数据不足,如何进行迁移学习?
现在,人工智能的发展处于跳跃式阶段,我们也对AI在大型数据集的应用进展感到吃惊。更重要的是,那些我们没有跟踪的数十亿张照片或餐厅的评论并没有被遗漏掉:迁移学习技术让收集数据变得更加“容易”。另外,得益于PyTorch框架、fast.ai应用程序库以及FloydHub公司,小团队或者是个别开发人员也能轻松的应用这些方法。
本文要讲的例子就是ULMFiT:Jeremy Howard和Sebastian Ruder在fast.ai展示了如何用几百个标记准确的对电影评论进行分类。除此之外,还有一个在通用英语文本语料库中训练的模型。

除了英语文本资料库和标记对评论进行分类外,fast.ai还有一个小技巧,它拥有大量特定领域的文本:10万多个样本评论,来展示普通英语和电影评论之间的区别。这引发了我们的思考:至少得需要多少数据,才足以弥合训练示例和通用语言模型之间的差距?
这并不是一个特别愚蠢的问题。Frame可以帮助Zendesk,Intercom和Slack等规模性公司标记、评价和理解与客户的对话。也就是说, “只要有足够的对话,我们就可以手动评价”和“我们有足够的数据从头训练一个模型”,这二者之间有很大的差距。仅仅几十个标签和几千条相关对话,这能够做什么?
事实证明,这非常有用。在本文中,我们将使用相同的电影评论数据集来证明:即便是只有少部分的数据,数据迁移依然可以有效。更加详细的代码请参考ULMFiT。
迁移什么?
深度神经网络是当前最新人工智能背后的关键技术,比如理解图像、音频或文本。深度神经网络的核心是它由层(“深度”)组成,每个层都将输入转换为更接近网络训练答案的新的表示。
我们通常会抱怨,不了解神经网络的中间层到底发生了什么……其实,它们通常被设计为更加清晰、可解释的角色!比如:很多语言模型利用嵌入层将单个单词或短语进行分类,将具有相似含义的单词或短语放在一起。举个例子来说,这将有助于翻译AI在需要使用“杰出”(illustrious)这个词的时候,会根据经验选择使用“伟大”(great)。
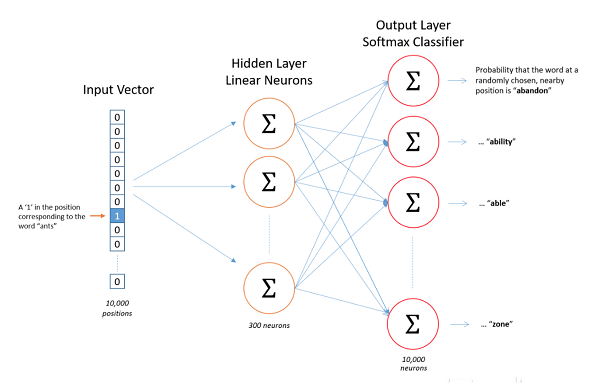
现在变得更有趣了:一个“知道”“illustrious = great”的层不仅有利于翻译,还可以学习情绪估计,将不同的观点聚集起来。这就是迁移学习,也就是说模型在一个任务中学习到的东西可以对另外一个学习任务有帮助。事实上,这个特殊的例子特别受欢迎,以至于改进的通用语言模型已经成为一个全新的领域!
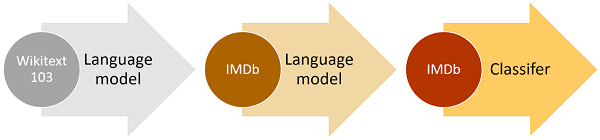
迁移学习不仅有利于任务之间的转移:它可以帮助一般模型在特定环境中更好的工作。例如:一个通用的英语情绪模型或许可以预测电影评论,但是可能不知道“紧张、紧张的惊悚”是件好事。
这就是Jeremy和Sebastian Rudder的通用语言模型微调文本分类(ULMFiT)的用武之地。他们对一个包含100,000个IMDB评论的通用语言模型做了改进。即便是只标记几百个单词,其余的单词也能够帮助AI学习审稿人经常用“杰出”或“很好”代替“紧张、紧绷”等,这很好的弥补了数据不足的缺陷。结果的准确度令我们感到惊讶:仅仅有500个标记示例,分类的准确度却高达94%。
未被标记的数据最少需要多少?
ULMFiT为NLP提供了一个有力的依据,使模型能够更有效的利用较小的数据集。在这项研究中,我们专注于回答以下问题:
如果我们对标记示例的预算特别少,那么,得需要收集多少未标记的数据才能有效的使用迁移学习?
为了解决这个问题,我们使用了大量固定的域数据池,并改变了标记示例的数量,来看看模型应该如何改进。将标记示例的数量保持不变,并改变未标记的其他域示例的数量。也就是说,我们的实验包括:
1.语言建模(变量)
2.语言任务(不变量)
我们的语言任务、情感分类和原始的ULMFiT论文中的任务相同,另外,也使用了IMDB电影评论数据集。在实验中,标记情绪训练样本的数量保持在500个,500个样本可以用于很多小领域的研究,并且,有助于强调不同语言模型的差异提升能力。

