OpenAI发现打破神经网络黑盒魔咒新思路:梯度噪
由于复杂的任务往往具有更嘈杂的梯度,因此越来越大的batch计算包,可能在将来变得有用,从而消除了AI系统进一步增长的一个潜在限制。
更广泛地说,这些结果表明训练不需要被认为是一种炼丹术,而是可以被量化和系统化。
在过去的几年里,AI研究人员通过数据并行技术,在加速神经网络训练方面取得了越来越大的成功,数据并行性将大batch数据分散到许多机器上。
研究人员成功地使用了成各种的batch进行图像分类和语言建模,甚至玩Dota 2。
这些大batch数据允许将越来越多的计算量有效地投入到单个模型的训练中,并且是训练计算快速增长的重要推动者。
但是,batch如果太大,则梯度消失。并且不清楚为什么这些限制对于某些任务影响更大而对其他任务影响较小。

我们已经发现,通过测量梯度噪声标度,一个简单的统计量来量化网络梯度的信噪比,我们可以近似预测较大有效batch大小。
同理,噪声尺度可以测量模型所见的数据变化(在训练的给定阶段)。当噪声规模很小时,快速并行查看大量数据变得多余;反之,我们仍然可以从大batch数据中学到很多东西。
这种类型的统计数据被广泛用于样本量选择,并且已被提议用于,但尚未被系统地测量或应用于现代训练运行。
我们对上图所示的各种任务进行了验证,包括图像识别,语言建模,Atari游戏和Dota。
由于大batch通常需要仔细和昂贵的调整或特殊高效的学习率,因此提前知道上限在训练新模型方面提供了显著的实际优势。
我们发现,根据训练的现实时间和我们用于进行训练的总体积计算(与美元成本成比例)之间的权衡,可视化这些实验的结果是有帮助的。
在非常小的batch的情况下,batch加倍可以让我们在不使用额外计算的情况下减少一半的训练。在非常大的batch,更多的并行化不会导致更快的训练。中间的曲线中存在“弯曲”,渐变噪声标度预测弯曲发生的位置。
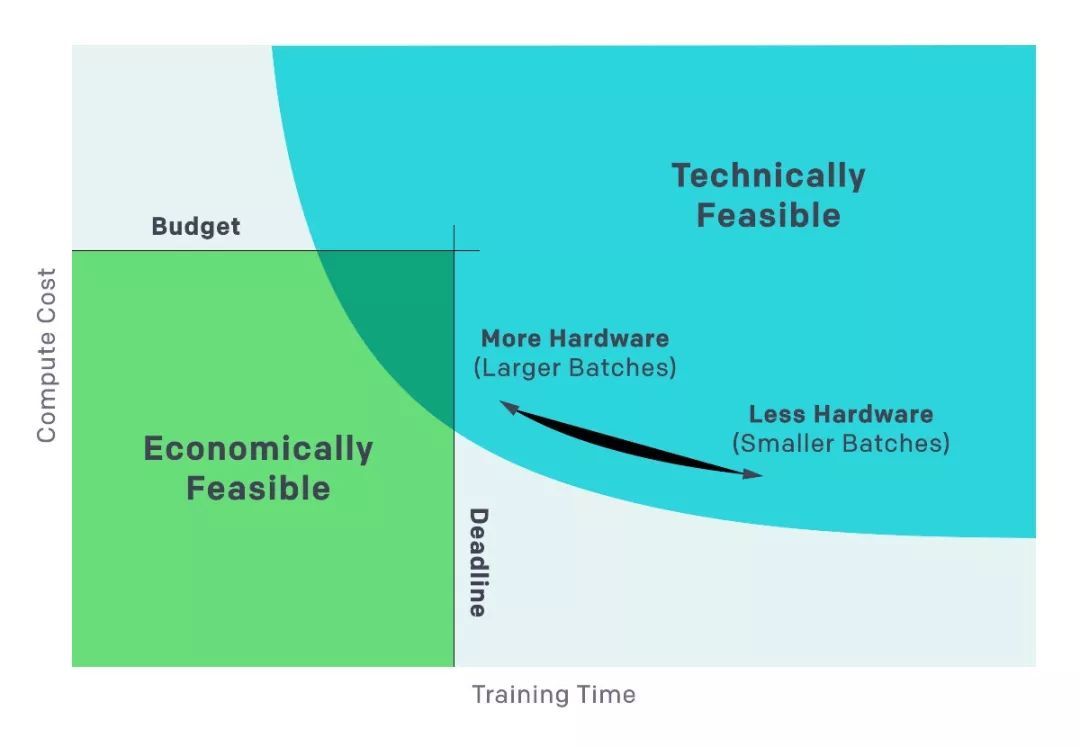
我们通过设置性能水平(比如在Beam Rider的Atari游戏中得分为1000)来制作这些曲线,并观察在不同batch大小下训练到该性能所需的时间。 结果与绩效目标的许多不同值相对较紧密地匹配了我们模型的预测。
梯度噪声尺度中的模式
我们在梯度噪声量表中观察到了几种模式,这些模式提供了人工智能训练未来可能存在的线索。
首先,在我们的实验中,噪声标度通常在训练过程中增加一个数量级或更多。
直观地,这意味着网络在训练早期学习任务的“更明显”的特征,并在以后学习更复杂的特征。
例如,在图像分类器的情况下,网络可能首先学习识别大多数图像中存在的小尺度特征(例如边缘或纹理),而稍后将这些部分组合成更一般的概念,例如猫和狗。
要查看各种各样的边缘或纹理,网络只需要看到少量图像,因此噪声比例较小;一旦网络更多地了解更大的对象,它就可以一次处理更多的图像,而不会看到重复的数据。
我们看到一些初步迹象表明,在同一数据集上不同模型具有相同的效果。更强大的模型具有更高的梯度噪声标度,但这仅仅是因为它们实现了更低的损耗。
因此,有一些证据表明,训练中增加的噪声比例不仅仅是收敛的假象,而是因为模型变得更好。如果这是真的,那么我们期望未来的更强大的模型具有更高的噪声规模,因此可以更加并行化。
在监督学习的背景下,从MNIST到SVHN到ImageNet都有明显的进展。在强化学习的背景下,从Atari Pong到Dota 1v1到Dota 5v5有明显的进展,较佳batch大小相差10,000倍以上。
因此,随着AI进入新的和更困难的任务,我们希望模型能够容忍更高的batch。
启示
数据并行度显着影响AI功能的进展速度。更快的训练使更强大的模型成为可能,并通过更快的迭代时间加速研究。
在早期研究中,我们观察到用于训练较大ML模型的计算,每3.5个月翻一番。我们注意到这种趋势是由经济能力和并行训练的能力共同决定的。
后一因素(算法可并行性)更难以预测,其局限性尚不清楚,但我们目前的结果代表了系统化和量化的一步。
特别是,我们有证据表明,在同一任务中,更困难的任务和更强大的模型将允许比我们迄今为止看到的更激进的数据并行性,这为训练计算的持续快速指数增长提供了关键驱动因素。
参考链接:
https://blog.openai.com/science-of-ai/
声明:文章收集于网络,如有侵权,请联系小编及时处理,谢谢!

时间:2018-12-19 21:57 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]GPT-2大战GPT-3:OpenAI内部的一场终极对决
- [机器学习]OpenAI推出数学推理证明模型,推理结果首次被数
- [机器学习]微软与OpenAI达成合作,获得GPT-3独家使用授权
- [机器学习]硬刚无限宽神经网络后,谷歌大脑有了12个新发现
- [机器学习]硬刚无限宽神经网络后,谷歌大脑有了12个新发现
- [机器学习]MIT研究人员发现 ImageNet 数据集存在系统性缺陷
- [机器学习]打破机器学习中的小数据集诅咒
- [机器学习]通过关系网络进行欺诈检测和欺诈团伙发现
- [机器学习]麻省理工科技评论:分析发现深度学习正在走向
- [机器学习]从Zero到Hero,OpenAI重磅发布深度强化学习资源
相关推荐:
网友评论:
最新文章

热门文章














