「回顾」爱奇艺搜索排序模型迭代之路
一、摘要
本次分享内容为爱奇艺在做视频搜索时,遇到的真实案例和详细问题;以及面对这些问题的时分,我们的处理计划。这次分享的 ppt 针对一线的开发人员,希望能够给一线的开发人员提供一些启示。
二、引见
首先引见一下我们支持的搜索入口,在我们 app 的搜索框里,支持下图所示的搜索方式:图搜索、台词搜索、语音搜索。

今天赋享的,其实还是一个愈加通用的搜索方式,即文本查询。经过把用户输入的文本做自然言语处置后停止的关键字查询,在此,我们做了很多自然言语处置和语义的了解。
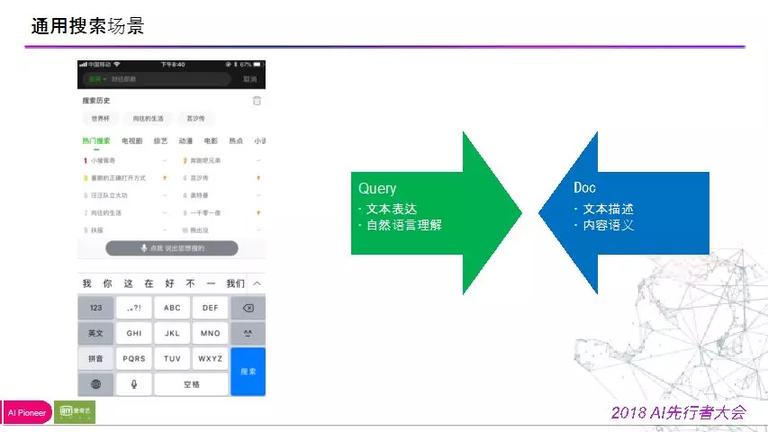
在视频内容层面,最重要的是视频自身的描绘信息,如标题,演职人员等信息。还有一个是内容的语义,我们当前并不是多模态特征去抽取,更多的是经过用户对该视频的观看行为,如搜索、阅读、评论、弹幕等各种行为,由此产生的数学构造去抽取语义信息。所以我们今天更关注在 doc 层和 query 层是如何做这些匹配的。
在引见详细的匹配过程之前,我们先理解一下一个通用的搜索系统的约束条件(下图所示):
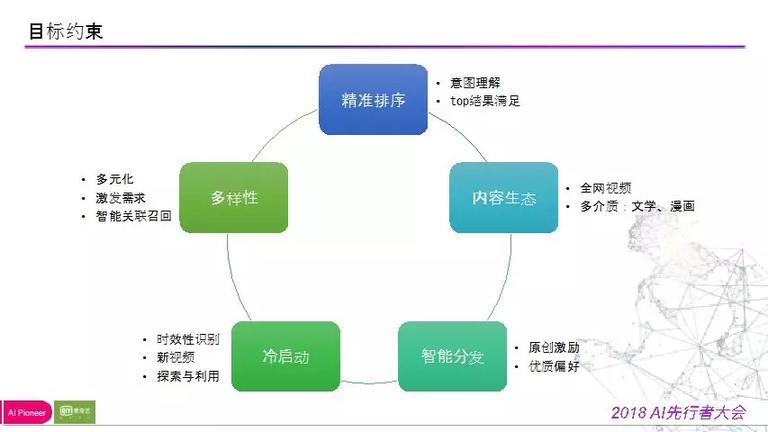
1) 精准匹配,用户搜什么词,展示什么内容,而且需求 top 结果排序;
2) 内容生态,爱奇艺的视频搜索不只仅是站内搜索引擎,而是全网的视频搜索引擎,所以我们会包括一切中文的视频资源,包括我们没有版权的视频,我们希望打造的是,协助用户链接到想要的资源,同时我们还支持文学、漫画资源的搜索;
3) 智能分发,搜索结果有不同的版权方,我们需求对原创结果停止鼓励,避免略币驱赶良币,载流量上给优质资源停止扶持;
4) 冷启动问题,新视频相比于老视频在特征上相对弱势,我们需求给予冷启动空间,在此做一些探究和应用;
5) 搜索多样性,避免靠前结果都是一样的。
此外,我们发现,当用户在搜索产生的结果使得本身的的主需求得到满足的时分,能够激起用户一些其他的语义相关的结果。
在这样五个约束条件下,我们如何搭建全网的搜索引擎呢?下图即是我们的整体系统框架。
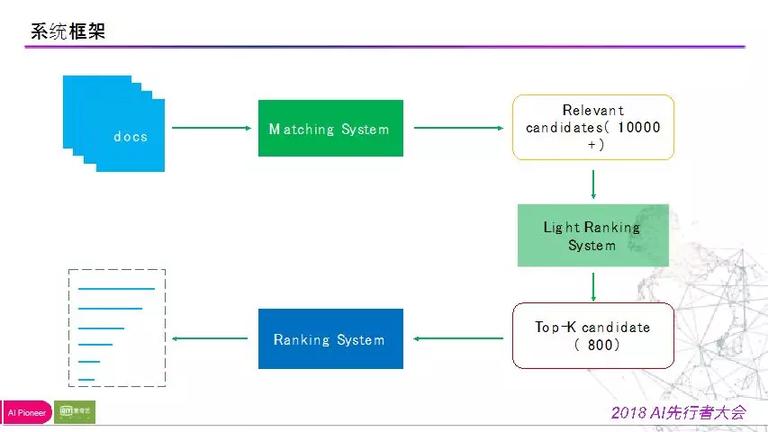
我们有大量视频资源,经过召回系统,即基于文本匹配的 matching system,得到候选集,经过粗排和精排,最后返回给用户,这是大致的流程图,其中最重要的是召回系统和排序系统。
两个系统的重要模块很多,下图罗列其中一些:包括改写纠错,根底召回,学问图谱召回,语义匹配召回;排序模块关注特征工程,学习模型的选择,模型交融与智能决策。
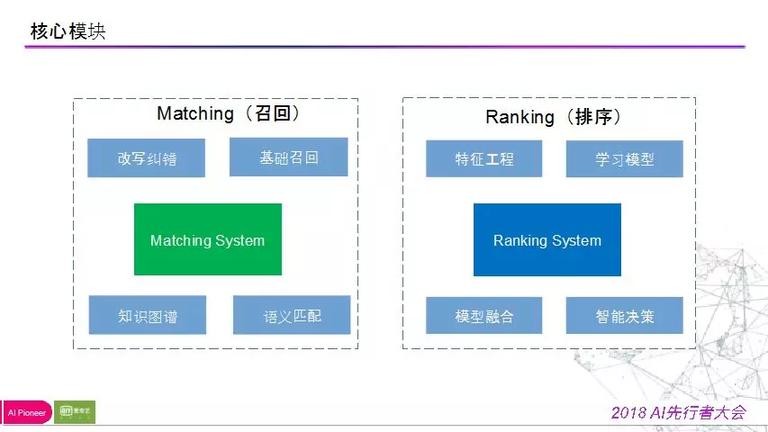
在此我们将要展开的是我们是如何停止一步步迭代的。
第一, 召回战略的迭代,我们从根底相关性渐渐走到语义相关性的途径;
第二, 排序模型的尝试。
三、 召回战略迭代
1. 根底相关性
首先是根底相关性,搜索引擎处置流程图如下:
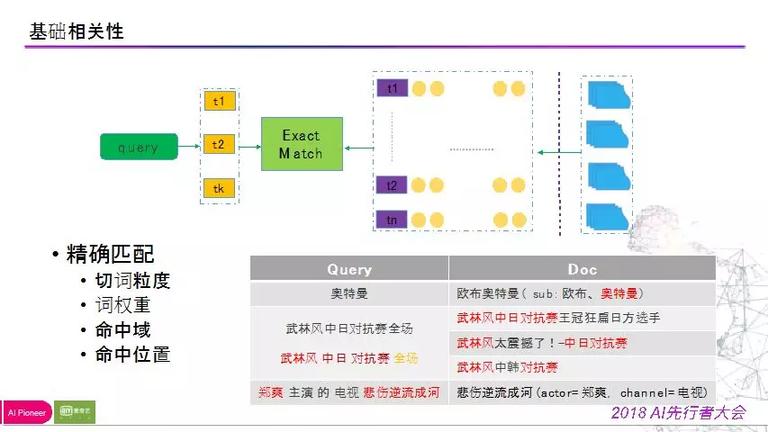
经过对用户的 query 停止切词,将右边的视频资源的文本描绘信息构建构建倒排索引,此过程为准确匹配过程,词匹配则倒排索引拉回归并,然后返回用户,此过程较为经典,在传统的搜索引擎也是比拟成熟的应用方式。
这样一个流程里面,它处理的问题也比拟通用:
1) 切词粒度,不同的词的粒度会影响你能否能够经过倒排索引召回内容;
2) 词权重,一个 query 中,哪些词是重要的,哪些是不重要的,会影响你在相关性计算的时分的最终得分。
这其实是根底相关性中需求处理的问题,也是我们在 1.0 版本中,花了很多力气去处理的问题。需求留意的是,上面的问题并没有最优解,这是一个依据 bad case 不时做优化的过程。
这里举个例子,如下图(例子描绘见视频):
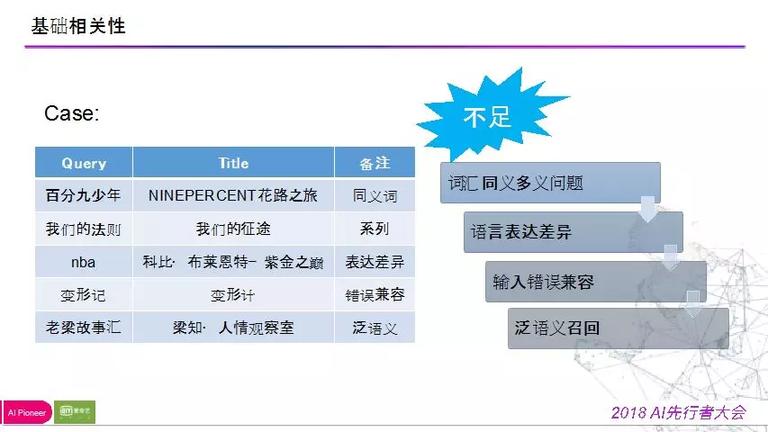
根底相关性处理不了的问题,我们归为四类:词汇的同义多以问题、言语表达差别、输入错误兼容、泛语义召回。
2. 语义相关性
在处理根底相关性遇到问题的时分,我们再来考虑一下,在文本匹配上是怎样处理语义的问题,如下图所示:
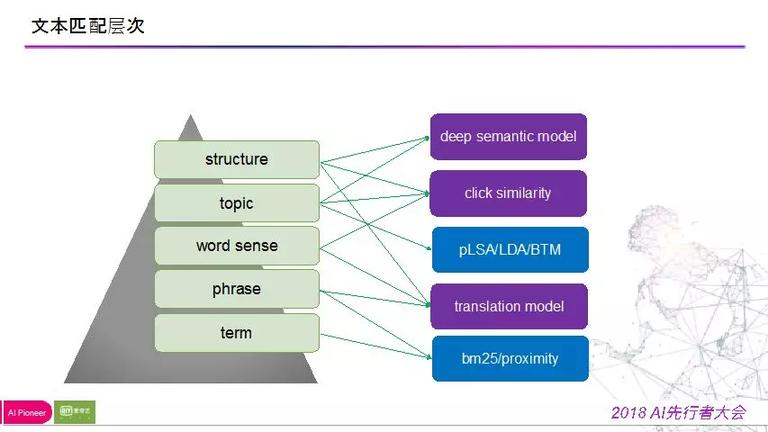
左边是 XX 教师整理的五个层面:词、词组、词义、主题、构造。在搜索场景下:我们有自然的用户搜索之后的点击行为,基于点击行为,我们能够在不同层面做语义匹配,紫色框是我们要处理的问题所用到的技术。
下图是机器翻译模型:
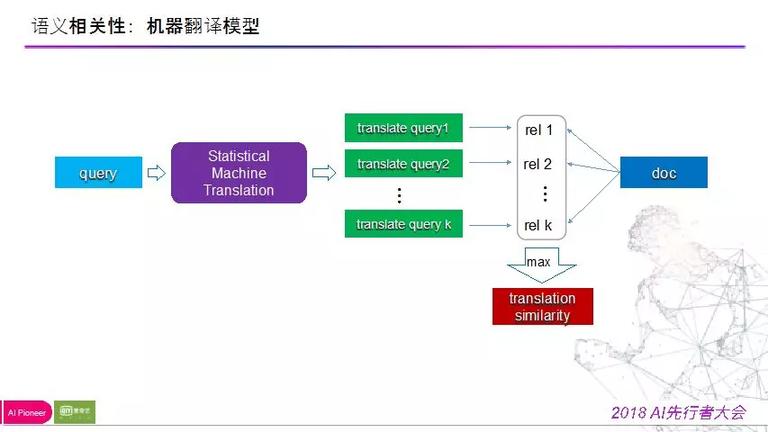
机器翻译是一个目前比拟炽热的范畴,并且在深度学习呈现之后,其精确率得到了飞跃性的进步。这是我们处理语义相关性的第一个手腕。
2.1 翻译模型
由于用户在搜词的时分,并不会去把相关词汇都搜索一遍,这就需求由搜索引擎去拓展用户的查询词汇。经过翻译系统,能够将查询词转化成与语义需求相同的其他词汇,用这些扩展后的新词与视频做相关性计算,取 top 结果返回给用户,以此来完成拓展词召回。
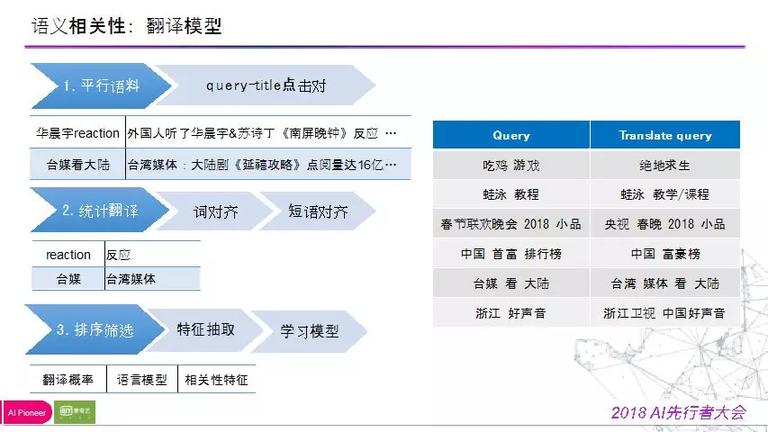
详细战略为:
第一步:依据用户的 query 以及点击的 document 生成 doc-query 点击对,以此来构建翻译的平行语料对;
第二步:做词对齐和短语对齐,此时,我们并没有用到很多深度学习的技术,由于在搜索场景下,并不需求翻译结果的精确性,更为重要的是拓展出来的词汇是不是有意义的,是不是让这个系统往正向开展的;
第三步:query 中的词汇与拓展的词汇行程映射对,在映射对里会存在噪音,针对噪音,传统的基于统计的短语和基于词的翻译模型会存在一些问题,我们再重新标注一局部翻译的 ground truth。
在这个根底上,我们依据翻译模型给出的翻译概率,并经过言语模型判别翻译结果能否通畅,再分离相关性的特征来甄别翻译对能否有效。
基于这样翻译过程拓展出来的词汇,可以明显拓宽我们召回的范围,这是第一个处理语义相关性的手腕。
2.2 点击相关性
第二个处理语义相关性的手腕是点击相关性。
做一个假定,当用户有一个搜索需求时,假定其用到的搜索词和编辑取的标题不在同一个语义空间,那么该场景形成的 mismatch 现象会十分严重。那么此时,我们就需求把二者映射到同一语义空间,以提升命中概率。
详细做法:应用搜索点击日志,来构建一个搜索点击二部图。如下图中能够看到:doc4 与 query2 和 query4 和 query6 有较强的相关性,固然此时我们并不晓得 doc4 是什么内容,但是我们已然不难看出,三个 query 词之间具有较强的相关性,并且这个结论的置信度也是很高的。
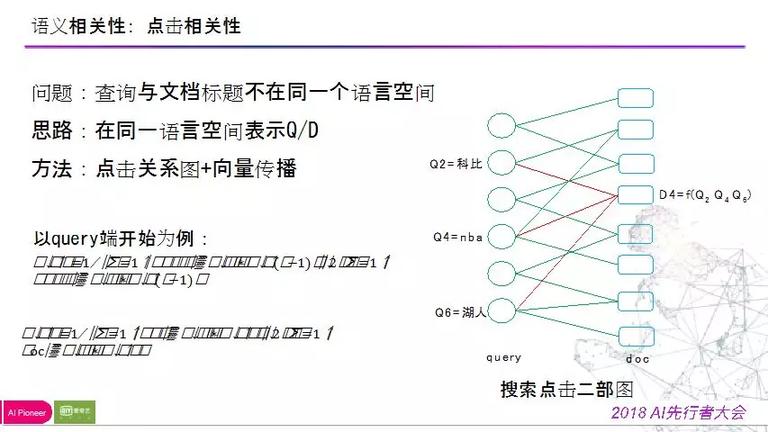
这关于查询结果来说是一个不错的拓展方式;在这样的二部图中,我们能够停止屡次的迭代,并以次来拓展 query 的表达。
在构建二部图的时分有许多高应战性的事情:
**1) ** 图的构建,点击存在噪音,图的内容足够高的置信度;边的权重设计,由于展现数量散布不均,点击数量散布不均,会影响向量传播权;
2) 迭代次数越多,向量传播途径越来越长,泛化才能越强,但是精确率会降落,需求选择最佳迭代次数;
**3) ** 点击关系链接未呈现的话,在二部图中是无法呈现的,该战略需求用 n-gram 来拆解拟合,最后用动态规划去选择最优的表达向量。
如下图所示,右侧为一个例子。

2.3 深度学习
第三个处理予以相关性的手腕是深度学习,该方式在 nlp 中应用十分普遍。在搜索场景下,用一些 nlp 工具,可以把词表示成低维的向量,该向量能够表示词与词之间的相关性,在网络里面参加 rnn,cnn 等机制,把网络做的足够复杂,以提取愈加有效的匹配的特征。同时,我们在文本匹配或者搜索语义匹配的时分,其实要做的就是计算多个文本词序列之间的相关性,我们把词向量和网络分离在一同就能够处理该问题。
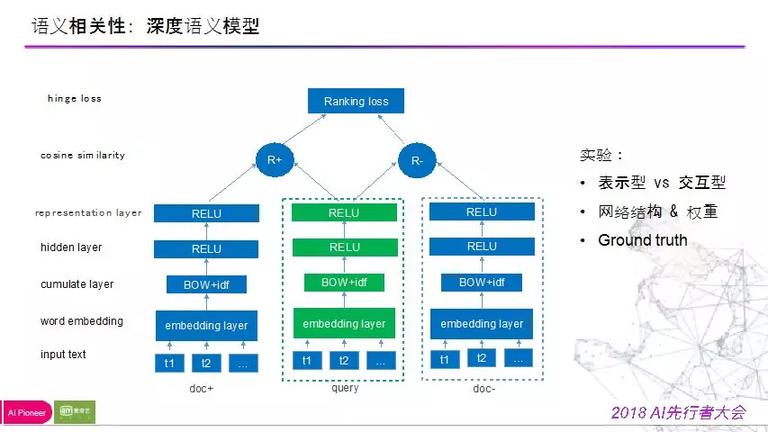
在传统的语义文本相关性中有两种计算框架:
1) 基于表达:将文本串经过模型来表示成向量,并用向量类似度来计算文本类似性(如 dssm);
2) 基于交互:在最底层将 query 和 document 中的每个词都计算相关性,以此得到相关性矩阵。
如下图所示:

我们当前的战略是基于表达,如下图所示框架:首先,抽取 query 下的正负样例;之后,做多粒度切词,用 embedding 做加权均匀,得到文本串的向量表示;再经过两个全衔接层生成正样例相关性和负样例相关性;在此根底上,结构损失函数使得正样例大于负样例相关性,用反向传播来优化网络参数。
在视频短文本场景下:表达型方式比交互型方式效果好;网络构造和权重对结果影响很大,idf 权重很高;最难点在于 ground true 构建,严重影响语义模型的效果。
下图是准确匹配 2.0 的版本,在这个版本我们基于翻译模型把 query 停止查询词拓展,同时 click-simi 的方式去拓展点击相关性的查询词,然后去搜索原倒排索引和语义倒排索引,最后基于相关性模型去计算 query 和视频内容能否相关。
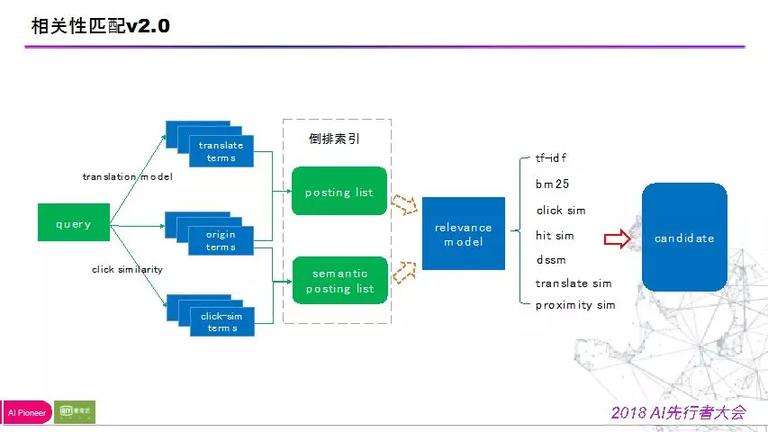
以上是在处理根底相关性的 bad case 的时分,应用的语义相关性的技术,这些技术是学术界提出的,在工业界经过 a/b test,不时的尝试后得出的比拟胜利的案例。
四、 排序战略迭代
接下来,我们要引见的是,在召回了许多跟用户相关的视频之后,面临的排序问题。其实排序问题也有一个逐步演进的途径:战略排序,学习排序,深度学习模型。
搜索排序面临问题如下:
用户 query 的时效性(新闻资讯 & 老电影,游戏 & 电视剧);
query 场景(新颖度、语义召回、视频来源、历史点击表现等)。
综合思索之后,做了一个最初的基于战略的版本,肯定了用户的关注要点:
1) 相关性;
2) 质量度,质量更好的结果排在前面如时效性;
3) 时效性,视频从上传开端,其相关性随着时间不时衰减;
4) 点击行为。
四种要素组合加上产品战略以及规则返回给系统,该版本能够处理大多数常见问题。
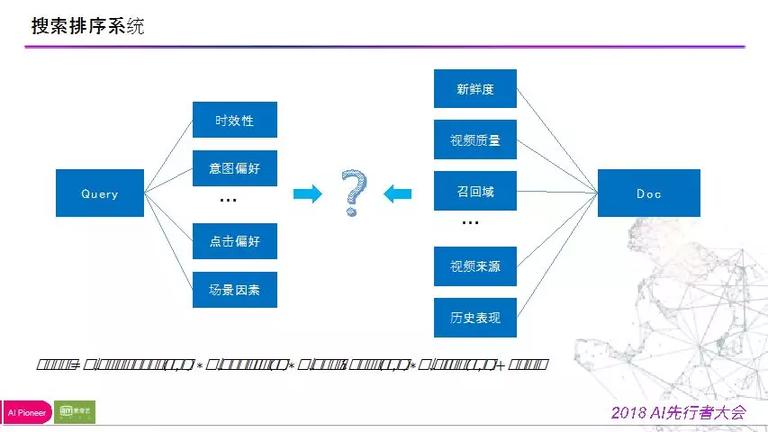
后面当我们的特征越来越多的时分,以上四个要素曾经开端很难全面地涵盖各种排序因子了。所以,我们需求理解:战略系统无法得到最优解,由于需求不时依据经历去尝试参数。
所以后面迁移到了学习系统,基于用户在历史的排序结果的点击行为搜集起来结构 label,依据用户在搜索时分给出的 query 以及展示给用户的 video 以及上下文信息结构特征向量,与 label 停止 join,得到 ground turth,之后进入学习系统停止学习,锻炼处一个排序模型,就能够对数据停止预测排序。
下图是排序系统的整体流程:
关于一个排序系统,应战来自于四点:
1) 优化目的:
point wise,相关不相关;
pair wise,A 优于 B;
list wise,使得排序效果最优化。
由于不同的损失函数反响的目的请求的严厉水平,会影响最终的模型从样本中学习的水平;
2) 样本:如何构建正负样本,正负样本比例以及权重对模型会产生要大影响;
3) 特征:先颜特征,后验特征,高维稠密特征;
4) 模型:学习才能,泛化才能。
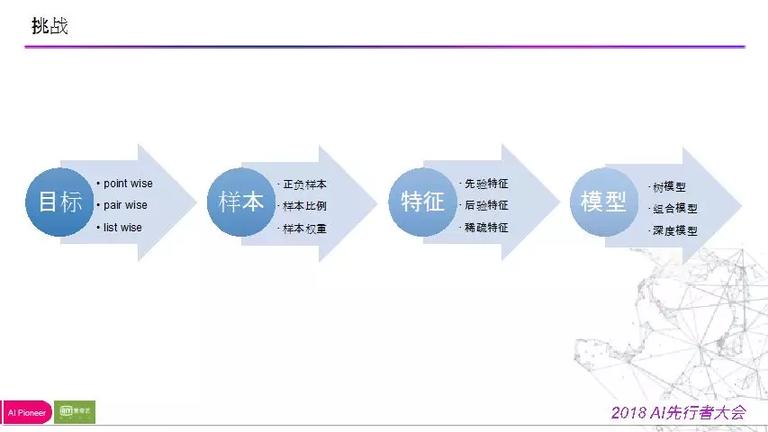
在我们的场景中,
1) 关于目的:
我们最开端选择的是 list wise 办法。我们采用的优化指标是 ndcg,这在搜索引擎中是应用的十分普遍的评价指标。它包含两个参数:
r(i) 代表第 i 个结果的相关性,
i 代表 i 个结果的排序位置。
直观了解:i 越小,r(i) 越大,ndcg 越大,越靠前的结果约相关,这个指标就越高。
这个和搜索引擎的优化目的十分贴近,因而选择这样的 list wise 学习的优化目的。
2) 关于样本:
用户的点击行为,点击并不代表喜欢,点击后的行为也需求思索进来,如:点击后观看了多长时间,观看时间占整个视频时间几,观看市场散布如何,最后会将其映射称观看称心度,量化为三个等级:excllent, good, normal
负样例:skip-above 看到的没有点为负样例,相关性负采样,排序靠后的位置做随机负采样,从而构建学习样本。
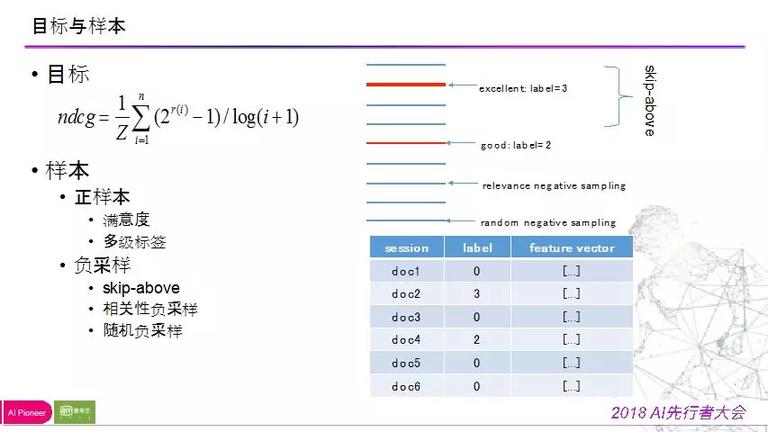
**
3) 关于特征:
与业务分离十分严密,如何把排序场景描绘的十分精确,把固定问题泛化,在向量的维度表达出来,即特征提取。Query 维度:企图类别(喜欢那个类型的数据),时效性偏好;document 维度:质量特征(码流、码率、用户评论、视频帧、视频标签、类别、来源等);相关性特征:命中特征,bm25 等;后验特征:包括用户真实点击率,观看时长,称心水平、点击位置(马太效应影响)、各种维度穿插特征。如下图所示:
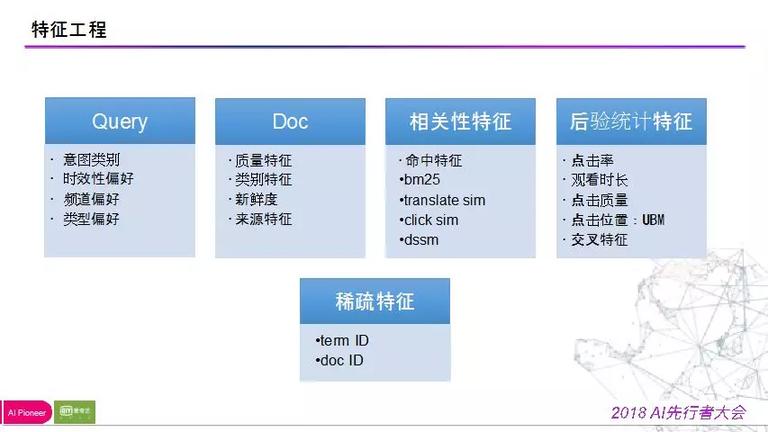
以上是我们在刚迁入机器学习时所采用的特征。
后面我们发现,id 特征也是有重要意义的,在特征工程中应该予以思索,由于我们在提取相关性特征时,是把相关性综合到一个特征中的,该方式丢掉了一些原始信息,那么,如何把这些信息放进去?
另外,query 的点击列表,或者说用户的观看列表其实是能够反映出视频的关联信息的,这种信息其实有利于我们做排序优化,我们如何应用这些信息?
所以,第二个版本我们的特征工程中,增加了稠密的 id 类特征。
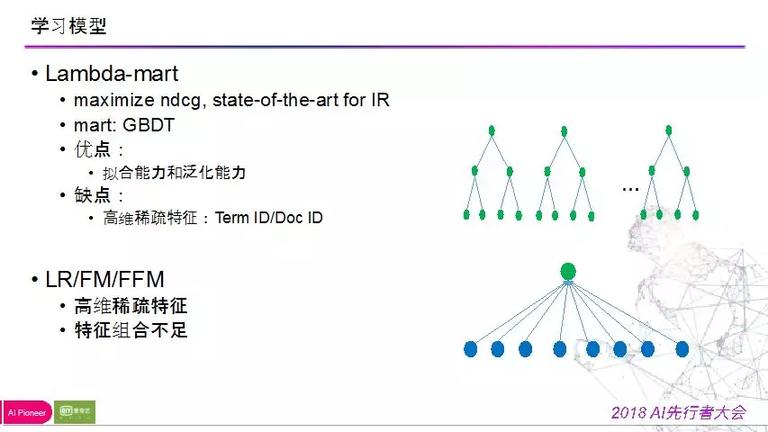
在没有参加稠密类特征之前,我们的模型是 lambda-mart 模型,在 IR 范畴是最先进的模型,该模型是一个 gbdt 模型,基于 boosting 思想,不时增加决策树,来减小残差。该模型在很多竞赛中表现良好,由于不用过多的特征处置,树模型会思索特征自身的数据散布,同时有很好的学习泛化才能,树构造很难兼容高维稠密特征,比如说我们的 document 是上亿级的特征,很难每个节点走一次树的分割,所以关于参加稠密特征的时分,树模型会遇到瓶颈。但是在出来高维稠密特征的时分,像 LR、FM、FFM 能够以为是线性模型,特征的增加并不会对此类模型形成压力,上亿维也没关系。LR 模型弱点在于特征组合才能缺乏,很多状况下特征组合方式比拟重要,树模型从根节点到叶子节点的途径其实是一种组合方式。如下如所示:
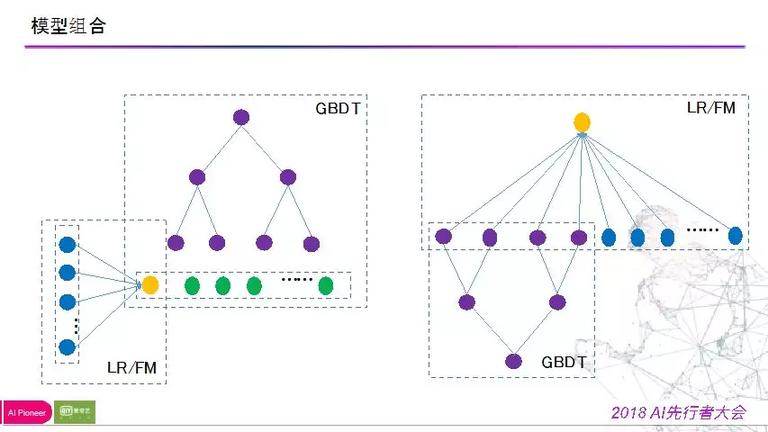
所以针对两类模型的优缺陷,我们做了进一步的模型交融的尝试:
第一种方式,用 LR 模型把高维稠密特征停止学习,学习出高维特征,把该特征和原始特征做拼接,学习 gbdt 模型。
该办法效果不好,提升很弱。
** 剖析缘由:** 把高维特征刚在一个特征去表达,丢掉了原始的特征。
第二种方式,用 gbdt 去学,学习后把样本落入叶子节点信息来进来与高维稠密特征拼接,在此根底上用 LR 学习。
该模型效果变差。
** 剖析缘由:** 点击类和穿插类特征是对排序影响最大的特征,这类特征和大量的稠密类特征做拼接的时分,招致重要性被稀释了,招致模型的学习才能变弱。
两次尝试的模型框架如下图所示:
经过这两种不胜利的实验之后,我们引入了基于 dnn 的排序模型,此模型也需求处理:稠密特征和稠密特征如何去综合的问题。
如图是我们的 dnn 排序框架:
底层是 query 和 document 的一些描绘文本做多粒度切词,之后做 embedding 然后做加权均匀,得到 document 和 query 的向量表达,拼接这两组向量,同时再做点积,(两个向量越来越相近,拼接的时分希望上层网络学到两个向量的类似性,需求有足够的样本和正负样例,所以我们本人做了点积),同时用稠密特征,即在 gbdt 中用到的特征抽取出来,与 embedding 特征做拼接,最后经过三个全衔接层,接 sigmoid 函数,就能够得到样本的 score,并在此根底上用 ndcg 的权衡规范去计算损失,从而反向优化网络构造。
而在 online 效劳侧,则直接用样本去 predict 得分。这个模型上线之后,效果十分明显。其中,二次搜索率降低(二次搜索率越低越好,阐明用户一次搜中)。
五、 总结
最后做一个总结,我们在做搜索引擎算法迭代的根底上,不断沿着两条路:相关性迭代,怎样去计算更精确,召回更多结果,包括根底相关性,语义匹配以及学问图谱优化相关性计算;同时在排序模型,丛集与战略的模型演化到机器学习的模型,后面处理稠密特征和稠密特征交融的深度学习的排序模型。最后还有做冷启动的时分用到的强化学习的模型,不过时间有限,在此不做细致引见了。

时间:2018-12-28 22:50 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]Attention!当推荐系统遇见注意力机制
- [机器学习]机器学习基础图表:概念、原理、历史、趋势和算法
- [机器学习]万物皆可Graph | 当推荐系统遇上图神经网络
- [机器学习]ResNet、Faster RCNN、Mask RCNN是专利算法吗?盘点何恺
- [机器学习]YOLO算法最全综述:从YOLOv1到YOLOv5
- [机器学习]推荐系统架构与算法流程详解
- [机器学习]YOLO算法最全综述:从YOLOv1到YOLOv5
- [机器学习]贝尔实验室和周公“掰手腕”:AI算法解梦成为现
- [机器学习]性能超越GPU、FPGA,华人学者提出软件算法架构加
- [机器学习]GPT-3的威力,算法平台的阴谋
相关推荐:
网友评论:















