58 招聘推荐系统介绍——AB 实验框架
58 招聘智能推荐系统
推荐的概念早已渗透进我们的日常生活中,我们欣赏过各类电影、音乐、游戏榜单,沉迷过电商节日层出不穷的百货商品,甚至钻研过如何选择投资理财,如何购房置业,如何开启更好的职业生涯。在这样一个信息爆炸的时代,我们永远不缺少选项,如果没有推荐发挥作用,在海量的数据面前,我们有时不知所措,踌躇不前,无法做出合适的抉择。
58 招聘平台是一个资源丰富并且成熟的求职者、企业双边服务平台,智能推荐系统将帮助企业寻找更合适的候选人,协助求职者寻觅更优质的工作。对于企业用户,通过剖析发布的职位特征,候选人简历特征,连接行为等数据,推荐匹配度高、更具有竞争力的求职者。对于求职者,尊重其主观简历意愿的同时,分析行为动态,构建用户长短期画像,深度挖掘更感兴趣的职位和行业。随着探索的不断深入,业务的进步发展,我们也凝练了招聘智能推荐系统的使命与愿景:
使命: 为求职者提供心仪的职位,为企业寻觅更契合的人才
愿景: 人人认可的招聘智能双边推荐平台
通过智能推荐系统筛选、优化信息,为双边用户提供更好的服务,让用户信赖与认可将是我们持续努力的源泉。
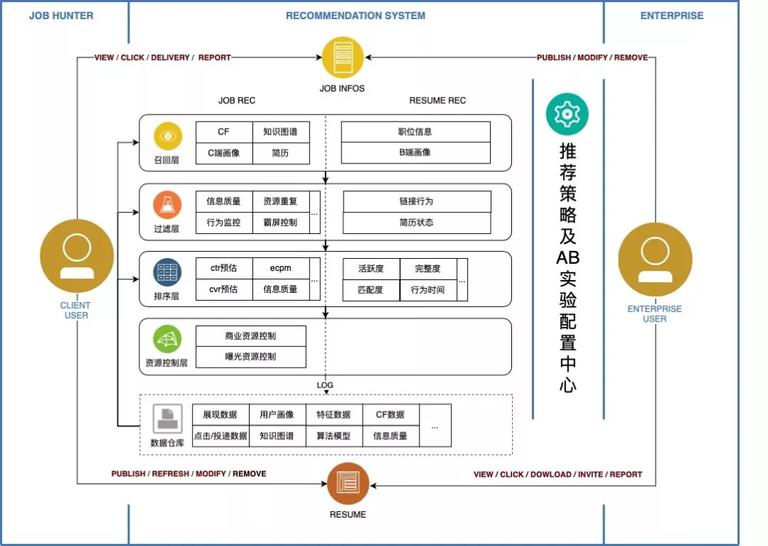
以推荐职位为例,推荐系统并不仅仅是依据求职者的简历信息精确的匹配职位,还是融合用户行为、职位转化情况、距离、企业、薪资、新颖度、惊喜度等一系列变量综合进行推荐的过程。每一个推荐位都有独特的推荐意义和推荐策略,为此我们一直在构建招聘业务的知识图谱,挖掘用户、职位的标签信息,完善特征体系,优化召回、排序模型,定制个性化推荐策略。
AB 实验框架介绍
1. 背景
在整个推荐链条中,从展示层到策略层,推荐系统需要进行多种策略选择、多种算法落地、多种产品思维融合,那么到底哪个方案更优,更加适合招聘场景的推荐呢?我们需要客观的从数据层面进行评估,而不是脱离业务去模仿其他产品,挪用最优的算法,毫无数据支撑的做出某种关键抉择。每一条推荐策略都是经过严格的离线计算,线上 AB 实验,最终综合评估确定的。因此一套成熟的 AB 实验框架是不可或缺的,它亦是推动整个系统有条不紊,以数据为驱动,严谨前行的坚固基石。
2. 调用流程
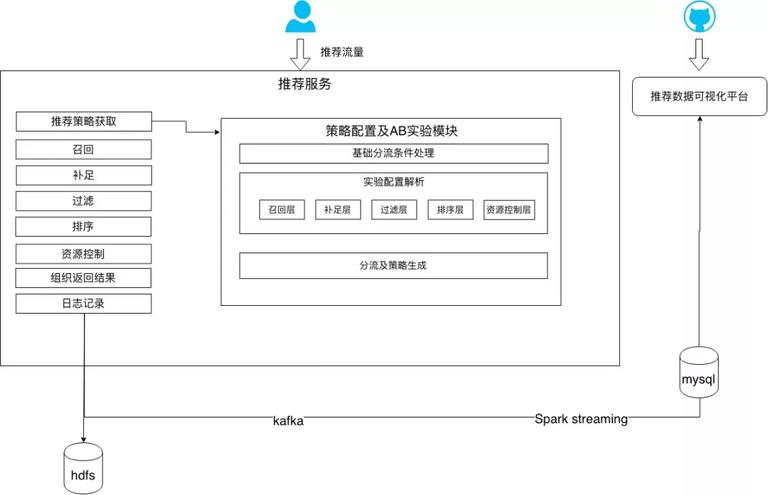 当推荐流量进入推荐服务后,会先通过推荐策略及 AB 实验模块,根据推荐位信息来获取个性化推荐逻辑。首先会经过基础分流条件处理模块以分配特定的流量,应对一些特殊的实验场景。例如常用的城市、类别等信息,当我们只想在特定城市或类别下进行实验时,可以简单的通过配置相应的基础条件来灵活高效利用实验流量。之后会进入实验配置解析模块,将各个不同逻辑层配置的 AB 实验逐一解析,使用分流策略按照流量配比选择对应的实验并且对实验标识进行记录。最后生成以推荐位为单元的个性化推荐策略返回给推荐服务,以支撑后续推荐流程。
当推荐流量进入推荐服务后,会先通过推荐策略及 AB 实验模块,根据推荐位信息来获取个性化推荐逻辑。首先会经过基础分流条件处理模块以分配特定的流量,应对一些特殊的实验场景。例如常用的城市、类别等信息,当我们只想在特定城市或类别下进行实验时,可以简单的通过配置相应的基础条件来灵活高效利用实验流量。之后会进入实验配置解析模块,将各个不同逻辑层配置的 AB 实验逐一解析,使用分流策略按照流量配比选择对应的实验并且对实验标识进行记录。最后生成以推荐位为单元的个性化推荐策略返回给推荐服务,以支撑后续推荐流程。
3. 分层实验模型及分流算法
显而易见,推荐的整体步骤清晰,层次分明,为了快速高效验证离线分析成果,策略算法同学经常会在不同层级并行迭代实验。因此要求实验不互相干扰,每层的实验流量正交,评估效果准确有效,框架需要支持分层实验的功能。

纵向来看,流量域分为独立实验区和分层实验区。独立实验区不支持分层实验,针对单一变量进行实验。而分层实验区根据推荐流程分为多层:召回层、补足层,过滤层、排序层、资源控制层。每一层均可配置多组实验,层与层之间互不干扰。其中召回层我们会整合多个数据源的职位数据,通过实验标识回传我们以简单轻量的方式支持下游服务的 AB 实验需求。
目前,流量划分支持按照 pv 来进行均匀切分,每一层含有一个 bucket 集合(长度为 100),每个实验按照配置的流量占比分配一批 bucket,然后通过算式:
bucketid=hash(md5(timestamp,layerid))%100+1
来计算本次请求落入哪个实验中,获取具体配置和实验标识。追加每一层的实验标识,例如 texp1 | fexp2 | rexp3,将最终的实验组合标识记录在日志中,用于离线数据和实时数据统计实验结果。
4. 个性化扩展参数
为了契合复杂多变的实验场景,在推荐配置中可以灵活定制扩展参数对每条策略进行个性化设计。
- 召回层, 补足层
priority: 策略优选级配置,从 1~n,默认值为 1,数字越小优先级越高。
capacity: 召回信息容量,默认值为 30,限制单次召回最大数量。
distance: 附近半径距离,不设置则不触发,用于附近召回策略。
- 排序层
weight: 打分因子权重。
- 资源分配层
frontpage_scale: 首页商业占比。
bizlow,biz****high: 商业资源占比最低、最高配比。
- 通用
tag: 实验标识。
percent: 流量配比。
group: 分组,同一层多策略并行时,如只想对某一策略进行 AB 实验,编入同组即可。
5. 支撑成果
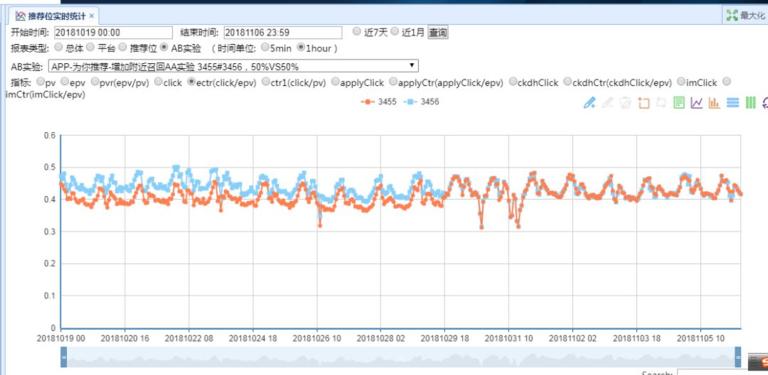
目前,推荐策略配置及 AB 实验框架支撑着我们每天 80 多个推荐位,线上 20 多个 AB 实验的日常迭代。通过我们的可视化平台配置 AB 实验参数(推荐位,实验号等)即可实时监控各个常用核心数据指标的实验效果。下图中可以清晰得看到一个实验从开始到 AA 验证的整体数据变化情况。
6. 持续演化完善功能
由于业务不断发展,实验框架也在不断的演化和完善,以支持更加多变的场景,减少 AB 实验及评估成本,提高工作效率。近期我们正在对 AB 实验框架进行迭代优化,总结了以前的核心痛点:
实验成本高 实验配置采用 xml 文件存储在推荐服务中,每一次策略更新或者流量调整都需要手动上线。
配置不透明 只有通过查看 xml 文件才能知晓推荐配置,可视化平台暂不支持自动创建实验监控配置。
实验标识零散 实验号由实验者添加,有时出现冲突情况,不易管理。
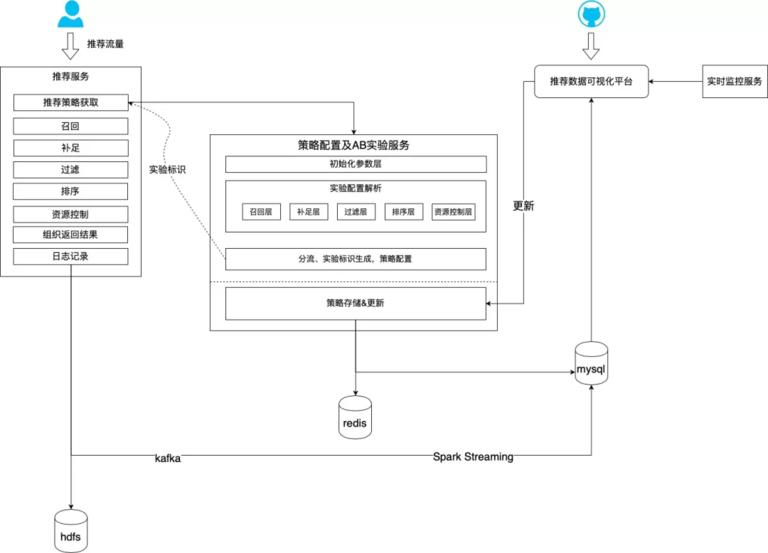
针对这些问题,我们将依次开展优化,从图中可以看到,首先搭建中心服务,将原先的配置中心逻辑迁移到一个独立服务里统一对外提供策略配置和实验分配的支持。其次,优化策略配置流程,增加一个初始化层来管理所有全流量的参数,当实验推全时只需将参数更新到初始化层就可以简单完成实验全流量。同时将配置存放在 redis 中,持久化选择 mysql 数据库,在可视化平台中读取相应数据即可展示所有推荐位策略及实验配置情况。实验者可以通过可视化平台提供的页面对配置进行修改,保存后将触发更新,可以利用 redis 的发布订阅功能通知所有使用方来同步新的推荐配置完成实验的线上实时更新,不再依赖服务上线操作。然后,实验标识自动化,实验者只需关注实验所需流量的占比,配置中心将自动分配相对应的流量并给予唯一实验标识,同步生成可视化实验参数配置方便观测实时数据。最后,增加实时数据监控模块,保证线上推荐配置效果。在数据库中会记录每个推荐位的历史版本的配置,如果实验者误操作或新上线的配置导致线上关键数据指标下降过多,将会发出报警信息,通知相关人员来进行处理,如果不及时处理,将自动恢复上一个版本的配置来增强整个系统的鲁棒性。
写在最后
推荐系统不仅仅需要精确把握用户兴趣进行“千人千面”的个性化推荐,还需要融合各种有效的数据、策略、算法来优化推荐的效果,给予用户具有多样性、新颖性、时效性、更高惊喜度的优秀结果。更强大的 AB 实验平台除了能为实验者提供简单友好的实验配置及数据监控可视化界面,还会进一步支持全链路的实验设计和策略管理,因此对于效果的评估,我们也将从展示样式、流量来源、点击效果、投递效果、进一步连接效果(IM/ 电话 )、商业收入、用户负反馈等多个维度综合考虑我们的优化路线,整体提升推荐体验。
Reference
- Overlapping Experiment Infrastructure: More, Better, Faster Experimentation

时间:2019-01-24 20:23 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