对于语言建模,我们改变了可用于语言任务的三种语言模型的域数据量:
•仅限ULM:这是使用Wikitext103预训练英语语言模型
•仅限域(domain):仅在IMDB数据上的基于域训练的模型。
•ULM +域(domain):ULMFiT模型
训练这些模型的计算量特别大,最大的域训练可能需要几天的时间才能完成。为了加快训练速度和有效的执行网格搜索,我们使用了FloydHub。
结果
经过大约50个小时GPU处理,结果如下:
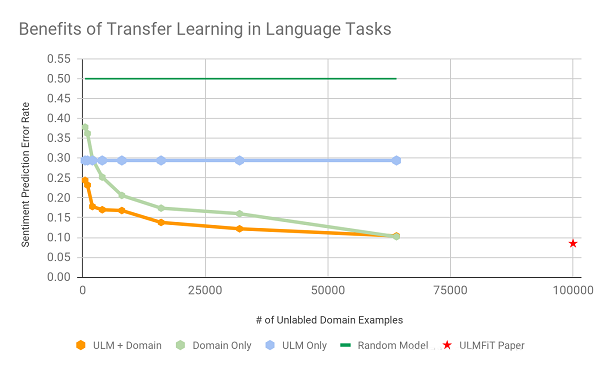
从实验结果,我们可得知:
•使用33%的域数据,就可以获得75%数据的UMLFiT性能。
•令人惊讶的是,ULM + 2,000域示例的语言任务预测准确率约为85%。
文章原标题《Learning More with Less: Frame explores transfer learning in low-data environments with FloydHub, fast.ai, and PyTorch》
译者:Mags,审校:袁虎。

时间:2018-12-17 23:49 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]阿里开源3D-FUTURE数据集 建模时间可从3小时降至10秒
- [机器学习]MIT研究人员发现 ImageNet 数据集存在系统性缺陷
- [机器学习]NVIDIA针对数据不充分数据集进行生成改进,大幅
- [机器学习]数据集永久下架,微软不是第一个,MIT 也不是最
- [机器学习]NVIDIA针对数据不充分数据集进行生成改进,大幅
- [机器学习]微软新作,ImageBERT虽好,千万级数据集才是亮点
- [机器学习]谷歌刚刚发布了2500万个免费数据集,了解一下
- [机器学习]19个数据科学项目的免费公共数据集
- [机器学习]亚马逊研究人员使用NLP数据集来改善Alexa的答案
- [机器学习]如何为数据集选择正确的聚类算法
相关推荐:
网友评论:















