从想法到实干,2018年13项NLP绝美新研究
在行将过去的 2018 年中,自然言语处置有很多令人冲动的想法与工具。从概念观念到实战锻炼,它们为 NLP 注入了新颖的生机。
前一段时间,Sebastian Ruder 引见了他心中 10 个最有影响力的想法,并且每一个都提供了详细论文与中心思想。正如 Ruder 所说,他的清单必然是客观的,主要涵盖了迁移学习和泛化相关的想法。其中有的想法在过去一年十分受关注,大家盘绕这些圆满的观念展开了很多研讨工作与理论。而有的想法并不是当前趋向,不过它们有可能在将来变得盛行。因而,机器之心在 Ruder 引见的根底上,重点关注今年的前沿趋向,并引荐一些真正好用的 NLP 新工具。
在本文中,我们会重点关注 2018 年里的 神经机器翻译 与预锻炼模型,这两个概念真的十分 Excited!然后关于实战配备,数百种中文预锻炼词嵌入向量、BERT预锻炼模型和建模框架 PyText 等工具真的令人忍不住想做一个新颖的 NLP 应用。
1. 神经机器翻译
在 2018 年, 神经机器翻译 似乎有了很大的改动,以前用 RNN 加上留意力机制打造的 Seq2Seq 模型仿佛都交换为了 Tramsformer。大家都在运用更大型的 Transformer,更高效的 Transformer 组件。例如阿里会依据最近的一些新研讨对规范 Transformer 模型停止一些修正。这些修正首先表现在将 Transformer 中的 Multi-Head Attention 交换为多个自留意力分支,其次他们采用了一种编码相对位置的表征以扩展自留意力机制,并令模型能更好天文解序列元素间的相对间隔。
有道翻译也采用了 Transformer,他们同样会采取一些修正,包括对单语数据的应用,模型构造的调整,锻炼办法的改良等。例如在单语数据的应用上,他们尝试了回译和对偶学习等战略,在模型构造上采用了相对位置表征等。所以总的而言,虽然 Transformer 在解码速度和位置编码等方面有一些缺陷,但它依然是当前效果最好的 神经机器翻译 根本架构。
在 Ruder 的引见中,它十分关注两种无监视机器翻译模型,它们都被承受为 ICLR 2018 论文。假如无监视机器翻译模型是能行得通的,那么这个想法自身就很惊人,虽然无监视翻译的效果很可能远比有监视差。在 EMNLP 2018 中,有一篇论文在无监视翻译上更进一步提出了很多改良,并取得极大的提升。Ruder 笔记中提到了以下这篇论文:
论文:Phrase-Based & Neural Unsupervised Machine Translation
-
论文链接: https://arxiv.org/abs/1804.07755
这篇论文很好地提炼出了无监视 MT 的三个关键点:优秀的参数初始化、言语建模和经过回译建模反向任务。这三种办法在其它无监视场景中也有运用,例如建模反向任务会迫使模型到达循环分歧性,这种分歧性曾经应用到了很多任务,可能读者最熟习的就是CycleGAN。该论文还对两种语料较少的言语做了大量的实验与评价,即英语-乌尔都语和英语-罗马尼亚语。
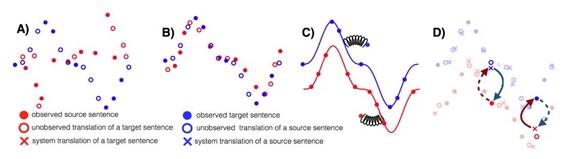
无监视 MT 的三个主要准绳:A)两种单语数据集、B)参数初始化、C)言语建模、D)回译。
这篇论文取得了 EMNLP 2018 的最佳长论文奖,它在遵照上面三个主要准绳的状况下简化了却构和损失函数。得到的模型优于以前的办法,并且更易于锻炼和调整。
2. 预锻炼模型
2018 年,运用预锻炼的言语模型可能是 NLP 范畴最显著的趋向,它能够应用从无监视文本中学习到的「言语学问」,并迁移到各种 NLP 任务中。这些预锻炼模型有很多,包括 ELMo、ULMFiT、OpenAITransformer 和BERT,其中又以BERT最具代表性,它在 11 项 NLP 任务中都取得当时最佳的性能。不过目前有 9 项任务都被微软的新模型超越。
机器之心曾解读过BERT的的中心过程,它会先从数据集抽取两个句子,其中第二句是第一句的下一句的概率是 50%,这样就能学习句子之间的关系。其次随机去除两个句子中的一些词,并请求模型预测这些词是什么,这样就能学习句子内部的关系。最后再将经过处置的句子传入大型 Transformer 模型,并经过两个损失函数同时学习上面两个目的就能完成锻炼。

如上所示为不同预锻炼模型的架构,BERT能够视为分离了OpenAIGPT 和 ELMo 优势的新模型。其中 ELMo 运用两条独立锻炼的 LSTM 获取双向信息,而OpenAIGPT 运用新型的 Transformer 和经典言语模型只能获取单向信息。BERT的主要目的是在OpenAIGPT 的根底上对预锻炼任务做一些改良,以同时应用 Transformer 深度模型与双向信息的优势。
这种「双向」的来源在于BERT与传统言语模型不同,它不是在给定一切前面词的条件下预测最可能的当前词,而是随机遮掩一些词,并应用一切没被遮掩的词停止预测。
此外,值得留意的是,最近微软发布了一种新的综合性模型,它在 GLUE 的 11 项基准NLP 任务中的 9 项超越了BERT,且评分也超越了BERT。除了精确率外,微软的新模型只要 1.1 亿的参数量,远比BERT-Large 模型的 3.35 亿参数量少,和BERT-Base 的参数量一样多。

在「Microsoft D365 AI & MSR AI」模型的描绘页中,新模型采用的是一种多任务结合学习。因而一切任务都共享相同的构造,并经过多任务锻炼办法结合学习。目前新模型的信息还十分少,假如经过多任务预锻炼,它也能像BERT那样用于更普遍的 NLP 任务,那么这样的高效模型无疑会有很大的优势。
Sebastian Ruder 十分观赏 ELMo 的创新性想法,它同样也是今年的论文(NAACL 2018):
论文:Deep contextualized word representations (NAACL-HLT 2018)
-
论文链接: https://arxiv.org/abs/1802.05365
这篇论文提出了广受好评的 ELMo,除了令人印象深入的实验结果外,最吸收人的就是论文的剖析局部,它剔除了各种要素的影响,并对表征所捕获的信息停止了剖析。在下图左中语义消歧(WSD)执行得很好,它们都标明言语模型提供的语义消歧和词性标注(POS)表现都接近当前最优程度。

第一层和第二层双向言语模型的语义消歧(左)和词性标注(右)与基线模型比照的结果。
3. 常识推理数据集
将常识融入模型是 NLP 最重要的研讨方向之一。但是,创立好的数据集并非易事,即便是盛行的数据集也存在很大的偏好问题。今年曾经呈现了一些试图教机器学习常识的数据集,如华盛顿大学的 Event2Mind 和 SWAG。但 SWAG 很快就被BERT打败了。有代表性的研讨成果包括:
论文:From Recognition to Cognition: Visual Commonsense Reasoning
-
论文地址: https://arxiv.org/abs/1811.10830
这是首个包含每个答案的根本原理(解释)的可视化 QA 数据集。而且,答复问题需求复杂的推理。创作者竭尽全力处理可能呈现的偏好,确保每个答案作为正确答案的先验概率为 25%(每个答案在整个数据集中呈现 4 次,其中 3 次作为错误答案,1 次作为正确答案);这需求应用能够计算相关性和类似性的模型来处理约束优化问题。

给定一幅图像、一系列地点和一个问题,模型必需答复该问题,并提供合理的推了解释答案为什么是正确的(Zellers et al., 2018)
