「回顾」NLP 在网络文学领域的应用

配套 PPT 下载,请辨认底部二维码关注社区公众号,后台回复【上海 NLP】
分享嘉宾:马宇峰** 阅文信息 内容发掘平台技术担任人**
编辑整理:赵世瑜
内容来源:DataFun AI Talk《NLP 在阅文内容发掘平台的应用场景与落地理论》
出品社区:DataFun
注:欢送转载,转载请注明出处。
一、业务背景
网络文学的开展已有 20 年的时间,阅文从开展之初的不太看好,再到如今开展为 400 亿港币市值的阅读平台和文学 IP 巨头。他的开展进程并不是那么好事多磨,但却也契合了当前人们对物质文化的热切需求。目前很多网络小说曾经改编为电影或电视剧,按每天每人阅读消费带动收入,能够说网络小说在泛文娱场景下已无处不在。
1.1 开展进程
从中国参加国际互联网以来,网络小说不断是相互竞争的范畴,简直互联网的巨头都想对这个范畴进行浸透。其缘由主要是小说是 IP(Intellectual Property)的一个来源,为了抢夺这样一个来源,很多公司都会在网络小说方面进行规划。2016 年阅文统一网络小说后,竞争仍在继续,如如今的爱奇艺文学以及头条传媒平台,都在做网络小说。
网络小说主要是创作式平台,作者在里面占有无足轻重的作用,所以永远不可能达成平台化的双方垄断,很难把一切的竞争对手都压制住,因此需求不断的提升作者与读者双方的生态体验。
1.2 产业情况
现代小说不在是作家单枪匹马进行创作,而是变成发掘哪些元素比拟受人喜欢,然后以一种比拟快的办法去切入进行变现,并随同一些商业衍消费品。如从网络小说衍生为国产动漫,电视剧、电影、自拍剧等,这些都是网络小说的一些变现办法。
网络小说是一种产业链生态,不仅仅是写小说、看小说这一件事。更多的是用户会参与其中,并通知我们小说衍生的下一步应该如何走,是应该变成漫画还是变成影视剧。也正是这个缘由,大量的付费阅读变成了免费阅读,希望把本人的作品扩展到其他范畴,获取更多的收益。每家都有本人的网络小说平台,开展方式都是从明星作家到产业变现的方式。为了 IP 变现和影视活动,需求对网络小说作品做更深层次的理解。以前不太关注的点,如一篇长篇小说是不是合适改编成影视、游戏或者动漫,如何对改编的合理性进行评价,如今都需求有深层次的理解。
1.3 作者作品
网络小说头部流量作品主要有玄幻、奇幻、科幻、仙侠、武侠、都市、历史、灵异和游戏。每品种型的网络小说都有本人的代表作,如武侠类别的代表作为英雄志。
不同类型的小说有不同的表现方式。如玄幻小说和武侠小说是完整不一样的作品,玄幻小说比武侠小说有更夸大的表现方式,如手一挥,星球就爆炸了,这种在武侠小说中依然不存在。 随着品种的变化词的意义也不同,如“吓死了”,很多时分不是死了或者要死了,而是情感的一种表达方式。这也是 NLP 之所以艰难的一个缘由。也就是说 NLP 是由共识而来,也是会随共识而变。关于一个词的语义,在不同的文章中、不同的上下文中都在不停的变化,不可能有一个规范的办法来处理一切 NLP 问题。而且抢手的网络小说类型也在不停的变化。
1.4 写作套路
网络小说的写作有本人套路,普通表如今书名、等级、打斗、配备、悬念及世界观等方面。如书名要么狂、要么 low,总之要贴近小白和草根;等级设定要完备、能够无限晋级、做到一山还比一山高;打斗要么跨级逆袭,要么扮猪吃虎;配备则需求变废为宝、随手捡来的渣滓也得是个废物;明线暗线要留足吊胃口的悬念,例如要报仇、要找爹妈、要复生老婆等;世界观都十分大,如玄幻仙侠中,可触及地球、星系、异界、多宇宙、平行宇宙、混沌等。网络小说到最后曾经不是在写文章,而是写一种体系和架构。作者会驱动本人把文章变成架构体系。文字作风需求运用夸大的手法,如一吼之下,让好几座山峰都炸开。
** **
1.5 网文构造化 - 标签维度
这里说的网文构造化,主要从标签维度思索。而在这之前需求明白什么是标签以及标签如何进行定义,如何把标签描绘分明等。一个好的标签体系是后续工作的根底。
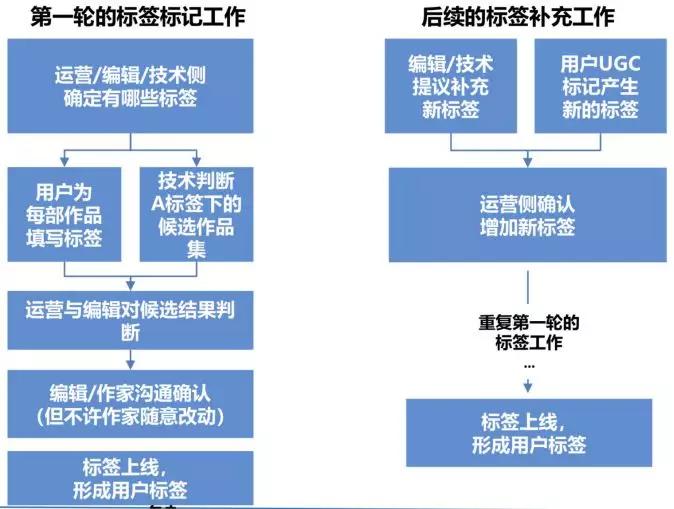
对网络文章进行构造化,主要是经过技术分离人工进行肯定。标签标志大致流程为。首先经过运营、编辑分离技术手腕肯定标签体系,再经过用户填写标签,以及经过技术判别标签下的候选作品集,运营和编辑对候选结果进行判别后与作家沟通确认(但不许作家随意改动)后,构成最终的用户标签。假如后续需求补充标签,如编辑或者技术提议补充新标签,或者用户标志了新标签后,需求运营对这些新增的标签进行确认,然后在反复标签标志的工作。流程如下图所示。
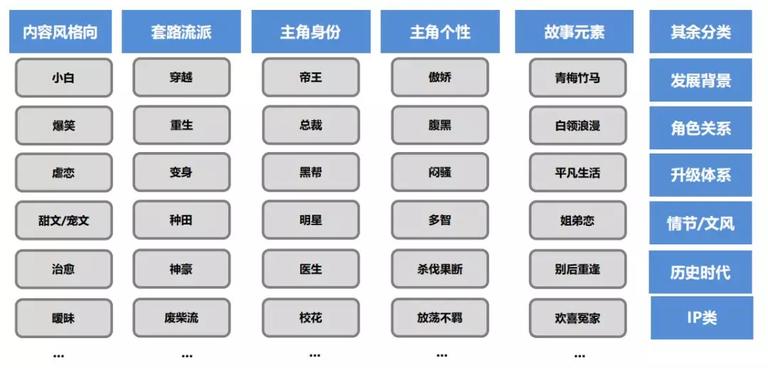
标签主要分为通用标签和品类题材标签,通用标签主要强调通用性,而品类主题标签主要是分离品类进行更加细化标签。以至内容作风、套路流派、主角身份及故事元素等方面都需求制定细化的标签体系。

为什么要做这么多、这么细的标签,其缘由在于网络文章的引荐是不同于短资讯类的引荐,短资讯喜欢不喜欢,看一眼马上就曾经明白了。但网络小说需求看比拟长的篇幅才干肯定喜欢还是不喜欢,假如引荐不精确,用户看了两小时后不喜欢这部小说,会招致用户对引荐十分恶感。因而需求对网络小说的标签进行细化,建立更多维度的标签。
二、技术架构
内容发掘目的:
持续提升内容价值转化。最简单的是肯定用户喜欢不喜欢、但更重要的是要转化到其他场景中去,需求深挖,把不同的场景循环起来。这才是一个比拟好的内容发掘平台。网络小说内容发掘主要存在三方面的问题:
1、内容发掘算子分散不集中、不可相互促进;
2、需求来源散乱、整理代价大、不可复用;
3、内容发掘后的运用渠道单一。
处理计划:
1、内容发掘平台需求闭环。即平台需求、发掘算子和业务反应需求构成闭环。
2、不同平台之间需求链接。即业务察看、内容消费、发掘平台及应用场景之间需求构成很好的链接关系。
2.1 内容发掘平台 - 赋能业务
内容发掘平台的主要任务是发掘内容价值、赋能作者,提升内容传播效率。其目的是赋能业务,不同的业务需求发掘不同的内容。假如是 IP 变现,需求预测内容的目的群体以及转化的可行性剖析,应该转化为动漫、电视剧还是游戏等。假如是针对阅读用户,用户提供一些明白的信息,则需求提供引荐理由、标签和构造信息等辅助用户进行消费决策。针对作家,能够引导作家写什么样的内容,用户更感兴味。针对内容审核能够提示一些审核风险等。经过趋向指数、候选标签的指导编辑进行内容方向的判别等。
2.2 技术全景
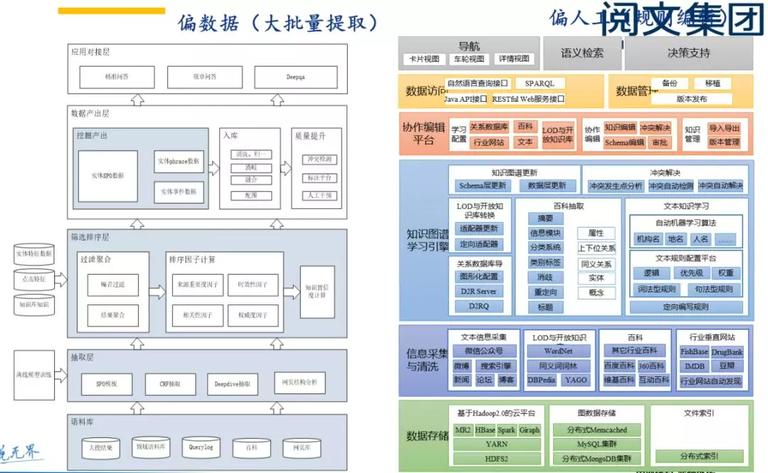
技术主要包含底层数据、中心技术、根底算子、应用策略和业务场景五层。如下图所示。
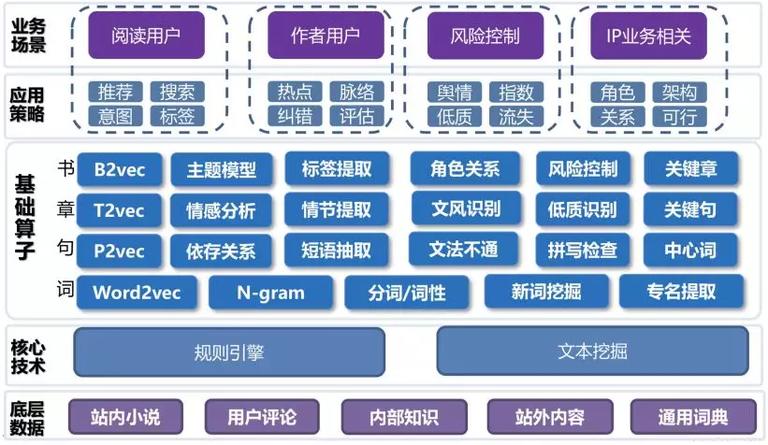
需求阐明的是,根底算子中的书层次,需求依赖段落与章节粒度的剖析,却又与这两个粒度的剖析办法不同,是独立的端到端模型。
2.3 学问库构建
学问库主要用于辅助语义理解、关系网络构建和学问推理。学问库能够辅助网络内容进行语义理解,并希望把这些学问库固化下来进行迭代更新。以及相应的角色与角色之间的关系,把关系网络树立起来。当需求大范围、系统化的深层关系发掘时,可经过学问库来支持学问推理。

2.4 学问库构建办法
学问库的构建办法主要有两种,一种是基于数据推理,另一种是基于人工构建。人工构建办法比拟简单,而基于数据推理的办法则需求大量的算法辅助。
三、落地理论
业务落地场景主要有角色剖析、标签建立、引荐语生成、色情鉴别和剽窃鉴别五种场景。
3.1 角色剖析
角色剖析主要经过 NER 加关系抽取进行剖析。NER 主要是书籍主角辨认,关系为人物关系和书籍角色关系。书籍主角名辨认最简单的一种办法是经过关键词 + 词性 + 百家姓来剖析角色,这种简单的办法就能够到达很高的精确率(95.6%)。另外主角的呈现次数是远多于其他角色,其他角色的次数呈现阶段性降落,经过这种方式能够肯定主要人物、重要人物、普通人物等。
人物关系经过社交关系反响。所谓社交关系,定义为两个人有过对话、打斗,即存在社交关系。社交普遍水平经过社交比例进行量化,与人物 A 有社交关系的一切人除以书中人物总数,即为人物 A 的社交比例。将每一次对话、打斗记为一次关系 (能够累加),能够经过这种关系构建人物关系矩阵。有了这个关系矩阵,就能够进一步构建人物关系图并剖析人物关系。
从人物关系矩阵中,能够发现每个人物之间存在的一些联络和抵触,然后经过统计人物奉献四周的一些词是正向还是负向来判别人物是正面人物还是背面人物。经过人物关系矩阵,进一步加工成关系向量,再用关系向量聚类,就能够聚成图中的四大类。
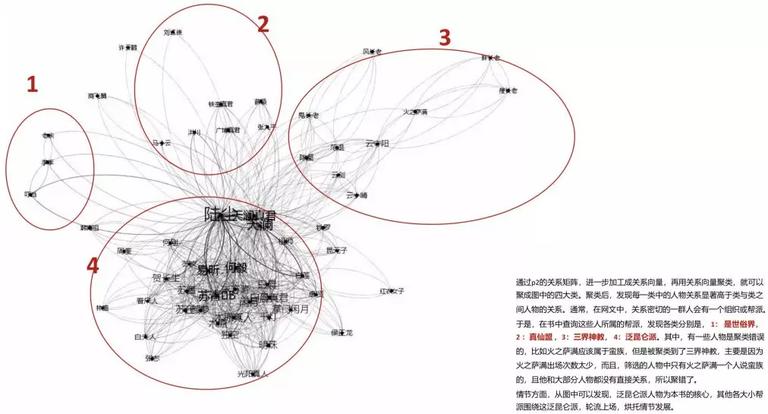
聚类后,发现每一类中的人物关系显著高于类与类之间人物的关系。通常,在网文中,关系亲密的一群人会有一个组织或帮派。与此同时,也会呈现少量的聚类错误。
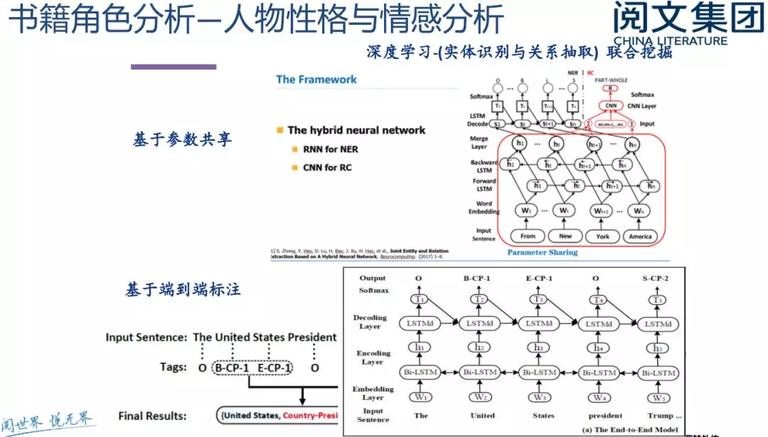
经过与主角的对话等,分离情感发掘办法进行情感剖析和预测,运用基于参数共享和端到端标注的深度学习办法对实体辨认与关系抽取进行结合发掘,剖析其他角色的人物性格与情感剖析。
3.2 标签建立
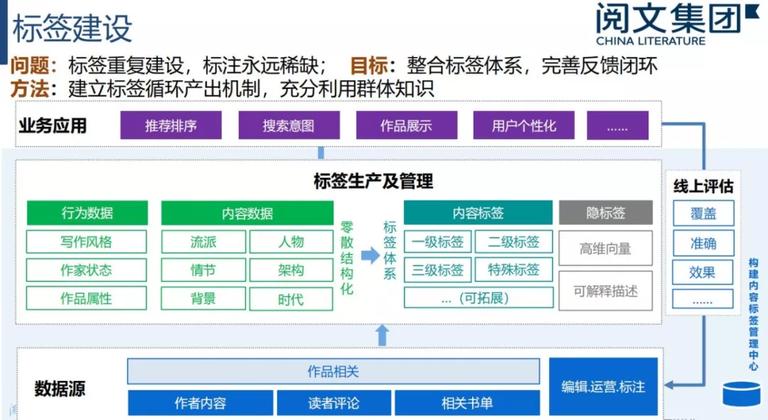
标签能有效给予读者锚点,让挑选的本钱进一步降低,但每本书的标签都是不一样的。与段内容的标签不同,段落中存在一些标签,但是很有可能不置信。网文标签变换十分快,2016 年抢手标签是校花、兵王,2018 年抢手标签变成了神豪、奶爸。重要的问题是不太分明抢手标签会不会变化,而且每年都会有新标签呈现,如何才干快速对新标签进行交融。第二个问题是标签由于某些书籍而降生,需求后续渐渐开展而填充进来,很可能在那个时间点样本是相当有限的(就算长期来看,某些标签的样本总量也极低)。由于这些问题,需求对标签进行反复建立,但是数据标注永远稀缺。因而需求整合标签体系,完善反应闭环。详细的做法是充沛利用群体学问,分离已有行为数据和内容数据的标签,经过标签消费和管理生成一些不太肯定标签,然后在经过编辑、运营进行标注,再进行标签生成和管理,构成标签产出机制进行循环迭代。
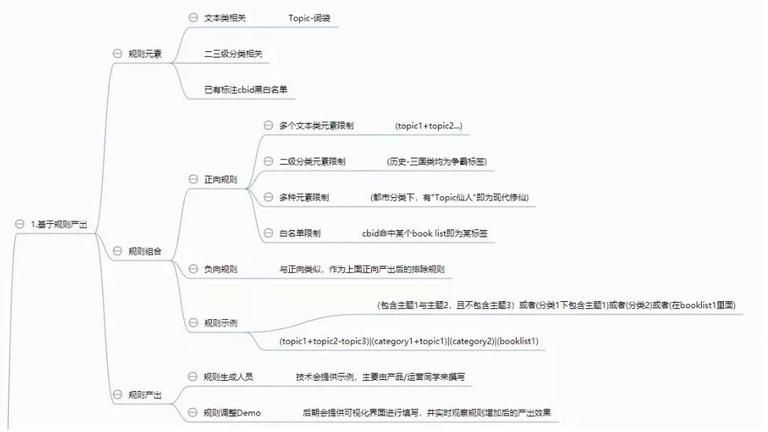
标签的生成主要有两种办法。一种是基于规则产出,缺陷是规则不好定义,规则中的词存在歧义,在不同的场景和上下文中有不同的意义。
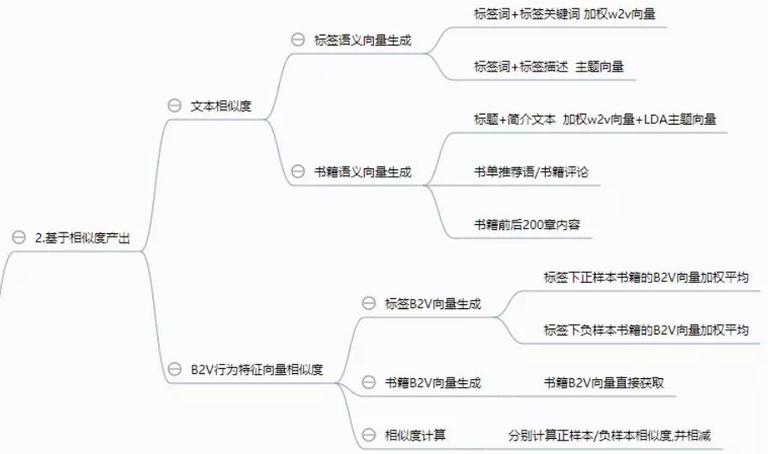
另一种办法是基于类似度产出,这里的类似度主要有两类,一类是语义类似度,包含标签语义向量生成和书籍语义向量生成;另一种是 B2V 行为特征向量类似度,经过用户行为的相关性对标签进行预测。
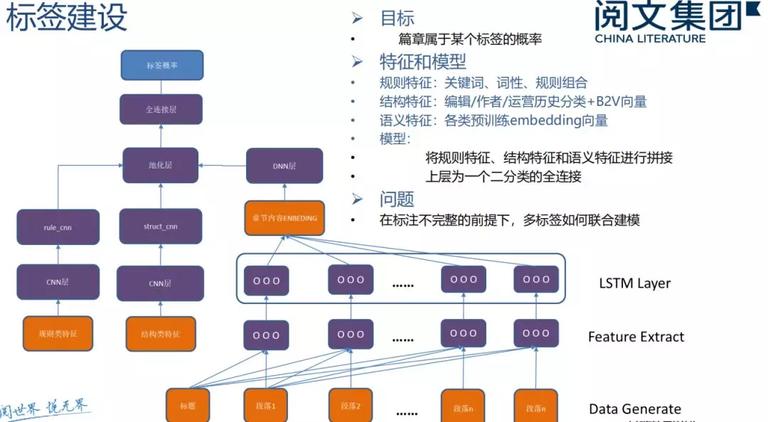
分离规则特征、构造特征和语义特征,运用深度学习进行建模。但存在在标注不完好的状况下,多标签如何结合建模的问题。
3.3 引荐语生成
生成引荐语的目的是需求掩盖引荐池内的数据,提升转化。处理引荐理由相对单调,信息量低的问题。
分离标签和用户行为数据,引荐语生成有两种计划。一是基于构造化内容模板生成,另一种计划是基于书单已有的引荐语作为锻炼语料,运用 data2seq 模型生成引荐语。
除引荐语生成外,还能够分离引荐文章生成,抢手作家、台词和时间模板等进行更好的引荐。让用户看到不仅仅是引荐、更是一个 AI 的应用场景。
3.4 色情鉴别
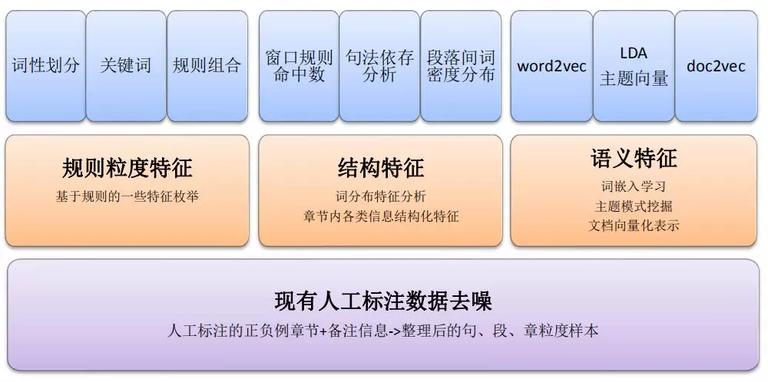
色情鉴别主要判别内容能否涉黄、涉政及涉黑等,鉴别办法包含关键词召回和模型召回两种。关键词召回需求定义风险召回关键词和黑名单等。模型召回运用的特征包括规则粒度特征、构造特征和语义特征。规则特征在不同的条件语境下,不同的代词会有不同的指代对象,此时需求很多规则去列举。如不同的衣着和形容词等,有不同的组合,定义好特征规则后,再接入模型进行判别。也能够运用 word2vec 进行特征扩展,但同时也会引入大量的噪音。
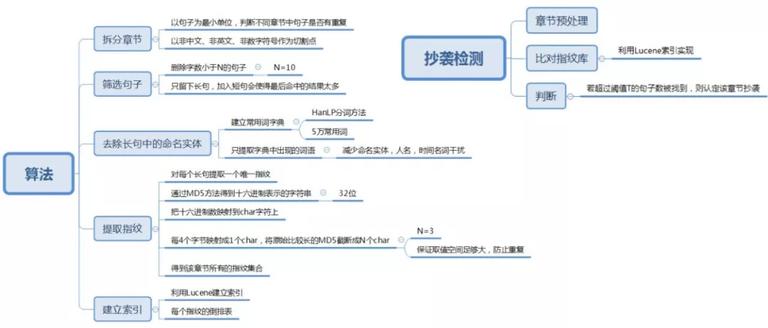
3.5 剽窃鉴别
剽窃普通会对关键词和命名实体进行交换。基于这种缘由,在做剽窃鉴别时,把句子中的局部关键词和命名实体辨认去除,只提取常用词词典中的词,减少命名实体、时间名词的干扰。详细的算法有:
** 章节拆分:** 以句子为最小单位,判别不同章节中句子能否有反复。
** 句子挑选:** 删除短句,只保留长句。缘由是参加短句会使得最后的命中结果太多。
** 去除长句中的命名实体:** 保留常用词,减少实体词的干扰。
** 提取指纹:** 经过 MD5 等,对每个长句提取独一的指纹,得到该章节的一切指纹汇合。
** 树立索引:** 经过 Lucene 对指纹树立倒排表。
鉴别时,先对章节进行预处理,利用 Lucene 索引比照指纹库,假如被找到的句子数超越一定的阈值,则认定该章节为剽窃章节。
四、理论总结
技术如何与业务分离。很多时分不能防止返工,但要保证这件事或者方向正确,要对业务问题十分分明。
如何快速构建正负样本。样本标注不是硬标注,应分离技术手腕尽可能减少标注的工作量(例如谷歌流体标注改造),标注尽可能运用二值判别的方式,防止运用从多个选项当选择一个的方式。另一点是配套监控与记载、校验,确保整个标注过程可控。
如何充沛利用用户行为。不要觉得用户行为是无效的,用户行为能提供很多信息。文本自身是经过共识达成的,而用户行为记载的是更实质的共识系统。假如业务上会产出用户行为,则优先思索用户行为奉献的学问。用户行为标明两个 item 相关,就不要单纯从 NLP 语义上去判别说不相关。将行为融入到 NLP 剖析模型中,也是后续的开展方向。

时间:2018-12-28 22:49 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















