推荐系统遇上深度学习 (二)--FFM 模型理论和实践
原文发布于微信公众号 - 小小挖掘机(wAIsjwj)
原文发表时间:2018-04-10
1、FFM 理论
在 CTR 预估中,经常会遇到 one-hot 类型的变量,one-hot 类型变量会导致严重的数据特征稀疏的情况,为了解决这一问题,在上一讲中,我们介绍了 FM 算法。这一讲我们介绍一种在 FM 基础上发展出来的算法 -FFM(Field-aware Factorization Machine)。
FFM 模型中引入了类别的概念,即 field。还是拿上一讲中的数据来讲,先看下图:
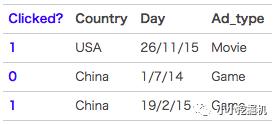
在上面的广告点击案例中,“Day=26/11/15”、“Day=1/7/14”、“Day=19/2/15”这三个特征都是代表日期的,可以放到同一个 field 中。同理,Country 也可以放到一个 field 中。简单来说,同一个 categorical 特征经过 One-Hot 编码生成的数值特征都可以放到同一个 field,包括用户国籍,广告类型,日期等等。
在 FFM 中,每一维特征 xi,针对其它特征的每一种 field fj,都会学习一个隐向量 v_i,fj。因此,隐向量不仅与特征相关,也与 field 相关。也就是说,“Day=26/11/15”这个特征与“Country”特征和“Ad_type" 特征进行关联的时候使用不同的隐向量,这与“Country”和“Ad_type”的内在差异相符,也是 FFM 中“field-aware”的由来。
假设样本的 n 个特征属于 f 个 field,那么 FFM 的二次项有 nf 个隐向量。而在 FM 模型中,每一维特征的隐向量只有一个。FM 可以看作 FFM 的特例,是把所有特征都归属到一个 field 时的 FFM 模型。根据 FFM 的 field 敏感特性,可以导出其模型方程。
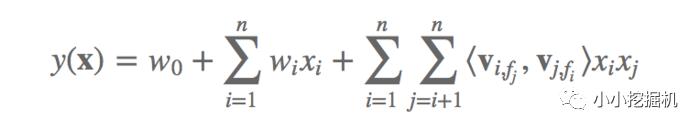
可以看到,如果隐向量的长度为 k,那么 FFM 的二次参数有 nfk 个,远多于 FM 模型的 nk 个。此外,由于隐向量与 field 相关,FFM 二次项并不能够化简,其预测复杂度是 O(kn^2)。
下面以一个例子简单说明 FFM 的特征组合方式。输入记录如下:

这条记录可以编码成 5 个特征,其中“Genre=Comedy”和“Genre=Drama”属于同一个 field,“Price”是数值型,不用 One-Hot 编码转换。为了方便说明 FFM 的样本格式,我们将所有的特征和对应的 field 映射成整数编号。

那么,FFM 的组合特征有 10 项,如下图所示。

其中,红色是 field 编号,蓝色是特征编号。
2、FFM 实现细节
这里讲得只是一种 FFM 的实现方式,并不是唯一的。
损失函数
FFM 将问题定义为分类问题,使用的是 logistic loss,同时加入了正则项

什么,这是 logisitc loss?第一眼看到我是懵逼的,逻辑回归的损失函数我很熟悉啊,不是长这样的啊?其实是我目光太短浅了。逻辑回归其实是有两种表述方式的损失函数的,取决于你将类别定义为 0 和 1 还是 1 和 -1。大家可以参考下下面的文章:https://www.cnblogs.com/ljygoodgoodstudydaydayup/p/6340129.html。当我们将类别设定为 1 和 -1 的时候,逻辑回归的损失函数就是上面的样子。
随机梯度下降
训练 FFM 使用的是随机梯度下降方法,即每次只选一条数据进行训练,这里还有必要补一补梯度下降的知识,梯度下降是有三种方式的,截图取自参考文献 3:

总给人一种怪怪的感觉。batch 为什么是全量的数据呢,哈哈。
3、tensorflow 实现代码
本文代码的 github 地址:
https://github.com/princewen/tensorflow_practice/tree/master/recommendation-FFM-Demo
这里我们只讲解一些细节,具体的代码大家可以去 github 上看:
生成数据
这里我没有找到合适的数据,就自己产生了一点数据,数据涉及 20 维特征,前十维特征是一个 field,后十维是一个 field:
def gen_data():
labels = [-1,1]
y = [np.random.choice(labels,1)[0] for _ in range(all_data_size)]
x_field = [i // 10 for i in range(input_x_size)]
x = np.random.randint(0,2,size=(all_data_size,input_x_size))
return x,y,x_field
定义权重项
在 ffm 中,有三个权重项,首先是 bias,然后是一维特征的权重,最后是交叉特征的权重:
def createTwoDimensionWeight(input_x_size,field_size,vector_dimension):
weights = tf.truncated_normal([input_x_size,field_size,vector_dimension])
tf_weights = tf.Variable(weights)
return tf_weights
def createOneDimensionWeight(input_x_size):
weights = tf.truncated_normal([input_x_size])
tf_weights = tf.Variable(weights)
return tf_weights
def createZeroDimensionWeight():
weights = tf.truncated_normal([1])
tf_weights = tf.Variable(weights)
return tf_weights
计算估计值
估计值的计算这里不能项 FM 一样先将公式化简再来做,对于交叉特征,只能写两重循环,所以对于特别多的特征的情况下,真的计算要爆炸呀!
def inference(input_x,input_x_field,zeroWeights,oneDimWeights,thirdWeight):
"""计算回归模型输出的值"""
secondValue = tf.reduce_sum(tf.multiply(oneDimWeights,input_x,name='secondValue'))
firstTwoValue = tf.add(zeroWeights, secondValue, name="firstTwoValue")
thirdValue = tf.Variable(0.0,dtype=tf.float32)
input_shape = input_x_size
for i in range(input_shape):
featureIndex1 = I
fieldIndex1 = int(input_x_field[I])
for j in range(i+1,input_shape):
featureIndex2 = j
fieldIndex2 = int(input_x_field[j])
vectorLeft = tf.convert_to_tensor([[featureIndex1,fieldIndex2,i] for i in range(vector_dimension)])
weightLeft = tf.gather_nd(thirdWeight,vectorLeft)
weightLeftAfterCut = tf.squeeze(weightLeft)
vectorRight = tf.convert_to_tensor([[featureIndex2,fieldIndex1,i] for i in range(vector_dimension)])
weightRight = tf.gather_nd(thirdWeight,vectorRight)
weightRightAfterCut = tf.squeeze(weightRight)
tempValue = tf.reduce_sum(tf.multiply(weightLeftAfterCut,weightRightAfterCut))
indices2 = [I]
indices3 = [j]
xi = tf.squeeze(tf.gather_nd(input_x, indices2))
xj = tf.squeeze(tf.gather_nd(input_x, indices3))
product = tf.reduce_sum(tf.multiply(xi, xj))
secondItemVal = tf.multiply(tempValue, product)
tf.assign(thirdValue, tf.add(thirdValue, secondItemVal))
return tf.add(firstTwoValue,thirdValue)
定义损失函数
损失函数我们就用逻辑回归损失函数来算,同时加入正则项:
lambda_w = tf.constant(0.001, name='lambda_w')
lambda_v = tf.constant(0.001, name='lambda_v')
zeroWeights = createZeroDimensionWeight()
oneDimWeights = createOneDimensionWeight(input_x_size)
thirdWeight = createTwoDimensionWeight(input_x_size, # 创建二次项的权重变量
field_size,
vector_dimension) # n * f * k
y_ = inference(input_x, trainx_field,zeroWeights,oneDimWeights,thirdWeight)
l2_norm = tf.reduce_sum(
tf.add(
tf.multiply(lambda_w, tf.pow(oneDimWeights, 2)),
tf.reduce_sum(tf.multiply(lambda_v, tf.pow(thirdWeight, 2)),axis=[1,2])
)
)
loss = tf.log(1 + tf.exp(input_y * y_)) + l2_norm
train_step = tf.train.GradientDescentOptimizer(learning_rate=lr).minimize(loss)
训练
接下来就是训练了,每次只用喂一个数据就好:
input_x_batch = trainx[t]
input_y_batch = trainy[t]
predict_loss,_, steps = sess.run([loss,train_step, global_step],
feed_dict={input_x: input_x_batch, input_y: input_y_batch})
跑的是相当的慢,我们来看看效果吧:

参考文章
1、https://tech.meituan.com/deep-understanding-of-ffm-principles-and-practices.html
2、https://www.cnblogs.com/ljygoodgoodstudydaydayup/p/6340129.html
3、https://www.cnblogs.com/pinard/p/5970503.html

时间:2019-01-17 22:36 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