4.元学习
元学习 是目前机器学习范畴一个令人振奋的研讨趋向,它处理的是学习如何学习的问题。元学习在少样本学习、强化学习和机器人学方面有很多应用,其中最突出的应用是与模型无关的元学习(model-agnostic meta-learning,MAML),但在 NLP 中的胜利应用却十分少。元学习在锻炼样本有限时十分有用。有代表性的研讨成果包括:
论文 1:Meta-Learning for Low-Resource Neural Machine Translation
-
论文链接: http://aclweb.org/anthology/D18-1398
作者应用 MAML 来学习一个好的用于翻译的初始化,将每个言语对看成一个独立的元任务。资源较少的言语或许是元学习在 NLP 范畴最有应用价值的场景。将多言语迁移学习(如多言语BERT)、无监视学习和元学习相分离是一个有前景的研讨方向。
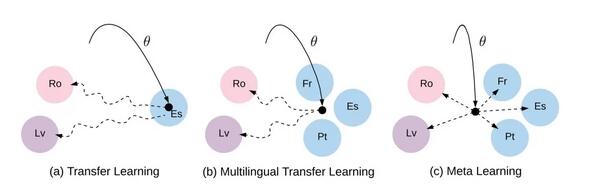
迁移学习、多缘由迁移学习和元学习之间的差别。实线:初始化的学习。虚线:微调途径。
论文 2:Meta-Learning a Dynamical Language Model
-
论文地址: https://arxiv.org/abs/1803.10631
作者提出,用于优化神经网络模型的元学习器的行为和循环神经网络相似,它会提取一系列模型锻炼过程中的参数和梯度作为输入序列,并依据这个输入序列计算得到一个输出序列(更新后的模型参数序列)。他们在论文中细致描绘了该类似性,并研讨了将元学习器用于神经网络言语模型中,以完成中期记忆:经过学习,元学习器可以在规范 RNN(如 LSTM)的权重中,编码中期记忆(除了短期记忆在 LSTM 躲藏状态中的传统编码方式以外)。
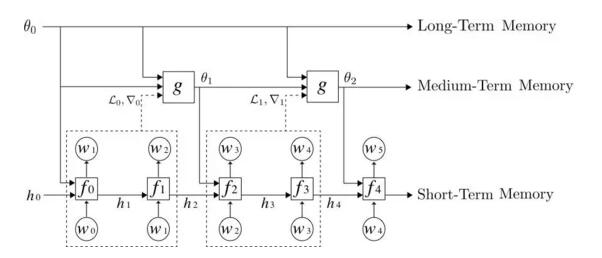
他们的元学习言语模型由 3 层记忆层级组成,自下而上分别是:规范 LSTM、用于更新 LSTM权重以存储中期记忆的元学习器,以及一个长期静态记忆。他们发现,元学习言语模型能够经过锻炼来编码最近输入的记忆,就像一篇维基百科文章的开端局部对预测文章的结尾局部十分有协助一样。
5. 鲁棒无监视办法
今年,我们察看到,跨言语嵌入办法在言语类似性低时会失效。这是迁移学习中的常见现象,源言语和目的言语设置(例如,域顺应中的域、持续学习和多任务学习中的任务)之间存在差别,招致模型退化或失效。因而,使模型对这些变化愈加鲁棒十分重要。有代表性的研讨成果包括:
-
论文:A robust self-learning method for fully unsupervised cross-lingual mappings of word embeddings
-
论文链接: http://www.aclweb.org/anthology/P18-1073
这篇论文依据其了解构建了一个更好的初始化,而没有运用元学习作为初始化。特别地,他们将两种言语中具有类似词散布的单词配对。这是从剖析中应用范畴学问和 insight 以使模型愈加鲁棒的绝佳范例。
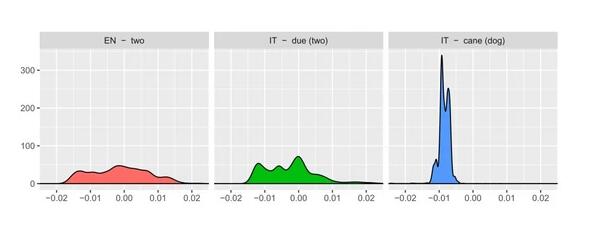
三个单词的类似性散布:与不相关的单词(「two」和「cane」(狗))相比,等效翻译(「two」和「due」)有愈加类似的词散布。(Artexte et al. 2018 http://www.aclweb.org/anthology/P18-1073)
6. 了解表征
今年,人们在更好天文解表征方面做了很多工作。特别地,《Fine-grained Analysis of Sentence Embeddings Using Auxiliary Prediction Tasks》这篇论文提出了「诊断分类器」(度量学习到的表征能否能预测特定属性的任务),之后在其它研讨中变得常见,如《What you can cram into a single vector: Probing sentence embeddings for linguistic properties》。有代表性的研讨成果包括:
论文:Dissecting Contextual Word Embeddings: Architecture and Representation
-
论文链接: http://aclweb.org/anthology/D18-1179
这篇论文在更好了解预锻炼言语模型表征方面做出了很大奉献。他们普遍地研讨了精心设计的无监视和有监视任务上学习到的单词和跨度表征。结果发现:预锻炼表征会在较低层学习到与低级形态和句法任务相关的任务,在较高层学习到更大范围的语义。对我而言,该研讨标明了预锻炼言语模型的确能捕捉文本的类似属性,正如计算机视觉模型在 ImageNet 上预锻炼后,能捕捉图像之间的类似属性。

BiLSTM 和 Transformer 的预锻炼表征的每一层的性能,从左到右依次是:POS 标志、选区解析和无监视共指解析 (Peters et al. 2018 http://aclweb.org/anthology/D18-1179 )。
7. 辅助任务
在很多设置中,我们都看到人们越来越多运用带有认真选择的辅助任务的多任务学习办法。其中最重要的一个案例是BERT。其运用了下一句预测来完成优越性能(近期被用在 Skip-thoughts 以及 Quick-thoughts 等)。有代表性的研讨成果包括:
论文 1:Syntactic Scaffolds for Semantic Structures
-
论文链接: http://aclweb.org/anthology/D18-1412
这篇论文经过为每个跨度预测对应的句法成分类型,以此提出了一种预锻炼跨度表征的辅助任务。虽然在概念上很简单,该辅助任务能够在跨度级预测任务中获得极大提升,例如语义角色标注和共指解析等。该论文标明,经过目的任务在所需级别学习的专用表征有极大的用途。
论文 2:pair2vec: Compositional Word-Pair Embeddings for Cross-Sentence Inference
-
论文链接: https://arxiv.org/abs/1810.08854
根据类似的思绪,这篇论文经过最大化词对以及语境的逐点互信息预锻炼词对表征。相比愈加通用的表征(例如言语建模),这鼓舞模型学习更有意义的词对表征。这些预锻炼表征在诸如 SQuAD、和 MultiNLI 等需求跨句推理的任务中很有效。我们能够等待看到更多可捕捉适用于特定下游任务的预锻炼模型,并且和愈加通用的任务互补(例如言语建模)。
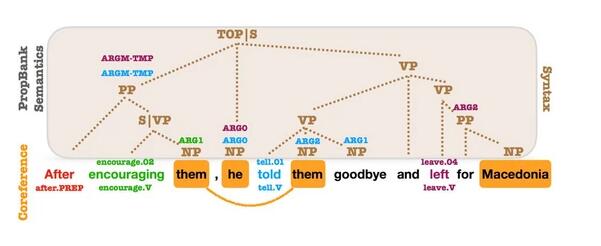
OntoNotes 的句法、命题语料库和共指标注。命题语料库SRL参数和共指在句法成分之上标注。简直每个参数都与句法成分有关 (Swayamdipta et al., 2018 http://aclweb.org/anthology/D18-1412 )
8.半监视学习分离迁移学习
最近,迁移学习获得最新停顿,我们不应该遗忘运用目的任务特定数据更明白的方式。其实,预锻炼表征与多种方式的半监视学习是互补的。曾经有研讨者探究半监视学习的一个特定类别——自标注办法。有代表性的研讨包括:
论文:Semi-Supervised Sequence Modeling with Cross-View Training
-
论文链接: http://aclweb.org/anthology/D18-1217
这篇论文标明,一个概念上十分简单的想法——即确保对不同输入视图的预测与主模型的预测分歧——能够在一系列不同的任务中取得收益。这一想法与 word dropout 相似,但允许应用未标注数据来增强模型的鲁棒性。与 mean teacher 等其他 self-ensembling 模型相比,它是特地为特定 NLP 任务设计的。
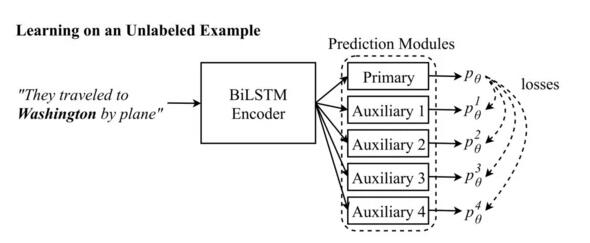
辅助预测模块看到的输入:辅助 1:They traveled to __________________. 辅助 2:They traveled to Washington _______. 辅助 3: _____________ Washington by plane. 辅助 4: ________________________ by plane
9. 应用大型文本的问答和推理
在一系列新的问答(QA)数据集的协助下,问答系统获得了很多停顿。除对话问答和多步骤推理之外,问答系统最具应战性的一个方面是合成叙说和含有大量信息的本文。有代表性的研讨包括:
论文:The NarrativeQA Reading Comprehension Challenge
-
论文链接: http://aclweb.org/anthology/Q18-1023
本文作者依据对整个电影剧本和书籍的问答提出了一个颇具应战性的 QA 数据集。固然目前的办法仍无法完成这项任务,但模型能够选择运用摘要(而不是整本书)作为上下文,选择答案(而不是生成答案),以及运用 IR 模型的输出。这些变体进步了任务的可行性,使得模型能够逐步扩展到完好的语境。
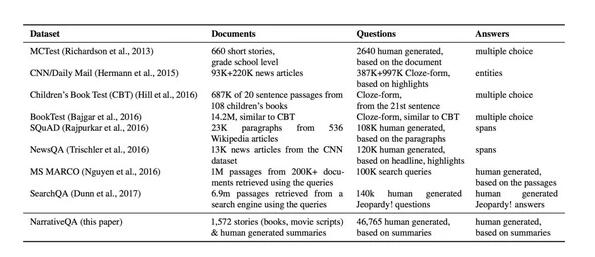
QA 数据集比照。
10. 归结倾向
CNN 中的卷积、正则化、dropout 以及其他机制等归结倾向都是神经网络模型做为正则化项的中心局部,也使得模型采样更为高效。但是,提出一种普遍可用的归结倾向并把它融入到模型中十分具有应战性。有代表性的研讨成果包括:
论文 1:sequence classification with human attention (CoNLL 2018)
-
论文链接: http://aclweb.org/anthology/K18-1030
该论文提出运用来自人类眼球追踪语料库的人类留意力来正则化RNN 中的留意。往常许多 Transformers 这样的现有模型都在运用 attention,找到更高效锻炼的适宜方式是很重要的方向。也很快乐看到人类言语学习能协助我们改良计算模型。
论文 2:Linguistically-Informed Self-Attention for Semantic Role Labeling (EMNLP 2018)
-
论文链接: http://aclweb.org/anthology/D18-1548
该论文有很多喜人的中央:在句法与语义任务上同时锻炼一个 Transformer;锻炼时参加高质量解析的才能以及范畴外评价。经过锻炼一个留意力 head 来关注每个 token 的 syntactic parents,这篇论文也正则化了 Transformer 的多 head 留意力,使其对句法更为敏感。我们将来可能会看到更多 Transformer 留意 head 示例,做为专注输入特定方面的辅助词预测器。
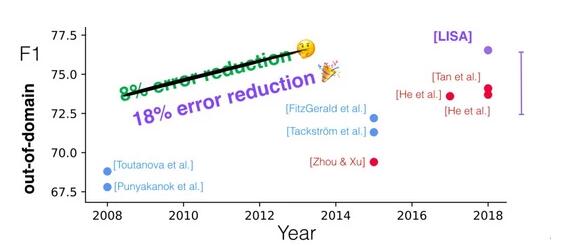
过去十年的 PropBank 语义角色标志。在范畴外数据上,Linguistically-Informed Self-Attention (LISA) 办法与其他办法的比照。
不管是采用 Mask 的言语模型还是经过回译的无监视机器翻译,这 10 个想法都十分漂亮。但是在实践应用中,我们更希望直接运用已有的工具构建高效应用,只要这样,这些想法才干转化为真正有意义的东西。
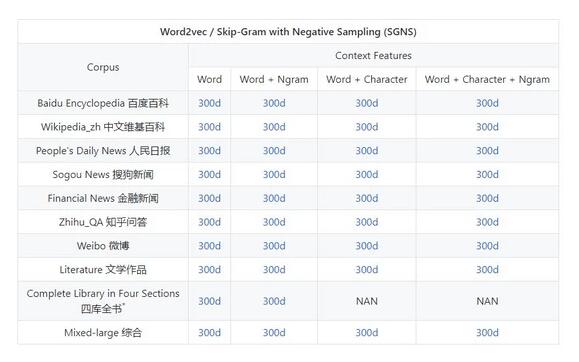
11. 上百种预锻炼中文词向量
做自然言语处置,词嵌入根本是绕不开的步骤,各种任务都需求归结到词层面才干继续计算。因而关于国内自然言语处置的研讨者而言,中文词向量语料库是需求很大的资源。为此,北京师范大学等机构的研讨者开源了「中文词向量语料库」,该库包含经过数十种用各范畴语料(百度百科、维基百科、人民日报 1947-2017、知乎、微博、文学、金融、古汉语等)锻炼的词向量,涵盖各范畴,且包含多种锻炼设置。
中文词向量项目地址: https://github.com/Embedding/Chinese-Word-Vectors
该项目提供运用不同表征(稠密和密集)、上下文特征(单词、n-gram、字符等)以及语料库锻炼的中文词向量(嵌入)。我们能够轻松取得具有不同属性的预锻炼向量,并将它们用于各类下游任务。
12.BERT开源完成
虽然如前所述BERT的效果惊人,但预锻炼所需求的计算力同样惊人,普通的开发者根本就不要想着能复现了。BERT的作者在 Reddit 上也表示预锻炼的计算量十分大,Jacob 说:「OpenAI的 Transformer 有 12 层、768 个躲藏单元,他们运用 8 块 P100 在 8 亿词量的数据集上锻炼 40 个 Epoch 需求一个月,而BERT-Large 模型有 24 层、2014 个躲藏单元,它们在有 33 亿词量的数据集上需求锻炼 40 个 Epoch,因而在 8 块 P100 上可能需求 1 年?16 Cloud TPU 曾经是十分大的计算力了。」
但是,谷歌团队开源了BERT的预锻炼模型,我们能够将它们用于不同的 NLP 任务。这俭省了我们大量计算力,同时还能提升已有模型的效果,因而做 NLP 任务前,你能够先用预锻炼的BERT试试水?
BERT完成地址: https://github.com/google-research/bert

其实目前曾经有很多开发者将BERT预锻炼模型应用到它们本人的项目中,包括抽取句向量、句子类似性判别或情感剖析等。
13. Facebook 开源 NLP 建模框架 PyText,从论文到产品部署只需数天
为了降低人们创立、部署自然言语处置系统的难度,Facebook 开源了一个建模框架—— PyText ,它含糊了实验与大范围部署之间的界线。PyTex 是 Facebook 正在运用的主要自然言语处置(NLP)建模框架,每天为 Facebook 及其应用程序系列的用户提供超越 10 亿次 AI 任务处置。这一框架基于 PyTorch,能够 1)简化工作流程,加快实验进度;2)提供一大批预构建的模型架构和用于文本处置和词汇管理的工具,以促进大范围部署;3)提供应用 PyTorch 生态系统的才能,包括由 NLP 社区中的研讨人员、工程师预构建的模型和工具。应用该框架,Facebook 在几天内就完成了 NLP 模型从理念到完好施行的整个过程,还部署了依赖多任务学习的复杂模型。
Yann LeCun 对此引见道,「PyText 是一个工业级的开源 NLP 工具包,可用于在 PyTorch 中开发 NLP 模型,并经过 ONNX 部署。其预锻炼模型包括文本分类、序列标注等。」
项目地址: https://github.com/facebookresearch/pytext

参考链接: http://ruder.io/10-exciting-ideas-of-2018-in-nlp/

时间:2018-12-26 23:24 来源:未知 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















