NLP 新秀 : BERT 的优雅解读
作为 2018 年自然语言处理领域的新秀,BERT 做到了过去几年 NLP 重大进展的集大成,一出场就技惊四座碾压竞争对手,刷新了 11 项 NLP 测试的最高纪录,甚至超越了人类的表现,相信会是未来 NLP 研究和工业应用最主流的语言模型之一。本文尝试由浅入深,为各位看客带来优雅的 BERT 解读。
NLP 背景:BERT 的应用舞台
NLP:Natural Language Process,自然语言处理,是计算机科学、信息工程以及人工智能的子领域,专注于人机交互,特别是大规模自然语言数据的处理和分析。
除了 OCR、语音识别,自然语言处理有四大类常见的任务。第一类任务:序列标注,譬如命名实体识别、语义标注、词性标注、分词等;第二类任务:分类任务,譬如文本分类、情感分析等;第三类任务:句对关系判断,譬如自然语言推理、问答 QA、文本语义相似性等;第四类任务:生成式任务,譬如机器翻译、文本摘要、写诗造句等。
GLUE benchmark:General Language Understanding Evaluation benchmark,通用语言理解评估基准,用于测试模型在广泛自然语言理解任务中的鲁棒性。
BERT 刷新了 GLUE benchmark 的 11 项测试任务最高记录,这 11 项测试任务可以简单分为 3 类。序列标注类:命名实体识别 CoNNL 2003 NER;单句分类类:单句情感分类 SST-2、单句语法正确性分析 CoLA;句对关系判断类:句对 entailment 关系识别 MNLI 和 RTE、自然语言推理 WNLI、问答对是否包含正确答案 QNLI、句对文本语义相似 STS-B、句对语义相等分析 QQP 和 MRPC、问答任务 SQuAD v1.1。虽然论文中没有提及生成式任务,BERT 核心的特征提取器源于谷歌针对机器翻译问题所提出的新网络框架 Transformer,本身就适用于生成式任务。
语言模型的更迭:BERT 之集大成
LM:Language Model,语言模型,一串词序列的概率分布,通过概率模型来表示文本语义。
语言模型有什么作用?通过语言模型,可以量化地衡量一段文本存在的可能性。对于一段长度为 n 的文本,文本里每个单词都有上文预测该单词的过程,所有单词的概率乘积便可以用来评估文本。在实践中,如果文本很长,P(wi|context(wi)) 的估算会很困难,因此有了简化版:N 元模型。在 N 元模型中,通过对当前词的前 N 个词进行计算来估算该词的条件概率。对于 N 元模型,常用的有 unigram、bigram 和 trigram,N 越大,越容易出现数据稀疏问题,估算结果越不准。此外,N 元模型没法解决一词多义和一义多词问题。
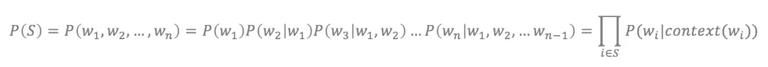 为了解决 N 元模型估算概率时的数据稀疏问题,研究者提出了神经网络语言模型,代表作有 2003 年 Bengio 等提出了的 NNLM,但效果并不吸引人,足足沉寂了十年。在另一计算机科学领域机器视觉,深度学习混得风生水起,特别值得一提的是预训练处理,典型代表:基于 ImageNet 预训练的 Fine-Tuning 模型。图像领域的预处理跟现在 NLP 领域的预训练处理思路相似,基于大规模图像训练数据集,利用神经网络预先训练,将训练好的网络参数保存。当有新的任务时,采用相同的网络结构,加载预训练的网络参数初始化,基于新任务的数据训练模型,Frozen 或者 Fine-Tuning。Frozen 指底层加载的预训练网络参数在新任务训练过程中不变,Fine-Tuning 指底层加载的预训练网络参数会随着新任务训练过程不断调整以适应当前任务。深度学习是适用于大规模数据,数据量少训练出来的神经网络模型效果并没有那么好。所以,预训练带来的好处非常明显,新任务即使训练数据集很小,基于预训练结果,也能训练出不错的效果。
为了解决 N 元模型估算概率时的数据稀疏问题,研究者提出了神经网络语言模型,代表作有 2003 年 Bengio 等提出了的 NNLM,但效果并不吸引人,足足沉寂了十年。在另一计算机科学领域机器视觉,深度学习混得风生水起,特别值得一提的是预训练处理,典型代表:基于 ImageNet 预训练的 Fine-Tuning 模型。图像领域的预处理跟现在 NLP 领域的预训练处理思路相似,基于大规模图像训练数据集,利用神经网络预先训练,将训练好的网络参数保存。当有新的任务时,采用相同的网络结构,加载预训练的网络参数初始化,基于新任务的数据训练模型,Frozen 或者 Fine-Tuning。Frozen 指底层加载的预训练网络参数在新任务训练过程中不变,Fine-Tuning 指底层加载的预训练网络参数会随着新任务训练过程不断调整以适应当前任务。深度学习是适用于大规模数据,数据量少训练出来的神经网络模型效果并没有那么好。所以,预训练带来的好处非常明显,新任务即使训练数据集很小,基于预训练结果,也能训练出不错的效果。
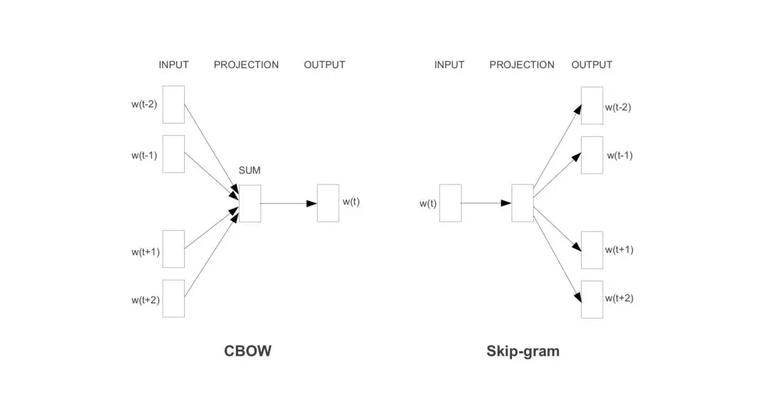
深度学习预训练在图像领域的成果,吸引研究者探索预训练在 NLP 领域的应用,譬如 Word Embedding。2013 年开始大火的 Word Embedding 工具 Word2Vec,Glove 跟随其后。Word2Vec 有 2 种训练方式:CBOW 和 Skip-gram。CBOW 指抠掉一个词,通过上下文预测该词;Skip-gram 则与 CBOW 相反,通过一个词预测其上下文。不得不说,Word2Vec 的 CBOW 训练方式,跟 BERT“完形填空”的学习思路有异曲同工之妙。
一个单词通过 Word Embedding 表示,很容易找到语义相近的单词,但单一词向量表示,不可避免一词多义问题。于是有了基于上下文表示的 ELMo 和 OpenAI GPT。
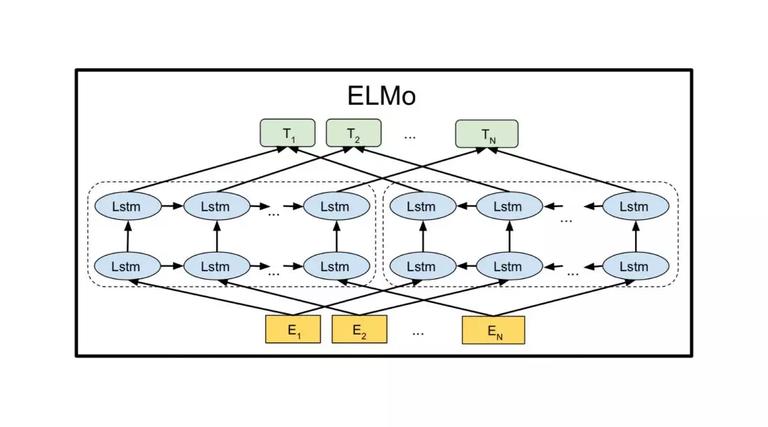
ELMo,Embedding from Language Models,基于上下文对 Word Embedding 动态调整的双向神经网络语言模型。ELMo 采用的是一种“Feature-based Approaches”的预训练模式,分两个阶段:第一阶段采用双层双向的 LSTM 模型进行预训练;第二阶段处理下游任务时,预训练网络中提取出的 Word Embedding 作为新特征添加到下游任务中,通过双层双向 LSTM 模型补充语法语义特征。相比 Word2Vec,ELMo 很好地解决了一词多义问题,在 6 个 NLP 测试任务中取得 SOTA。
Transformer:谷歌提出的新网络结构,这里指 Encoder 特征提取器。LSTM 提取长距离特征有长度限制,而 Transformer 基于 self-Attention 机制,任意单元都会交互,没有长度限制问题,能够更好捕获长距离特征。
GPT,Generative Pre-Training,OpenAI 提出的基于生成式预训练的单向神经网络语言模型。GPT 采用的是一种“Fine-Tuning Approaches”的预训练模式,同样分两个阶段: 第一阶段采用 Transformer 模型通过上文预测的方式进行预训练;第二阶段采用 Fine-Tuning 的模式应用到下游任务。GPT 的效果同样不错,在 9 个 NLP 测试任务中取得 SOTA。不过,GPT 这种单向训练模式,会丢失下文很多信息,在阅读理解这类任务场景就没有双向训练模式那么优秀。

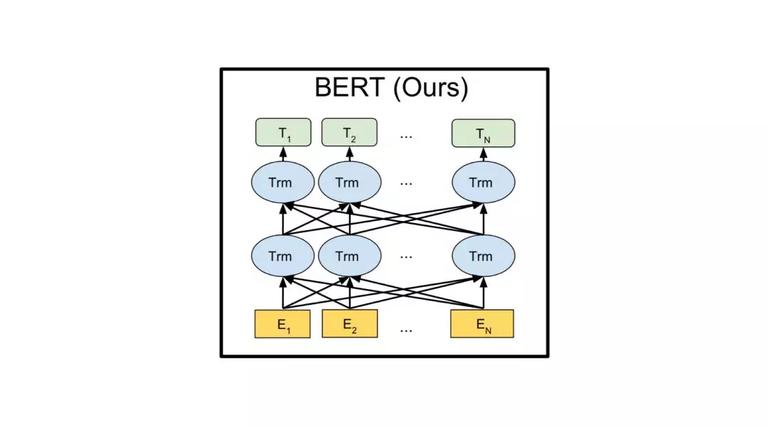
BERT,Bidirectional Encoder Representations from Transformers,基于 Transformer 的双向语言模型。同样,BERT 采用跟 GPT 一样的“Fine-Tuning Approaches”预训练模式,分两个阶段:第一阶段采用双层双向 Transformer 模型通过 MLM 和 NSP 两种策略进行预训练;第二阶段采用 Fine-Tuning 的模式应用到下游任务。有人戏称:Word2Vec + ELMo + GPT = BERT,不过也并无道理,BERT 吸收了这些模型的优点:“完形填空”的学习模式迫使模型更多依赖上下文信息预测单词,赋予了模型一定的纠错能力;Transformer 模型相比 LSTM 模型没有长度限制问题,具备更好的能力捕获上下文信息特征;相比单向训练模式,双向训练模型捕获上下文信息会更加全面;等等。当然,效果才是王道,集大成者 BERT 拿了 11 项 SOTA。
论文解读:BERT 原理
相关论文:
2017 年,谷歌发表《Attention Is All You Need》,提出 Transformer 模型;
2018 年,谷歌发表《BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding》,提出基于 Transformer 的语言模型 BERT。
在未来 NLP 领域的研究和应用,BERT 有两点值得被借鉴:其一,基于 Transformer 编码器作特征提取,结合 MLM&NSP 策略预训练;其二,超大数据规模预训练 Pre-Training+ 具体任务微调训练 Fine-Tuning 的两阶段模式。
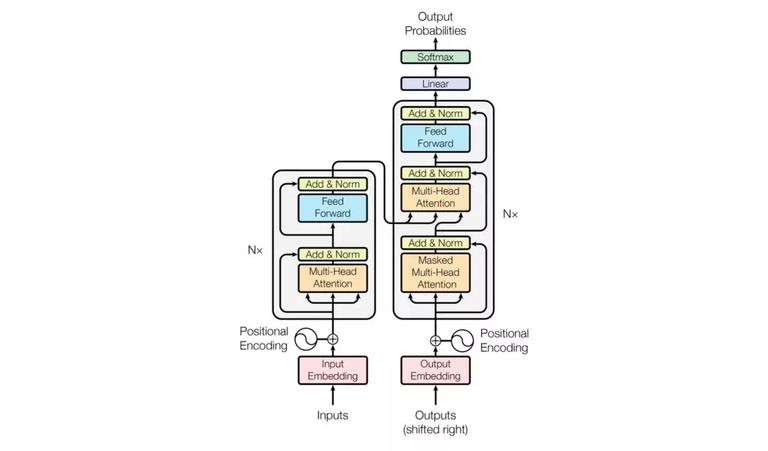
1. 特征提取器
Transformer Encoder,特征提取器,由 Nx 个完全一样的 layer 组成,每个 layer 有 2 个 sub-layer,分别是:Multi-Head Self-Attention 机制、Position-Wise 全连接前向神经网络。对于每个 sub-layer,都添加了 2 个操作:残差连接 Residual Connection 和归一化 Normalization,用公式来表示 sub-layer 的输出结果就是 LayerNorm(x+Sublayer(x))。
Attention Mechanism。为什么要有注意力机制?换句话说,注意力机制有什么好处?类比人类世界,当我们看到一个人走过来,为了识别这个人的身份,眼睛注意力会关注在脸上,除了脸之后的其他区域信息会被暂时无视或不怎么重视。对于语言模型,为了模型能够更加准确地判断,需要对输入的文本提取出关键且重要的信息。怎么做?对输入文本的每个单词赋予不同的权重,携带关键重要信息的单词偏向性地赋予更高的权重。抽象来说,即是:对于输入 Input,有相应的向量 query 和 key-value 对,通过计算 query 和 key 关系的 function,赋予每个 value 不同的权重,最终得到一个正确的向量输出 Output。在 Transformer 编码器里,应用了两个 Attention 单元:Scaled Dot-Product Attention 和 Multi-Head Attention。
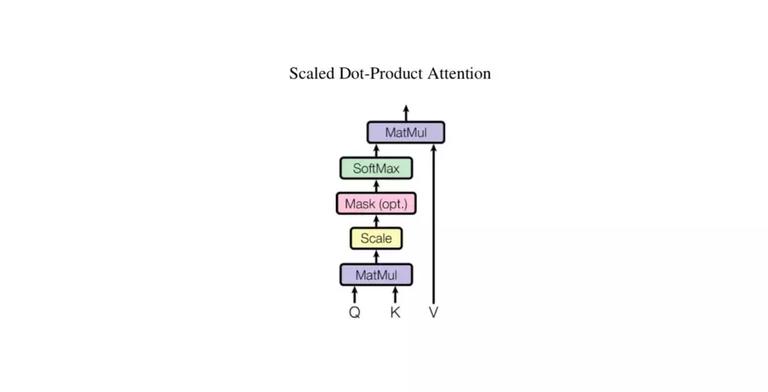
Scaled Dot-Product Attention。Self-Attention 机制是在该单元实现的。对于输入 Input,通过线性变换得到 Q、K、V,然后将 Q 和 K 通过 Dot-Product 相乘计算,得到输入 Input 中词与词之间的依赖关系,再通过尺度变换 Scale、掩码 Mask 和 Softmax 操作,得到 Self-Attention 矩阵,最后跟 V 进行 Dot-Product 相乘计算。
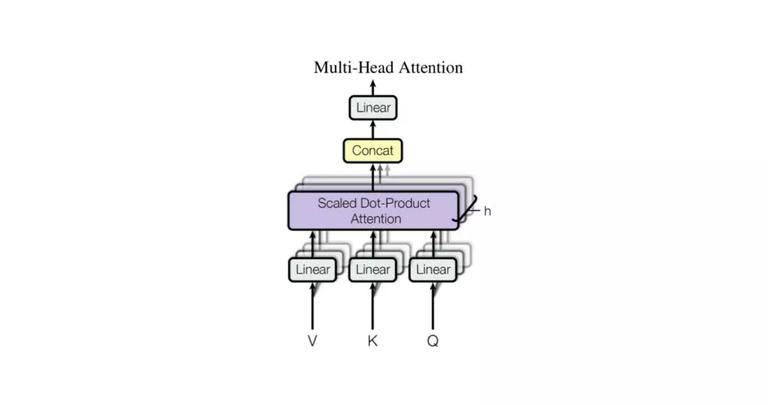
Multi-Head Attention。通过 h 个不同线性变换,将 d_model 维的 Q、K、V 分别映射成 d_k、d_k、d_v 维,并行应用 Self-Attention 机制,得到 h 个 d_v 维的输出,进行拼接计算 Concat、线性变换 Linear 操作。
2. 输入特征处理
BERT 的输入是一个线性序列,支持单句文本和句对文本,句首用符号 [CLS] 表示,句尾用符号 [SEP] 表示,如果是句对,句子之间添加符号[SEP]。输入特征,由 Token 向量、Segment 向量和 Position 向量三个共同组成,分别代表单词信息、句子信息、位置信息。

3. 预训练
BERT 采用了 MLM 和 NSP 两种策略用于模型预训练。为了证明这两种策略的效果,谷歌额外增加了两组对照实验。对照组一:No NSP,保留 MLM,但没有 NSP;对照组二:LTR & No NSP,没有 MLM 和 NSP,替换成一个 Left-to-Right(LTR)模型,甚至为了增强可信性,在对照组二的基础上增加一个随机初始化的 BiLSTM。实验数据表明,BERT 采用 MLM&NSP 策略完胜其他。

MLM,Masked LM。对输入的单词序列,随机地掩盖 15% 的单词,然后对掩盖的单词做预测任务。相比传统标准条件语言模型只能 left-to-right 或 right-to-left 单向预测目标函数,MLM 可以从任意方向预测被掩盖的单词。不过这种做法会带来两个缺点:1. 预训练阶段随机用符号 [MASK] 替换掩盖的单词,而下游任务微调阶段并没有 Mask 操作,会造成预训练跟微调阶段的不匹配;2. 预训练阶段只对 15% 被掩盖的单词进行预测,而不是整个句子,模型收敛需要花更多时间。对于第二点,作者们觉得效果提升明显还是值得;而对于第一点,为了缓和,15% 随机掩盖的单词并不是都用符号 [MASK] 替换,掩盖单词操作进行了以下改进,同时举例“my dog is hairy”挑中单词“hairy”。
80% 用符号 [MASK] 替换:my dog is hairy -> my dog is [MASK]
10% 用其他单词替换:my dog is hairy -> my dog is apple
10% 不做替换操作:my dog is hairy -> my dog is hairy
NSP,Next Sentence Prediction。许多重要的下游任务譬如 QA、NLI 需要语言模型理解两个句子之间的关系,而传统的语言模型在训练的过程没有考虑句对关系的学习。NSP,预测下一句模型,增加对句子 A 和 B 关系的预测任务,50% 的时间里 B 是 A 的下一句,分类标签为 IsNext,另外 50% 的时间里 B 是随机挑选的句子,并不是 A 的下一句,分类标签为 NotNext。
Input = [CLS] the man went to [MASK] store [SEP]
_ he brought a gallon [MASK] milk [SEP]_
Label = IsNext
Input = [CLS] the man went to [MASK] store [SEP]
_ penguin [MASK] are flight ##less birds [SEP]_
Label = NotNext
4. 任务微调
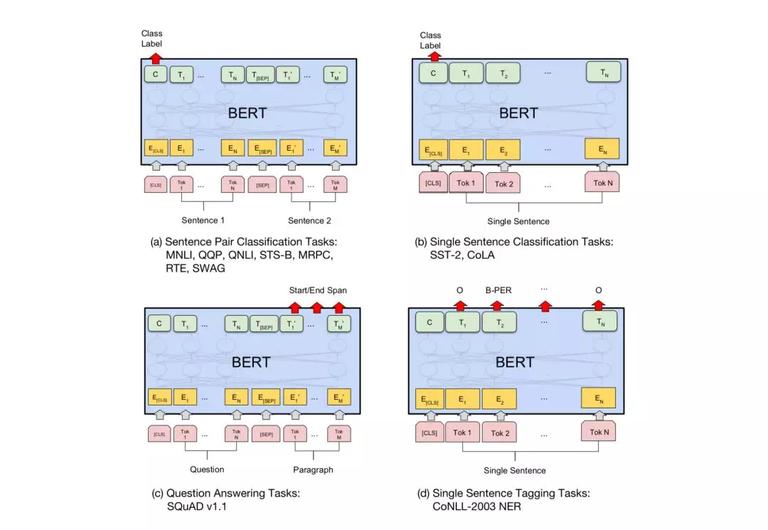
BERT 提供了 4 种不同下游任务的微调方案:
(a)句对关系判断,第一个起始符号 [CLS] 经过 Transformer 编码器后,增加简单的 Softmax 层,即可用于分类;
(b)单句分类任务,具体实现同(a)一样;
(c)问答类任务,譬如 SQuAD v1.1,问答系统输入文本序列的 question 和包含 answer 的段落,并在序列中标记 answer,让 BERT 模型学习标记 answer 开始和结束的向量来训练模型;
(d)序列标准任务,譬如命名实体标注 NER,识别系统输入标记好实体类别(人、组织、位置、其他无名实体)的文本序列进行微调训练,识别实体类别时,将序列的每个 Token 向量送到预测 NER 标签的分类层进行识别。
源码分析:BERT 实现
PyTorch:Torch 的 python 包,而 Torch 是一个用于机器学习和科学计算的模块化开源库。Anaconda Python 针对 Interl 架构调整了 MKL,使得 PyTorch 在 Interl CPU 上的性能达到最佳;此外,PyTorch 支持 NVIDIA GPU,能够利用 GPU 加速训练。
网上已经有各个版本的 BERT 源码,譬如谷歌开源的基于 TensorFlow 的 BERT 源码,谷歌推荐的能够加载谷歌预训练模型的 PyTorch-PreTrain-BERT 版本。我用来源码分析学习的是另一个 PyTorch 版本:Google AI 2018 BERT PyTorch Implementation,对照谷歌开源的 tf-BERT 版本开发实践。
MLM 模型实现。

NSP 模型实现。分类模型,同样可以适用于单句分类或句对关系判断任务。

BERT-Encoder 实现。

Transformer 实现。

Multi-Head Attention 实现

Self-Attention 实现。

SubLayerConnection 实现。

参考资料:
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Krisina Toutanova.2018.BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
Matthew Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. 2018. Deep contextualized word rep- resentations. In NAACL.
Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving language under- standing by Generative Pre-Training. Technical re- port, OpenAI.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Pro- cessing Systems, pages 6000–6010.
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei- Fei. 2009. ImageNet: A Large-Scale Hierarchical Image Database. In CVPR09.
Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013.Efficient Estimation of Word Representations in Vector Space.

时间:2019-03-05 18:22 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















