Spark 踩坑记—Spark Streaming+Kafka

作者:肖力涛
前言
在 WeTest 舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了 spark streaming 从 kafka 中不断拉取数据进行词频统计。本文首先对 spark streaming 嵌入 kafka 的方式进行归纳总结,之后简单阐述 Spark streaming+kafka 在舆情项目中的应用,最后将自己在 Spark Streaming+kafka 的实际优化中的一些经验进行归纳总结。
Spark streaming 接收 Kafka 数据
用 spark streaming 流式处理 kafka 中的数据,第一步当然是先把数据接收过来,转换为 spark streaming 中的数据结构 Dstream。接收数据的方式有两种:1.利用 Receive r接收数据,2.直接从 kafka 读取数据。
基于 Receiver 的方式
这种方式利用接收器(Receiver)来接收 kafka 中的数据,其最基本是使用 Kafka 高阶用户 API 接口。对于所有的接收器,从 kafka 接收来的数据会存储在 spark 的executor 中,之后 spark streaming 提交的 job 会处理这些数据。如下图:
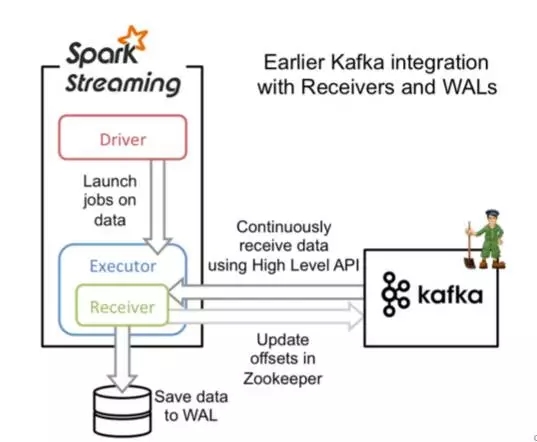
在使用时,我们需要添加相应的依赖包:
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka_2.10</artifactId>
<version>1.6.3</version>
</dependency>
而对于 Scala 的基本使用方式如下:
import org.apache.spark.streaming.kafka._
val kafkaStream = KafkaUtils.createStream(streamingContext,
[ZK quorum], [consumer group id], [per-topic number of Kafka partitions to consume])
还有几个需要注意的点:
在 Receiver 的方式中,Spark 中的 partition 和 kafka 中的 partition 并不是相关的,所以如果我们加大每个topic的partition数量,仅仅是增加线程来处理由单一Receiver消费的主题。但是这并没有增加Spark在处理数据上的并行度。
对于不同的Group和topic我们可以使用多个Receiver创建不同的Dstream来并行接收数据,之后可以利用union来统一成一个Dstream。
如果我们启用了Write Ahead Logs复制到文件系统如HDFS,那么storage level需要设置成 StorageLevel.MEMORY_AND_DISK_SER,也就是KafkaUtils.createStream(..., StorageLevel.MEMORY_AND_DISK_SER)
直接读取方式
在spark1.3之后,引入了Direct方式。不同于Receiver的方式,Direct方式没有receiver这一层,其会周期性的获取Kafka中每个topic的每个partition中的最新offsets,之后根据设定的maxRatePerPartition来处理每个batch。其形式如下图:
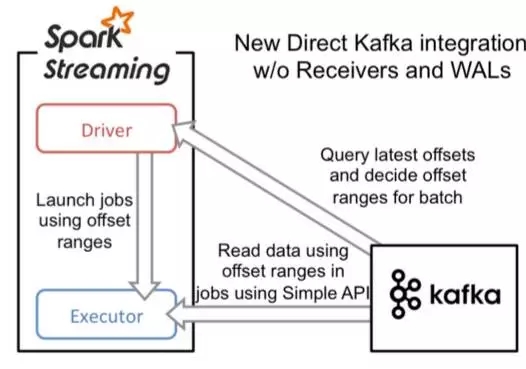
这种方法相较于Receiver方式的优势在于:
简化的并行:在Receiver的方式中我们提到创建多个Receiver之后利用union来合并成一个Dstream的方式提高数据传输并行度。而在Direct方式中,Kafka中的partition与RDD中的partition是一一对应的并行读取Kafka数据,这种映射关系也更利于理解和优化。
高效:在Receiver的方式中,为了达到0数据丢失需要将数据存入Write Ahead Log中,这样在Kafka和日志中就保存了两份数据,浪费!而第二种方式不存在这个问题,只要我们Kafka的数据保留时间足够长,我们都能够从Kafka进行数据恢复。
精确一次:在Receiver的方式中,使用的是Kafka的高阶API接口从Zookeeper中获取offset值,这也是传统的从Kafka中读取数据的方式,但由于Spark Streaming消费的数据和Zookeeper中记录的offset不同步,这种方式偶尔会造成数据重复消费。而第二种方式,直接使用了简单的低阶Kafka API,Offsets则利用Spark Streaming的checkpoints进行记录,消除了这种不一致性。
以上主要是对官方文档[1]的一个简单翻译,详细内容大家可以直接看下官方文档这里不再赘述。
不同于Receiver的方式,是从Zookeeper中读取offset值,那么自然zookeeper就保存了当前消费的offset值,那么如果重新启动开始消费就会接着上一次offset值继续消费。而在Direct的方式中,我们是直接从kafka来读数据,那么offset需要自己记录,可以利用checkpoint、数据库或文件记录或者回写到zookeeper中进行记录。这里我们给出利用Kafka底层API接口,将offset及时同步到zookeeper中的通用类,我将其放在了github上:
Spark streaming+Kafka demo(https://github.com/xlturing/MySpark/tree/master/SparkStreamingKafka)。
示例中KafkaManager是一个通用类,而KafkaCluster是kafka源码中的一个类,由于包名权限的原因我把它单独提出来,ComsumerMain简单展示了通用类的使用方法,在每次创建KafkaStream时,都会先从zooker中查看上次的消费记录offsets,而每个batch处理完成后,会同步offsets到zookeeper中。
Spark向kafka中写入数据
上文阐述了Spark如何从Kafka中流式的读取数据,下面我整理向Kafka中写数据。与读数据不同,Spark并没有提供统一的接口用于写入Kafka,所以我们需要使用底层Kafka接口进行包装。
最直接的做法我们可以想到如下这种方式:

但是这种方式缺点很明显,对于每个partition的每条记录,我们都需要创建KafkaProducer,然后利用producer进行输出操作,注意这里我们并不能将KafkaProducer的新建任务放在foreachPartition外边,因为KafkaProducer是不可序列化的(not serializable)。显然这种做法是不灵活且低效的,因为每条记录都需要建立一次连接。如何解决呢?
首先,我们需要将KafkaProducer利用lazy val的方式进行包装如下:

之后我们利用广播变量的形式,将KafkaProducer广播到每一个executor,如下:

这样我们就能在每个executor中愉快的将数据输入到kafka当中:

Spark streaming+Kafka应用
WeTest舆情监控对于每天爬取的千万级游戏玩家评论信息都要实时的进行词频统计,对于爬取到的游戏玩家评论数据,我们会生产到Kafka中,而另一端的消费者我们采用了Spark Streaming来进行流式处理,首先利用上文我们阐述的Direct方式从Kafka拉取batch,之后经过分词、统计等相关处理,回写到DB上(至于Spark中DB的回写方式可参考我之前总结的博文:Spark踩坑记——数据库(Hbase+Mysql)(http://km.oa.com/group/24949/articles/show/271286)),由此高效实时的完成每天大量数据的词频统计任务。
Spark streaming+Kafka调优
Spark streaming+Kafka的使用中,当数据量较小,很多时候默认配置和使用便能够满足情况,但是当数据量大的时候,就需要进行一定的调整和优化,而这种调整和优化本身也是不同的场景需要不同的配置。
合理的批处理时间(batchDuration)
几乎所有的Spark Streaming调优文档都会提及批处理时间的调整,在StreamingContext初始化的时候,有一个参数便是批处理时间的设定。如果这个值设置的过短,即个batchDuration所产生的Job并不能在这期间完成处理,那么就会造成数据不断堆积,最终导致Spark Streaming发生阻塞。而且,一般对于batchDuration的设置不会小于500ms,因为过小会导致SparkStreaming频繁的提交作业,对整个streaming造成额外的负担。在平时的应用中,根据不同的应用场景和硬件配置,我设在1~10s之间,我们可以根据SparkStreaming的可视化监控界面,观察Total Delay来进行batchDuration的调整,如下图:

合理的Kafka拉取量(maxRatePerPartition重要)
对于Spark Streaming消费kafka中数据的应用场景,这个配置是非常关键的,配置参数为:spark.streaming.kafka.maxRatePerPartition。这个参数默认是没有上线的,即kafka当中有多少数据它就会直接全部拉出。而根据生产者写入Kafka的速率以及消费者本身处理数据的速度,同时这个参数需要结合上面的batchDuration,使得每个partition拉取在每个batchDuration期间拉取的数据能够顺利的处理完毕,做到尽可能高的吞吐量,而这个参数的调整可以参考可视化监控界面中的Input Rate和Processing Time,如下图:
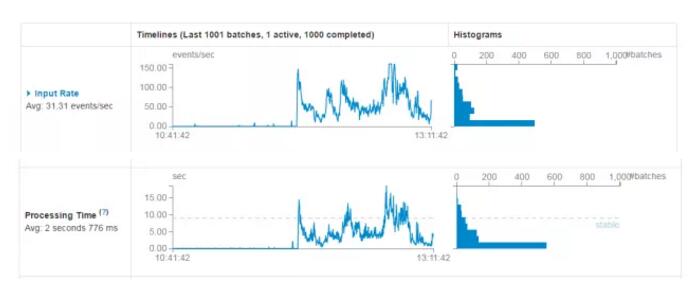
缓存反复使用的Dstream(RDD)
Spark中的RDD和SparkStreaming中的Dstream,如果被反复的使用,最好利用cache(),将该数据流缓存起来,防止过度的调度资源造成的网络开销。可以参考观察Scheduling Delay参数,如下图:

设置合理的GC
长期使用Java的小伙伴都知道,JVM中的垃圾回收机制,可以让我们不过多的关注与内存的分配回收,更加专注于业务逻辑,JVM都会为我们搞定。对JVM有些了解的小伙伴应该知道,在Java虚拟机中,将内存分为了初生代(eden generation)、年轻代(young generation)、老年代(old generation)以及永久代(permanent generation),其中每次GC都是需要耗费一定时间的,尤其是老年代的GC回收,需要对内存碎片进行整理,通常采用标记-清楚的做法。同样的在Spark程序中,JVM GC的频率和时间也是影响整个Spark效率的关键因素。在通常的使用中建议:
--conf "spark.executor.extraJavaOptions=-XX:+UseConcMarkSweepGC"
设置合理的CPU资源数
CPU的core数量,每个executor可以占用一个或多个core,可以通过观察CPU的使用率变化来了解计算资源的使用情况,例如,很常见的一种浪费是一个executor占用了多个core,但是总的CPU使用率却不高(因为一个executor并不总能充分利用多核的能力),这个时候可以考虑让么个executor占用更少的core,同时worker下面增加更多的executor,或者一台host上面增加更多的worker来增加并行执行的executor的数量,从而增加CPU利用率。但是增加executor的时候需要考虑好内存消耗,因为一台机器的内存分配给越多的executor,每个executor的内存就越小,以致出现过多的数据spill over甚至out of memory的情况。
设置合理的parallelism
partition和parallelism,partition指的就是数据分片的数量,每一次task只能处理一个partition的数据,这个值太小了会导致每片数据量太大,导致内存压力,或者诸多executor的计算能力无法利用充分;但是如果太大了则会导致分片太多,执行效率降低。在执行action类型操作的时候(比如各种reduce操作),partition的数量会选择parent RDD中最大的那一个。而parallelism则指的是在RDD进行reduce类操作的时候,默认返回数据的paritition数量(而在进行map类操作的时候,partition数量通常取自parent RDD中较大的一个,而且也不会涉及shuffle,因此这个parallelism的参数没有影响)。所以说,这两个概念密切相关,都是涉及到数据分片的,作用方式其实是统一的。通过spark.default.parallelism可以设置默认的分片数量,而很多RDD的操作都可以指定一个partition参数来显式控制具体的分片数量。
在SparkStreaming+kafka的使用中,我们采用了Direct连接方式,前文阐述过Spark中的partition和Kafka中的Partition是一一对应的,我们一般默认设置为Kafka中Partition的数量。
使用高性能的算子
这里参考了美团技术团队的博文,并没有做过具体的性能测试,其建议如下:
使用reduceByKey/aggregateByKey替代groupByKey
使用mapPartitions替代普通map
使用foreachPartitions替代foreach
使用filter之后进行coalesce操作
使用repartitionAndSortWithinPartitions替代repartition与sort类操作
使用Kryo优化序列化性能
这个优化原则我本身也没有经过测试,但是好多优化文档有提到,这里也记录下来。在Spark中,主要有三个地方涉及到了序列化:
在算子函数中使用到外部变量时,该变量会被序列化后进行网络传输(见“原则七:广播大变量”中的讲解)。
将自定义的类型作为RDD的泛型类型时(比如JavaRDD,Student是自定义类型),所有自定义类型对象,都会进行序列化。因此这种情况下,也要求自定义的类必须实现Serializable接口。
使用可序列化的持久化策略时(比如MEMORY_ONLY_SER),Spark会将RDD中的每个partition都序列化成一个大的字节数组。
对于这三种出现序列化的地方,我们都可以通过使用Kryo序列化类库,来优化序列化和反序列化的性能。Spark默认使用的是Java的序列化机制,也就是ObjectOutputStream/ObjectInputStream API来进行序列化和反序列化。但是Spark同时支持使用Kryo序列化库,Kryo序列化类库的性能比Java序列化类库的性能要高很多。官方介绍,Kryo序列化机制比Java序列化机制,性能高10倍左右。Spark之所以默认没有使用Kryo作为序列化类库,是因为Kryo要求最好要注册所有需要进行序列化的自定义类型,因此对于开发者来说,这种方式比较麻烦。
以下是使用Kryo的代码示例,我们只要设置序列化类,再注册要序列化的自定义类型即可(比如算子函数中使用到的外部变量类型、作为RDD泛型类型的自定义类型等):

结果
经过种种调试优化,我们最终要达到的目的是,Spark Streaming能够实时的拉取Kafka当中的数据,并且能够保持稳定,如下图所示:
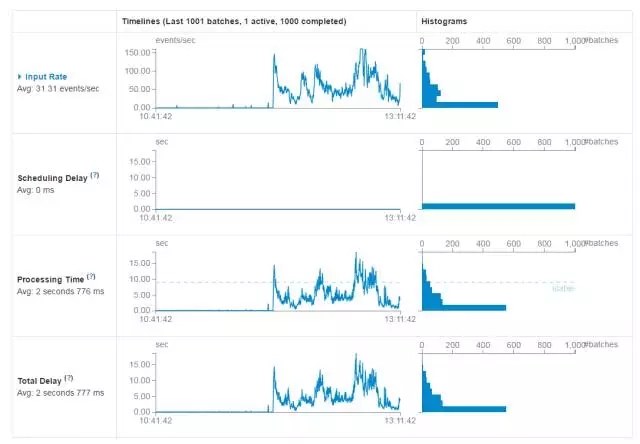
当然不同的应用场景会有不同的图形,这是本文词频统计优化稳定后的监控图,我们可以看到Processing Time这一柱形图中有一Stable的虚线,而大多数Batch都能够在这一虚线下处理完毕,说明整体Spark Streaming是运行稳定的。
参考文献:
Spark Streaming + Kafka Integration Guide
https://spark.apache.org/docs/1.4.0/streaming-kafka-integration.html
DirectStream、Stream的区别-SparkStreaming源码分析02
http://hadoop1989.com/2016/03/15/KafkaStreaming/
Spark Streaming性能调优详解
https://www.iteblog.com/archives/1333
Spark性能优化指南——基础篇
http://tech.meituan.com/spark-tuning-basic.html
Spark的性能调优
http://www.infoq.com/cn/news/2016/01/Spark-performance-tuning
How to write to Kafka from Spark Streaming
http://stackoverflow.com/questions/31590592/how-to-write-to-kafka-from-spark-streaming

时间:2018-10-29 23:19 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
相关推荐:
网友评论:















