推荐系统遇上深度学习 (二十)-- 贝叶斯个性化排
排序推荐算法大体上可以分为三类,第一类排序算法类别是点对方法 (Pointwise Approach),这类算法将排序问题被转化为分类、回归之类的问题,并使用现有分类、回归等方法进行实现。第二类排序算法是成对方法(Pairwise Approach),在序列方法中,排序被转化为对序列分类或对序列回归。所谓的 pair 就是成对的排序,比如(a,b) 一组表明 a 比 b 排的靠前。第三类排序算法是列表方法(Listwise Approach),它采用更加直接的方法对排序问题进行了处理。它在学习和预测过程中都将排序列表作为一个样本。排序的组结构被保持。
之前我们介绍的算法大都是 Pointwise 的方法,今天我们来介绍一种 Pairwise 的方法:贝叶斯个性化排序 (Bayesian Personalized Ranking, 以下简称 BPR)
1、BPR 算法简介
1.1 基本思路
在 BPR 算法中,我们将任意用户 u 对应的物品进行标记,如果用户 u 在同时有物品 i 和 j 的时候点击了 i,那么我们就得到了一个三元组,它表示对用户 u 来说,i 的排序要比 j 靠前。如果对于用户 u 来说我们有 m 组这样的反馈,那么我们就可以得到 m 组用户 u 对应的训练样本。
这里,我们做出两个假设:
-
每个用户之间的偏好行为相互独立,即用户 u 在商品 i 和 j 之间的偏好和其他用户无关。
-
同一用户对不同物品的偏序相互独立,也就是用户 u 在商品 i 和 j 之间的偏好和其他的商品无关。
为了便于表述,我们用 >u 符号表示用户 u 的偏好,上面的可以表示为:i >u j。
在 BPR 中,我们也用到了类似矩阵分解的思想,对于用户集 U 和物品集 I 对应的 U*I 的预测排序矩阵,我们期望得到两个分解后的用户矩阵 W(|U|×k) 和物品矩阵 H(|I|×k),满足:
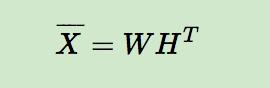
那么对于任意一个用户 u,对应的任意一个物品 i,我们预测得出的用户对该物品的偏好计算如下:
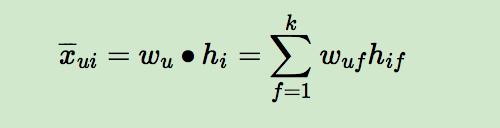
而模型的最终目标是寻找合适的矩阵 W 和 H,让 X-(公式打不出来,这里代表的是 X 上面有一个横线,即 W 和 H 矩阵相乘后的结果) 和 X(实际的评分矩阵) 最相似。看到这里,也许你会说,BPR 和矩阵分解没有什区别呀?是的,到目前为止的基本思想是一致的,但是具体的算法运算思路,确实千差万别的,我们慢慢道来。
1.2 算法运算思路
BPR 基于最大后验估计 P(W,H|>u) 来求解模型参数 W,H, 这里我们用θ来表示参数 W 和 H, >u 代表用户 u 对应的所有商品的全序关系, 则优化目标是 P(θ|>u)。根据贝叶斯公式,我们有:
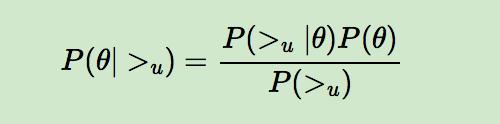
由于我们求解假设了用户的排序和其他用户无关,那么对于任意一个用户 u 来说,P(>u) 对所有的物品一样,所以有:
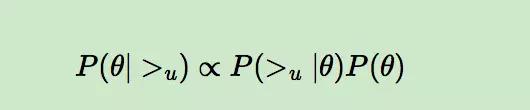
这个优化目标转化为两部分。第一部分和样本数据集 D 有关,第二部分和样本数据集 D 无关。
第一部分
对于第一部分,由于我们假设每个用户之间的偏好行为相互独立,同一用户对不同物品的偏序相互独立,所以有:
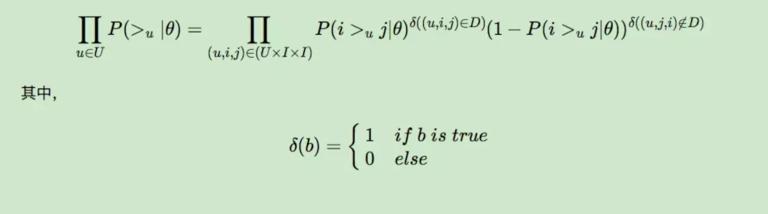
上面的式子类似于极大似然估计,若用户 u 相比于 j 来说更偏向 i,那么我们就希望 P(i >u j|θ) 出现的概率越大越好。
上面的式子可以进一步改写成:
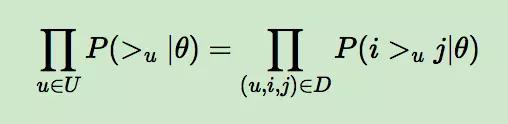
而对于 P(i >u j|θ) 这个概率,我们可以使用下面这个式子来代替:
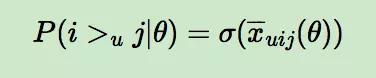
其中,σ(x) 是 sigmoid 函数,σ里面的项我们可以理解为用户 u 对 i 和 j 偏好程度的差异,我们当然希望 i 和 j 的差异越大越好,这种差异如何体现,最简单的就是差值:
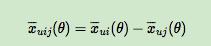
省略θ我们可以将式子简略的写为:
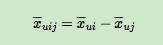
因此优化目标的第一项可以写作:
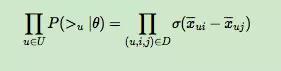
哇,是不是很简单的思想,对于训练数据中的,用户更偏好于 i,那么我们当然希望在 X- 矩阵中 ui 对应的值比 uj 对应的值大,而且差距越大越好!
第二部分
回想之前我们通过贝叶斯角度解释正则化的文章:https://www.jianshu.com/p/4d562f2c06b8
当θ的先验分布是正态分布时,其实就是给损失函数加入了正则项,因此我们可以假定θ的先验分布是正态分布:
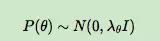
所以:
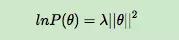
因此,最终的最大对数后验估计函数可以写作:
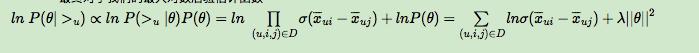
剩下的我们就可以通过梯度上升法 (因为是要让上式最大化) 来求解了。我们这里就略过了,BPR 的思想已经很明白了吧,哈哈!让我们来看一看如何实现吧。
2、算法实现
本文的 github 地址为:https://github.com/princewen/tensorflow_practice/tree/master/recommendation/Basic-BPR-Demo
所用到的数据集是 movieslen 100k 的数据集,下载地址为:http://grouplens.org/datasets/movielens/
数据预处理
首先,我们需要处理一下数据,得到每个用户打分过的电影,同时,还需要得到用户的数量和电影的数量。
def load_data():
user_ratings = defaultdict(set)
max_u_id = -1
max_i_id = -1
with open('data/u.data','r') as f:
for line in f.readlines():
u,i,_,_ = line.split("\t")
u = int(u)
i = int(i)
user_ratings[u].add(i)
max_u_id = max(u,max_u_id)
max_i_id = max(i,max_i_id)
print("max_u_id:",max_u_id)
print("max_i_idL",max_i_id)
return max_u_id,max_i_id,user_ratings
下面我们会对每一个用户 u,在 user_ratings 中随机找到他评分过的一部电影 i, 保存在 user_ratings_test,后面构造训练集和测试集需要用到。
def generate_test(user_ratings):
"""
对每一个用户u,在user_ratings中随机找到他评分过的一部电影i,保存在user_ratings_test,我们为每个用户取出的这一个电影,是不会在训练集中训练到的,作为测试集用。
"""
user_test = dict()
for u,i_list in user_ratings.items():
user_test[u] = random.sample(user_ratings[u],1)[0]
return user_test
构建训练数据
我们构造的训练数据是的三元组,i 可以根据刚才生成的用户评分字典得到,j 可以利用负采样的思想,认为用户没有看过的电影都是负样本:
def generate_train_batch(user_ratings,user_ratings_test,item_count,batch_size=512):
"""
构造训练用的三元组
对于随机抽出的用户u,i可以从user_ratings随机抽出,而j也是从总的电影集中随机抽出,当然j必须保证(u,j)不在user_ratings中
"""
t = []
for b in range(batch_size):
u = random.sample(user_ratings.keys(),1)[0]
i = random.sample(user_ratings[u],1)[0]
while i==user_ratings_test[u]:
i = random.sample(user_ratings[u],1)[0]
j = random.randint(1,item_count)
while j in user_ratings[u]:
j = random.randint(1,item_count)
t.append([u,i,j])
return np.asarray(t)
构造测试数据
同样构造三元组,我们刚才给每个用户单独抽出了一部电影,这个电影作为 i,而用户所有没有评分过的电影都是负样本 j:
def generate_test_batch(user_ratings,user_ratings_test,item_count):
"""
对于每个用户u,它的评分电影i是我们在user_ratings_test中随机抽取的,它的j是用户u所有没有评分过的电影集合,
比如用户u有1000部电影没有评分,那么这里该用户的测试集样本就有1000个
"""
for u in user_ratings.keys():
t = []
i = user_ratings_test[u]
for j in range(1,item_count + 1):
if not(j in user_ratings[u]):
t.append([u,i,j])
yield np.asarray(t)
模型构建
首先回忆一下我们需要学习的参数θ,其实就是用户矩阵 W(|U|×k) 和物品矩阵 H(|I|×k) 对应的值,对于我们的模型来说,可以简单理解为由 id 到 embedding 的转化,因此有:
u = tf.placeholder(tf.int32,[None])
i = tf.placeholder(tf.int32,[None])
j = tf.placeholder(tf.int32,[None])
user_emb_w = tf.get_variable("user_emb_w", [user_count + 1, hidden_dim],
initializer=tf.random_normal_initializer(0, 0.1))
item_emb_w = tf.get_variable("item_emb_w", [item_count + 1, hidden_dim],
initializer=tf.random_normal_initializer(0, 0.1))
u_emb = tf.nn.embedding_lookup(user_emb_w, u)
i_emb = tf.nn.embedding_lookup(item_emb_w, i)
j_emb = tf.nn.embedding_lookup(item_emb_w, j)
回想一下我们要优化的目标,第一部分是 ui 和 uj 对应的预测值的评分之差,再经由 sigmoid 变换得到的 [0,1] 值,我们希望这个值越大越好,对于损失来说,当然是越小越好。因此,计算如下:
x = tf.reduce_sum(tf.multiply(u_emb,(i_emb-j_emb)),1,keep_dims=True)
loss1 = - tf.reduce_mean(tf.log(tf.sigmoid(x)))
第二部分是我们的正则项,参数就是我们的 embedding 值,所以正则项计算如下:
l2_norm = tf.add_n([
tf.reduce_sum(tf.multiply(u_emb, u_emb)),
tf.reduce_sum(tf.multiply(i_emb, i_emb)),
tf.reduce_sum(tf.multiply(j_emb, j_emb))
])
因此,我们模型整个的优化目标可以写作:
regulation_rate = 0.0001
bprloss = regulation_rate * l2_norm - tf.reduce_mean(tf.log(tf.sigmoid(x)))
train_op = tf.train.GradientDescentOptimizer(0.01).minimize(bprloss)
至此,我们整个模型就介绍完了,如果大家想要了解完整的代码实现,可以参考 github 哟。
3、总结
1.BPR 是基于矩阵分解的一种排序算法,它不是做全局的评分优化,而是针对每一个用户自己的商品喜好分贝做排序优化。
2. 它是一种 pairwise 的排序算法,对于每一个三元组,模型希望能够使用户 u 对物品 i 和 j 的差异更明显。
3. 同时,引入了贝叶斯先验,假设参数服从正态分布,在转换后变为了 L2 正则,减小了模型的过拟合。
参考文献
1、http://www.cnblogs.com/pinard/p/9128682.html
2、http://www.cnblogs.com/pinard/p/9163481.html

时间:2019-01-20 01:21 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















