title中第一个词总是以标签“B-” 或 “O”开始,而不是“I-”;
2、标签“B-label1 I-label2 I-label3 I-…”,label1, label2, label3应该属于同一类实体。例如,“B-BRA I-BRA” 是合法的序列, 但是“B-BRA I-GOD” 是非法标签序列;
3、标签序列“O I-label” 是非法的.实体标签的首个标签应该是 “B-” ,而非 “I-”, 换句话说,有效的标签序列应该是“O B-label”。
有了以上自动学习到的约束规则,标签序列预测中非法序列出现的概率将会显著降低。
实验效果
论文[1]基于语料CoNLL-2003,在4种语言(英语、德语、荷兰语、西班牙语)上表现亮眼,其中在德语和西班牙语上取得了SOA效果。
在苏宁小店商品标题标注语料上,我们进行了随机初始向量和word2vec预训练的对比实验,实验1的方式比较粗糙,我们以“字”为单位,对非数字和字母的字符进行one-hot编码并经过look-up层获得字符的低维稠密编码,所有数字和字母的编码分别被固化;实验2对非数字和字母的字符采用word2vec预训练的编码方式;考虑到商品title中的数字和英文字母对编码的重要性,实验3对实验2稍加改造,同时训练出字母、数字的字向量;实验4舍弃实验3中基于character的编码方式,按照分词后的token重新标注后作为模型的输入,下表展示了实验结果(N表示未对字母与数字进行区分编码,Y相反):

从上面的实验可知,将每个字母与数字视为和汉字相同意义的字符后对F1值的提升有较大作用。从小店实际要提取的实体信息结构我们也可以知道,字母和数字是属性词、品牌词的重要构成部分,比如:1000g的洗衣粉,“1000g”是需要提取的属性词;HUAWEI p20手机套,“HUAWEI”是需要提取的品牌词。Word2vec对分词后的token进行预训练后,模型的准确率又得到了进一步提升,由此可见,word相对于char包含的语义更丰富,有助于模型参数的正确拟合。
ELMO
上文B-LSTM+CRF输入的word embedding是通过随机化或word2vec训练得到的,这种方式得到的embedding质量不高,包含的隐含特征很有限且无法解决一词多义,比如“苹果”,如果苹果前面是吃、咬等食用性动词,则苹果表示一种水果,是我们需要提取的物品词,如果是“某某苹果手机”,或title中含有256g、金色等属性词,则苹果是我们需要提取的品牌词。因为word2vec模型的学习目标是预测词发生的概率,这种从海量语料中学习到的是词的通用语义信息,无法直接应用于定制业务的匹配场景。
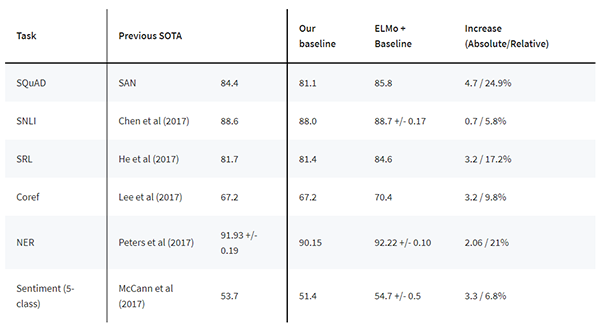
ELMO是2018年由AllenNLP出品,并被评为当年NAACL best paper,它的主要贡献是训练得到的word embedding融于了丰富的句法和语义特征,作者将它加入到下游任务中,在六项挑战性的NLP任务中取得了SOA效果。从官网给出的效果来看,基本上在原SOA的基础上绝对提升了2~4个百分点。
模型框架与原理
下面从模型结合源码的角度来分析这个神奇的模型。
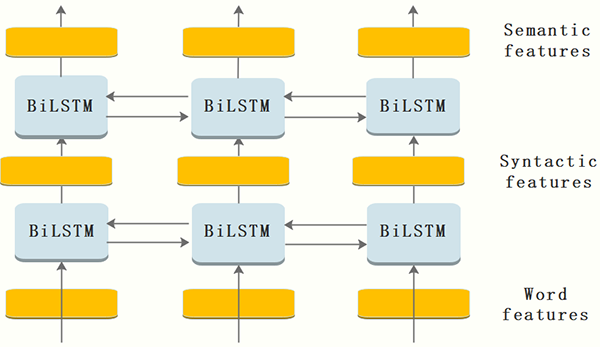
由于传统NLP语言模型是一种单向的概率模型,对于预测下一个word,只利用了前向的单词,比如预测第k个单词,用公式表示如下:(公式5)

所以这种模型的弊端就很明显,无法利用预测单词的右侧信息,尤其是在完形填空、阅读理解、机器翻译等领域需要考虑上下文的场合不是特别适用,对于本文目标这种提取标题中的品牌、属性、物品词等信息,考虑其上下文的信息也是很有必要的,只考虑右向信息的语言模型公式如下:(公式6)
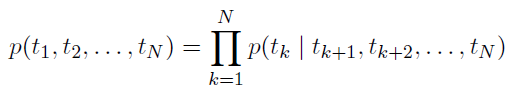
ELMO的创新之处是采用了两层的B-LSTM模型,同时考虑左右两侧的信息,将上面公式5和6联立起来作为目标函数:(公式7)
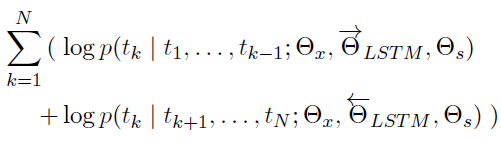
通过最大化上面的似然函数,求得模型的参数。其中, 表示模型的初始化输入的token representation,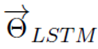 、
、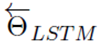 分别表示前向、后向隐层的token representation,
分别表示前向、后向隐层的token representation,
表示前后向的softmax参数,用来调节隐层representation的比重。
当喂训练数据给这个网络时,经过一定的迭代训练次数,我们就可以得到各个隐层以及初始token的embedding,下面k表示第k个token,j表示网络的层数:(公式8)
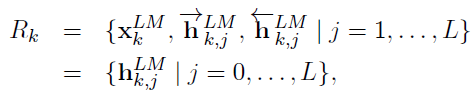
上面是一个token的三层embedding综合表达,要获取最终的embedding,我们需要去调节每个隐层(包含初始输入,当做第0层)在最终embedding中所占的比重。论文中给出了这个公式:(公式9)
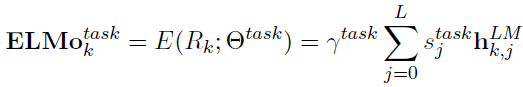
其中,sj是一个和task相关的权值,是由softmax函数normalized得到。
由源码可知,如果只是利用ELMO去产出词向量,而不和下游的任务结合使用的话,这里的task就是指上面公式7的语言模型task,sj是单纯由这个“改进的”语言模型task而训练得到。如果和下游的task配合使用,则是由两者共同训练得到。
按照论文的说法,第一隐层的embedding能获取更多的语法特征,第二隐层embedding能获取更多的语义特征,所以当下游任务是偏句法分析的task时,会学习到更大的s1,反之,如果下游任务偏语义分析时,s2相对更大一些。
使用方式
从是否使用预训练模型的角度,ELMO有两种使用方式,第一种就是直接使用官方提供的预训练模型,它给我们提供了预训练好的模型参数并给出了超参(官方的预训练模型是基于英文的,10亿token word的新闻语料,在3个GTX 1080上迭代10次训练了长达2周的时间)。而我们的任务是中文对话语料的NER问题,不能直接使用其提供好的模型,但我们不妨先看一下官方对于使用其预训练模型的几种方式:

第一种是使用字符输入方式动态的去训练你的语料,这种方式比较通用但是代价较高,它的好处是对于能一定程度减少未登录词的影响。第二种是将一些和上下文无关,没什么歧义的词事先训练好缓存起来,等到用的时候就不用重复训练了,这种方式相对1来说代价低一些,但是这些词需要事先指定好。第三种是将你所有的语料,比如爬取的新闻数据、采集的对话数据等等全部喂给ELMO,把训练好的终极词向量和中间隐层词向量全部存起来,等到下游任务需要的时候直接去load就好了,我觉得这种方式一开始的代价比较高,但由于embedding可以复用,所以能给以后的task节约不少时间,在下游的task使用这些 embedding时和预训练时一样,做个动态的加权就好了。
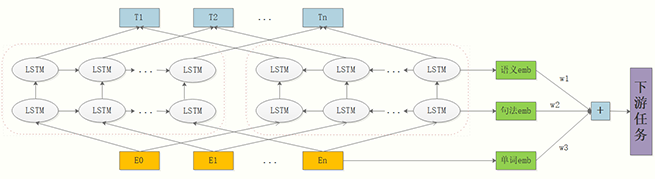
上面介绍了使用预训练模型的方式,归根到底是在原来模型的基础上对模型参数做了一个微调,从而间接对输出的embedding做了微调,使输出的embedding更符合当前上下文的语义。
从是否使用预训练模型角度的第二种方式:自然就是不直接使用预训练好的模型,那我们需要从零开始去训练所有的参数,这个代价很高,但如果要使用ELMO去获取中文的embedding,这个工作是必须要做的,步骤如下:

处理细节可参考哈工大的博文(如何将ELMo词向量用于中文)。
实验效果
说了这么多,EMLO到底有没有解决一词多义呢?请看下图作者的实验(论文[2]):

Glove根据它的 embedding 找出的最接近的其它单词大多数集中在体育领域,这很明显是因为训练数据中包含 play 的句子中体育领域的数量明显占优导致;而使用 ELMO,根据上下文动态调整后的 embedding 不仅能够找出对应的「演出」的相同语义的句子,而且还可以保证找出的句子中的 play 对应的词性也是相同的,这是超出期待之处。
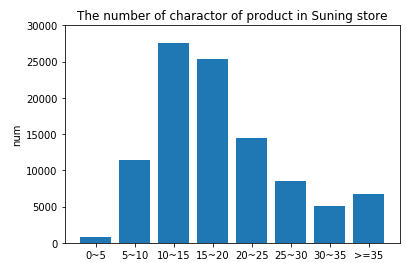
同样的,在我们的苏宁小店商品title知识抽取任务中,底层的预训练方式由上文实验4中的word2vec换为ELMO,对于相同的训练数据,经过实验得到的F1值稍有提升,但不太明显。下图采样了10万条苏宁小店商品标题,统计了每条文本的字符个数,大部分集中在10~20个字符之间,可能这种短文本蕴含的句法和语义信息有限,ELMO相对word2vec学习到额外的特征也有限。
那ELMO有没有什么缺点呢?显然是有的!由于ELMO的特征提取器采用的是老将LSTM,其特征抽取能力远弱于新贵Transformer,而且双层B-LSTM拼接方式的双向融合特征融合能力偏弱,所以这种模型架构还是有一些弊端的,因此下面尝试采用18年大火的BERT架构作为底层word embedding的编码器。
BERT
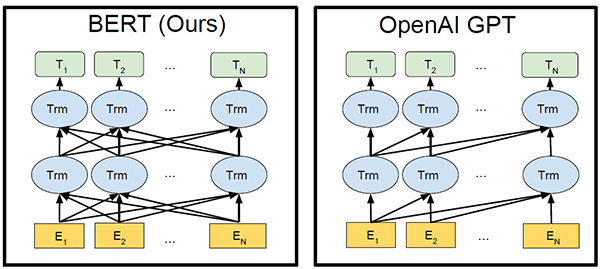
BERT是google在2018年的代表作,其在11项NLP任务中取得SOA效果,几乎可以说是横扫各种牛马蛇神。BERT的主要创新在于提出了MLM(Mask Language Mode),并同时融入了预测句子的子任务,使Transformer可以实现双向编码。
Transformer是17年谷歌在论文《Attention is all you need》中提出的一种新的编解码模型。模型创新性的提出了self-attention机制,在克服传统RNN无法并行计算问题的同时,还能抽取到更多的语义信息,现在已经得到了工业界和学术界的青睐并有逐渐替代RNN、CNN等传统模型的趋势。
Self-attention机制利用查询向量Q、键向量K和值向量V获得了当前token和其他每个token的相关度,每个token根据这种相关度都自适应的融入了其他token的representation,用公式表示如下:(公式10)
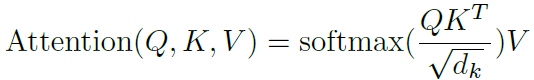
类似于CNN中的多核卷积操作,论文中同时使用了multi-head机制,因为每一个head都会使某个token和其他token产生关联,这种关联或多或少有强有弱,mutil-head通过拼接每个head的输出,再乘以一个联合模型训练的权重矩阵,有效扩展了模型专注于不同位置的能力,有点博览众家之长的意思,公式表示如下:(公式11)

论文《Attention is all you need》主要验证了Transformer在机器翻译中的良好表现,和本文训练word embedding的目标不一样,机器翻译是一个监督型任务,在给定的双语语料下,模型的输入是一个完整待翻译sentence,sentence中的每个token都并行参与编码,而词向量训练是一个无监督任务,常常使用传统NLP语言模型去最大化语言模型的极大似然,从而得到每个token的representation,它仅仅考虑单向的token信息。说到使用transformer进行词向量训练就不得不提2018年OpenAI提出的论文《Improving Language Understanding by Generative Pre-Training》(简称GPT),但其在非监督预训练阶段使用的仍然是单向的语言模型,训练出的word embedding固然损失了许多精度。
最近openAI基于GPT的扩展又公布了新的通用NLP模型—GPT-2,无需预训练就能完成多种不同任务且取得良好结果,这个我们保持关注。言归正传,bert抛弃了传统的单向语言模型,创新性的提出了MLM语言模型,类似于word2vec中的CBOW模型,利用窗口内的上下文来预测中心词,同时引入预测下一句文本的子任务,有效解决了预测单词这种细粒度任务不能很好编码到句子层级的问题。
BERT从头训练的代价十分高昂,好在google开源了中文的预训练模型参数,所以本文直接用小店的商品标题语料对预训练好的模型进行fine-tune。

数据按照one-hot预处理好后喂给BertModel,再将模型输出的sequence embedding传入下游的B-LSTM+CRF,最终的标注结果相对实验3(word2vec+字+Y)提升2.002%,足以说明BERT的强大。
总结
深度学习较强的参数拟合能力,省去了许多繁琐的特征工程工作。本文介绍了几种常见的预训练方式,阐述了算法的基本原理并应用于苏宁小店商品标题的知识抽取任务。苏宁搜索团队在NER、关系抽取、事件抽取、共指消解等知识挖掘的子任务有很多的尝试与实践,限于篇幅本文不做介绍,欢迎读者关注后续的文章分享。
参考文献
1、Lample G, Ballesteros M, Subramanian S, et al. Neural architectures for named entity recognition[J]. arXiv preprint arXiv:1603.01360, 2016.
2、Peters M E, Neumann M, Iyyer M, et al. Deep contextualized word representations[J]. arXiv preprint arXiv:1802.05365, 2018.
3、Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
4、https://github.com/allenai/bilm-tf
5、https://allennlp.org/elmo
6、张俊林. 从Word Embedding到Bert模型——自然语言处理预训练技术发展史
7、DL4NLP —— 序列标注:BiLSTM-CRF模型做基于字的中文命名实体识别
8、简书 御风之星.BiLSTM模型中CRF层的运行原理
9、The Annotated Transformer
10、Radford A, Narasimhan K, Salimans T, et al. Improving language understanding by generative pre-training[J].

时间:2019-03-23 10:41 来源:未知 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]Facebook新AI模型SEER实现自监督学习,LeCun大赞最有
- [机器学习]一文详解深度学习最常用的 10 个激活函数
- [机器学习]增量学习(Incremental Learning)小综述
- [机器学习]盘点近期大热对比学习模型:MoCo/SimCLR/BYOL/SimSi
- [机器学习]深度学习中的3个秘密:集成、知识蒸馏和蒸馏
- [机器学习]【模型压缩】深度卷积网络的剪枝和加速
- [机器学习]堪比当年的LSTM,Transformer引燃机器学习圈:它是
- [机器学习]深度学习三大谜团:集成、知识蒸馏和自蒸馏
- [机器学习]论机器学习领域的内卷:不读PhD,我配不配找工
- [机器学习]“狂欢”的半导体设备
相关推荐:
网友评论:















