透彻理解深度学习背后的各种思想和思维
深度神经网络在2012年兴起,当时深度学习模型能够在传统机器学习问题,例如图像分类和语音识别,击败最先进的传统方法。这要归功于支撑深度学习的各种哲学思想和各种思维。
抓住主要矛盾,忽略次要矛盾--池化
神经网络中经过池化后,得到的是突出化的概括性特征。相比使用所有提取得到的特征,不仅具有低得多的维度,同时还可以防止过拟合。
比如max_pooling: 夜晚的地球俯瞰图,灯光耀眼的穿透性让人们只注意到最max的部分,产生亮光区域被放大的视觉错觉。故而 max_pooling 对较抽象一点的特征(如纹理)提取更好。

池化是一种降采样技术,减少参数数量,也可防止过拟合。如卷积核一样,在池化层中的每个神经元被连接到上面一层输出的神经元,只对应一小块感受野的区域。

池化体现了“抓住主要矛盾,忽略次要矛盾”哲学思想,在抽取特征的过程中,抓住图片特征中最关键的部分,放弃一些不重要、非决定性的小特征。
避免梯度消失--ReLU和批归一化
深度神经网络随着层数的增多,梯度消失是一个很棘手的问题。
ReLU主要好处是降低梯度弥散可能性和增加稀疏性。
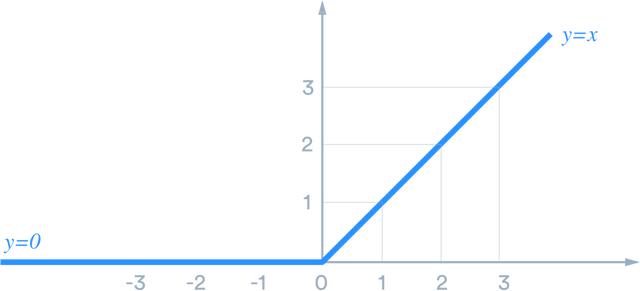
线性整流函数ReLU(Rectified Linear Unit)的定义是h = max(0,a)其中a = Wx + b。
降低梯度消失可能性。特别是当a > 0时,此时梯度具有恒定值。作为对比,随着x的绝对值增加,sigmoid函数的梯度变得越来越小。ReLU的恒定梯度导致更快的学习。
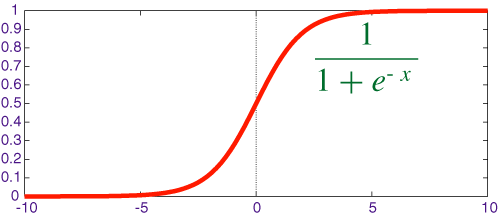
增加稀疏性。当a≤ 0稀疏性出现。网络层中存在的这样单元越多,得到越多的表示稀疏性。另一方面,Sigmoid激活函数总是可能产生一些非零值,从而产生密集的表示。稀疏表示比密集表示更有益。
批归一化BN(Batch Normalization)很好地解决了梯度消失问题,这是由其减均值除方差保证的:

把每一层的输出均值和方差规范化,将输出从饱和区拉倒了非饱和区(导数),很好的解决了梯度消失问题。下图中对于第二层与第一层的梯度变化,在没有使用BN时,sigmoid激活函数梯度消失5倍,使用BN时,梯度只消失33%;在使用BN时,relu激活函数梯度没有消失。

集成学习的思想--Dropout
Dropout是可以避免过拟合的一种正则化技术。

Dropout是一种正则化形式,它限制了网络在训练时对数据的适应性,以避免它在学习输入数据时变得"过于聪明",因此有助于避免过度拟合。
dropout本质上体现了集成学习思想。在集成学习中,我们采用了一些"较弱"的分类器,分别训练它们。由于每个分类器都经过单独训练,因此它学会了数据的不同"方面",并且它们的错误也不同。将它们组合起来有助于产生更强的分类器,不容易过度拟合。随机森林、GBDT是典型的集成算法。
一种集成算法是装袋(bagging),其中每个成员用输入数据的不同子集训练,因此仅学习了整个输入特征空间的子集。
dropout,可以看作是装袋的极端版本。在小批量的每个训练步骤中,dropout程序创建不同的网络(通过随机移除一些单元),其像往常一样使用反向传播进行训练。从概念上讲,整个过程类似于使用许多不同网络(每个步骤一个)的集合,每个网络用单个样本训练(即极端装袋)。
在测试时,使用整个网络(所有单位)但按比例缩小。在数学上,这近似于整体平均。
显然这是一种非常好应用于深度学习的集成思想。
深层提取复杂特征的思维
今天深度学习已经取得了非常多的成功。深度神经网络,由AlexNet的8层到GoogLeNet的22层,再到ResNet的152层,随着层数的增加,top5错误率越来越低,达到3.57%。
由于图像和文本包含复杂的层次关系,因此在特征提取器中找到表示这些关系的公式并不容易。深度学习系统具有多层表示能力,它能够让网络模拟所有这些复杂的关系。
所以在学习和应用深度学习时,不要惧怕网络层次之深,正是这种深层结构才提取了图像、文本、语音等原始数据的抽象的本质特征。

神经网络构建一个逐步抽象的特征层次结构。
每个后续层充当越来越复杂的特征的过滤器,这些特征结合了前一层的特征。
- 每一层对其输入应用非线性变换,并在其输出中提供表示。
- 每一层中的每个神经元都会将信息发送到下一层神经元,下一层神经元会学习更抽象的数据。
所以你上升得越高,你学到的抽象特征就越多。。目标是通过将数据传递到多个转换层,以分层方式学习数据的复杂和抽象表示。感官数据(例如图像中的像素)被馈送到第一层。因此,每层的输出作为其下一层的输入提供。
深层次网络结构所具有的强大的抽象学习和表征能力
拿图像识别举例,在最底层,是像素这些东西。当我们一层一层往上的时候,慢慢的可能有边缘,再往上可能有轮廓,甚至对象的部件,等等。总体上,当我们逐渐往上的时候,它确实是不断在对对象进行抽象。而由现象到本质的抽象过程中,是需要很多阶段、很多过程的,需要逐步去粗取精、逐步凸显,才能最终完成。
层数为什么要那么多?这其中体现了从整体到部分、从具体到抽象的认识论哲学思想。
抽取共同的、本质性的特征,舍弃非本质的特征。这过程本来就是一个逐渐抽象的过程,抽丝剥茧、层层萃取、逐渐清晰、统一汇总,层数少抽取出的特征是模糊的、无法表征的!
非线性思维
每一层进行非线性变换是深度学习算法的基本思想。数据在深层架构中经过的层越多,构造的非线性变换就越复杂。这些变换表示数据,因此深度学习可以被视为表示学习算法的特例,其在深层体系结构中学习具有多个表示级别的数据表示。所实现的最终表示是输入数据的高度非线性函数。
深层体系结构层中的非线性变换,试图提取数据中潜在的解释因素。不能像PCA那样使用线性变换作为深层结构层中的变换算法,因为线性变换的组合产生另一种线性变换。因此,拥有深层架构是没有意义的。
例如,通过向深度学习算法提供一些人脸图像,在第一层,它可以学习不同方向的边缘; 在第二层中,它组成这些边缘以学习更复杂的特征,如嘴唇,鼻子和眼睛等脸部的不同部分。在第三层中,它组成了这些特征,以学习更复杂的特征,如不同人的面部形状。这些最终表示可以用作面部识别应用中的特征。
提供该示例是为了简单地以可理解的方式解释深度学习算法如何通过组合在分层体系结构中获取的表示来找到更抽象和复杂的数据表示。
省去特征工程的思维
传统机器学习中,特征工程作为机器学习技能的一部分。在这种情况下,需要以可以理解的形式将数据转换并输入到算法中。然而,在训练和测试模型之前,并不知道这些特征的用处,数据挖掘人员往往会陷入开发新特征、重建模型、测量结果的繁杂循环中,直到对结果满意为止。这是一项非常耗时的任务,需要花费大量时间。

穿着黑色衬衫的男人正在弹吉他
这个图像的下边的标题是由神经网络生成的,它与我们想象这个图片的方式非常相似。对于涉及此类复杂解释的案例,必须使用深度学习。这背后的主要原因是超参数。标题图像所需的超参数的数量将非常高,并且在SVM的情况下手动选择这些超参数几乎是不可能的。但是深度神经网络可以通过训练集和学习来自主地进行。


时间:2019-03-23 10:24 来源:未知 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















