读“懂”用户找房需求:贝壳语义解

1. 引言
自然语言理解(natural language understanding,NLU)是人工智能的核心难题之一,同时也是文本和语音搜索的核心。本文主要阐述了 NLU 在贝壳找房中的探索和实践,以及如何为贝壳的搜索场景赋能。在文章开始之前我们先来道一道 NLU 在贝壳房源搜索中的任务和实现难点。
贝壳房源搜索场景主要有 C 端搜索以及语音找房,而根据用户的历史搜索数据分析,在贝壳找房搜索中以地理位置搜索、房屋属性搜索以及地理位置与房屋属性的组合搜索为主,NLU 的主要任务是从用户搜索 query 中结构化出用户的搜索条件,为后续的房源检索提供精准搜索支持。
那么在房源搜索中 NLU 实现的难点是什么呢?
- 鲁棒性
用户搜索是复杂多样的,比如多字、少字、错字、别字、别称、逆序等,都给用户搜索意图的识别带来了很大困难。
- 精确性
精准的搜索意图识别对于下游产品的使用逻辑有着重要的影响,而在我们的业务场景中需要识别的类别有 50 类之多。
- 歧义性
语言的歧义性,不管在开放域还是在房产领域都不可避免,比如:朝阳,在北京有朝阳区,在沈阳有朝阳县。
2. 架构设计
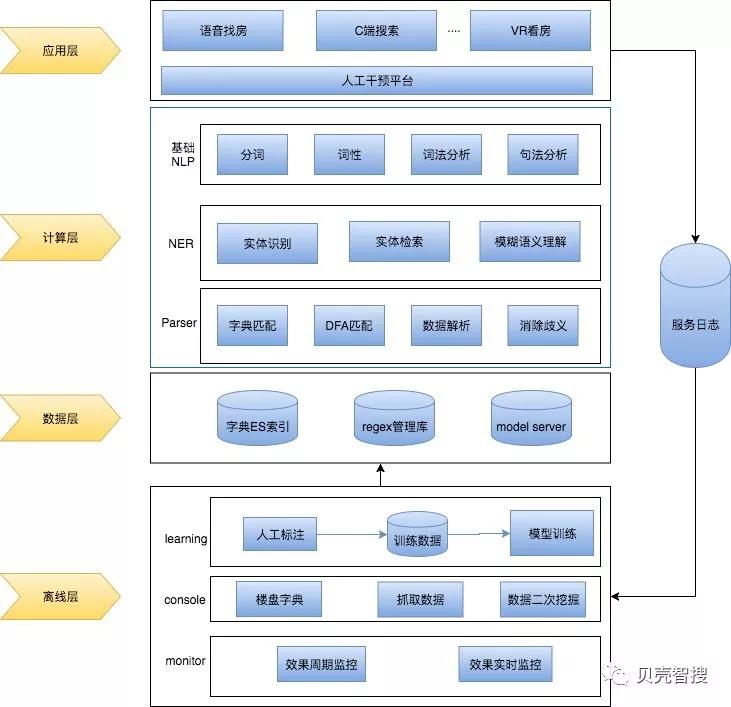
如上图所示,整体架构可以分为四个层面,分别是应用层、计算层、数据层和离线层。
2.1 应用层
应用层分成两个部分一部分是服务所面向的业务方,比如:语音找房、C 端搜索以及 VR 看房。语音找房和 C 端搜索的应用场景非常相近,唯一不同的是语音找房中需要通过 ASR 将用户的语音输入转换为文本再进行语义解析,在后端实现中我们结合公司的业务特点,将服务抽象成了二手、新房以及租赁等场景,不同的业务方需求都是基于底层业务模块的组装,从而实现服务的复用性;VR 看房更多的是指令集的解析,比如看看卧室、去卫生间等。
另一部分是人工干预平台,人工干预平台可以保证对输入输出结果的实时干预,从而达到对用户反馈 badcase 的高效响应,也为后端算法和服务迭代争取了时间。
2.2 计算层
计算层是服务的核心,主要包含了基础 NLP 模块,NER(命名实体识别)模块,以及 Parser 模块。基础 NLP 模块提供基础的分词、词性标注、词法以及句法分析等基础功能,我们这里着重介绍 NER 模块和 Parser 模块。
NER 模块包含了三个部分:命名实体识别、实体检索以及模糊语义理解,这么设计是因为,从我们的数据分析来看,贝壳的找房搜索中关于房屋属性词的搜索,搜索词特征都相对比较明显比如两室一厅、精装修、loft 等等,通过规则的形式就可以达到比较不错的效果,比较困难的是对地理位置类型的识别,有的地理位置类型之间并没有明显的特征可以区分,比如:上地(商圈)、亚运新新家园(社区)、亚运新新家园林澜园(小区),如果用 NER 直接识别实体的类别是商圈、小区还是社区等精度往往无法达到业务的需求,所以这里引入了检索的思路,通过对检索结果的召回排序,取 topn 结果的类型作为对实体类型的推断。命名实体识别模块的任务是从搜索 query 中识别出其中的地理位置实体,比如:五道口附近两室一厅,从中识别出“五道口”是一个地址实体即可,然后基于五道口从索引库中检索出与五道口文本相似的实体名称,然后将召回的候选实体进行排序,将预期的实体排在 topn 的位置,这样做不仅可以做到识别的目的还对实体有一定的纠错能力。具体实现在“算法及实现”部分会详细介绍。
Paser 模块主要负责对非地址类型进行解析、数值转换以及消歧,这里比较困难的是服务中需要维护大量的正则表达式,如何高效的对多个正则进行匹配,服务里已经有 300 个正则左右, 这里我们引入了动态 dfa 算法, 可以实现正则的快速匹配,耗时不到 1ms。
2.3 数据层
数据层主要包含三个部分:
-
regex 管理库:Parser 模块需要用到的正则集合
-
字典 ES 索引:对所有地理位置字典构建索引,当识别出来命名实体后,可以从 ES 索引中检索出候选的地理实体。
-
model server:模型服务器,用于实现 BiLSTM-CRF 模型的管理和 inference。这里我们引入了 tensorflow serving(TFS)平台,因为我们的服务是基于 C 开发的,而模型是基于 tensorflow 训练的,tensorflow C 库的提取以及模型的更新和版本控制都比较困难,所以在这里引入 google 开源的 TFS,后续会有专门的文章介绍 TFS 在我们项目中的具体实践。
2.4 离线层
离线层也分为三大模块:
-
learning:我们定期会对日志数据进行回收和效果评估,经人工标注后回流到训练数据中,重新进行模型训练以保证 NER 模型预测效果的动态更新。
-
console:也就是内部的数据中台,数据中台是项目中所有用到数据的唯一接入源,数据中台主要负责公司楼盘字典数据以及抓取数据的统一、规范以及二次挖掘以为下游业务提供有力支撑。
-
monitor:monitor 模块用于对线上解析效果的实时监控、算法效果的定期评估,每次定期评估的结果也是算法下一期迭代的重要依据。
3. 算法及实现
3.1 命名实体识别(NER)
NER 是房源搜索语义解析的核心算法,因为用户数据的复杂多样,比如:多字、少字、错字、别字等问题,基于规则的方式往往无法解决这类,从数据分析来看这部分数据在现有的 query 搜索中占比在 20% 左右,而在语音找房需求中因为 ASR 的原因这一部分问题的占比会进一步的扩大。下面简单阐述下我们项目中在 NER 识别中的一些实践经验。
- 数据
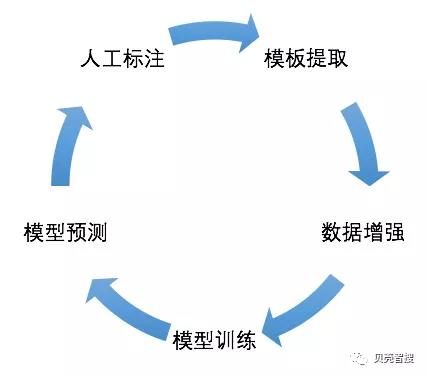
训练数据的获取一直是 NER 识别中比较消耗人力的部分,为了减少人工标注成本我们采用了半监督的方式进行语料的收集, 整个语料的获取流程如下循环图所示。启动阶段可以通过规则的方式提取一批模板,然后用已有的同类数据对模板进行增强处理,比如:提取了”(DISRICT)两室一厅“的模板,那么就可以拿字典中所有的行政区类型进行模板的增强,基于增强后的数据训练模型,用训练后的模型对语料中的高频语料进行预测,这样只需要人工标注对错就行,对于预测错的标注出正确的模板,这样循环迭代 5 次左右,模型的预测精度已经达到了 90% 以上。
- 算法
通过对 CRF 算法与 BiLSTM-CRF 的对比实验,我们最终选择了 BiLSTM-CRF 算法,最终的识别精确率 92.66%,召回率 93.76%,F1-Score93.21%,基本满足我们的业务需求。当然在具体实现中还有更多的细节考虑,敬请期待后续专门介绍 NER 的文章。
3.2 候选实体检索
基于 NER 结果进行候选实体 ES 检索这里我们还是踩了不少坑的。
- 一号坑:
为了能够有效的召回所有的候选集一开始采用了基于单字和单音的方式召回,比如:五道口两室一厅这个问题,NER 识别出五道口这个实体后,我们会召回所有包含“五”、“道”、“口”、“wu”、“dao”、“kou”的候选最后发现这样召回的候选集太大了,而且也没有利用搜索实体原始的序列信息,比如如果候选是“五道庙” 和“五里口”这两个候选的 ES 打分是没有区别的。
- 二号坑:
经过对单字和单音召回问题的分析我们引入了 ngram 的召回方式,具体做法就是在构建 ES 索引时构建了候选字典字和音 1 到 30 的 ngram 索引,召回时也会把实体也按照 ngram 的方式进行拆分,ngram 长度越大对应的 boost 权重也越大,比如同样是“五道口”,按照 ngram 的形式会拆分成“五”、”道“、”口“、”五道”、“道口”、“wu”、“dao”、”kou”、“wudao”、”daokou" 按照这样的方式去召回既可以有效的召回候选,也可以利用请求实体的序列信息。看上去方案很完美,实际效果也是惊喜连连,因为,ES 响应时间也没有让我失望,平均达到了要求响应时间的 150%,就只能面带微笑舍弃这种方案。
- 三号坑:
对问题继续分析,1)大部分情况下拼音召回候选集是大于等于字召回,所以我们可以只用拼音召回不用汉字召回; 2)我们想要使用的是序列信息,那么 bigram 其实已经够了,没有必要所有的 gram 信息都参与计算。所以最终线上我们采用了基于 bigram 拼音的候选实体召回方案,比如:”五道口” , 就用“wudao”、“daokou”进行召回,既能减少召回数量,召回质量也满足需求,这种方案当然不是最优的比如,如果实体只有两个字,其中一个字拼音输错了,实体有三个字中间字的拼音输入错了,基于这种方式都是不可召回的,也算是一种性能和质量的一种折中吧。
3.3 模糊语义理解
如何能够根据检索的候选实体反向推断请求实体的类型就是模糊语义理解要做的事情,在这里我们通过语言模型、文本相似性、拼音相似性、热度、地理位置、文本位置等进行综合排序。
相似性计算时我们同时考虑了 Jaccard 距离和编辑距离,这么做也是结合我们的数据特点,在用户输入中有一部分的实体会出现逆序的情况,而 jaccard 的无序性和鲁棒性正好可以有效缓解这一部分问题;考虑地理位置是因为地理位置可以很好的辅助消歧,比如:搜索朝阳,如果是在北京搜索有很大的概率可以推断用户想要搜索的是朝阳区,如果在沈阳搜索用户可能更想要的结果是朝阳县;文本位置特征针对的是文本在候选实体中的位置权重,比如前缀包含、后缀包含等。
3.4 效果评测及优化
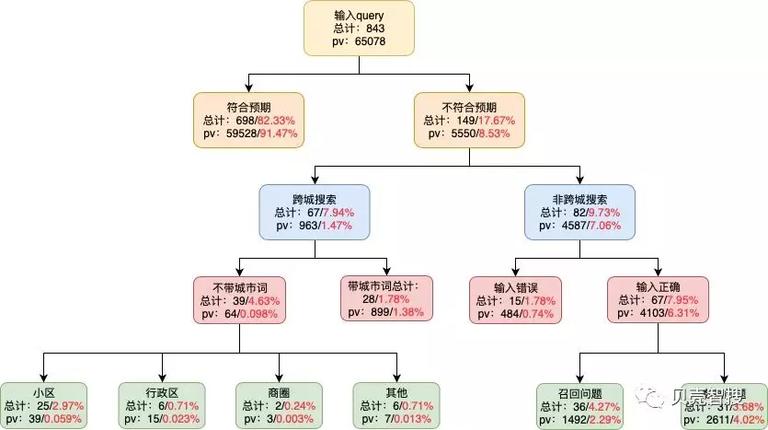
周期性的效果评测可以从指标上反应,算法的调优效果,更重要的是可以从评测中发现问题,确定下一阶段算法的优化重点。如下是我们算法迭代过程中其中的一版算法分析漏斗图,从漏斗图可以直观的看到算法下一阶段需要解决的问题是跨城识别与算法使用策略。
4. 小结
本文伊始阐述了 NLU 在房源搜索中的任务和难点,然后从架构设计、算法及实现方案角度描述了我们的具体实践方案。最后想说的在实际系统实现中算法和规则应该是同等重要的,算法带来的长期收益可能会更高但是投入成本和迭代周期也更长,规则可以快速解决问题,迭代快,对于一些特征显著或者线上需要快速解决的 case,用规则无疑是最快速有效的选择。
希望此文对读者有些许启发,感谢阅读。

时间:2019-03-10 19:32 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















