Python+数据分析:数据分析北京Python开发的现状
相信各位同学多多少少在拉钩上投过简历,今天突然想了解一下北京Python开发的薪资水平、招聘要求、福利待遇以及公司地理位置。既然要分析那必然是现有数据样本。本文通过爬虫和数据分析为大家展示一下北京Python开发的现状,希望能够在职业规划方面帮助到大家!!!
爬虫
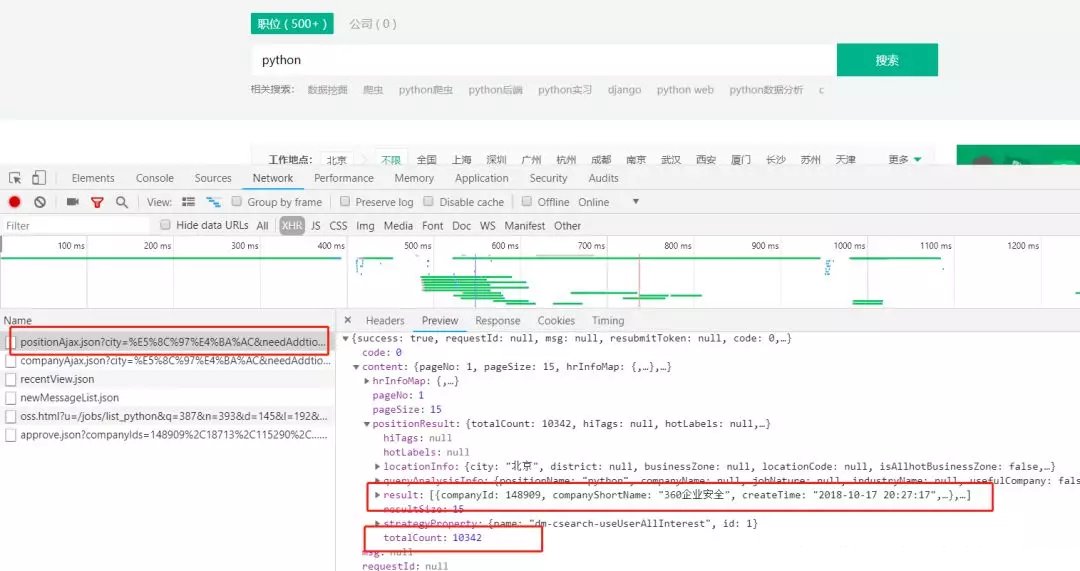
爬虫的第一步自然是从分析请求和网页源代码开始。从网页源代码中我们并不能找到发布的招聘信息。但是在请求中我们看到这样一条POST请求
如下图我们可以得知
url:https://www.lagou.com/jobs/positionAjax.json?city=北京&needAddtionalResult=false
请求方式:post
result:为发布的招聘信息
totalCount:为招聘信息的条数

通过实践发现除了必须携带headers之外,拉勾网对ip访问频率也是有限制的。一开始会提示 ‘访问过于频繁’,继续访问则会将ip拉入黑名单。不过一段时间之后会自动从黑名单中移除。
针对这个策略,我们可以对请求频率进行限制,这个弊端就是影响爬虫效率。
其次我们还可以通过代理ip来进行爬虫。网上可以找到免费的代理ip,但大都不太稳定。付费的价格又不太实惠。
具体就看大家如何选择了
思路
通过分析请求我们发现每页返回15条数据,totalCount又告诉了我们该职位信息的总条数。
向上取整就可以获取到总页数。然后将所得数据保存到csv文件中。这样我们就获得了数据分析的数据源!
post请求的Form Data传了三个参数
first : 是否首页(并没有什么用)
pn:页码
kd:搜索关键字
no bb, show code

接下来我们只需要每次翻页之后调用 get_json 获得请求的结果 再遍历取出需要的招聘信息即可

ok! 数据我们已经获取到了,最后一步我们需要将数据保存下来
# 将总数据转化为data frame再输出
df = pd.DataFrame(data=search_job_result,
columns=['公司全名', '公司简称', '公司规模', '融资阶段', '区域', '职位名称', '工作经验', '学历要求', '工资', '职位福利'])
df.to_csv('lagou.csv', index=False, encoding='utf-8_sig')
运行main方法直接上结果:
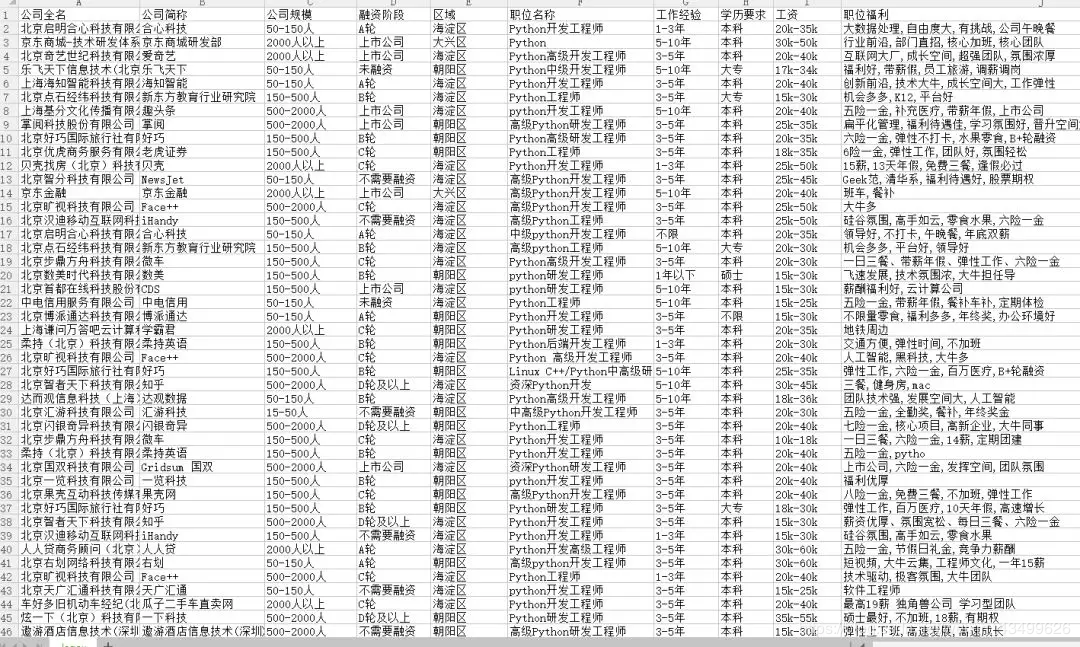
数据分析
通过分析cvs文件,为了方便我们统计,我们需要对数据进行清洗
比如剔除实习岗位的招聘、工作年限无要求或者应届生的当做 0年处理、薪资范围需要计算出一个大概的值、学历无要求的当成大专

数据通过简单的清洗之后,下面开始我们的统计
绘制薪资直方图

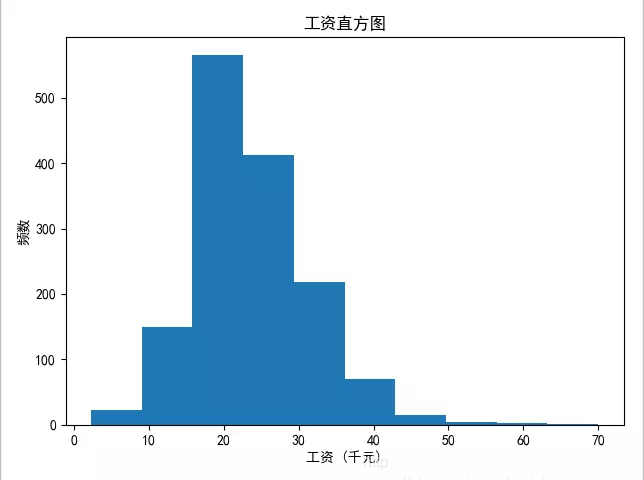
结论:北京市Python开发的薪资大部分处于15~25k之间
公司分布饼状图

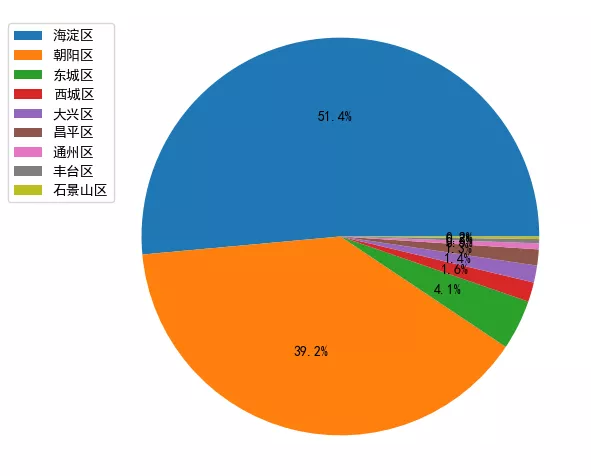
结论:Python开发的公司最多的是海淀区、其次是朝阳区。准备去北京工作的小伙伴大概知道去哪租房了吧
学历要求直方图

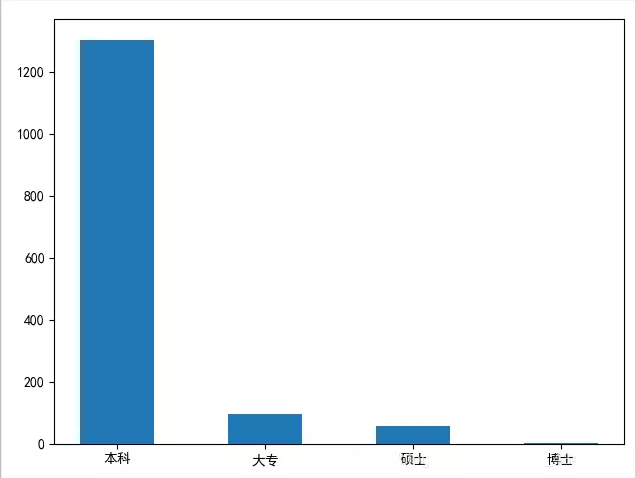
结论:在Python招聘中,大部分公司要求是本科学历以上。但是学历只是个敲门砖,如果努力提升自己的技术,这些都不是事儿
福利待遇词云图


结论:弹性工作是大部分公司的福利,其次五险一金少数公司也会提供六险一金。团队氛围、扁平化管理也是很重要的一方面。
作者:w_初一丶
来源:CSDN

时间:2018-11-29 23:17 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]底层I/O性能大PK:Python/Java被碾压,Rust有望取代
- [数据挖掘]大数据分析的技术有哪些?
- [数据挖掘]大数据分析会遇到哪些难题?
- [数据挖掘]RedMonk语言排行:Python力压Java,Ruby持续下滑
- [数据挖掘]不得了!Python 又爆出重大 Bug~
- [数据挖掘]TIOBE 1 月榜单:Python年度语言四连冠,C 语言再次
- [数据挖掘]TIOBE12月榜单:Java重回第二,Python有望四连冠年度
- [数据挖掘]这个可能打败Python的编程语言,正在征服科学界
- [数据挖掘]2021年编程语言趋势预测:Python和JavaScript仍火热,
- [数据挖掘]Spark 3.0重磅发布!开发近两年,流、Python、SQL重
相关推荐:
网友评论:















