详解 Embeddings at Alibaba(KDD 2018)
文章转载自知乎: https://zhuanlan.zhihu.com/p/56119617
论文发表在 KDD 2018 上,链接为Learning and Transferring IDs Representation in E-commerce,文章属于实际应用,有些 insight,值得读下。
一、Introduction
以电商网站数据为例,其数据不管是从维度还是量级来说都是巨大的,包括商品信息、店铺信息、品类信息、评论信息等等。这里面 ID 类的特征是一种比较特殊的数据,可能只是一个长整型数。表面上来看并不带任何信息,但实际上通过行为的汇总其承载了丰富的信息。ID 类最初的处理方法是使用 one-hot 编码,这种方式有两个缺点:一个是高维带来的稀疏问题,模型具有足够置信度的话需要的样本量指数级增加;另一个是无法表示 ID 之间的关系,比如通过 one-hot 编码无法度量两个 ID 对应 item 的相似性。
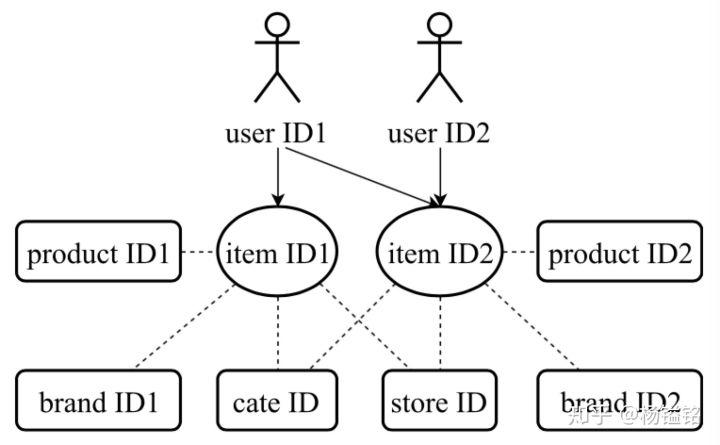
Item ID 和其他类型 ID 的结构关系
从交互式会话中可以得到 ID 的序列,从而可以用类似 Word2Vec 或者 Item2Vec 的方法对 ID 的共现关系进行建模,将 ID 映射到低维连续的向量。基于此,这篇文章提出一个学习 Embedding 的框架,产生使用所有类型 ID 的低维表示(映射到统一空间),并在多个任务上测试其效果。
二、所提模型
item 是电商类网站的核心交互单元。从用户交互会话中可以得到海量的 item ID 序列。
- 用户交互序列上的 Skip-Gram
如果将 item ID 序列看做 document,可使用 skip-gram 模型来产生 item 的表示。其思想就是给定 target item 来预测周围的 context item,形式化表达如下:

其中 C 是窗口大小,实验设置中 C=4。这里用户行为序列随机性相对语言要高,用户浏览意图可能短期内发生明显变化,个人感觉噪声会偏多。在基本的 skip-gram 模型中,  。其中
。其中  ,
,  和
和 分别表示 context 和 target 的表示,m 是 embedding 向量长度,D 是所有 item ID 构成字典的大小。
- Log-uniform Negative-sampling
对  的计算开销和字典大小 D 相关,如果字典非常大,则其计算并不现实。这里引入负采样来对
的计算开销和字典大小 D 相关,如果字典非常大,则其计算并不现实。这里引入负采样来对 的计算进行改进:

其中,  ,S 是从噪声分布
,S 是从噪声分布  中抽取的负样本的个数,实验设置中 S=2。
中抽取的负样本的个数,实验设置中 S=2。  最简单的形式就是均匀分布,但是均匀分布对稀少或热门的 item 的平衡处理并不好。这里作者提出使用 log-uniform negative-sampling 的方式进行修正,负样本的选择通过 Zipfian 分布产生。
最简单的形式就是均匀分布,但是均匀分布对稀少或热门的 item 的平衡处理并不好。这里作者提出使用 log-uniform negative-sampling 的方式进行修正,负样本的选择通过 Zipfian 分布产生。
- Joint Embedding Attribute IDs
ID 类型的特征可分成两种:item ID and its attribute IDs。Item 是核心的交互单元,同时它包含很多 attribute ID,比如产品 ID、商铺 ID、品牌 ID 和类别 ID 等;user ID。user ID 用来标识一个用户,可代表 cookie、IMEI 或者登录账号。通过引入 item ID 和其 attribute ID 的结构联系,作者提出层级 Embedding 模型来联合训练得到 item ID 和 attribute ID 的低维表示。
首先,item ID 的共现关系也暗示了其对应 attribute ID 的共现关系。假设有 K 种类型的 ID,设  ,分别是 Item ID,Product ID,Store ID 等。可得下式:
,分别是 Item ID,Product ID,Store ID 等。可得下式:

其中,  。
。
其次,item ID 和 attribute ID 间存在着结构联系,这意味着可对模型增加限制。前面提到,比如两个 item ID 由于共现两者的 Embedding 相似,而且如果 product ID、restore ID 等特征相同则两者的 Embedding 也应该相似,所以可通过 attribute ID 来预测 item ID。形式化表达如下:

这里需要乘以一个矩阵  的原因是不同类型 attribute ID 的 Embedding 长度可能不一样,无法直接相乘。综合刚才提到的两点,可以得到最终的损失函数 L,我们需要最大化 L,如下式。通过一起训练,使得 item ID 和 attribute ID 可以映射到同一个语义空间,这便于在真实应用中使用或迁移这些 representation。
的原因是不同类型 attribute ID 的 Embedding 长度可能不一样,无法直接相乘。综合刚才提到的两点,可以得到最终的损失函数 L,我们需要最大化 L,如下式。通过一起训练,使得 item ID 和 attribute ID 可以映射到同一个语义空间,这便于在真实应用中使用或迁移这些 representation。

- Embedding Users IDs
用户的偏爱可通过其交互过的 item ID 序列来表示,那该如何通过这些 item ID 对应的 Embedding 向量处理得到用户的 Embedding 呢?直接做平均还是使用 RNN 结构?作者提到盒马鲜生的场景用户兴趣变化非常快,采用 RNN 结构训练会明显耗时,所以采用了直接对近期交互的 T 个 item ID 平均的方式来快速更新用户的 Embedding。这里并未提到T 的取值如何确定,个人感觉是个比较 trick 的点,因为如果 T 的取值比较大,则某一个 item ID 对平均之后的结果影响不大,而如果 T 的取值比较小,则平均后的结果携带的信息量不足。
另外值得一提的是,文中提到 item ID 和 attribute ID 的 Embedding 是周级更新,这也是符合实际情况的,毕竟 item 信息相对稳定。但是用户的 Embedding 是要尽量实时更新的,因为用户兴趣变化要更快。
三、实验任务
- 计算 item 相似度
物品间的相似性在推荐系统中使用广泛,比如给用户推荐和用户感兴趣的物品相似的物品。物品相似性可以通过两者对应的 Embedding 向量的余弦距离来度量。item-based CF 方法需要明确的 user-item 关系,但很大比例的交互数据并没有用户识别信息。而 skip-gram 模型基于会话的,可以利用全量的数据。因此基于 Embedding 的方法比基于 item-based 的 CF 方法要更好一些,实验结果也说明其有更高的召回。
- 迁移到新的 item
推荐系统中冷启动是个很大的问题,新物品由于没有交互信息,此时 item-based 的 CF 方法失效。一般可通过基于 image 或者 text 的辅助信息来进行推荐。这里解决冷启动的方法出发点是和新物品连接的 attribute ID 通常有历史记录,因此可以通过这些 attribute ID 的 Embedding 来预测得到新物品的 Embedding。通过一些推导和近似,使用  来拟合新物品的 Embedding。最后的近似步骤并没有看得很懂,有明白的小伙伴可以评论讲解下。这个直接推导新物品 Embedding 的思路比较自然清奇,有点像优化问题直接求出闭式解。
来拟合新物品的 Embedding。最后的近似步骤并没有看得很懂,有明白的小伙伴可以评论讲解下。这个直接推导新物品 Embedding 的思路比较自然清奇,有点像优化问题直接求出闭式解。
- 迁移到新的领域
盒马鲜生作为一个新平台,很大比例的用户是新的,因此做个性化的推荐较为困难。文章提出了一种将淘宝 (source domain) 用户的兴趣迁移到盒马 (target domain) 上的方法。首先,设  和
和  分别表示淘宝和盒马的用户,其交集
分别表示淘宝和盒马的用户,其交集  。首先获得
。首先获得  中用户的 Embedding。然后通过 K-means 算法将
中用户的 Embedding。然后通过 K-means 算法将  中的用户划分成 1000 个簇,对每个簇的选择最热门的 item 集合作为候选集合。对于新来的用户
中的用户划分成 1000 个簇,对每个簇的选择最热门的 item 集合作为候选集合。对于新来的用户  ,根据用户的 Embedding 和簇中心的距离分配一个最相近的簇,然后将这个簇对应的候选集合推荐给新用户。
,根据用户的 Embedding 和簇中心的距离分配一个最相近的簇,然后将这个簇对应的候选集合推荐给新用户。
- 迁移到不同任务
作者在预测店铺销量的任务上进行了测试,使用历史销售数据和 store Embedding 作为输入,baseline 是只用历史销售数据或者使用 store one-hot 编码来作为输入。
四、总结
深度学习中设计离散特征的话一般都处理成 Embedding 的形式,作为网络的底部,一般对整体网络效果有着重要的作用。和 Airbnb 那篇文章类似,这篇文章也是根据自己的业务特征对 Embedding 的模型进行了改进。对于常见模型不仅要知其然也要知其所以然,能根据真实的业务特点对模型做适配来提升模型效果。这是作为算法工程师的核心竞争力之一。

时间:2019-03-05 18:22 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]堪比当年的LSTM,Transformer引燃机器学习圈:它是
- [机器学习]论机器学习领域的内卷:不读PhD,我配不配找工
- [机器学习]人工智能十年回顾:CNN、AlphaGo、GAN……它们曾这
- [机器学习]机器学习基础图表:概念、原理、历史、趋势和算法
- [机器学习]分析了 600 多种烘焙配方,机器学习开发出新品
- [机器学习]2021年的机器学习生命周期
- [机器学习]物联网和机器学习促进企业业务发展的5种方式
- [机器学习]20年以后,半数工作将被人工智能取代?这些“高危行业”有哪些
- [机器学习]机器学习中分类任务的常用评估指标和Python代码实现
- [机器学习]机器学习和深度学习的区别是什么?
相关推荐:
网友评论:















