深度强化学习打造的 ANYmal 登上 Science 子刊
足式机器人是机器人学中最具挑战性的主题之一。动物动态、敏捷的动作是无法用现有人为方法模仿的。一种引人注目的方法是强化学习,它只需要极少的手工设计,能够促进控制策略的自然演化。然而,截至目前,足式机器人领域的强化学习研究还主要局限于模仿,只有少数相对简单的例子被部署到真实环境系统中。主要原因在于,使用真实的机器人(尤其是使用带有动态平衡系统的真实机器人)进行训练既复杂又昂贵。本文介绍了一种可以在模拟中训练神经网络策略并将其迁移到当前最先进足式机器人系统中的方法,因此利用了快速、自动化、成本合算的数据生成方案。该方法被应用到 ANYmal 机器人中,这是一款中型犬大小的四足复杂机器人系统。利用在模拟中训练的策略,ANYmal 获得了之前方法无法实现的运动技能:它能精确、高效地服从高水平身体速度指令,奔跑速度比之前的机器人更快,甚至在复杂的环境中还能跌倒后爬起来。
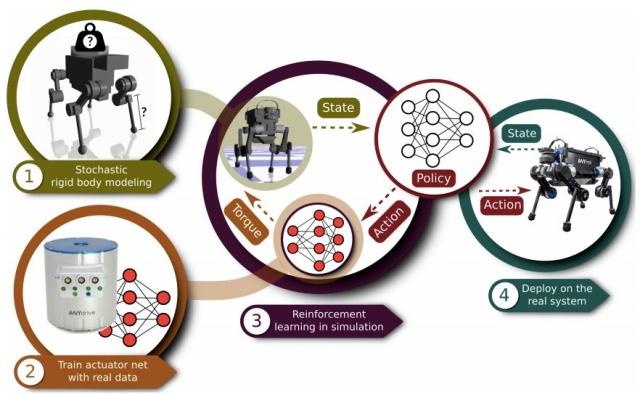
创建一个控制策略。第一步是确定机器人的物理参数并估计其中的不确定性。第二步是训练一个致动器网络,建模复杂的致动器/软件动力机制。第三步是利用前两步中得到的模型训练一个控制策略。第四步是直接在物理系统中部署训练好的策略。
基于命令的运动
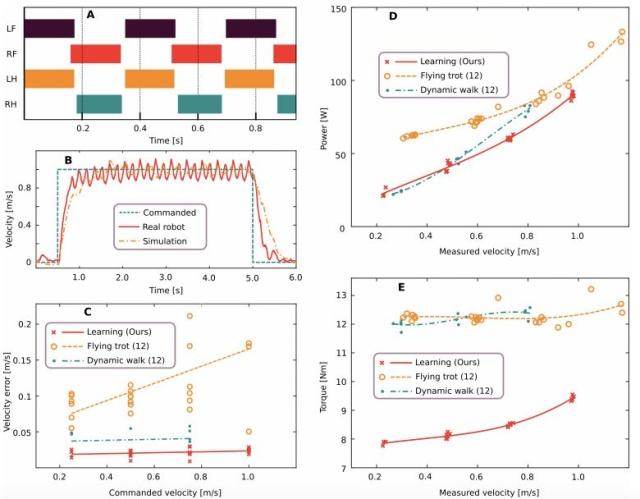
习得运动控制器的量化评估结果。A. 发现的步态模式按速度指令以 1.0 m/s 的速度运行。LF 表示左前腿,RF 表示右前腿,LH 表示左后腿,RH 表示右后腿。B. 使用本文方法得到的基础速度的准确率。C-E. 本文习得控制器与现有最佳控制器在能耗、速度误差、扭矩大小方面的对比,给定的前进速度指令为 0.25、0.5、0.75 和 1.0 m/s。
高速运动
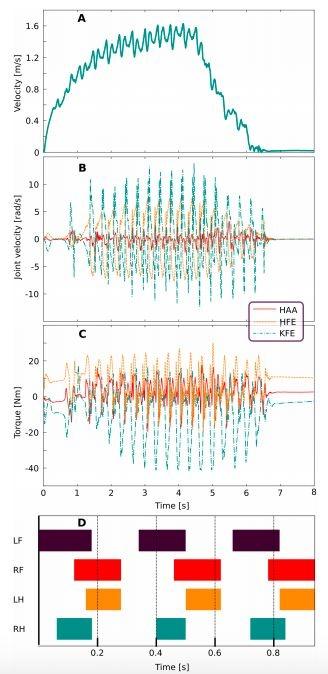
对高速运动训练策略的评估结果。A. ANYmal 的前进速度。B. 关节速度。C. 关节扭矩。D. 步态模式。

时间:2019-01-22 23:36 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关推荐:
网友评论:















