2019 深度学习工具汇总
深度学习工具
深度学习的进步也严重依赖于软件基础架构的进展。 软件库如: Torch(2011), Theano(2012), DistBelief(2012), PyLearn2 (2013), Caffe(2013), MXNet (2015) 和 TensorFlow(2015) 都能支持重要的研究项目或商业产品。
如果说深度学习的话,我个人接触是在2015年,这个技术其实被雪藏了很久,在2012年又得到了完全的爆发,至今已经是AI界的主流,那今天就来说说最实际也是接触最多的一个环节,那就是框架,也可以说是工具。
大家所了解的工具不知道有哪些???
今天,我以我使用过的工具来和大家分享,希望你们可以找到自己喜欢的工具,与其一起去“ 炼丹 ”(不知道这个意思的,百度下)嘿嘿!

在我研究生入学以来,接触的深度学习工具一只手就可以数过来,有兴趣的小伙伴可以深入搜索,网上还是有很多不同说法。我接下来根基我自己的实际体验而大家说说深度学习工具这些事。 Matlab
Matlab
刚开始接触深度学习,第一个使用的工具就是:DeepLearnToolbox,一个用于深度学习的Matlab工具箱。 深度学习作为机器学习的一个新领域,它的重点是学习深层次的数据模型,其主要灵感来自于人脑表面的深度分层体系结构,深度学习理论的一个很好的概述是学习人工智能的深层架构。这个工具箱比较简单,当时我就做了一个手写数字和人脸分类(AR人脸数据库)。主要包括如下:
NN :前馈BP神经网络的库
CNN :卷积神经网络的库
DBN :深度置信网络的库
SAE :堆栈自动编码器的库
CAE :卷积自动编码器的库
Util :库中使用的效用函数
Data :数据存储
tests :用来验证工具箱正在工作的测试
案例如下
- rand('state',0)
- cnn.layers = {
- struct('type', 'i') %输入
- struct('type', 'c', 'outputmaps', 6, 'kernelsize', 5) %卷积层
- struct('type', 's', 'scale', 2) %下采样层
- struct('type', 'c', 'outputmaps', 12, 'kernelsize', 5) %卷积层
- struct('type', 's', 'scale', 2) %下采样层
- };
- cnn = cnnsetup(cnn, train_x, train_y); opts.alpha = 1;
- opts.batchsize = 50;
- opts.numepochs = 5;
- cnn = cnntrain(cnn, train_x, train_y, opts); save CNN_5 cnn;
- load CNN_5;
- [er, bad] = cnntest(cnn, test_x, test_y); figure; plot(cnn.rL);
- assert(er<0.12, 'Too big error');
运行界面比较单一:
PyTorch
这个Pytorch库的话,其实我没怎么用,就是随便试玩了下,个人感觉还是不要碰了,没啥意思,我接下来也就简单聊一下。 他是一个基于Python的科学计算包,目标用户有两类。一类是 为了使用GPU来替代numpy;另一类是一个深度学习援救平台:提供最大的灵活性和速度。

以深度学习来说,可以使用 torch.nn 包来构建神经网络。已知道autograd包,nn包依赖autograd包来定义模型并求导。一个nn.Module包含各个层和一个faward(input)方法,该方法返回output。
案例如下
- import torch from torch.autograd
- import Variable import torch.nn
- import torch.nn.functional as F
- class Net(nn.Module):
- def __init__(self):
- super(Net, self).__init__()
- # 1 input image channel, 6 output channels, 5*5 square convolution
- # kernel
- self.conv1 = nn.Conv2d(1, 6, 5)
- self.conv2 = nn.Conv2d(6, 16, 5)
- # an affine operation: y = Wx + b
- self.fc1 = nn.Linear(16 * 5 * 5, 120)
- self.fc2 = nn.Linear(120, 84)
- self.fc3 = nn.Linear(84, 10)
- def forward(self, x):
- # max pooling over a (2, 2) window
- x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
- # If size is a square you can only specify a single number
- x = F.max_pool2d(F.relu(self.conv2(x)), 2)
- x = x.view(-1, self.num_flat_features(x))
- x = F.relu(self.fc1(x))
- x = F.relu(self.fc2(x))
- x = self.fc3(x)
- return x
- def num_flat_features(self, x):
- size = x.size()[1:]
- # all dimensions except the batch dimension
- num_features = 1
- for s in size:
- num_features *= s
- return num_features
- net = Net()
- print(net)
具体操作和细节过程,有兴趣的可以抽空去玩玩!
Caffe
Caffe的作者为UC Berkeley大学的贾扬清。Caffe是一个c++/CUDA架构,支持命令行、Python、Matlab接口,可以在CPU/GPU上运行。

深度学习不断在发展,其对应的实验工具也随着得到了大家的重视。Caffe就是现在流行的深度学习框架之一,工具内已经提前提供了模板,也就是该工具有现成的编程框架,而且可以与现状流行的图形计算GPU联合使用,加快网络训练的速度,流行的神经网络框架算法都可以在Caffe中运行,而且可以自己设置框架,因为Caffe已经提前就做好了各结构的定义,研究学者也可以根据自己的设计需求去进行相应的添加,设计出新的深度学习框架去完成所需的任务。
Caffe框架中,主要就是 Blobs , Layers 和 Nets 三大类结构,而且由于是事前定义好的结构,所以在使用该框架的时候是不可以更改。
Blobs
Blob是Caffe框架中的一个主要结构,其为包装器,在使用Caffe框架时,数据都要被设置成格式,只有这样的数据格式才能在Caffe框架中进行执行和处理。并且在Caffe设计时,很多函数和类都提前设计好了,在执行的过程中是不可以修改其结构,否则将无法调用其中的函数,导致网络训练的失败。
Blob的格式主要由Number,Channel,Height和Width四个元素组成,如果在进行图像处理,则表示图像通道(一般彩色图像为3通道的数据,Height和Width就表示输入数据的尺寸。而对于的元素,其主要体现在训练过程中,因为训练的时候需要选择一次性输入多少数据,就是一次输入数据的数量,通常称之为Batch。这种训练方式也可以大大缓解内存的不足。
Layers
Layers是Caffe框架中网络构成的重要结构之一,网络的构成就是因为Layers的作用,通过接收输入和输出数据,最后通过内部的计算输出。Caffe在使用网络层的时候,其定义方式特别简单明了,大致都分为三个小步骤,如下: 1)建立网络层,且建立层之间的连接关系,可以通过随机初始化的操作,去对一些网络层的变量进行初始化; 2)网络训练过程中,首先计算前向传播,在改过过程中Layers接受上一层的输出数据作为本次的输入数据,最后通过内部 的计算进行输出。 3)前向传播后,由于得到的结果与期望相差较大,通过之前提及到的反向传播来进行计算去调整网络的参数值,以达到最 优值,并且在反向传播计算时,Layers会把每次计算的梯度值存放在该层中。
Nets
之前介绍的Layers就是Nets的一个子元素,通过多种Layers的组合连接得到整个Nets,在该结构中,Nets定义了网络的各 Layers、Input和Output。
例如Caffe定义中最基本的隐层网络,其定义如下:
- name: “LogReg”
- layers {
- name: “mnist”
- type: DATA
- top: “data”
- top: “label”
- data_param {
- source: “input_leveldb”
- batch_size: 64
- }}
- layers {
- name: “ip”
- type: INNER_PRODUCT
- bottom: “data”
- top: “ip”
- inner_product_param {
- num_output: 2
- }}
- layers {
- name: “loss”
- type: SOFTMAX_LOSS
- bottom: “ip”
- bottom: “label”
- top: “loss”
- }
Caffe优势
-
Caffe作为一个开源的框架,其表达式的结构得到很多研究学者的喜爱,因为其可以鼓励更过的人去进行创新、修改完善及实际应用。在框架中,网络的模型、设计和优化过程都是指令来调用和执行,不像其他工具框架,需要通过硬编码来获取相应的操作。而且在Caffe应用中可以使用CPU中央处理器和GPU图形图像处理器进行学习,而且两个处理器可以来回切换,只要通过在GPU机器上设置一个指令就可以,而且GPU的使用在普遍增加,因为其可以给予网络的训练速度,减少训练的时间,提高网络的训练效率,进一步对网络进行微调。
-
开源框架的好处就是可以被大家扩展,所以Caffe促进了其自身的开发,在贾扬清创建Caffe之后,仅在一年时间里,就已经有上千位研究爱好者参加了开发,而且他们都做出了很大的贡献才会有现在完善的深度学习框架,现在该框架还在不断进行优化和发展。
-
上手快,因为网络模型不需要用代码的形式表现出来,只需要通过文本形式表现,并且Caffe框架中已定义了该模型。
-
Caffe的出现特征事宜学校机构的实验室和工业相关部门的使用。因为Caffe与英伟达GPU合用,可以达到很高的效率。曾有过一个实验,用一台英伟达生产的K40图形图像处理器去训练图片,一天下来可以执行六千万以上的训练图像。现在其表现的速度,在常用的深度学习框架中,可以算得上最快的框架之一。
-
方便快速地使用到其他任务重,因为Caffe已经定义了各层的类型,只需通过简单调用来定义自己设计的网络模型即可。
TF
Google在2011年推出人工深度学习系统——DistBelief。通过DistBelief,Google能够扫描数据中心数以千计的核心,并建立更大的神经网络。这个系统将Google应用中的语音识别率提高了25%,以及在Google Photos中建立了图片搜索,并驱动了Google的图片字幕匹配实验。DistBelief还存在不少不足和限制。它很难被设置,和Google内部的基础设施联系也过于紧密,这导致研究代码机会不可能分享。

针对以上问题,Google在2015年Google Research Blog宣布推出新一代人工智能学习系统——TensorFlow。
TensorFlow是一个异构分布式系统上的大规模机器学习框架,移植性好(小到移动设备如手机,大到大规模集群,都能支持),支持多种深度学习模型。根据Google说法,TensorFlow是综合的、灵活的、可移植的、易用的,更为关键的,它是开源的。同时,TensorFlow的速度相比前代DistBelief有了不小的提升,在一些跑分测试中,TensorFlow的得分是第一代系统的两倍。
尽管如此,TensorFlow的效率仍然比不过其他大部分开源框架。不过,随着TensorFlow源码逐步开放,对新硬件、新设备、新的加速如cuDNN的支持力度不断提升,其成为目前极具潜力的深度学习。
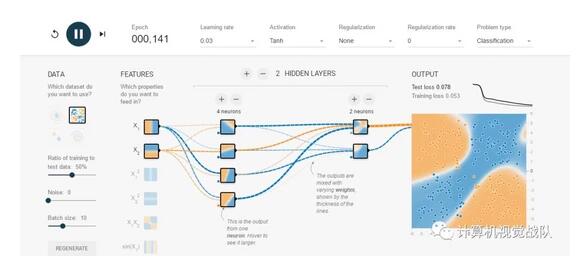
有兴趣可以体验下PlayGround,其是一个用于教学目的的简单神经网络的在线演示、实验的图形化平台,非常强大地可视化了神经网络的训练过程。使用它可以在浏览器里训练神经网络,对 Tensorflow有一个感性的认识。
TF缺点
-
TensorFlow 的每个计算流都必须构造为一个静态图,且缺乏符号性循环(symbolic loops),这会带来一些计算困难;
-
没有对视频识别很有用的三维卷积(3-D convolution);
-
尽管 TensorFlow 现在比起始版本快了 58 倍,但在执行性能方面依然落后于竞争对手。
今天就到此位置吧,感觉讲的有点多,但是又不是很深入,有机会来一次深度学习工具专题,我们大家一起慢慢聊!

时间:2019-03-23 10:17 来源:未知 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















