基于深度强化学习的新闻推荐模型 DRN
文章作者:杨镒铭 滴滴出行 高级算法工程师
内容来源:记录广告、推荐等方面的模型积累 @知乎专栏
出品社区:DataFun
注:欢迎后台留言投稿「行知」专栏文章。
在深度学习大潮之后,搜索推荐等领域模型该如何升级迭代呢?强化学习在游戏等领域大放异彩,那是否可将强化学习应用到搜索推荐领域呢?推荐搜索问题往往也可看作是序列决策的问题,引入强化学习的思想来实现长期回报最大的想法也是很自然的,事实上在工业界已有相关探索。因此后面将会写一个系列来介绍近期强化学习在搜索推荐业务上的应用。
本次将介绍第一篇,发表在 WWW2018 上,链接为:
http://www.personal.psu.edu/~gjz5038/paper/www2018_reinforceRec/www2018_reinforceRec.pdf。
▪ Introduction
在新闻推荐业务中,虽然很多机器学习模型有较好的建模能力,但是仍有如下问题:
- 新闻推荐中的动态变化难以处理
动态变化表现在两种层次:一个是新闻的时效性,可能会很快过时;另一个是用户的浏览兴趣,随着时间会动态变化。虽然通过在线学习的方式可以捕获新闻特征和用户兴趣的动态变化,但是这些方法只注重短期回报,并未考虑长期回报。
- 仅使用是否点击作为用户反馈
现有方法只考虑是否点击或者打分来作为用户的反馈。作者提出引入用户返回 APP 的时间,因为该指标也反映了用户对推荐的满意度。
- 现有方法推荐结果重复较多
现有方法倾向于给用户推荐相似 item,而这将降低用户对相似 topic 的兴趣,也不利于探索用户新的兴趣。
▪ 所提模型
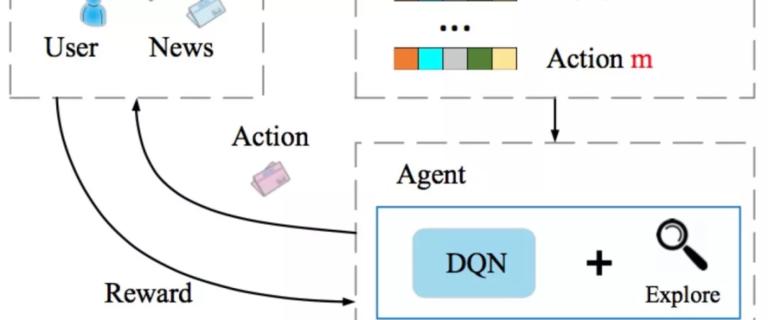
为了解决上述问题,作者提出了基于 DQN 的框架来进行实时新闻推荐。具体来说,将用户和 news 的特征表示输入给 Deep Q-Network 来预测可能的 reward,也就是用户点击 news 的概率。该框架通过 DQN 的在线更新来处理新闻推荐中的动态变化,并注重长期回报。框架除了用户 click 的反馈之外,引入了 user activeness(用户在一次推荐后返回到 APP 的频率)作为回报。另外为避免传统的 exploration 策略比如 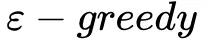 或 UCB 可能带来的不准确推荐,作者引入 Dueling Bandit Gradient Descent 策略来改善推荐的多样性。
或 UCB 可能带来的不准确推荐,作者引入 Dueling Bandit Gradient Descent 策略来改善推荐的多样性。
- 模型框架
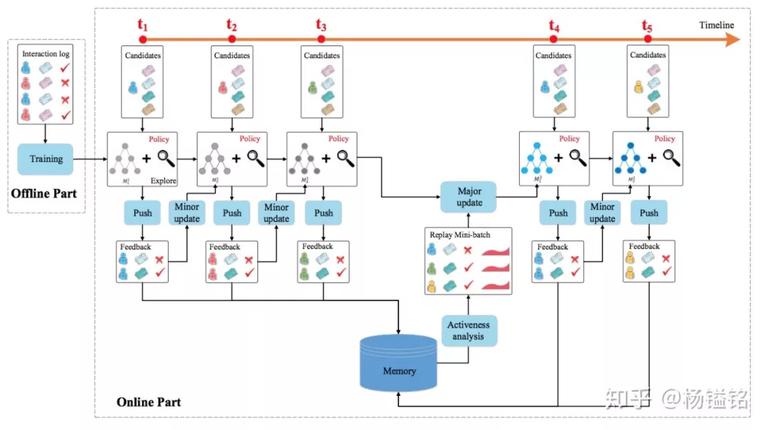
模型框架
如下图,整体框架包括离线和在线两部分。所需信息主要是从 news 和 user 中抽取 4 类特征,Deep Q-network 则根据这 4 类特征来预测 reward(用户 click 和 activeness 的结合)。离线部分主要是使用离线的用户点击日志来训练,给点击和未点击的 news 不同的奖励,然后训练一个 Q 网络。这部分和论文作者聊过,其实就是一个监督学习的过程。在线部分涉及推荐 agent 和用户的交互过程,按下面的流程对网络进行更新:
-
Push:每当用户发送一个请求,推荐智能体 G 会根据用户和候选 news 集合的特征表示,综合 exploitation 和 exploration 生成 top-k 的 news 列表 L。
-
FeedBack:用户针对接受的列表 L 将会有点击行为。
-
Minor Update:在每个时间戳后,根据 user、news 列表 L 和反馈 B,智能体 G 将会比较 exploitation network Q 和 exploration network
 的推荐效果来更新模型。如果
的推荐效果来更新模型。如果 给出的效果更好,则将 Q 往
给出的效果更好,则将 Q 往 的方向更新,否则 Q 保持不变。每次推荐发生之后都会进行 Minor update。
的方向更新,否则 Q 保持不变。每次推荐发生之后都会进行 Minor update。 -
Major Update:在一个特定时期
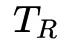 后,智能体 G 将使用用户反馈 B 和用户 activeness 来更新网络 Q。这里使用经验回放来实现,智能体 G 保存近期历史 click 和用户 activeness 记录,当触发 Major Update 时,智能体随机选择一个 batch 来更新模型。Major Update 通常间隔比如一个小时来进行,在这段时间会收集很多次的展现和反馈的记录。
后,智能体 G 将使用用户反馈 B 和用户 activeness 来更新网络 Q。这里使用经验回放来实现,智能体 G 保存近期历史 click 和用户 activeness 记录,当触发 Major Update 时,智能体随机选择一个 batch 来更新模型。Major Update 通常间隔比如一个小时来进行,在这段时间会收集很多次的展现和反馈的记录。
- 特征构造
针对预测用户是否会点击某个 news,文中构造了 4 大类特征,包括 News Feature、User Feature、User News Feature 和 Context Feature。篇幅有限,这里不再细讲。
- 深度强化推荐
考虑到新闻推荐中的动态变化和长期回报,文章使用 DQN 来建模用户是否点击某一 news 的概率,而这一概率也是智能体能得到的奖励即 reward。文章对 total reward 进行如下形式化:

其中状态 state 表示成 context feature 和 user feature,而动作 action 表示成 news feature 和 user-news 交互特征,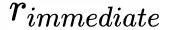 和
和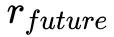 别表示当前情况下奖励(也就是用户是否点击新闻)和未来回报。给定当前状态 s、动作 a 和时间戳 t,使用 DDQN 来对 total reward 进行预测:
别表示当前情况下奖励(也就是用户是否点击新闻)和未来回报。给定当前状态 s、动作 a 和时间戳 t,使用 DDQN 来对 total reward 进行预测:

其中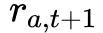 表示采取动作 a 的立即回报,
表示采取动作 a 的立即回报,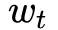 和
和 表示 DQN 中的两个不同参数集合。首先给定候选动作集,在参数
表示 DQN 中的两个不同参数集合。首先给定候选动作集,在参数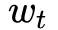 的设置下根据长期回报最大选择出动作
的设置下根据长期回报最大选择出动作 。然后估计
。然后估计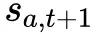 采取动作
采取动作 所得到的长期回报。每几轮迭代之后
所得到的长期回报。每几轮迭代之后 和
和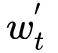 将互换。DDQN 可解决 Q 值过高估计的问题。通过这个过程,模型可兼顾 total reward 进行决策。
将互换。DDQN 可解决 Q 值过高估计的问题。通过这个过程,模型可兼顾 total reward 进行决策。
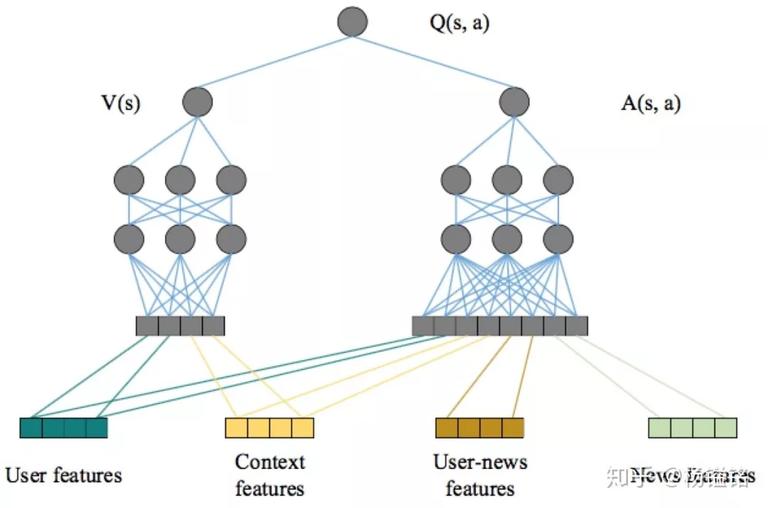
Q network 如上图所示。底层将四类特征输入到网络中,user feature 和 context feature 作为 state feature,而 user-news feature 和 news feature 作为 action feature。一方面,在一个特定状态采用某个动作的 reward 和所有特征均有关。另一方面,reward 受 user 本身特征的影响要大于只用用户状态和 context 特征。基于此,文中类似 Dueling Network 将 Q 函数分解成 V(s) 和 A(s,a),其中 V(s) 只受 state 特征影响,而 A(s,a) 则会受到 state 特征和 action 特征影响。
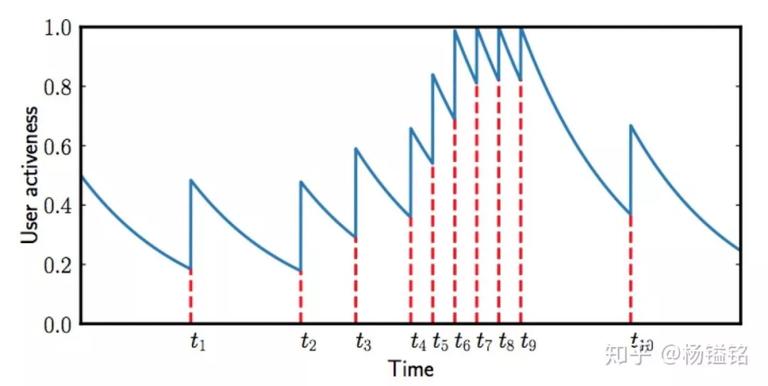
- User activeness
文中采用留存模型来对用户 activeness 来建模。时间 t 后用户返回 App 的概率定义为  ,其中一个生命周期
,其中一个生命周期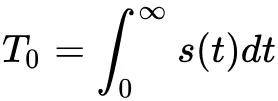 (文中
(文中 设为一天)。每次检测到一个用户返回 App,我们将使得
设为一天)。每次检测到一个用户返回 App,我们将使得 。如下图,开始时
。如下图,开始时 ,然后 activeness 衰减,在
,然后 activeness 衰减,在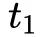 时刻用户返回 App,使得 activeness 增加
时刻用户返回 App,使得 activeness 增加 ,后续以此类推。整个过程保证活跃度保持在 0-1 之间,如果超过 1 的话直接截断成 1。这里
,后续以此类推。整个过程保证活跃度保持在 0-1 之间,如果超过 1 的话直接截断成 1。这里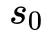 、
、 等值的设定都是数据中的真实用户行为模式确定的。
等值的设定都是数据中的真实用户行为模式确定的。
- Exploration
常见的探索方法包括 和 UCB 等,其中前者会随机推荐一些新 item,后者会选择一些未探索充分的 item,这些都会导致推荐效果有一定下降。因此作者使用了 Dueling Bandit Gradient Descent 算法 (最早来自 online LTR 领域) 来进行 exploration。智能体 G 使用当前网络 Q 产出推荐列表 L,并使用 explore 网络
和 UCB 等,其中前者会随机推荐一些新 item,后者会选择一些未探索充分的 item,这些都会导致推荐效果有一定下降。因此作者使用了 Dueling Bandit Gradient Descent 算法 (最早来自 online LTR 领域) 来进行 exploration。智能体 G 使用当前网络 Q 产出推荐列表 L,并使用 explore 网络 产生另一个推荐列表
产生另一个推荐列表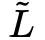 。
。 的参数可以通过 Q 的参数基础上增加微小扰动得到。然后使用 L 和
的参数可以通过 Q 的参数基础上增加微小扰动得到。然后使用 L 和 进行 interleave 来产生一个融合的列表
进行 interleave 来产生一个融合的列表  。如果探索网络
。如果探索网络 产生的 item 得到更好的反馈,则智能体 G 将网络 Q 向
产生的 item 得到更好的反馈,则智能体 G 将网络 Q 向 的方向更新,表示为
的方向更新,表示为 ,否则 Q 的参数保持不变。
,否则 Q 的参数保持不变。

▪ 总结
这篇文章结合了一些已有的 DQN 及改进实现了强化学习在新闻推荐上的应用,其中的框架设计和 exploration 机制值得相关的业务场景进行借鉴。
作者介绍:
杨镒铭,滴滴出行高级算法工程师,硕士毕业于中国科学技术大学,知乎「记录广告、推荐等方面的模型积累」专栏作者。

时间:2019-03-15 23:28 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















