2018年AI和ML技术总结和2019年趋势(上)
1、简介:
过去几年一直是人工智能爱好者和机器学习专业人士最幸福的时光。因为这些技术已经发展成为主流,并且正在影响着数百万人的生活。各国现在都有专门的人工智能规划和预算,以确保在这场比赛中保持优势。
数据科学从业人员也是如此,这个领域正在发生很多事情,你必须要跑的足够的快才能跟上时代步伐。回顾历史,展望未来一直是我们寻找方向的最佳方法。
这也是我为什么想从数据科学从业者的角度退一步看一下人工智能的一些关键领域的发展,它们突破了什么?2018年发生了什么?2019年会发生什么?

我将在本文中介绍自然语言处理(NLP)、计算机视觉、工具库、强化学习、走向合乎正道的人工智能
2、自然语言处理(NLP)

让机器分析单词和句子似乎是一个梦想,就算我们人类有时候也很难掌握语言的细微差别,但2018年确实是NLP的分水岭。
我们看到了一个又一个显著的突破:ULMFiT、ELMO、OpenAI的Transformer和Google的BERT等等。迁移学习(能够将预训练模型应用于数据的艺术)成功应用于NLP任务,为无限可能的应用打开了大门。让我们更详细地看一下这些关键技术的发展。
ULMFiT
ULMFiT由Sebastian Ruder和fast.ai的Jeremy Howard设计,它是第一个在今年启动的NLP迁移学习框架。对于没有经验的人来说,它代表通用语言的微调模型。Jeremy和Sebastian让ULMFiT真正配得上Universal这个词,该框架几乎可以应用于任何NLP任务!
想知道对于ULMFiT的最佳部分以及即将看到的后续框架吗?事实上你不需要从头开始训练模型!研究人员在这方面做了很多努力,以至于你可以学习并将其应用到自己的项目中。ULMFiT可以应用六个文本分类任务中,而且结果要比现在最先进的方法要好。
你可以阅读Prateek Joshi关于如何开始使用ULMFiT以解决任何文本分类问题的优秀教程。
ELMO
猜一下ELMo代表着什么吗?它是语言模型嵌入的简称,是不是很有创意? ELMo一发布就引起了ML社区的关注。
ELMo使用语言模型来获取每个单词的嵌入,同时还考虑其中单词是否适合句子或段落的上下文。上下文是NLP的一个重要领域,大多数人以前对上下文都没有很好的处理方法。ELMo使用双向LSTM来创建嵌入,如果你听不懂-请参考这篇文章,它可以让你很要的了解LSTM是什么以及它们是如何工作的。
与ULMFiT一样,ELMo显着提高了各种NLP任务的性能,如情绪分析和问答,在这里了解更多相关信息。
BERT
不少专家声称BERT的发布标志着NLP的新时代。继ULMFiT和ELMo之后,BERT凭借其性能真正击败了竞争对手。正如原论文所述,“BERT在概念上更简单且更强大”。BERT在11个NLP任务中获得了最先进的结果,在SQuAD基准测试中查看他们的结果:
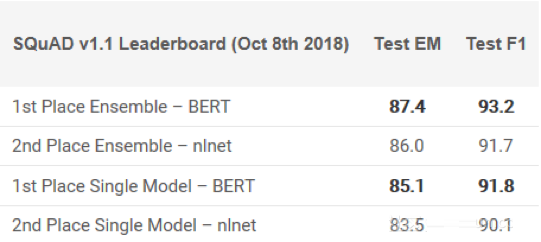
有兴趣入门吗?你可以使用PyTorch实现或Google的TensorFlow代码尝试在自己的计算机上得出结果。
我很确定你想知道BERT代表什么,它实际上是Transformers的双向编码器表示,如果你能够领悟到这些,那很不错了。
PyText
Facebook开源了深度学习NLP框架PyText,它在不久之前发布,但我仍然要测试它,但就早期的评论来说非常有希望。根据FB发表的研究,PyText使会话模型的准确性提高了10%,并且缩短了训练时间。
PyText实际上落后于Facebook其他一些产品,如FB Messenger。如果你对此有兴趣。你可以通过GitHub下载代码来自行尝试。
2019年NLP趋势:
塞巴斯蒂安·罗德讲述了NLP在2019年的发展方向,以下是他的想法:
预训练的语言模型嵌入将无处不在,不使用它们的模型将是罕见的。
我们将看到可以编码专门信息的预训练模型,这些信息是对语言模型嵌入的补充。
我们将看到有关多语言应用程序和跨语言模型的成果。特别是,在跨语言嵌入的基础上,我们将看到深度预训练的跨语言表示的出现。
3、计算机视觉

这是现在深度学习中最受欢迎的领域,我觉得我们已经完全获取了计算机视觉中容易实现的目标。无论是图像还是视频,我们都看到了大量的框架和库,这使得计算机视觉任务变得轻而易举。
我们今年在Analytics Vidhya花了很多时间研究这些概念的普通化。你可以在这里查看我们的计算机视觉特定文章,涵盖从视频和图像中的对象检测到预训练模型列表的相关文章,以开始你的深度学习之旅。
以下是我今年在CV中看到的最佳开发项目:
如果你对这个美妙的领域感到好奇,那么请继续使用我们的“使用深度学习的计算机视觉”课程开始你的旅程。
BigGAN的发布
在2014年,Ian Goodfellow设计了GAN,这个概念产生了多种多样的应用程序。年复一年,我们看到原始概念为了适应实际用例正在慢慢调整,直到今年,仍然存在一个共识:机器生成的图像相当容易被发现。
但最近几个月,这个现象已经开始改变。或许随着BigGAN的创建,该现象或许可以彻底消失,以下是用此方法生成的图像:

除非你拿显微镜看,否则你将看不出来上面的图片有任何问题。毫无疑问GAN正在改变我们对数字图像(和视频)的感知方式。
Fast.ai的模型18分钟内在ImageNet上被训练
这是一个非常酷的方向:大家普遍认为需要大量数据以及大量计算资源来执行适当的深度学习任务,包括在ImageNet数据集上从头开始训练模型。我理解这种看法,大多数人都认为在之前也是如此,但我想我们之前都可能理解错了。
Fast.ai的模型在18分钟内达到了93%的准确率,他们使用的硬件48个NVIDIA V100 GPU,他们使用fastai和PyTorch库构建了算法。

所有的这些放在一起的总成本仅为40美元! 杰里米在这里更详细地描述了他们的方法,包括技术。这是属于每个人的胜利!
NVIDIA的vid2vid技术
在过去的4-5年里,图像处理已经实现了跨越式发展,但视频呢?事实证明,将方法从静态框架转换为动态框架比大多数人想象的要困难一些。你能拍摄视频序列并预测下一帧会发生什么吗?答案是不能!
NVIDIA决定在今年之前开源他们的方法,他们的vid2vid方法的目标是从给定的输入视频学习映射函数,以产生输出视频,该视频以令人难以置信的精度预测输入视频的内容。

你可以在这里的GitHub上试用他们的PyTorch实现。
2019年计算机视觉的趋势:
就像我之前提到的那样,在2019年可能看到是改进而不是发明。例如自动驾驶汽车、面部识别算法、虚拟现实算法优化等。就个人而言,我希望看到很多研究在实际场景中实施,像CVPR和ICML这样的会议描绘的这个领域的最新成果,但这些项目在现实中的使用有多接近?
视觉问答和视觉对话系统最终可能很快就会如他们期盼的那样首次亮相。虽然这些系统缺乏概括的能力,但希望我们很快就会看到一种综合的多模式方法。
自监督学习是今年最重要的创新,我可以打赌明年它将会用于更多的研究。这是一个非常酷的学习线:标签可以直接根据我们输入的数据确定,而不是浪费时间手动标记图像。
文章原标题《A Technical Overview of AI & ML (NLP, Computer Vision, Reinforcement Learning) in 2018 & Trends for 2019》
译者:乌拉乌拉

时间:2019-01-16 00:03 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]人工智能十年回顾:CNN、AlphaGo、GAN……它们曾这
- [机器学习]20年以后,半数工作将被人工智能取代?这些“高危行业”有哪些
- [机器学习]人工智能十年回顾:CNN、AlphaGo、GAN……它们曾这
- [机器学习]年终总结:2021年五大人工智能(AI)和机器学习(ML)发展趋势
- [机器学习]神经科学如何影响人工智能?看DeepMind在NeurIPS2
- [机器学习]美俄人工智能军事应用
- [机器学习]民调不靠谱?人工智能预测拜登获胜
- [机器学习]人工智能正在误导我们的广告,是时候纠正这些错误了
- [机器学习]美国陆军研究如何组建人-人工智能系统团队
- [机器学习]数据科学vs.机器学习:有什么区别?
相关推荐:
网友评论:















