强化学习时代正在到来
强化学习是近来最热门也是成果最丰富的人工智能领域之一。之前为我们带来《深度强化学习》手稿的加拿大阿尔伯塔大学计算机系博士Yuxi Li 近日发表博文认为我们正迎来强化学习的时代,本文为该文章的中文版。
强化学习(RL)已经取得了斐然的成就,比如 Atari 游戏、AlphaGo、AlphaGo Zero、AlphaZero、DeepStack、Libratus、OpenAI Five、Dactyl、DeepMimic、夺旗,以及学习穿着打扮、冷却数据中心、化学合成、药物设计等。更多强化学习应用请参阅:https://medium.com/@yuxili/rl-applications-73ef685c07eb
其中大多数都是学术研究。但是,我们也正见证着强化学习产品和服务的诞生,比如谷歌的 Cloud AutoML 和 Facebook 的 Horizon,还有 OpenAI Gym、DeepMindLab、DeepMind Control Suite、Google Dopamine、DeepMind TRFL、Facebook ELF、Microsoft TextWorld、Amazon AWS DeepRacer、Intel RL Coach 等开源项目和测试平台。多臂赌博机方面(尤其是情景赌博机(contextual bandits))已有很多成功的应用。
后文将简要介绍强化学习,讨论强化学习近期的成果、问题、研究方向、应用和未来。总体而言想要说明一点:强化学习时代正在到来。
简要介绍
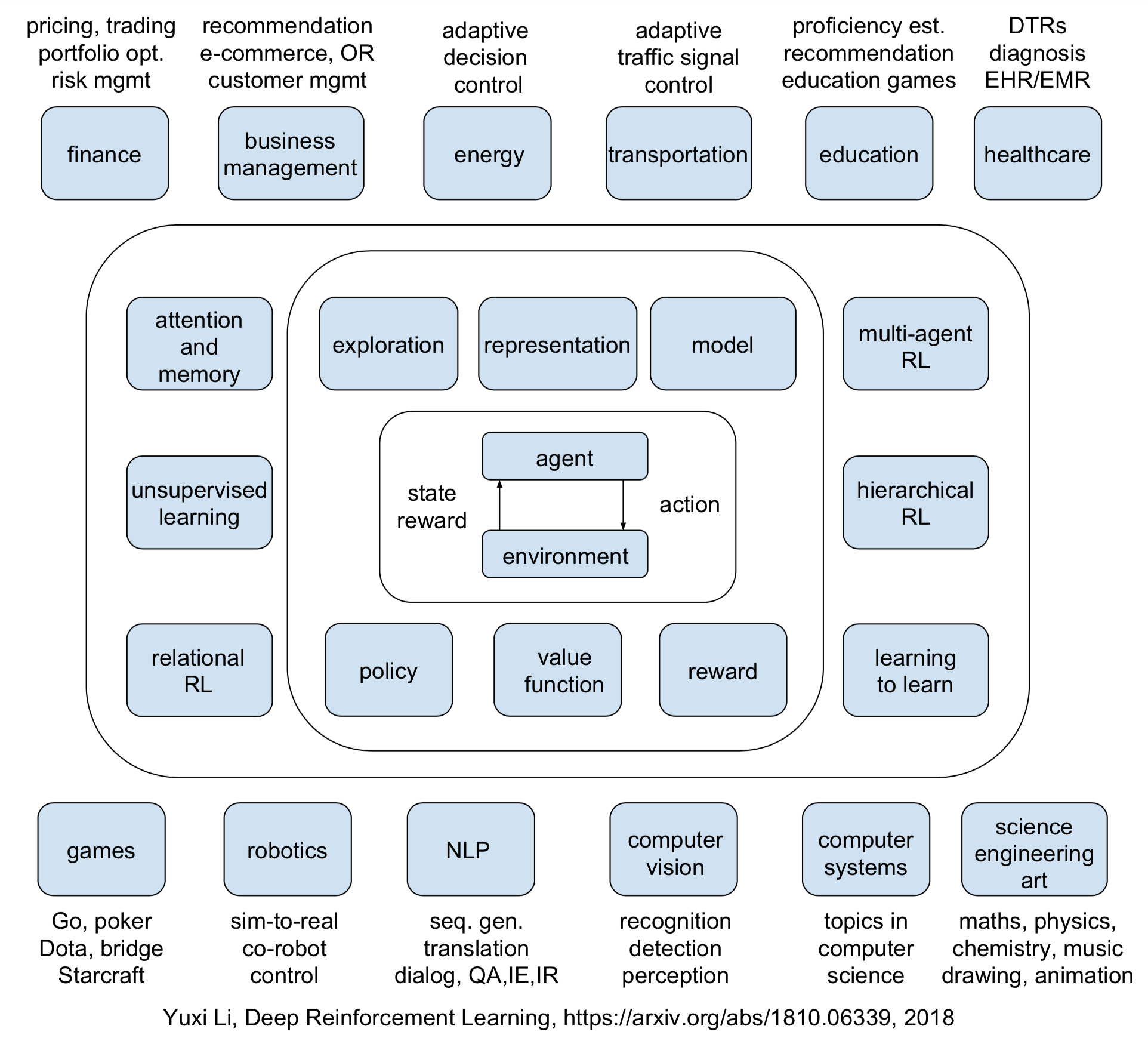
在自然科学、社会科学、工程学和艺术等范围广泛的领域,针对序列决策问题,强化学习智能体(agent)会通过试错方式与环境交互,随着时间学习到一个最优策略。
在每一个时间步骤,智能体都会接收到一个状态并遵循一个策略选择一个动作,这就是该智能体的行为,即从状态到动作的一个映射。智能体会接收一个标量的奖励,并会根据环境动态转换到下一个状态。模型直接关乎转换概率和奖励函数。智能体的目标是最大化一个长期回报的期望,即一个折扣的累积奖励。
监督学习通常是一次性的、短视的且考虑即时的奖励,而强化学习则是序列式的、目光长远且会考虑长期的累积奖励。
Russell 和 Norvig 的人工智能教科书指出:「也许可以认为强化学习包含了一切人工智能:放置在环境中的智能体必须学习以便在其中成功地行事」以及「可将强化学习视为整个人工智能问题的一个缩影」。研究也表明计算机科学领域具有可计算描述的任务都可以构建为强化学习问题的形式。这些都支持 David Silver 博士的假设:AI = RL + DL(人工智能=强化学习+深度学习)。
可参考下列资源了解更多有关强化学习的详细情况:
David Silver 博士的 UCL 强化学习课程:http://www0.cs.ucl.ac.uk/staff/d.silver/web/Teaching.html
DeepMind 和 UCL 的深度学习和强化学习课程:https://www.youtube.com/playlist?list=PLqYmG7hTraZDNJre23vqCGIVpfZ_K2RZs
Sergey Levine 教授的深度强化学习课程:http://rail.eecs.berkeley.edu/deeprlcourse/
OpenAI 的 Spinning Up in Deep RL:https://blog.openai.com/spinning-up-in-deep-rl/
Sutton 和 Barto 的强化学习著作:http://incompleteideas.net/book/the-book-2nd.html
一本有关深度强化学习的书籍草稿:https://arxiv.org/abs/1810.06339
一份深度强化学习资源汇集:https://medium.com/@yuxili/resources-for-deep-reinforcement-learning-a5fdf2dc730f

近期成果
我们已经见证了深度强化学习取得的一些突破:比如深度 Q 网络(DQN)、AlphaGo(以及 AlphaGo Zero 和 AlphaZero)、DeepStack/Libratus。它们每一个都代表了一大类问题和大量应用。DQN 可用于单玩家游戏和广义上的单智能体控制。DQN 为当前的深度强化学习普及浪潮掀起了最初的浪花。AlphaGo 可用于双玩家完美信息零和博弈。AlphaGo 在一个非常艰难的问题上取得了现象级的重大成果,成为了人工智能领域的一大里程碑。DeepStack 针对的是双玩家不完美信息零和博弈,这一类问题本身是很难解决的。与 AlphaGo 类似,DeepStack/Libratus 也在一个困难问题上取得了重大的进展,成为了人工智能的发展里程碑。
OpenAI Five 在 Dota 2 游戏上战胜了优秀的人类玩家。OpenAI 还训练了 Dactyl,可让类人式机器手灵活地操控实际物体。DeepMimic 模拟人形机器人来执行高度动态的、杂技般的技能。智能体也在多玩家游戏 Catch The Flag 中达到了人类水平,这是在掌握战术和战略团队协作上的进展。另外还有一个衣着模拟模型完成了穿着任务。强化学习也已经被用于数据中心冷却,这是在真实世界物理系统中的应用。化学合成领域已经在逆合成方面应用了强化学习。
我们也已经看到强化学习在产品和服务中得到了应用。AutoML 试图让人们更容易获取 AI。谷歌 Cloud AutoML 提供了神经网络架构设计自动化等服务。Facebook Horizon 已经开源了一个强化学习平台,可用于通知、视频传输比特流优化、改善 Messenger 中的 M 建议等产品和服务。亚马逊已经推出了一款实体的强化学习测试平台AWSDeepRacer,另外还有英特尔的 RL Coach。
这些成果之下的技术包括深度学习、强化学习、蒙特卡洛树搜索(MCTS)和自学习;它们还将有更广泛和更深入的应用和影响。
问题
强化学习领域存在很多概念、算法和问题。样本效率、稀疏奖励、信用分配、探索与利用、表征都是常见问题,也有人在努力试图解决它们。离策略在学习时既会使用在策略数据,也会使用离策略数据。辅助奖励和自监督学习是学习环境中的非奖励信号。奖励塑造(reward shaping)能提供更密集的奖励。分层强化学习可用于时间抽象。通用价值函数(GVF,尤其是 Horde)、通用价值函数近似器(UVF)和事后经验重放(HER)能够学习目标之间共有的表征/知识。探索技术可从有价值的动作中学到更多。基于模型的强化学习可以生成更多可供学习的数据。学习去学习(比如 one/zero/few-shot 学习、迁移学习和多任务学习)是通过学习相关任务以实现高效的学习。结构和知识的整合可帮助得到更智能的表征以及实现更智能的问题构建。
使用了函数近似的强化学习(尤其是深度强化学习)面临着一大问题,即由离策略、函数近似和 bootstrapping 的组合所导致的不稳定性和/或发散性。解决这一基础问题的努力有很多,比如梯度时间差分(GTD)、平滑的贝尔曼误差嵌入(SBEED)和 non-delusional算法。
可再现性是深度强化学习的又一问题。实验结果会受超参数的影响,其中包括网络架构和奖励规模、随机种子和试验、环境和代码库。
强化学习与机器学习还有一些共有问题,比如时间/空间效率、准确度、可解释性、安全性、可扩展性、稳健性、简洁性等。

研究方向
我们有必要研究基于价值的方法、基于策略的方法、基于模型的方法、奖励、探索与利用、表征。这 6 个核心元素在这本深度强化学习草稿中也有探讨:https://arxiv.org/abs/1810.06339 。有 6 大重要机制分别在(深度)强化学习的不同方面发挥着关键性作用,即注意和记忆、无监督学习、分层强化学习、多智能体强化学习、关系强化学习、学习去学习。
深度强化学习一书中讨论了六个研究方向,包含挑战和机会。研究方向一是对深度强化学习算法进行系统性的比较研究,这涉及到可再现性以及深度强化学习算法表面下的稳定性和收敛性。研究方向二是「解决」多智能体问题,这涉及到在大规模、复杂以及可能存在对抗性的设定中的样本效率、稀疏奖励、稳定性、非定态性(non-stationarity)和收敛性。研究方向三是从实体而不只是原始输入学习,这涉及到样本效率、稀疏奖励和可解释性,需要整合更多知识和结构。研究方向四是为强化学习设计最优的表征。研究方向五是自动强化学习。研究方向六是用于现实生活的(深度)强化学习。这些涉及到整个强化学习问题,也即强化学习领域中涉及到表征、自动化和应用的各个角度的所有问题。我们预计所有这些研究方向都还会继续存在,但第一个除外,不过它也是很有挑战性的。而这些方向的进展将会加深我们对(深度)强化学习的理解以及推动人工智能前沿的进一步发展。
Rich Sutton 教授重点强调了利用学习到的模型进行规划的重要性。Yann LeCun 教授讨论过世界模型的学习,尤其是自监督学习。Yoshua Bengio 教授讨论过解离式表征(disentangled representation)。
有越来越多的研究在致力于开发构建能像人类一样学习和思考的机器,并且也在整合经典人工智能的组件,比如因果、推理、符号主义等。因果推理和关系学习得到的关注尤其多。更多内容请查阅 https://arxiv.org/abs/1810.06339
应用
《深度强化学习》中讨论了 12 个应用领域,包括游戏、机器人、自然语言处理、计算机视觉、金融、业务管理、医疗保健、教育、能源、交通运输、计算机系统以及科学、工程和艺术。最后一项「科学、工程和艺术」几乎涵盖了一切,这传递出了一个信息:强化学习和人工智能将无处不在。
强化学习是一种用于序列决策问题的解决方案式的方法。但是,某些问题表面上看似不是序列式的,也能被强化学习成功解决,比如神经网络架构设计。一般而言,如果一个问题可以被看成或可以转换成一个序列决策问题,并且可以构建出状态、动作以及可能的奖励,那么强化学习都可能提供帮助。粗略地讲,如果一个任务涉及到某种人工设计的「策略」,则就有可能能用强化学习帮助自动化和优化该策略。
强化学习在波束搜索策略、数据库联合查询、主动学习、问题合成、模型压缩和加速、驱动器管理等方面都有有趣的应用。
强化学习有一个具体应用方向是扩展 AlphaGo 技术。正如 AlphaGo 的作者在他们的论文中建议的那样,以下应用还值得进一步研究:广义上的游戏(尤其是视频游戏)、经典规划、部分可观察的规划、调度、约束满足、机器人、工业控制、在线推荐系统、蛋白质折叠、降低能耗、寻找革命性的新材料。化学合成就是一个很好的例子。
要让强化学习用在现实生活应用中,我们需要考虑数据和计算的可用性。AlphaGo 的成功就得益于其完美的围棋模型(可以生成大量训练数据)和谷歌级的计算能力。对于机器人、医疗保健和教育等一些应用而言,我们通常还没有优良的模型,因此不容易得到大量数据。离策略的策略评估是一种解决这一问题的方法。
讨论
前文讨论了强化学习近期的进展、问题、研究方向和应用。下面我将介绍几位研究人员的观点。
David Silver 教授总结了深度强化学习的原则:评估推动进步,可扩展性决定成功,泛化能力保证算法的未来,对智能体的经验和状态的信任是主观的,控制流,价值函数建模世界,规划,从想象的经历中学习,为函数近似器赋能,学习去学习。
Dimitri Bertsekas 教授对强化学习的未来(包括其在现实生活中的应用)的态度是谨慎乐观。以下内容直接引用自他的幻灯片:
♦ 可广泛应用的方法:可以解决范围广泛的难题。确实-随机-动态,离散-连续,等。
♦ 没有任何方法能确保对所有甚至大部分问题都有效。
♦ 对于大多数类型的优化问题,都有足够多的可尝试的方法且它们都有相当好的成功可能性。
♦ 理论的作用:引导前沿发展,描绘可行的想法。
♦ 所有方法都有困难的实现问题,而且没有防误操作的方法。
♦ 问题近似和特征选择需要领域特定的知识。
♦ 不同于你通过阅读文献可能形成的看法,训练算法可能并没有那样有效。
♦ 近似策略迭代涉及到振荡。
♦ 很难认定成功或失败!
♦ 强化学习在游戏领域的成功很惊人,但这得益于完美已知的和稳定的模型以及(每个状态)少量的控制。
♦ 具有部分可观察状态的问题依然是一大难题。
♦ 大规模计算能力与分布式计算很有希望。
♦ 一线曙光:我们可以开始解决一些难度超乎想象的实际问题!
♦ 前路激动人心!
Sutton 和 Barto 的强化学习著作《Reinforcement Learning: An Introduction》很直观。Bertsekas 和 Tsitsiklis 的《Neuro-Dynamic Programming》(神经动态规划,接近(深度)强化学习)是理论方面的。Bertsekas 教授有一本新的强化学习和最优控制著作《Reinforcement Learning and Optimal Control》。如果我们称 Sutton 教授是强化学习之父,那么 Bertsekas 教授就是强化学习的叔叔。
我们看到,不仅重视基础研究的研究者对强化学习有积极的态度,而且 Google Cloud AutoML 和 Facebook Horizon 等产品和服务也在部署强化学习。
预测是很困难的,尤其是预测未来。很多博客探讨过强化学习的重要性,尤其是在 2019 年。强化学习是 MIT Technology Review 2017 年的 10 大突破性技术之一,深度学习入选了 2013 年的榜单。对于广义上的人工智能,Geoffrey Hinton 教授说过:「不,不会再有一个人工智能冬天了,因为它驱动着你的手机。在之前的人工智能冬天,人工智能还没有真正成为你的日常生活的一部分。而现在已经是了。」吴恩达博士提供了一份人工智能转换手册:https://landing.ai/ai-transformation-playbook/
在基础研究和现实生活应用方面,强化学习一直在积累量的变化,这将会导致质的变化。要记得,挑战与机遇并存,有证据表明强化学习时代正要来临。
原博文:https://medium.com/@yuxili/e3-cb5325d60381
《深度强化学习》:https://arxiv.org/abs/1810.06339

时间:2019-01-10 00:07 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]人工智能十年回顾:CNN、AlphaGo、GAN……它们曾这
- [机器学习]20年以后,半数工作将被人工智能取代?这些“高危行业”有哪些
- [机器学习]人工智能十年回顾:CNN、AlphaGo、GAN……它们曾这
- [机器学习]AI 发展方向大争论:混合AI ?强化学习 ?将实际
- [机器学习]年终总结:2021年五大人工智能(AI)和机器学习(ML)发展趋势
- [机器学习]神经科学如何影响人工智能?看DeepMind在NeurIPS2
- [机器学习]美俄人工智能军事应用
- [机器学习]民调不靠谱?人工智能预测拜登获胜
- [机器学习]人工智能正在误导我们的广告,是时候纠正这些错误了
- [机器学习]监督学习、非监督学习、强化学习都是什么?终于有人讲明白了
相关推荐:
网友评论:















