「干货」YouTube 基于深度神经网络推荐系统剖析

文章作者:王科 某司资深算法工程师
内容来源:《YouTube 基于深度神经网络推荐系统剖析》
出品社区:DataFun
YouTube 的推荐系统是近年来业内的佼楚之作。其经典之处不仅仅在于基于深度学习的解决方案,也有很多不属于纯技术范畴的设计抉择。
YouTube 转用深度学习做推荐系统,也许有跟风的意味,希望跟随谷歌“using deep learning as a general-purpose solution for nearly alllearning problems”也就是将深度学习作为机器学习问题的通用解决方案。所幸这样的方法是成功的,带来了推荐系统的“Dramatic Improvement”。
YouTube 推荐系统的三大难点:
· 一是规模太大,简单的推荐算法在如此大规模数据量上可能是失效的;
· 二是实效性,即新数据不断产生,需要将其良好的呈现给用户,以平衡旧有的好内容以及新内容;
· 三是噪音问题,用户行为与视频描述均有噪音,并且只能获得充满噪音的用户隐含反馈,而不能直接获取用户满意度。

图 1.YouTube 基于深度学习推荐系统架构图
本文呈现的推荐系统解决方案分为两个部分:
· 一个是备选生成(Candidate Generation),其目标是初选结果,从海量数据中选择出符合其个人需求偏好的百级别数据;
· 一个则是排序(Ranking),通过更加丰富的用户,视频乃至场景信息,对结果进行精细化排序,得到呈现给用户的备选。
备选生成阶段,将推荐系统定义为一个多分类器,其职责是确定某个用户,在某个场景与时间下,将从系统的视频中选择消费哪一个视频。具体的方法是,将用户与视频全部转化为 Embedding 描述,即一个向量,最终用户消费某个视频的概率通过如下方式计算得到:

而构建用户与视频的 Embedding,则是通过训练而来。将用户观看视频 / 搜索记录 / 其它信息如年龄性别等作为输入特征,部分稀疏特征首先进行 Embedding 化,中间为数层 ReLU,最终一层用 SoftMax 进行分类。换句话讲,是将用户与场景信息作为输入,预估用户下一个要看的视频,也就是将用户分到具体某一个视频作为其类别。 用户与视频的 Eembedding,则是神经网络最后一层的对应矩阵。这种方法除了能利用用户行为信息外,其它信息例如设备,地理位置,性别等也可以作为输入,这是神经网络相对于普通 MF 类算法的优势之一。

图 2.YouTube 推荐备选生成阶段架构
备选生成的下一个阶段是排序。其网络结构跟备选生成阶段类似,将所有排序模型中的信息输入后,进入多层 ReLU,最终进行优化的是一个加权逻辑回归损失函数,观看时间作为阳性样本权重。在这一层,也可以看到其推荐“代理问题”的转化:由点击行为预估转为了以观看时长为权重的点击行为预估,这样更佳贴近 Youtube 的产品优化方向。与备选生成阶段另一个不同在于,排序模块需要考量的特征要多得多:
· “场景”类特征,例如用户可能在某个地方某个时间愿意观看某一条视频,但是在别的地方别的时间则不会;
· 曝光信息:用户观看了某界面,但是并未在其上进行操作,那么随之应进行已呈现内容降级;
· 备选生成层输出:排序需要将各种备选结果联合起来;
· 更丰富的用户信息:例如用户最近的一次搜索词,用户最近观看的同一个主题下的视频数量,用户上一次观看同主题视频的时间,用户所使用的语言等;
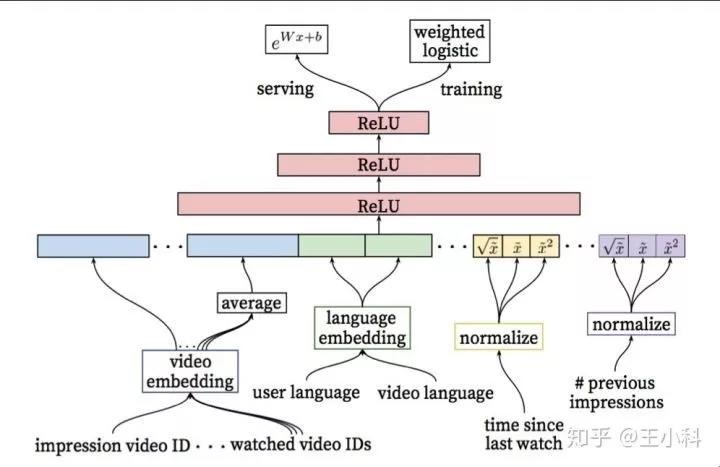
图 3.YouTube 推荐排序阶段架构
除了整体设计与系统架构以外,本篇论文中陈述了很多“选择”,这些选择更多的是“艺术”而不完全属于技术范畴。这些选择往往是很多技术人员关注不多的点,但在笔者看来,这些都蕴含着 YouTube 技术与产品人员深入的思考与判断。
“Example Age” 特征
对于 YouTube 产品层来讲,鼓励内容产生毫无疑问是至关重要的,所以推荐系统也希望对用户上传的新内容的有所偏好。然而幸运的是,即使损失一部分相关性,视频的消费者也偏好新内容。也就是说,新内容的价值可以良好的通过其带来的吸引力呈现出来,并不需要平台刻意而为之。
由于系统使用一个时间窗口的训练样本进行训练,如果没有视频的上传时间信息,那么模型会认为这个时间窗口内用户对视频的偏好是稳定的,然而事实远非如此。将视频的上传时间加入到特征集合后,预估更加准确,尤其是视频刚上传阶段的强烈便好被成功捕捉到。

图 4. 无时间特征预估 / 有时间特征预估 / 真实情况 三者对比
优化目标选择

图 5. 优化对象的选择
算法系统的设计首先要明确优化对象,这不仅仅涉及到损失函数的形式,同样也是评判系统成功与否的标准。YouTube 是视频平台,更是富含“价值”的长视频平台,其观看行为比点击行为意义更大。(当然,笔者认为没有任何一个简单指标可以完全代表一个产品)
“正样本”定义

图 6. 何为正样本的设计选择
YouTube 选择用户观看记录作为训练数据的初始来源,即完成观看视频记录为正样本。主要原因是用户观看记录相对于用户的显性行为例如点赞收藏要多得多。而观看更是视频应用中表达赞赏的最直接方式,其它的显性行为往往意味着强烈的情绪与偏好。
训练数据来源
图 7. 关于训练数据来源的设计抉择
训练数据应该只来源于推荐界面的曝光吗?YouTube 认为不然。如果只考虑推荐界面曝光,则无法对用户便好进行探索,更加无法捕捉用户偏好的变化,因为用户偏好的变化往往首先会对应着搜索与浏览行为。所以 YouTube 将各个界面例如搜索,导航等用户行为全部纳入其中。
训练数据窗口

图 8. 训练数据收集方式的设计选择
Youtube 将所有用户等而视之,每个用户收集一定量的样本。而不是惯常可见的直接收集一个时间窗口内的所有用户行为,作为训练样本。这样的好处是避免系统收到少数行为过多用户的影响,使得系统更多的为大众设计。这样的设计理念与近期阿里 Gai Kun 的论文中评测方法 (用户 AUC) 设计有异曲同工之妙。
用户行为序列处理

图 9. 用户行为序列信息处理的设计选择
在系统中,用户往往会顺着一个检索结果页或者用户发布者浏览页进行顺序观看,如果系统捕捉到了用户看了检索界面的前三个结果,那么预估用户将看第四个结果就会很容易。但是这样真的好吗?将检索结果页面或者用户发布视频界面直接作为推荐结果呈现给用户是并不友好的–抢了别的界面应该干的活嘛。所以此处 YouTube 对用户行为序列做了处理,在模型输入中选择放弃用户行为的序列信息,将其打散成词袋 Embedding,即使这样的信息有利于模型的离线训练效果。
预估对象的选择

图 10. 关于预估对象的设计选择
用户的行为往往是有顺序的,用户在系统中“热身”后,在一个频道下面,往往先看大众喜欢的热门,然后逐步找到自己的兴趣点,聚焦看一块内容。那么,训练数据则应该收集用户前段时间行为,预估此后的行为。而不是收集时间前后段的行为,预估中间时间段的用户行为。这样模型更加接近用户习惯。

除此之外,Youtube 根据系统设计了对应的实验,结果非常简单:深度网络层数越高,效果越好。
YouTube 的推荐系统,已经为其贡献了 70% 的用户播放时长,搜索与导航在 PC 时代的主导地位在移动时代已经完全被颠覆掉。希望大家在其中学到一些东西。笔者水平所限,若有错误不当之处,敬请指正。
另外,个人用 TensorFlow 模拟 Youtube 的推荐系统,做了一个简单实现。其实就是一个多分类器外加一个单分类器,远谈不上成熟,可以供大家参考。
https://github.com/wangkobe88/Earth
——END——

时间:2018-12-10 13:12 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [机器学习]人工智能十年回顾:CNN、AlphaGo、GAN……它们曾这
- [机器学习]Attention!当推荐系统遇见注意力机制
- [机器学习]模仿人脑视觉处理,助力神经网络应对对抗性样本
- [机器学习]神经网络背后的简单数学
- [机器学习]准备好了吗?GNN 图神经网络 2021 年的5大应用热点
- [机器学习]20年以后,半数工作将被人工智能取代?这些“高危行业”有哪些
- [机器学习]万物皆可Graph | 当推荐系统遇上图神经网络
- [机器学习]人工智能十年回顾:CNN、AlphaGo、GAN……它们曾这
- [机器学习]一文详解神经网络与激活函数的基本原理
- [机器学习]年终总结:2021年五大人工智能(AI)和机器学习(ML)发展趋势
相关推荐:
网友评论:















