维基百科中的数据科学:手把手教你用Python读懂
没人否认,维基百科是现代最令人惊叹的人类发明之一。
几年前谁能想到,匿名贡献者们的义务工作竟创造出前所未有的巨大在线知识库?维基百科不仅是你写大学论文时最好的信息渠道,也是一个极其丰富的数据源。
从自然语言处理到监督式机器学习,维基百科助力了无数的数据科学项目。
维基百科的规模之大,可称为世上最大的百科全书,但也因此稍让数据工程师们感到头疼。当然,有合适的工具的话,数据量的规模就不是那么大的问题了。
本文将介绍“如何编程下载和解析英文版维基百科”。
在介绍过程中,我们也会提及以下几个数据科学中重要的问题:
1、从网络中搜索和编程下载数据
2、运用Python库解析网络数据(HTML, XML, MediaWiki格式)
3、多进程处理、并行化处理
这个项目最初是想要收集维基百科上所有的书籍信息,但我之后发现项目中使用的解决方法可以有更广泛的应用。这里提到的,以及在Jupyter Notebook里展示的技术,能够高效处理维基百科上的所有文章,同时还能扩展到其它的网络数据源中。
本文中运用的Python代码的笔记放在GitHub,灵感来源于Douwe Osinga超棒的《深度学习手册》。前面提到的Jupyter Notebooks也可以免费获取。
GitHub链接:https://github.com/WillKoehrsen/wikipedia-data-science/blob/master/notebooks/Downloading%20and%20Parsing%20Wikipedia%20Articles.ipynb
免费获取地址:
https://github.com/DOsinga/deep_learning_cookbook
编程搜索和下载数据
任何一个数据科学项目第一步都是获取数据。我们当然可以一个个进入维基百科页面打包下载搜索结果,但很快就会下载受限,而且还会给维基百科的服务器造成压力。还有一种办法,我们通过dumps.wikimedia.org这个网站获取维基百科所有数据的定期快照结果,又称dump。
用下面这段代码,我们可以看到数据库的可用版本:
import requests
# Library for parsing HTML
from bs4 import BeautifulSoup
base_url = 'https://dumps.wikimedia.org/enwiki/'
index = requests.get(base_url).text
soup_index = BeautifulSoup(index, 'html.parser')
# Find the links on the page
dumps = [a['href'] for a in soup_index.find_all('a') if
a.has_attr('href')]
dumps
['../',
'20180620/',
'20180701/',
'20180720/',
'20180801/',
'20180820/',
'20180901/',
'20180920/',
'latest/']
这段代码使用了BeautifulSoup库来解析HTML。由于HTML是网页的标准标识语言,因此就处理网络数据来说,这个库简直是无价瑰宝。
本项目使用的是2018年9月1日的dump(有些dump数据不全,请确保选择一个你所需的数据)。我们使用下列代码来找到dump里所有的文件。
dump_url = base_url + '20180901/'
# Retrieve the html
dump_html = requests.get(dump_url).text
# Convert to a soup
soup_dump = BeautifulSoup(dump_html, 'html.parser')
# Find list elements with the class file
soup_dump.find_all('li', {'class': 'file'})[:3]
[<li><a href="/enwiki/20180901/enwiki-20180901-pages-articles-multistream.xml.bz2">enwiki-20180901-pages-articles-multistream.xml.bz2</a> 15.2 GB</li>,
<li><a href="/enwiki/20180901/enwiki-20180901-pages-articles-multistream-index.txt.bz2">enwiki-20180901-pages-articles-multistream-index.txt.bz2</a> 195.6 MB</li>,
<li><a href="/enwiki/20180901/enwiki-20180901-pages-meta-history1.xml-p10p2101.7z">enwiki-20180901-pages-meta-history1.xml-p10p2101.7z</a> 320.6 MB</li>]
我们再一次使用BeautifulSoup来解析网络找寻文件。我们可以在https://dumps.wikimedia.org/enwiki/20180901/页面里手工下载文件,但这就不够效率了。网络数据如此庞杂,懂得如何解析HTML和在程序中与网页交互是非常有用的——学点网站检索知识,庞大的新数据源便触手可及。
考虑好下载什么
上述代码把dump里的所有文件都找出来了,你也就有了一些下载的选择:文章当前版本,文章页以及当前讨论列表,或者是文章所有历史修改版本和讨论列表。如果你选择最后一个,那就是万亿字节的数据量了!本项目只选用文章最新版本。
所有文章的当前版本能以单个文档的形式获得,但如果我们下载解析这个文档,就得非常费劲地一篇篇文章翻看,非常低效。更好的办法是,下载多个分区文档,每个文档内容是文章的一个章节。之后,我们可以通过并行化一次解析多个文档,显著提高效率。
“当我处理文档时,我更喜欢多个小文档而非一个大文档,这样我就可以并行化运行多个文档了。”
分区文档格式为bz2压缩的XML(可扩展标识语言),每个分区大小300~400MB,全部的压缩包大小15.4GB。无需解压,但如果你想解压,大小约58GB。这个大小对于人类的全部知识来说似乎并不太大。
维基百科压缩文件大小
下载文件
Keras 中的get_file语句在实际下载文件中非常好用。下面的代码可通过链接下载文件并保存到磁盘中:
from keras.utils import get_file
saved_file_path = get_file(file, url)
下载的文件保存在~/.keras/datasets/,也是Keras默认保存设置。一次性下载全部文件需2个多小时(你可以试试并行下载,但我试图同时进行多个下载任务时被限速了)
解析数据
我们首先得解压文件。但实际我们发现,想获取全部文章数据根本不需要这样。我们可以通过一次解压运行一行内容来迭代文档。当内存不够运行大容量数据时,在文件间迭代通常是唯一选择。我们可以使用bz2库对bz2压缩的文件迭代。
不过在测试过程中,我发现了一个更快捷(双倍快捷)的方法,用的是system utility bzcat以及Python模块的subprocess。以上揭示了一个重要的观点:解决问题往往有很多种办法,而找到最有效办法的唯一方式就是对我们的方案进行基准测试。这可以很简单地通过%%timeit Jupyter cell magic来对方案计时评价。
迭代解压文件的基本格式为:
data_path = '~/.keras/datasets/enwiki-20180901-pages-articles15.xml-p7744803p9244803.bz2
# Iterate through compressed file one line at a time
for line in subprocess.Popen(['bzcat'],
stdin = open(data_path),
stdout = subprocess.PIPE).stdout:
# process line
如果简单地读取XML数据,并附为一个列表,我们得到看起来像这样的东西:
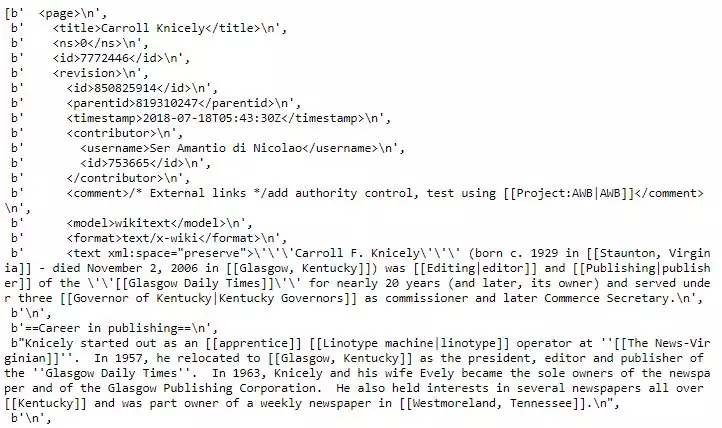
维基百科文章的源XML
上面展示了一篇维基百科文章的XML文件。每个文件里面有成千上万篇文章,因此我们下载的文件里包含百万行这样的语句。如果我们真想把事情弄复杂,我们可以用正则表达式和字符串匹配跑一遍文档来找到每篇文章。这就极其低效了,我们可以采取一个更好的办法:使用解析XML和维基百科式文章的定制化工具。
解析方法
我们需要在两个层面上来解析文档:
1、从XML中提取文章标题和内容
2、从文章内容中提取相关信息
好在,Python对这两个都有不错的应对方法。
解析XML
解决第一个问题——定位文章,我们使用SAX(Simple API for XML) 语法解析器。BeautifulSoup语句也可以用来解析XML,但需要内存载入整个文档并且建立一个文档对象模型(DOM)。而SAX一次只运行XML里的一行字,完美符合我们的应用场景。
基本思路就是我们对XML文档进行搜索,在特定标签间提取相关信息。例如,给出下面这段XML语句:
<text xml:space="preserve">\'\'\'Carroll F. Knicely\'\'\' (born c. 1929 in [[Staunton, Virginia]] - died November 2, 2006 in [[Glasgow, Kentucky]]) was [[Editing|editor]] and [[Publishing|publisher]] of the \'\'[[Glasgow Daily Times]]\'\' for nearly 20 years (and later, its owner) and served under three [[Governor of Kentucky|Kentucky Governors]] as commissioner and later Commerce Secretary.\n'
</text>
我们想筛出在<title>和<text>这两标签间的内容(这个title就是维基百科文章标题,text就是文章内容)。SAX能直接让我们实现这样的功能——通过parser和ContentHandler这两个语句来控制信息如何通过解析器然后被处理。每次扫一行XML句子进解析器,Content Handler则帮我们提取相关的信息。
如果你不尝试做一下,可能理解起来有点难度,但是Content handler的思想是寻找开始标签和结束标签之间的内容,将找到的字符添加到缓存中。然后将缓存的内容保存到字典中,其中相应的标签作为对应的键。最后我们得到一个键是标签,值是标签中的内容的字典。下一步,我们会将这个字典传递给另一个函数,它将解析字典中的内容。
我们唯一需要编写的SAX的部分是Content Handler。全文如下:
在这段代码中,我们寻找标签为title和text的标签。每次解析器遇到其中一个时,它会将字符保存到缓存中,直到遇到对应的结束标签(</tag>)。然后它会保存缓存内容到字典中-- self._values。文章由<page>标签区分,如果Content Handler遇到一个代表结束的 </page> 标签,它将添加self._values 到文章列表(self._pages)中。如果感到疑惑了,实践观摩一下可能会有帮助。
下面的代码显示了如何通过XML文件查找文章。现在,我们只是将它们保存到handler._pages中,稍后我们将把文章发送到另一个函数中进行解析。
# Object for handling xml
handler = WikiXmlHandler()
# Parsing object
parser = xml.sax.make_parser()
parser.setContentHandler(handler)
# Iteratively process file
for line in subprocess.Popen(['bzcat'],
stdin = open(data_path),
stdout = subprocess.PIPE).stdout:
parser.feed(line)
# Stop when 3 articles have been found
if len(handler._pages) > 2:
break
如果我们观察 handler._pages,我们将看到一个列表,其中每个元素都是一个包含一篇文章的标题和内容的元组:
handler._pages[0]
[('Carroll Knicely',
"'''Carroll F. Knicely''' (born c. 1929 in [[Staunton, Virginia]] - died November 2, 2006 in [[Glasgow, Kentucky]]) was [[Editing|editor]] and [[Publishing|publisher]] ...)]
此时,我们已经编写的代码可以成功地识别XML中的文章。现在我们完成了解析文件一半的任务,下一步是处理文章以查找特定页面和信息。再次,我们使用专为这项工作而创建的一个工具。
解析维基百科文章
维基百科运行在一个叫做MediaWiki的软件上,该软件用来构建wiki。这使文章遵循一种标准格式,这种格式可以轻易地用编程方式访问其中的信息。虽然一篇文章的文本看起来可能只是一个字符串,但由于格式的原因,它实际上编码了更多的信息。为了有效地获取这些信息,我们引进了强大的 mwparserfromhell, 一个为处理MediaWiki内容而构建的库。
如果我们将维基百科文章的文本传递给 mwparserfromhell,我们会得到一个Wikicode 对象,它含有许多对数据进行排序的方法。例如,以下代码从文章创建了一个wikicode对象,并检索文章中的 wikilinks()。这些链接指向维基百科的其他文章:
import mwparserfromhell
# Create the wiki article
wiki = mwparserfromhell.parse(handler._pages[6][1])
# Find the wikilinks
wikilinks = [x.title for x in wiki.filter_wikilinks()]
wikilinks[:5]
['Provo, Utah', 'Wasatch Front', 'Megahertz', 'Contemporary hit radio', 'watt']
有许多有用的方法可以应用于wikicode,例如查找注释或搜索特定的关键字。如果您想获得文章文本的最终修订版本,可以调用:
wiki.strip_code().strip()
'KENZ (94.9 FM, " Power 94.9 " ) is a top 40/CHR radio station broadcasting to Salt Lake City, Utah '
因为我的最终目标是找到所有关于书籍的文章,那么是否有一种方法可以使用解析器来识别某个类别中的文章呢?幸运的是,答案是肯定的——使用MediaWiki templates。
文章模板
模板(templates)是记录信息的标准方法。维基百科上有无数的模板,但与我们的目的最相关的是信息框( Infoboxes)。有些模板编码文章的摘要信息。例如,战争与和平的信息框是:

维基百科上的每一类文章,如电影、书籍或广播电台,都有自己的信息框。在书籍的例子中,信息框模板被命名为Infobox book。同样,wiki对象有一个名为filter_templates()的方法,它允许我们从一篇文章中提取特定的模板。因此,如果我们想知道一篇文章是否是关于一本书的,我们可以通过book信息框去过滤。展示如下:
# Filter article for book template
wiki.filter_templates('Infobox book')
如果匹配成功,那我们就找到一本书了!要查找你感兴趣的文章类别的信息框模板,请参阅信息框列表。
如何将用于解析文章的mwparserfromhell 与我们编写的SAX解析器结合起来?我们修改了Content Handler中的endElement方法,将包含文章标题和文本的值的字典,发送到通过指定模板搜索文章文本的函数中。如果函数找到了我们想要的文章,它会从文章中提取信息,然后返回给handler。首先,我将展示更新后的endElement 。
def endElement(self, name):
"""Closing tag of element"""
if name == self._current_tag:
self._values[name] = ' '.join(self._buffer)
if name == 'page':
self._article_count += 1
# Send the page to the process article function
book = process_article(**self._values,
template = 'Infobox book')
# If article is a book append to the list of books
if book:
self._books.append(book)
一旦解析器到达文章的末尾,我们将文章传递到函数 process_article,如下所示:
def process_article(title, text, timestamp, template = 'Infobox book'):
"""Process a wikipedia article looking for template"""
# Create a parsing object
wikicode = mwparserfromhell.parse(text)
# Search through templates for the template
matches = wikicode.filter_templates(matches = template)
if len(matches) >= 1:
# Extract information from infobox
properties = {param.name.strip_code().strip(): param.value.strip_code().strip()
for param in matches[0].params
if param.value.strip_code().strip()}
# Extract internal wikilinks
虽然我正在寻找有关书籍的文章,但是这个函数可以用来搜索维基百科上任何类别的文章。只需将模板替换为指定类别的模板(例如 Infobox language是用来寻找语言的),它只会返回符合条件的文章信息。
我们可以在一个文件上测试这个函数和新的ContentHandler 。
Searched through 427481 articles.
Found 1426 books in 1055 seconds.
让我们看一下查找一本书的结果:
books[10]
['War and Peace',
{'name': 'War and Peace',
'author': 'Leo Tolstoy',
'language': 'Russian, with some French',
'country': 'Russia',
'genre': 'Novel (Historical novel)',
'publisher': 'The Russian Messenger (serial)',
'title_orig': 'Война и миръ',
'orig_lang_code': 'ru',
'translator': 'The first translation of War and Peace into English was by American Nathan Haskell Dole, in 1899',
'image': 'Tolstoy - War and Peace - first edition, 1869.jpg',
'caption': 'Front page of War and Peace, first edition, 1869 (Russian)',
'release_date': 'Serialised 1865–1867; book 1869',
'media_type': 'Print',
'pages': '1,225 (first published edition)'},
['Leo Tolstoy',
'Novel',
'Historical novel',
'The Russian Messenger',
'Serial (publishing)',
'Category:1869 Russian novels',
'Category:Epic novels',
'Category:Novels set in 19th-century Russia',
'Category:Russian novels adapted into films',
'Category:Russian philosophical novels'],
['https://books.google.com/?id=c4HEAN-ti1MC',
'https://www.britannica.com/art/English-literature',
'https://books.google.com/books?id=xf7umXHGDPcC',
'https://books.google.com/?id=E5fotqsglPEC',
'https://books.google.com/?id=9sHebfZIXFAC'],
'2018-08-29T02:37:35Z']
对于维基百科上的每一本书,我们把信息框中的信息整理为字典、书籍在维基百科中的wikilinks信息、书籍的外部链接和最新编辑的时间戳。(我把精力集中在这些信息上,为我的下一个项目建立一个图书推荐系统)。你可以修改process_article 函数和WikiXmlHandler类,以查找任何你需要的信息和文章!
如果你看一下只处理一个文件的时间,1055秒,然后乘以55,你会发现处理所有文件的时间超过了15个小时!当然,我们可以在一夜之间运行,但如果可以的话,我不想浪费额外的时间。这就引出了我们将在本项目中介绍的最后一种技术:使用多处理和多线程进行并行化。
并行操作
与其一次一个解析文件,不如同时处理其中的几个(这就是我们下载分区的原因)。我们可以使用并行化,通过多线程或多处理来实现。
多线程与多处理
多线程和多处理是同时在计算机或多台计算机上执行许多任务的方法。我们磁盘上有许多文件,每个文件都需要以相同的方式进行解析。一个简单的方法是一次解析一个文件,但这并没有充分利用我们的资源。因此,我们可以使用多线程或多处理同时解析多个文件,这将大大加快整个过程。
通常,多线程对于输入/输出绑定任务(例如读取文件或发出请求)更好(更快)。多处理对于cpu密集型任务更好(更快)。对于解析文章的过程,我不确定哪种方法是最优的,因此我再次用不同的参数对这两种方法进行了基准测试。
学习如何进行测试和寻找不同的方法来解决一个问题,你将会在数据科学或任何技术的职业生涯中走得更远。
相关报道:https://towardsdatascience.com/wikipedia-data-science-working-with-the-worlds-largest-encyclopedia-c08efbac5f5c

时间:2018-10-27 11:58 来源: 转发量:次
声明:本站部分作品是由网友自主投稿和发布、编辑整理上传,对此类作品本站仅提供交流平台,转载的目的在于传递更多信息及用于网络分享,并不代表本站赞同其观点和对其真实性负责,不为其版权负责。如果您发现网站上有侵犯您的知识产权的作品,请与我们取得联系,我们会及时修改或删除。
相关文章:
- [数据挖掘]底层I/O性能大PK:Python/Java被碾压,Rust有望取代
- [数据挖掘]RedMonk语言排行:Python力压Java,Ruby持续下滑
- [数据挖掘]不得了!Python 又爆出重大 Bug~
- [数据挖掘]TIOBE 1 月榜单:Python年度语言四连冠,C 语言再次
- [数据挖掘]TIOBE12月榜单:Java重回第二,Python有望四连冠年度
- [数据挖掘]这个可能打败Python的编程语言,正在征服科学界
- [数据挖掘]2021年编程语言趋势预测:Python和JavaScript仍火热,
- [数据挖掘]Spark 3.0重磅发布!开发近两年,流、Python、SQL重
- [数据挖掘]Python 为什么推荐蛇形命名法?
- [数据挖掘]Python才是世界上最好的语言
相关推荐:
网友评论:















